") Google Brain和DeepMind聯(lián)手發(fā)布可以分布式訓練模型的框架
Google Brain和DeepMind聯(lián)手發(fā)布可以分布式訓練模型的框架
【導讀】AI模型進入大數(shù)據(jù)時代,單機早已不能滿足訓練模型的要求,最近Google Brain和DeepMind聯(lián)手發(fā)布了一個可以分布式訓練模型的框架Launchpad,堪稱AI界的MapReduce。
正如吳恩達所言,當代機器學習算法的成功很大程度上是由于模型和數(shù)據(jù)集大小的增加,在大規(guī)模數(shù)據(jù)下進行分布式訓練也逐漸變得普遍,而如何在大規(guī)模數(shù)據(jù)、大模型的情況下進行計算,還是一個挑戰(zhàn)。
分布式學習過程也會使實現(xiàn)過程復雜化,這對于許多不熟悉分布式系統(tǒng)機制的機器學習從業(yè)者來說是個問題,尤其是那些具有復雜通信拓撲結(jié)構(gòu)的機器學習從業(yè)者。
在arxiv上一篇新論文中,來自 DeepMind 和 Google Brain 的研究團隊用 Launchpad 解決了這個問題,Launchpad 是一種編程模型,它簡化了定義和啟動分布式計算實例的過程。
論文的第一作者是來自DeepMind的華人Yang Fan,畢業(yè)于香港中文大學。
Launchpad 將分布式系統(tǒng)的拓撲描述為一個圖形數(shù)據(jù)結(jié)構(gòu),這樣圖中的每個節(jié)點都代表一個服務,即研究人員正在運行的基本計算單元。
將句柄構(gòu)造為節(jié)點的引用,將客戶端表示為尚未構(gòu)造的服務。
圖的邊表示兩個服務之間的通信,并在構(gòu)建時將與一個節(jié)點相關聯(lián)的句柄給予另一個節(jié)點時創(chuàng)建。
通過這種方式,Launchpad 可以通過傳遞節(jié)點句柄來定義跨服務通信。Launchpad 的計算構(gòu)建塊由不同的服務類型表示,每種服務類型由特定于該類型的節(jié)點和句柄類表示。

論文中提出的 Launchpad 的生命周期可以分為三個階段: 設置、啟動和執(zhí)行。設置階段構(gòu)造程序數(shù)據(jù)結(jié)構(gòu); 在啟動階段,處理這個數(shù)據(jù)結(jié)構(gòu)以分配資源、地址等,并啟動指定服務; 然后執(zhí)行階段運行服務,例如為服務通信創(chuàng)建客戶端。
Launchpad 是用流行的編程語言 Python 實現(xiàn)的,它簡化了定義程序和節(jié)點數(shù)據(jù)結(jié)構(gòu)以及為單個平臺啟動的過程。Launchpad 框架還可以很容易地用任何其他宿主語言實現(xiàn),包括 c/c + + 等低級編程語言。

Launchpad 編程模型非常豐富,足以容納各種各樣的分布式系統(tǒng),包括參數(shù)服務器、 MapReduce和 Evolution Strategies。
研究人員用簡潔的代碼詳細描述了如何將 Launchpad 應用到這些常見的分布式系統(tǒng)范例中,并說明了該框架在簡化本研究領域常用機器學習算法和組件的設計過程方面的能力。
總的來說,Launchpad 是一個實用的、用戶友好的、表達性強的框架,用于機器學習研究人員和實踐者詳細說明分布式系統(tǒng),作者表示,這個框架能夠處理日益復雜的機器學習模型。其他框架
2020年,DeepMind 發(fā)布過一個強化學習優(yōu)化框架Acme,可以讓AI驅(qū)動的智能體在不同的執(zhí)行規(guī)模上運行,從而簡化強化學習算法的開發(fā)過程。
強化學習可以讓智能體與環(huán)境互動,生成他們自己的訓練數(shù)據(jù),這在電子游戲、機器人技術、自動駕駛機器人出租車等領域取得了突破。
隨著所使用的訓練數(shù)據(jù)量的增加,這促使設計了一個系統(tǒng),使智能體與環(huán)境實例相互作用,迅速積累經(jīng)驗。DeepMind 斷言,將算法的單進程原型擴展到分布式系統(tǒng)通常需要重新實現(xiàn)相關的智能體,這就是 Acme 框架的用武之地。
DeepMind研究員寫道,「Acme 是一個用于構(gòu)建可讀、高效、面向研究的 RL 算法的框架。Acme 的核心是設計用于簡單描述 RL 智能體,這些智能體可以在不同規(guī)模的執(zhí)行中運行,包括分布式智能體。」
Determined AI也是一個深度學習神器。Determined使深度學習工程師可以集中精力大規(guī)模構(gòu)建和訓練模型,而無需擔心DevOps,或者為常見任務(如容錯或?qū)嶒灨櫍┚帉懘a。更快的分布式訓練,智能的超參優(yōu)化,實驗跟蹤和可視化。
一萬億模型要來了?谷歌大腦和DeepMind聯(lián)手發(fā)布分布式訓練框架Launchpad
Determined主要運用了Horovod,以Horovod為起點,研究人員運用了多年的專業(yè)知識和經(jīng)驗,使得整個訓練過程比庫存配置要快得多。
Horovod 是一套面向TensorFlow 的分布式訓練框架,由Uber 構(gòu)建并開源,目前已經(jīng)運行于Uber 的Michelangelo 機器學習即服務平臺上。Horovod 能夠簡化并加速分布式深度學習項目的啟動與運行。當數(shù)據(jù)較多或者模型較大時,為提高機器學習模型訓練效率,一般采用多 GPU 的分布式訓練。TensorFlow 集群存在諸多缺點,如概念太多、學習曲線陡峭、修改的代碼量大、性能損失較大等,而 Horovod 則讓深度學習變得更加美好,隨著規(guī)模增大,Horovod 性能基本是線性增加的,損失遠小于 TensorFlow。
2019年,字節(jié)跳動AI lab開源了一款高性能分布式框架BytePS,在性能上顛覆了過去幾年allreduce流派一直占據(jù)上風的局面,超出目前其他所有分布式訓練框架一倍以上的性能,且同時能夠支持Tensorflow、PyTorch、MXNet等開源庫。
BytePS 提供了 TensorFlow、PyTorch、 MXNet 以及Keras的插件,用戶只要在代碼中引用BytePS的插件,就可以獲得高性能的分布式訓練。BytePS的核心邏輯,則實現(xiàn)在BytePS core里。具體的通信細節(jié),完全由BytePS完成,用戶完全不需要操心。
編輯:jq
-
gpu
+關注
關注
28文章
4916瀏覽量
130744 -
開源
+關注
關注
3文章
3624瀏覽量
43543 -
分布式
+關注
關注
1文章
982瀏覽量
75203 -
機器學習
+關注
關注
66文章
8493瀏覽量
134178 -
pytorch
+關注
關注
2文章
809瀏覽量
13791
發(fā)布評論請先 登錄
潤和軟件StackRUNS異構(gòu)分布式推理框架的應用案例

