 一文帶你了解RNN、LTSM、Seq2Seq、Attention機制
一文帶你了解RNN、LTSM、Seq2Seq、Attention機制
上一章我們詳細介紹了小樣本做文本分類中的膠囊網絡,那么這一章我們就來看看RNN(循環神經網絡)。大神們準備好了嗎,我們要發車了~
首先就是我們為什么需要RNN?
舉個簡單的例子,最近娛樂圈頂流明星吳亦凡又出新瓜,大家都吃了咩?(反正小編吃的很飽哈)那么就以我 吃 瓜為例,三個單詞標注詞性為 我/nn 吃/v 瓜/nn。
那么這個任務的輸入就是:
我 吃 瓜 (已經分詞好的句子)
這個任務的輸出是:
我/nn 吃/v 瓜/nn(詞性標注好的句子)
很明顯,一個句子中,前一個單詞其實對于當前單詞的詞性預測是有很大影響的,比如預測“瓜”的時候,由于前面的吃是一個動詞,那么很顯然“瓜”作為名詞的概率就會遠大于動詞的概率,因為動詞后面接名詞很常見,而動詞后面接動詞很少見。
所以為了更好的處理序列的信息,解決一些這樣類似的問題,我們的RNN就誕生了。
rnn的結構和原理
看完初步的概念我們來深入一點看看RNN的結構和原理。rnn的結構和原理
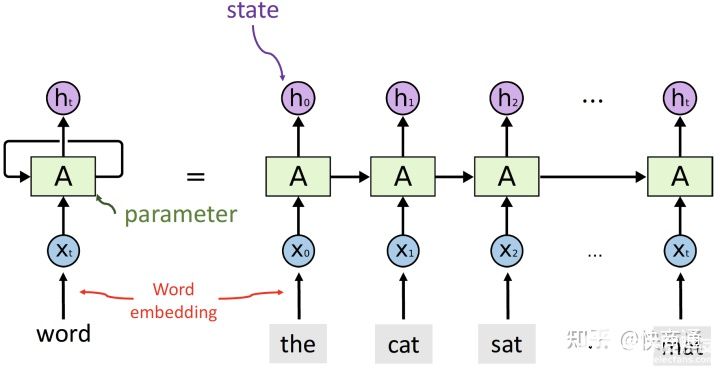
剛開始看到這幅圖的同學會不會有一點懵懵?沒關系,我們來帶著解釋一遍~
首先通過這副圖,就能明白RNN的意義就是每個輸出的狀態都只由前一時刻的狀態和當前時刻的輸入來決定。從等式左邊的一個環繞箭頭就能明白參數是共享的。
一個序列的每個詞就是每個時間步,每個詞都會對應得到一個hidden_state,并將這個隱藏層狀態輸入下一個時間步。
最終會得到output和hidden,output是每一步運算的輸出,因此output=(seqence_len, batch_size, hidden_size)。hidden_state是每一步的輸出,當然有參數來控制可以取最后一步的輸出,所以RNN中一般output=hidden。
lstm的結構和原理
聊完一圈RNN之后,我們來看看它的變種兄弟-LSTM吧!
