") 使用NVIDIA TAO工具包構建對話AI和應用程序
使用NVIDIA TAO工具包構建對話AI和應用程序
對話式人工智能是一組技術,能夠在人類和設備之間基于最自然的界面(語音和自然語言)進行類似人類的交互。基于對話人工智能的系統(tǒng)可以通過識別語音和文本、在不同語言之間進行即時翻譯、理解我們的意圖以及以模仿人類對話的方式響應來理解命令。
構建對話式人工智能系統(tǒng)和應用程序很困難。為您的數(shù)據(jù)中心部署量身定制哪怕是單個組件來滿足您企業(yè)的需求就更難了。特定于領域的應用程序的部署通常需要幾個周期的重新培訓、微調和部署模型,直到滿足需求為止。
為了解決這些問題,本文介紹了三個關鍵產(chǎn)品:
NVIDIA TAO Toolkit 促進對話 AI 模型的培訓和微調。
NVIDIA Riva 簡化了結果模型的部署和推斷。
NVIDIA NGC collections 已經(jīng)預先訓練了對話 AI 模型,可以作為進一步微調或部署的起點。
由于這些產(chǎn)品的緊密集成,您可以將 80 小時的培訓、微調和部署周期壓縮到 8 小時。在本文中,我們將重點介紹 TAO 工具包,向您展示它如何支持各種遷移學習場景,以及它如何與 Riva 集成以部署對話 AI 模型和運行實時推理。
會話人工智能簡介
在對話人工智能系統(tǒng)中,有幾個組件,大致分為三個主要領域(圖 1 ):
自動語音識別( ASR )封裝以用戶語音作為輸入開始的所有任務。在這些任務中,最常用的是負責生成口語單詞和句子的轉錄本的語音對文本。
自然語言處理( NLP )負責文本處理,包括提取、理解和處理語義信息。 NLP 封裝了許多任務,從簡單的任務(如命名實體識別)到復雜的任務(如對話框狀態(tài)跟蹤、問答和機器翻譯)。
文本到語音( TTS )將系統(tǒng)以文本形式的響應轉換為您可以聽到的音標。
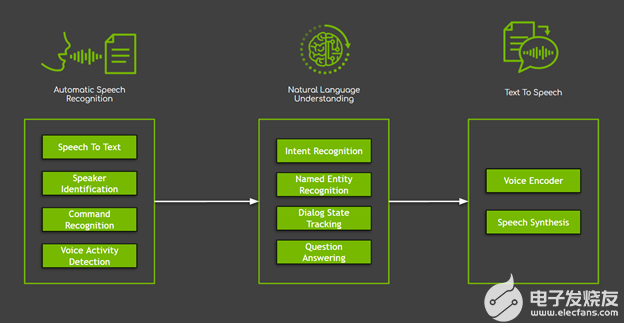
圖 1 。對話人工智能系統(tǒng)的三個主要領域,以及示例任務。
雖然這些任務可以以各種方式實現(xiàn),但由深度神經(jīng)網(wǎng)絡推動的新方法已經(jīng)取得了最佳效果,克服了大多數(shù)機器學習和基于規(guī)則的解決方案的局限性。然而,這一進步是有代價的:基于神經(jīng)網(wǎng)絡的模型需要大量的數(shù)據(jù)。
克服數(shù)據(jù)匱乏最常見的解決方案之一是使用一種稱為遷移學習。 轉移學習可以使現(xiàn)有的神經(jīng)網(wǎng)絡適應(微調)到新的神經(jīng)網(wǎng)絡,這需要更少的領域特定數(shù)據(jù)。在大多數(shù)情況下,微調所需的時間顯著減少(通常減少 x10 倍),從而節(jié)省時間和資源。最后,由于缺乏高質量、大規(guī)模的公共數(shù)據(jù)集,這種技術對對話式人工智能系統(tǒng)特別有吸引力。
TAO 工具包 3 。 0 概述
TAO Toolkit 是一個 Python 工具包,用于獲取專門構建的預訓練神經(jīng)模型,并使用您自己的數(shù)據(jù)對其進行定制。該工具包的目標是使優(yōu)化的、最先進的、經(jīng)過預訓練的模型易于在自定義企業(yè)數(shù)據(jù)上重新編譯。
TAO 工具包最重要的區(qū)別在于它遵循零編碼范式并附帶了一組可隨時使用的 Python 腳本和配置規(guī)范以及默認參數(shù)值,使您能夠啟動培訓和微調。這降低了門檻,使沒有深入了解模型、深度學習專業(yè)知識或開始編碼技能的用戶能夠培訓新模型并對預先訓練的模型進行微調。隨著新的 TAO Toolkit 3 。 0 版本的發(fā)布,該工具包實現(xiàn)了重大轉變,并開始支持最有用的對話 AI 模型。
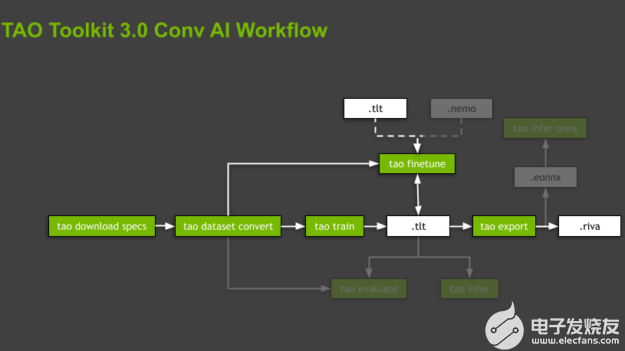
圖 2 。 TAO 工具包的一般工作流程,包括最重要的子任務(綠色框)和資產(chǎn)(白色框)。
TAO 工具包通過在專用的、預構建的 Docker 容器中執(zhí)行所有操作來抽象軟件依賴關系。腳本按層次結構組織,遵循與支持的模型關聯(lián)的域和特定于域的任務。對于每個模型,工具箱通過強制命令的執(zhí)行順序來指導您,從數(shù)據(jù)準備、培訓和微調模型到導出以供推斷。這些命令是子任務,整個組織稱為工作流程(圖 2 )。
TAO 工具包為每個工作流提供了幾個有用的腳本。在這篇文章中,我們將重點關注突出顯示的子任務,只簡要提及其余的子任務。
使用 TAO Toolkit 3 。 0 構建對話 AI 模型
TAO 工具包以 Python 包的形式提供,可使用 NVIDIA PyPI (Private Python Package) 中的 pip 進行安裝。入口點是 TAO 工具包啟動器,它使用 Docker 容器。確保 following prerequisites 可用:
安裝玩具娃娃按照官方指令的要求。然后,按照 post-installation 步驟確保 Docker 可以在沒有管理員權限(即沒有 sudo )的情況下運行。
安裝Invidia 容器工具包通過遵循 instructions 。
登錄到 NGC Docker 注冊表。
地圖目錄
TAO 工具包在后臺運行 Docker 容器,以執(zhí)行與不同命令相關聯(lián)的腳本。這個容器隱藏在 TAO 工具包啟動器后面,所以您不必擔心它。唯一的要求是預先指定存儲數(shù)據(jù)、規(guī)范文件和結果的單獨目錄。您還應該掛載一個 .cache 目錄,工具箱可以在其中存儲下載的、預先訓練的檢查點。這可以防止腳本在每次運行新的培訓或微調時反復下載相同的文件。
可以使用命令行參數(shù)設置這些目錄并使其對 Docker 容器可見,也可以在 ~/.tao_mounts.json 文件中配置這些目錄。有關更多信息,請參閱 Running the launcher 。
下面的代碼示例是一個配置文件。 source 值表示計算機中的目錄, destination 是 Docker 容器中映射的目錄。

