") 英偉達(dá)H100 Transformer引擎加速AI訓(xùn)練 準(zhǔn)確而且高達(dá)6倍性能
英偉達(dá)H100 Transformer引擎加速AI訓(xùn)練 準(zhǔn)確而且高達(dá)6倍性能
在當(dāng)今計(jì)算平臺(tái)上,大型 AI 模型可能需要數(shù)月來完成訓(xùn)練。而這樣的速度對(duì)于企業(yè)來說太慢了。
隨著一些模型(例如大型語言模型)達(dá)到數(shù)萬億參數(shù),AI、高性能計(jì)算和數(shù)據(jù)分析變得日益復(fù)雜。
NVIDIA Hopper 架構(gòu)從頭開始構(gòu)建,憑借強(qiáng)大的算力和快速的內(nèi)存來加速這些新一代 AI 工作負(fù)載,從而處理日益增長的網(wǎng)絡(luò)和數(shù)據(jù)集。
Transformer 引擎是全新 Hopper 架構(gòu)的一部分,將顯著提升 AI 性能和功能,并助力在幾天或幾小時(shí)內(nèi)訓(xùn)練大型模型。
使用 Transformer 引擎訓(xùn)練 AI 模型
Transformer 模型是當(dāng)今廣泛使用的語言模型(例如 asBERT 和 GPT-3)的支柱。Transformer 模型最初針對(duì)自然語言處理用例而開發(fā),但因其通用性,現(xiàn)在逐步應(yīng)用于計(jì)算機(jī)視覺、藥物研發(fā)等領(lǐng)域。
與此同時(shí),模型大小不斷呈指數(shù)級(jí)增長,現(xiàn)在已達(dá)到數(shù)萬億個(gè)參數(shù)。由于計(jì)算量巨大,訓(xùn)練時(shí)間不得不延長到數(shù)月,而這樣就無法滿足業(yè)務(wù)需求。
Transformer 引擎采用 16 位浮點(diǎn)精度和新增的 8 位浮點(diǎn)數(shù)據(jù)格式,并整合先進(jìn)的軟件算法,將進(jìn)一步提升 AI 性能和功能。
AI 訓(xùn)練依賴浮點(diǎn)數(shù),浮點(diǎn)數(shù)是小數(shù),例如 3.14。TensorFloat32 (TF32) 浮點(diǎn)格式是隨 NVIDIA Ampere 架構(gòu)而面世的,現(xiàn)已成為 TensorFlow 和 PyTorch 框架中的默認(rèn) 32 位格式。