潤和軟件發(fā)布StackRUNS異構(gòu)分布式推理框架

曙光存儲領跑中國分布式存儲市場
淺談工商企業(yè)用電管理的分布式儲能設計
分布式云化數(shù)據(jù)庫有哪些類型
大模型訓練框架(五)之Accelerate
HarmonyOS Next 應用元服務開發(fā)-分布式數(shù)據(jù)對象遷移數(shù)據(jù)權(quán)限與基礎數(shù)據(jù)
大語言模型開發(fā)框架是什么
Google DeepMind發(fā)布Genie 2:打造交互式3D虛擬世界
分布式通信的原理和實現(xiàn)高效分布式通信背后的技術NVLink的演進

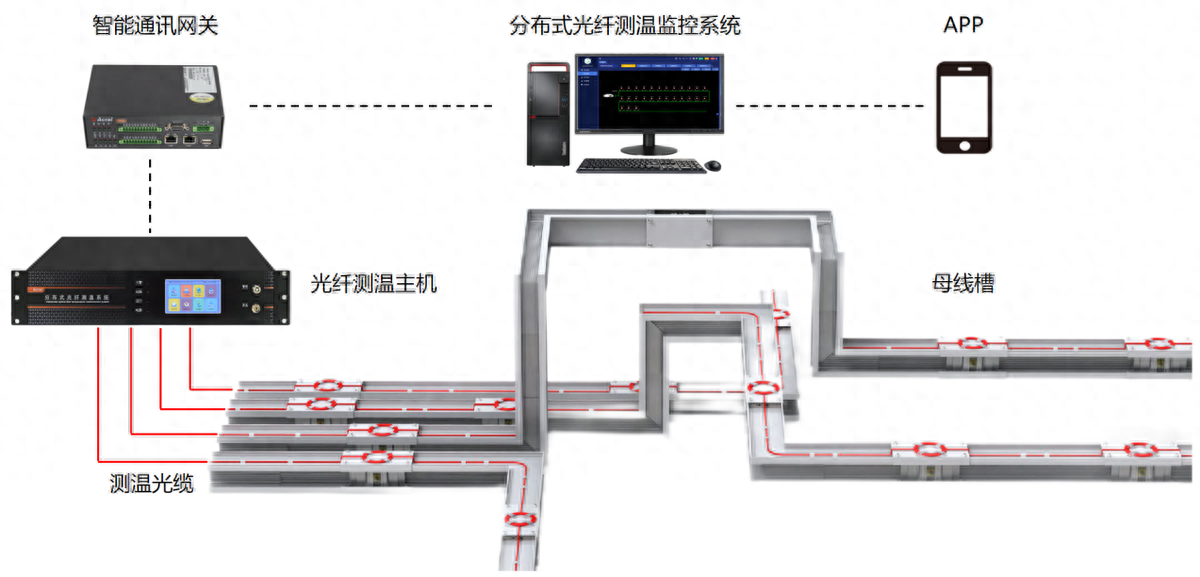
分布式光纖測溫是什么?應用領域是?
NetApp與Google Cloud深化合作,強化分布式云存儲
分布式故障在線監(jiān)測|高精度技術選用 行波特征 故診模型
安科瑞分布式光伏系統(tǒng)在某重工企業(yè)18MW分布式光伏中應用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論