利用遷移學習建立文本分類模型
下面是 NLP 領域的一個示例任務:基于 BERT 的模型的文本分類。文本分類是根據(jù)文本內容為文本指定標記或類別的一般任務。
在下一節(jié)中,您將重點介紹 文本分類的兩種不同應用:
情緒分析– 類別表示輸入段落的積極或消極情緒。
領域分類– 這些類別是不同的會話域。
使用 TAO Toolkit 3 。 0 在 NLP 領域中使用遷移學習有兩種不同的方法。
下載實驗規(guī)范文件
初始化 TAO 工具包啟動器后,可以開始調用與一個或另一個工作流關聯(lián)的命令。所有這些命令都在調用需要大量參數(shù)的腳本,例如數(shù)據(jù)集參數(shù)、模型參數(shù)、優(yōu)化器和訓練超參數(shù)。使 TAO 工具箱如此易于使用的部分原因是,大多數(shù)參數(shù)都以實驗規(guī)范文件( spec 文件)的形式隱藏起來。
您可以從頭開始編寫這些規(guī)范文件,也可以通過運行 tao 《 task 》 download _ specs 《 args 》從每個任務或工作流可以下載的默認文件開始編寫。您甚至可以通過啟動器單獨覆蓋每個或所有這些參數(shù)。有關每個任務的每個腳本或子任務的參數(shù)化的更多信息,請參閱 Text Classification 。
要啟動,請下載文本分類任務的默認等級庫文件:

請注意, -o 參數(shù)指示要下載默認規(guī)范文件的文件夾, -r 參數(shù)指示腳本保存日志的位置。確保 -o 參數(shù)指向空文件夾。
使用預訓練編碼器訓練情緒分析模型
對于情緒分析示例,請使用公開的 Stanford Sentiment Treebank (SST-2) 數(shù)據(jù)集。它包含 215154 個短語,在電影評論中 11855 個句子的解析樹中有情感標簽。該模型可以在細粒度( 5 向)或二元(正/負)分類任務上進行訓練,并根據(jù)精度評估性能。 SST-2 格式包含每個數(shù)據(jù)集分割的。 tsv 文件,即訓練、開發(fā)和測試數(shù)據(jù)。每個條目都有一個空格分隔的句子,后跟一個選項卡和一個標簽。
下載數(shù)據(jù)
下載 SST-2.zip archive 并將其解壓縮到主機上的一個目錄中,您將在其中存儲數(shù)據(jù)并將其裝載到 TAO Toolkit Docker 。在本例中,它是主文件夾中的/ data 文件夾:

準備數(shù)據(jù)
訓練或微調模型的第一步是準備數(shù)據(jù)。 TAO Toolkit 使用專用的數(shù)據(jù)集轉換腳本( tao dataset_convert )支持此步驟,這些腳本將輸入數(shù)據(jù)預處理為培訓、微調、評估或推理所需的格式。
對于文本分類任務, TAO Toolkit dataset _轉換腳本支持兩個公開可用的數(shù)據(jù)集,即 SST-2 和 IMDB 數(shù)據(jù)集。對于該職位,請使用 SST-2 :

請注意,所需的 -e 選項負責將配置規(guī)范文件提供給腳本,而 -r 選項指示腳本將日志文件保存在何處。所有路徑都引用安裝在 Docker 容器中的目錄。
將數(shù)據(jù)集轉換為正確的格式后,工作流中的下一步是開始培訓( tao train )或微調( tao finetune )。
使用預訓練編碼器訓練模型
從體系結構的角度來看, TAO Toolkit 中支持的所有 NLP 模型都屬于 encoder-decoder models 的一般類別,編碼器是 BERT (來自 transformer s 的雙向編碼器表示)和非回歸解碼器的變體之一。有關 NLP 模型和基于 BERT 的體系結構的更多信息,請參閱本文后面的內容。
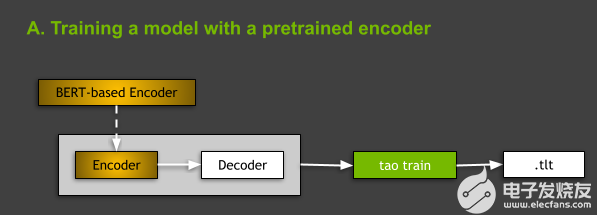
圖 3 。圖中顯示了使用預訓練編碼器訓練模型的想法。
在 TAO Toolkit 中訓練 NLP 模型時,有兩種選擇:從頭開始訓練,或者使用基于 model: 的編碼器訓練模型,該編碼器在一些通用 NLP 任務上進行了預訓練。在本文中,我們將重點討論后一種情況(圖 3 )。您可以通過在 spec 文件中指出 BERT 的 language_model 小節(jié)中基于預訓練的 BERT 編碼器的名稱來實現(xiàn)這一點