別慌,我說的不是變種成僵尸的那種東東,Lstm為長短期記憶,是在RNN的基礎上引入了細胞狀態,根據細胞狀態可決定哪些狀態應該保留下來,哪些狀態應該被遺忘,可以在一定程度上解決梯度消失問題。
那么為了能夠學習序列關系的長期依賴,Lstm的輸出和rnn一樣都包含output和hidden,除此之外還有一個cell_state,這個就是學習序列信息lstm與rnn的差異。
在lstm里面理解的就是用“門”結構,來選擇信息通過,關鍵是用了$sigmoid(\cdot)$函數來區分趨于0的和趨于1的特征數據。
遺忘門:通過$f_t=\sigma(W_f \cdot[h_{t-1},x_t] + b_f)$ 來判斷隱藏層信息的取舍。
輸入門:
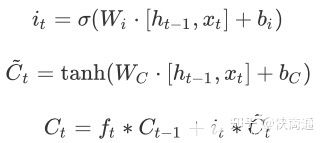
通過$\tanh(\cdot)$,來將隱藏層狀態映射到(-1,1)最后來更新$C_{t-1}$ 到$C_t $
輸出門:
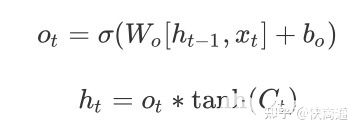
會發現$f_t、i_t、o_t$的構成是一致的。但是通過不同的權重來學習。因此優化lstm是將遺忘門和輸入門合并成了一個更新門,這就是GRU:
可以理解為主要分為兩部分,第一部分:
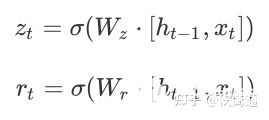
$z_t$表示更新向量,$r_t$表示重置向量,于是在接下來就能夠考慮$r_t$與$h_{t-1}$的相關性來去對部分數據進行重置,也就相當于舍棄。實現遺忘門的效果。
第二部分:
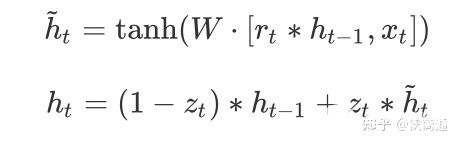
很好理解,就可以通過篩選得到的有效的隱藏層信息$\tilde{h}t$和更新向量來獲取最終的輸出結果$(1-z_t) * h{t-1}$表示對當前一時刻隱藏層狀態選擇性“遺忘”。$z_t * \tilde{h}_t$就表示對當前序列信息的“記憶”。
sequence-to-sequence的結構和原理
也叫做Encoder-Decoder結構,在encoder和decoder中也都是用序列模型,就是將數據先encode成一個上下文向量context vector,這個context vector可以是1)最后一個隱藏層狀態,2)可以是完整的隱藏層輸出,3)也可以是對隱藏層輸出做激活或者線性變換之后的輸出。
之后在decoder中,將context vector作為前一時刻初始化的狀態輸入從而將語義按監督信息的需要解碼。或者將context vector作為decoder每一個時間步的輸入。因此會發現seq2seq并不限制輸入和輸出的序列長度,這就表示應用范圍可以很廣。
Attention
會發現context vector并不能夠包含長句的所有信息,或者說會造成信息的丟失,因此attention機制就是能夠向decoder的每一個時間步輸入不同的文本信息,提升語義的理解能力。
因為lstm會得到完整的包含每一個時間步的輸出得到的ouput和hidden,因此$h_i$和$C_j$的相關性就能夠表示在decode第$j$步序列時最關心的文本是那一步的 $h_i $,用 $\alpha_{ij}$來表示。
每一個encoder的hidden單元和每一個decoder的hidden單元做點乘,得到每兩個單元之間的相關性,在lstm/rnn之后用attention就是計算hidden和ouput的每個單元之間的相關性,然后做一步$softmax$得到encoder的hidden或者說是lstm的hidden每個單元的attention weights。因此:Attention 無非就是這三個公式:
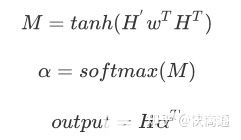
從常規的(Q,K,V)的角度來理解,可以如圖所示:
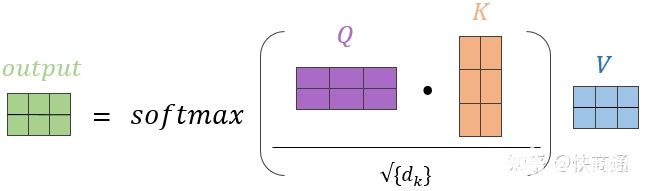
在Attention中$Q$和$K$分別是hidden和output,同樣的$V$也是ouput,在self-attention中Q=K=V,并且$\sqrt{d_k}$有些情況下是不會加在attention過程中的。
編輯:jq
-
數據
+關注
關注
8文章
7247瀏覽量
91300 -
Gru
+關注
關注
0文章
12瀏覽量
7627
發布評論請先 登錄
【米爾-全志T536開發板試用體驗】Wi-Fi連接測試體驗
函數HAL_I2C_Slave_Seq_Transmit_IT和HAL_I2C_Slave_Seq_Receive_IT實現代碼里有處理DMA請求,這是出于什么考慮?
DLPLCR4500EVM打光結束后任然顯示Seq. Running, 并且pause與stop無法終止該狀態是怎么回事?
RNN的應用領域及未來發展趨勢
RNN與LSTM模型的比較分析
深度學習中RNN的優勢與挑戰
RNN的基本原理與實現
一文詳解SiC的晶體缺陷

LSTM神經網絡與傳統RNN的區別
一文了解MySQL索引機制






 工商網監
工商網監
評論