大多數(shù) AI 浮點(diǎn)運(yùn)算采用 16 位“半”精度 (FP16)、32 位“單”精度 (FP32),以及面向?qū)I(yè)運(yùn)算的 64 位“雙”精度 (FP64)。Transformer 引擎將運(yùn)算縮短為 8 位,能以更快的速度訓(xùn)練更大的網(wǎng)絡(luò)。
與 Hopper 架構(gòu)中的其他新功能(例如,在節(jié)點(diǎn)之間提供直接高速互連的 NVLink Switch 系統(tǒng))結(jié)合使用時(shí),H100 加速服務(wù)器集群能夠訓(xùn)練龐大網(wǎng)絡(luò),而這些網(wǎng)絡(luò)此前幾乎無法以企業(yè)所需的速度進(jìn)行訓(xùn)練。
更深入地研究 Transformer 引擎
Transformer 引擎采用軟件和自定義 NVIDIA Hopper Tensor Core 技術(shù),該技術(shù)旨在加速訓(xùn)練基于常見 AI 模型構(gòu)建模塊(即 Transformer)構(gòu)建的模型。這些 Tensor Core 能夠應(yīng)用 FP8 和 FP16 混合精度,以大幅加速 Transformer 模型的 AI 計(jì)算。采用 FP8 的 Tensor Core 運(yùn)算在吞吐量方面是 16 位運(yùn)算的兩倍。
模型面臨的挑戰(zhàn)是智能管理精度以保持準(zhǔn)確性,同時(shí)獲得更小、更快數(shù)值格式所能實(shí)現(xiàn)的性能。Transformer 引擎利用定制的、經(jīng)NVIDIA調(diào)優(yōu)的啟發(fā)式算法來解決上述挑戰(zhàn),該算法可在 FP8 與 FP16 計(jì)算之間動(dòng)態(tài)選擇,并自動(dòng)處理每層中這些精度之間的重新投射和縮放。
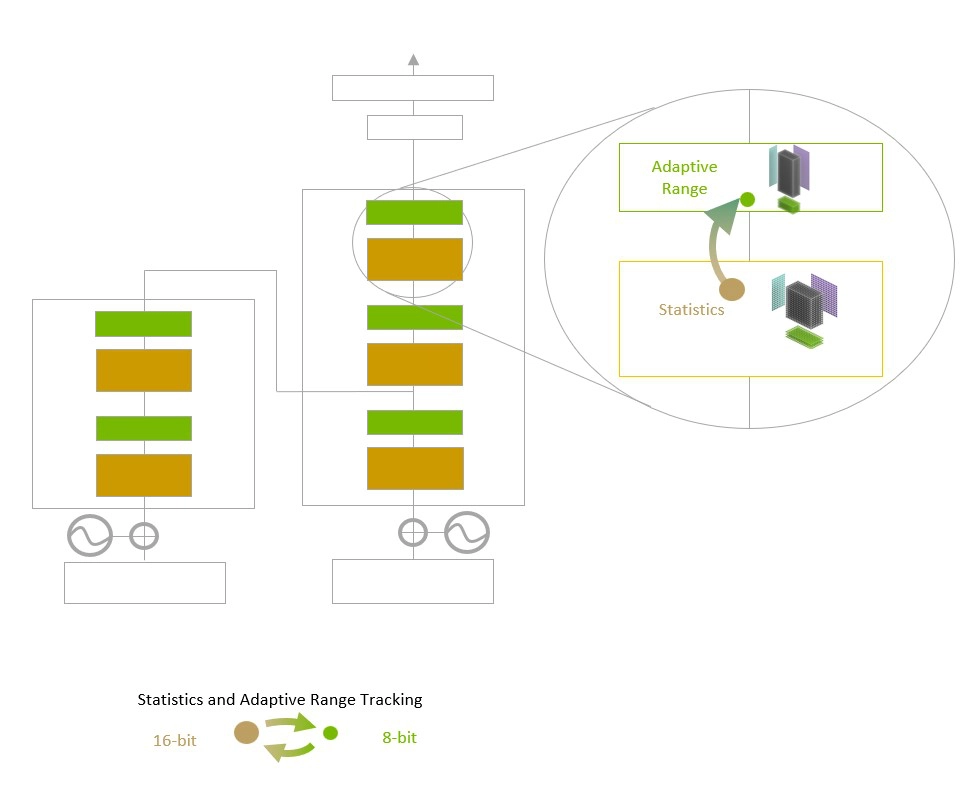
Transformer Engine 使用每層統(tǒng)計(jì)分析來確定模型每一層的最佳精度(FP16 或 FP8),在保持模型精度的同時(shí)實(shí)現(xiàn)最佳性能。