這是為文本分類任務下載等級庫文件時的默認設置。有關更多信息,請參閱 Required Arguments for Training 。
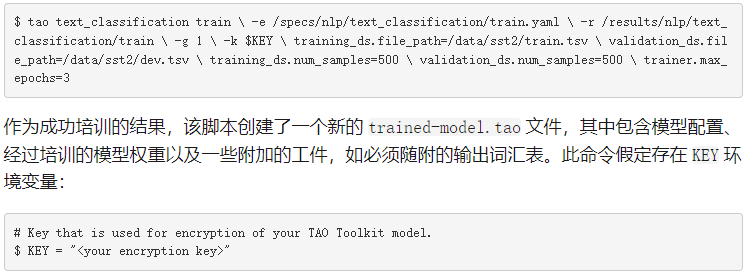
要訓練模型,必須運行 tao text_classification train 命令:
-e :微調規(guī)范文件的路徑。
-r :保存輸出日志和模型的文件夾的路徑。
-g : number of GPU to use 。
-k :保存或加載模型時要使用的用戶指定的加密密鑰。
-r :用于指定保存結果的目錄。
對等級庫文件中參數(shù)的任何替代。
正如您在本文的其余部分中所看到的,所有工作流中的大多數(shù) TAO 工具箱子任務都共享這些參數(shù)。
微調領域分類模型
TAO 工具包還支持不同的用例:微調從 NGC 下載的預訓練模型。在以下部分中,我們將向您展示如何微調域分類器。
從 NGC 下載預訓練模型
TAO 工具包在 NGC 上提供了幾個資產(chǎn)。從 NGC TAO Toolkit Text Classification model card 下載預訓練模型。為便于使用,請將其下載到/ results 文件夾:

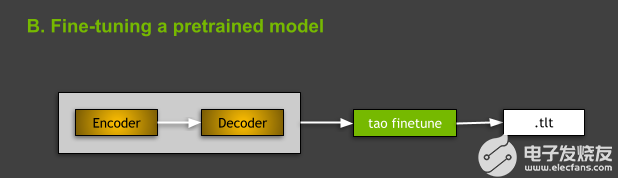
圖 4 。微調預訓練模型。
微調預訓練模型
要微調 TAO 工具箱中的文本分類模型,請使用 tao text_classification finetune 命令。從命令的角度來看,訓練和微調之間的主要區(qū)別在于存在微調所需的預訓練模型 -m 參數(shù),其中 -m 是預訓練模型文件的路徑。
在本例中,必須將數(shù)據(jù)集轉換為培訓和微調可接受的格式。有關更多信息,請參閱 Data Format 。與培訓類似,您還可以手動覆蓋包含微調和驗證數(shù)據(jù)的文件的路徑,假設微調中使用的數(shù)據(jù)文件夾為 ~/tao/data/my_domain_classification/) 。將上一步下載的 nlp-tc-trained-model.tao 文件作為輸入。

此公共 NGC 模型的加密密鑰為 tlt_encode 。
評估績效
評估子任務的目標是測量給定模型在測試分割上的性能。運行 tao evaluate :

運行推理
除了評估子任務外, TAO Toolkit 還為您提供了 tao infer 子任務,用于測試模型是否按預期運行,并為 speech_to_text 提供的原始輸入樣本(。 wav 文件)探測其輸出 question_answering 的任務、原始文本或句子 任務等)。在這種情況下,運行推斷顯示模型是否能夠正確分類輸入句子的情緒:

導出模型
最后,當您確定模型行為正確時,可以使用 tao export 命令將其導出以進行部署:

默認情況下,這將導致在 /results/nlp/text_classification/export 文件夾中創(chuàng)建 exported-model.riva 文件。導出子任務還允許將模型導出為 ONNX (開放式神經(jīng)網(wǎng)絡交換)格式( .eonnx )。必須手動設置 export_format=ONNX 參數(shù)。完成后,還可以通過運行 tao infer_onnx 命令來測試導出的 ONNX 模型的行為。盡管如此,從部署到基于 Riva 和 Riva 的推理的角度來看,這是可選的,目前不需要。
有關所有 TAO 工具包命令的更多信息,請參閱 TAO Toolkit v3.0 User Guide 。在本文后面,我們還將簡要討論其他支持的對話 AI 任務。
在 Riva 中將對話 AI 模型部署為實時服務
NVIDIA Riva 是一個 GPU – 加速 SDK ,用于使用 GPU 構建語音 AI 服務。 Riva SDK 包括針對 ASR 、 NLP 和 TTS 任務的預訓練模型、工具和優(yōu)化的端到端服務。使用 Riva 將您的模型部署為在 GPU 上進行推理優(yōu)化的服務。為了充分利用 GPU 的計算能力, Riva 使用 NVIDIA Triton Inference Server 為神經(jīng)網(wǎng)絡服務,并使用 NVIDIA TensorRT 運行推理。與僅 CPU 平臺上所需的 25 秒相比,生成的實時服務可以在 150 毫秒內運行。
要部署導出到 Riva (上一節(jié)中創(chuàng)建的 .riva 文件)的 TAO 工具箱模型,請使用 Riva ServiceMaker ,這是一個組合所有必要資產(chǎn)(模型圖、模型權重、模型配置、推理中使用的詞匯表等)的實用工具,并將其部署到目標環(huán)境中。圖 5 顯示, Riva ServiceMaker 分為兩個主要組件: riva-build 和 riva-deploy.
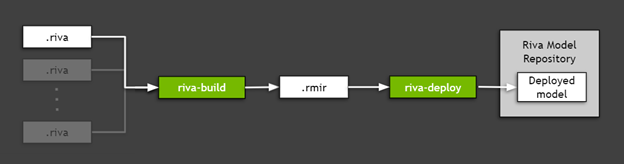
圖 5 。使用 Riva ServiceMaker 部署導出的 TAO 工具包模型。
安裝 Riva 必備組件
首先,設置一些環(huán)境變量以供以后使用。在本例中,您使用之前使用 TAO 工具箱訓練和導出的情緒分析模型,因此必須相應地設置路徑。

在本例中,您使用 /data 文件夾作為 Riva Model Repository 值,因為 Riva 快速啟動腳本默認使用此名稱。此文件夾用于存儲模型集成以及運行推理服務器所需的所有資產(chǎn)。
接下來,安裝 Riva Quick Start scripts 。最簡單的路徑是通過 NGC 注冊表。安裝 NGC CLI 并運行以下命令:

您已準備好進行模型部署。
運行 Riva – 構建
riva-build 負責一個或多個導出模型的組合( .riva 文件)轉換為包含稱為 Riva 模型中間表示( .rmir )的中間格式的單個文件。該文件包含整個端到端管道的部署無關規(guī)范,以及最終部署和推斷所需的所有資產(chǎn)。要在 Riva ServiceMaker Docker 映像內運行 riva-build 命令,請運行以下命令:

運行 Riva – 部署
riva-deploy 部署工具將 .rmir 文件作為輸入,并創(chuàng)建一個集合配置,指定執(zhí)行的管道。
在本例中,您使用 Riva 快速啟動附帶的腳本,它為您運行部署。有關如何手動調用 riva-deploy 的更多信息,請參閱 Riva Deploy 。
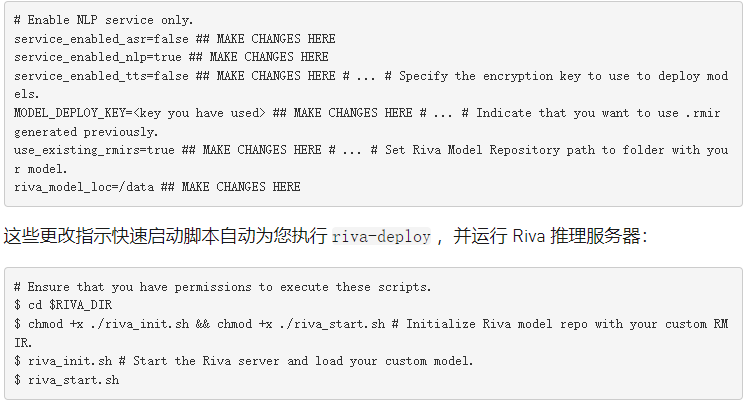
使用快速啟動啟動 Riva 服務器
在 Riva 中部署模型有兩個選項。在這種情況下,使用前面從 NGC 中提取的 Riva 快速啟動設置本地工作站。在從 pull 創(chuàng)建的文件夾中,找到 config.sh 文件。下面的代碼示例使用了一個附加變量, $RIVA_DIR ,以指示此文件夾。編輯 config 。 sh 文件并應用以下更改:
實現(xiàn)客戶端應用程序
Riva 服務器啟動并使用您的模型運行后,您可以發(fā)送查詢服務器的推斷請求。要發(fā)送 gRPC 請求,請安裝 Riva 客戶端 Python API 綁定。這個 API 是一個帶有 Riva 快速啟動的 pip .whl 。
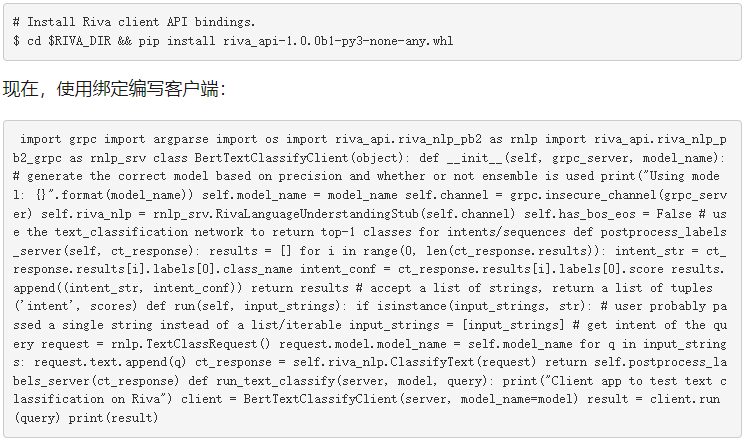
運行客戶端
現(xiàn)在,您已準備好運行客戶端:
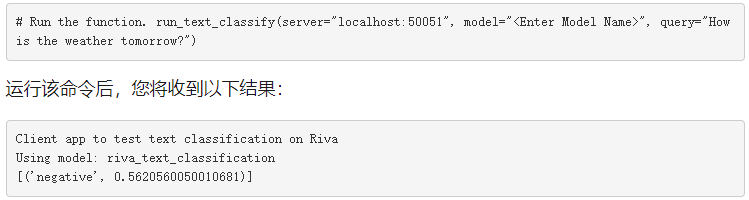
就這樣!您剛剛學習了如何使用 TAO 工具包訓練模型,將其部署到 Riva ,運行 Riva 推理服務器,并使用 Riva API 編寫簡單的客戶端。祝賀
TAO Toolkit 3 。 0 中支持的其他對話 AI 任務和模型
本文介紹的文本分類任務只是當前 TAO Toolkit 3 。 0 版本中支持的任務之一。此版本支持會話 AI 空間中兩個域的任務: ASR 和 NLP 。在本版本中跳過 TTS 的主要原因是我們發(fā)現(xiàn)培訓最先進的 TTS 模型很困難。它需要用戶專業(yè)知識和領域知識。他們還沒有為零編碼模式做好準備。
自動語音識別領域
自動語音識別( ASR )是從語音輸入中提取有意義信息的任務。來自該領域的示例性任務包括向交互式虛擬助理發(fā)出語音命令、將電影和視頻聊天中的音頻轉換為字幕,以及將客戶交互轉換為文本以便在呼叫中心存檔。
目前, TAO Toolkit 3 。 0 支持來自 ASR 域的單個任務,即語音到文本( STT )( tao speech_to_text ),負責轉錄語音。模型的輸出可以用于不同的目的。通過附加邏輯, STT 的輸出可用于語音命令。
TAO 工具包用戶有三種可用模型,所有 convolutional 神經(jīng)聲學模型:
Jasper 體系結構旨在通過允許將整個子塊融合到單個 GPU 內核中來促進快速 GPU 推理。這對于在推理過程中滿足 STT 的嚴格實時性要求非常重要。
QuartzNet 是一個類似 Jasper 的網(wǎng)絡,它使用可分離卷積和更大的過濾器大小。它的精度與 Jasper 相當,但參數(shù)要少得多。
Citrinet 是 QuartzNet 的一個版本,它使用 1D 時間通道可分離卷積與子字編碼、壓縮和激發(fā)相結合。由此產(chǎn)生的體系結構顯著減少了非自回歸和序列到序列以及傳感器模型之間的差距。
自然語言處理領域
自然語言處理( NLP )是會話人工智能應用的另一個支柱。該領域的任務包括對文本進行分類、理解語言意圖、識別關鍵詞或實體、添加自動標點符號和大寫字母以及回答給定上下文的問題。
TAO Toolkit 3 。 0 支持 NLP 域中的五種不同任務或模型:
聯(lián)合意圖和槽分類 (tao intent_slot_classification ) 是對意圖進行分類并在查詢中檢測該意圖的所有相關插槽(實體)的任務。例如,在查詢“明天早上圣塔 Clara 的天氣如何?”中,您希望將查詢分類為“天氣”意圖,將“ Santa Clara ”檢測為地方插槽,并將“明早”檢測為日期和時間狹槽意圖和插槽名稱通常是特定于任務的,并在培訓數(shù)據(jù)中定義為標簽。這是在任何任務驅動的對話 AI 助手中執(zhí)行的基本步驟。