與上一代 TF32、FP64、FP16 和 INT8 精度相比,NVIDIA Hopper 架構(gòu)還將每秒浮點(diǎn)運(yùn)算次數(shù)提高了三倍,從而在第四代 Tensor Core 的基礎(chǔ)上實(shí)現(xiàn)了進(jìn)一步提升。Hopper Tensor Core 與 Transformer 引擎和第四代 NVLink 相結(jié)合,可使 HPC 和 AI 工作負(fù)載的加速實(shí)現(xiàn)數(shù)量級(jí)提升。
加速 Transformer 引擎
AI 領(lǐng)域的大部分前沿工作都圍繞 Megatron 530B 等大型語言模型展開。下圖顯示了近年來模型大小的增長趨勢(shì),業(yè)界普遍認(rèn)為這一趨勢(shì)將持續(xù)發(fā)展。許多研究人員已經(jīng)在研究用于自然語言理解和其他應(yīng)用的超萬億參數(shù)模型,這表明對(duì) AI 計(jì)算能力的需求有增無減。
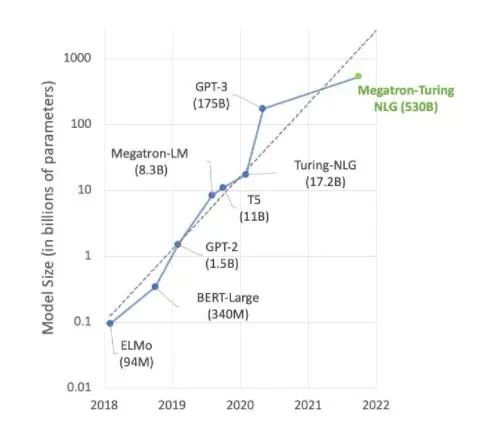
自然語言理解模型仍在快速增長。
為滿足這些持續(xù)增長的模型的需求,高算力和大量高速內(nèi)存缺一不可。NVIDIA H100 Tensor Core GPU 兩者兼?zhèn)洌偌由?Transformer 引擎實(shí)現(xiàn)的加速,可助力 AI 訓(xùn)練更上一層樓。
通過上述方面的創(chuàng)新,就能夠提高吞吐量,將訓(xùn)練時(shí)間縮短 9 倍——從 7 天縮短到僅 20 個(gè)小時(shí):
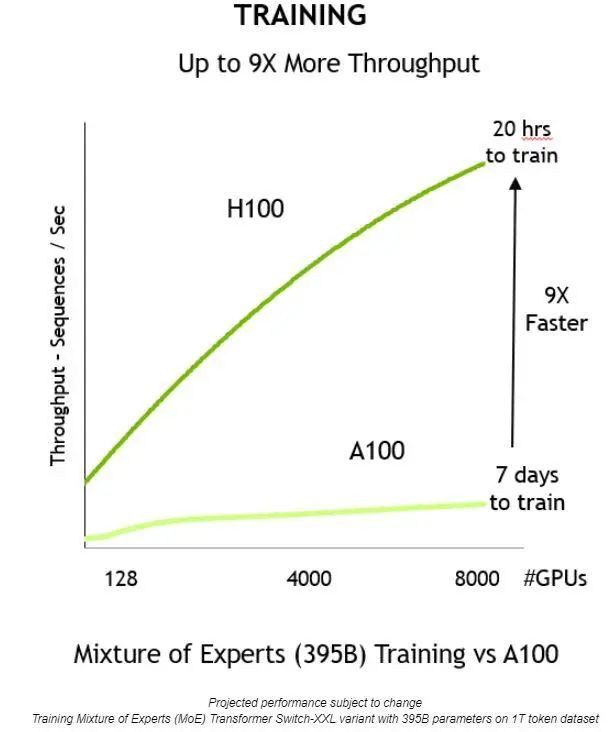
與上一代相比,NVIDIA H100 Tensor Core GPU 提供 9 倍的訓(xùn)練吞吐量,從而可在合理的時(shí)間內(nèi)訓(xùn)練大型模型。
Transformer 引擎還可用于推理,無需進(jìn)行任何數(shù)據(jù)格式轉(zhuǎn)換。以前,INT8 是實(shí)現(xiàn)出色推理性能的首選精度。但是,它要求經(jīng)訓(xùn)練的網(wǎng)絡(luò)轉(zhuǎn)換為 INT8,這是優(yōu)化流程的一部分,而 NVIDIA TensorRT 推理優(yōu)化器可輕松實(shí)現(xiàn)這一點(diǎn)。