聯(lián)合標點與大寫 (tao punctuation_and_capitalization ) 對于輸入句子或段落中的每個單詞,模型必須預測單詞后面的標點符號以及單詞是否應大寫。
問答 (tao question_answering ) 給定一個問題和一個自然語言的上下文,模型必須預測上下文中的跨度,并以開始和結束位置指示問題的答案。
文本分類 (tao text_classification ) 是一項基本但有用的 NLP 任務,可適用于許多應用,如情感分析、領域分類、語言識別和主題分類。例如,在情緒分析中,以下輸入“表演令人難以置信!”具有積極情緒,而“既不浪漫也不刺激”具有消極情緒。
令牌分類 (tao token_classification ) 是一項任務,其中輸入標記(如單詞)中的每個實體在輸出中都有相應的標簽。命名實體識別( NER )是令牌分類任務的一個應用,其目標是檢測和分類文本中的關鍵信息(實體)。例如,在一句話中,“瑪麗住在圣塔 Clara ,在 NVIDIA 工作。”模型應該檢測到“瑪麗”是一個人“ Santa Clara ”是一個地方“ NVIDIA ”是一個公司。
TAO 工具包中支持的所有 NLP 模型都將 BERT 作為其主干編碼器。 BERT 使用一種稱為 Transformer 的基于注意的體系結構來學習上下文單詞嵌入,表示文本中單詞之間的關系。 BERT 的主要創(chuàng)新在于預訓練步驟,即使用大型文本語料庫對模型進行兩個無監(jiān)督預測任務的訓練。對這些無監(jiān)督任務的培訓產(chǎn)生了一個通用語言模型,然后可以對該模型進行快速微調,以在各種 NLP 任務上實現(xiàn)最先進的性能。
結論
你或許會問,“ TAO 工具包最適合誰?”工具包當前形狀背后的關鍵人口統(tǒng)計是已經(jīng)擁有模型基礎架構的用戶,他們正試圖定制和微調它,以適應其管道中的特定用例。
通過預定義的規(guī)范文件、詳細的文檔、內置加密、與面向推理的 Riva 的開箱即用集成,以及 NGC 上的一組預訓練模型, TAO Toolkit 旨在將整個開發(fā)部署過程加快 10 倍。我們相信, TAO 工具包可以成為轉移學習和對話 AI 的一站式工具。
關于作者
About Disha Mehra是 NVIDIA 的解決方案架構師。她的工作圍繞著幫助在 NVIDIA GPU 上開發(fā)深度學習解決方案的企業(yè)客戶展開。她畢業(yè)于布法羅大學,獲計算機科學碩士學位。
About Mengdi Huang是 NVIDIA 的深度學習工程師,在基于 DL 的人工智能研究和應用領域擁有五年的工作經(jīng)驗,包括可伸縮機器學習、推薦系統(tǒng)、多模態(tài)語言、視覺和語音處理。
About Shashank Verma是 NVIDIA 的一名深入學習的技術營銷工程師。他負責開發(fā)和展示各種深度學習框架中以開發(fā)人員為中心的內容。他從威斯康星大學麥迪遜分校獲得電氣工程碩士學位,在那里他專注于計算機視覺、數(shù)據(jù)科學的安全方面和 HPC 。
About Tanay Varshney是 NVIDIA 的一名深入學習的技術營銷工程師,負責廣泛的 DL 軟件產(chǎn)品。他擁有紐約大學計算機科學碩士學位,專注于計算機視覺、數(shù)據(jù)可視化和城市分析的橫斷面。
About Evelina Bakhturina是 Nvidia 的一個深學習應用科學家,專注于自然語言處理任務和英偉達 NeMo 框架。她畢業(yè)于紐約大學,獲得數(shù)據(jù)科學碩士學位。
About Jocelyn Huang是 NVIDIA 的一名深度學習軟件工程師,她致力于 NeMo 框架和語音模型的開發(fā)。她畢業(yè)于卡內基梅隆大學,獲得計算機科學學士學位和機器學習碩士學位。
About Vlad Getselevich:是 NVIDIA 的高級應用研究科學家,專注于對話 AI 研究主題及其在實際應用中的使用。在此之前,他開發(fā)了三個大型對話系統(tǒng),每個系統(tǒng)都有數(shù)十萬用戶在生產(chǎn)中。他擁有以色列 Technion 的計算機科學碩士學位。
About Vahid Noroozi是一名應用研究科學家,在 NVIDIA 的人工智能應用小組工作。他的主要研究集中在語音和自然語言處理的深度學習上。他獲得了博士學位。來自芝加哥伊利諾伊大學的計算機科學。
About Sergei Nikolaev是 NVIDIA 人工智能應用團隊的軟件工程師。他有數(shù)學博士學位。
About Yang Zhang是英偉達人工智能應用集團的一名深度學習軟件工程師。她目前的重點是自然語言處理、對話管理和文本(去規(guī)范化)。在過去,她一直致力于大型 ASR 模型和語言模型預培訓的可擴展培訓。她在卡內基梅隆大學獲得機器學習碩士學位,在德國卡爾斯魯厄理工學院獲得計算機科學學士學位。
About Purnendu Mukherjee是一名高級深度學習軟件工程師,在 NVIDIA 的人工智能應用小組工作。他的主要工作是將最先進的、基于深度學習的語音和自然語言處理模型作為開發(fā) Jarvis 平臺的一部分投入生產(chǎn)。在加入 NVIDIA 之前, PurnNuu 畢業(yè)于佛羅里達大學,擁有計算機科學碩士學位,專門從事基于自然語言的深度學習。
About Varun Praveen是智能視頻分析團隊的高級軟件工程師,致力于創(chuàng)建深度學習解決方案并將其部署到邊緣。 2017 年加入英偉達之前,他在克萊姆森大學獲得了電氣工程碩士學位。他的研究興趣是數(shù)字信號處理、計算機視覺和機器學習。
About Tomasz Kornuta是 NVIDIA 的高級應用研究科學家,致力于多模態(tài)機器學習和對話人工智能。在加入 NVIDIA 之前,他曾在加利福尼亞州 IBM research 擔任研究人員五年,從事視覺感知、認知科學、推理和深度學習方面的研究。托馬斯茲擁有博士學位。在機器人技術和控制方面擁有深厚的專業(yè)知識,包括軟件工程、機器人技術、視覺感知和機器學習。他撰寫或合著了 80 多篇同行評議會議和期刊論文,專門討論這些主題。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5267瀏覽量
105892 -
gpu
+關注
關注
28文章
4919瀏覽量
130770 -
AI
+關注
關注
88文章
34488瀏覽量
275959
發(fā)布評論請先 登錄
企業(yè)使用NVIDIA NeMo微服務構建AI智能體平臺
如何在 Raspberry Pi AI Camera 上構建為開發(fā)人員提供實時的智能應用程序!

構建開源OpenVINO?工具包后,使用MYRIAD插件成功運行演示時報錯怎么解決?
云計算開發(fā)工具包的功能
NVIDIA 發(fā)布保障代理式 AI 應用安全的 NIM 微服務
最新Simplicity SDK軟件開發(fā)工具包發(fā)布
基于EasyGo Vs工具包和Nl veristand軟件進行的永磁同步電機實時仿真
NVIDIA發(fā)布全新AI和仿真工具以及工作流
基于NVIDIA TAO工具包訓練汽車目標識別模型
FPGA仿真工具包軟件EasyGo Vs Addon介紹

采用德州儀器 (TI) 工具包進行模擬前端設計應用說明

使用NVIDIA JetPack 6.0和YOLOv8構建智能交通應用
使用freeRTOS開發(fā)工具包時,在哪里可以找到freeRTOS的版本?
在NVIDIA Holoscan SDK中使用OpenCV構建零拷貝AI傳感器處理管線






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論