使用以 FP8 精度訓(xùn)練的模型時(shí),開發(fā)者可以完全跳過此轉(zhuǎn)換步驟,并使用相同的精度執(zhí)行推理操作。與 INT8 格式的網(wǎng)絡(luò)一樣,使用 Transformer 引擎的部署能以更小的內(nèi)存占用空間運(yùn)行。
在 Megatron 530B 上,NVIDIA H100 的每 GPU 推理吞吐量比 NVIDIA A100 高 30 倍,響應(yīng)延遲為 1 秒,這表明它是適用于 AI 部署的上佳平臺(tái):
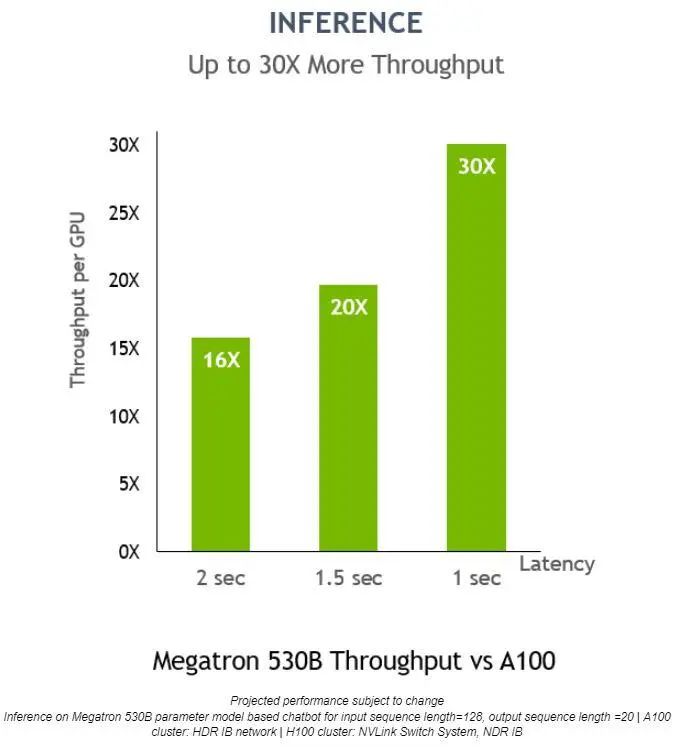
對(duì)于低延遲應(yīng)用,Transformer 引擎還可將推理吞吐量提高 30 倍。
-
AI
+關(guān)注
關(guān)注
88文章
34588瀏覽量
276193 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3927瀏覽量
93273 -
H100
+關(guān)注
關(guān)注
0文章
33瀏覽量
401
原文標(biāo)題:GTC22 | H100 Transformer 引擎大幅加速 AI 訓(xùn)練,在不損失準(zhǔn)確性的情況下提供高達(dá) 6 倍的性能
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
GPU 維修干貨 | 英偉達(dá) GPU H100 常見故障有哪些?

特朗普要叫停英偉達(dá)對(duì)華特供版 英偉達(dá)H20出口限制 或損失55億美元
新思科技攜手英偉達(dá)加速芯片設(shè)計(jì),提升芯片電子設(shè)計(jì)自動(dòng)化效率
英偉達(dá)A100和H100比較

英偉達(dá)H100芯片市場(chǎng)降溫
英偉達(dá)推出歸一化Transformer,革命性提升LLM訓(xùn)練速度
英偉達(dá)發(fā)布AI模型 Llama-3.1-Nemotron-51B AI模型
亞馬遜云科技宣布Amazon EC2 P5e實(shí)例正式可用 由英偉達(dá)H200 GPU提供支持
英偉達(dá)Blackwell可支持10萬億參數(shù)模型AI訓(xùn)練,實(shí)時(shí)大語言模型推理
蘋果AI模型訓(xùn)練新動(dòng)向:攜手谷歌,未選英偉達(dá)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論