") 機器學(xué)習(xí)模型調(diào)優(yōu)3大策略
機器學(xué)習(xí)模型調(diào)優(yōu)3大策略

無論是 Kaggle 競賽還是工業(yè)部署,機器學(xué)習(xí)模型在搭建起來之后都面臨著無盡的調(diào)優(yōu)需求。在這個過程中我們要遵循怎樣的思路呢?
如果準(zhǔn)確性不夠,機器學(xué)習(xí)模型在真實世界就沒有什么實用性了。對于開發(fā)者們來說,如何提高性能是非常重要的工作,本文將介紹一些常用策略,包括選擇最佳算法、調(diào)整模型設(shè)置和特征工程。 如果你學(xué)習(xí)過正確的教程,很快就能訓(xùn)練起自己的第一個機器學(xué)習(xí)模型。然而想要在第一個模型上跑出很好的效果是極難的。在模型訓(xùn)練完后,我們需要花費大量時間進行調(diào)整以提高性能。不同類型的模型有不同的調(diào)優(yōu)策略,在本文中,我們將介紹模型調(diào)優(yōu)的常用策略。 模型好不好? 在模型調(diào)優(yōu)之前,我們首先需要知道現(xiàn)在的模型性能是好是壞。如果你不知道如何衡量模型的性能,可以參考:
https://www.mage.ai/blog/definitive-guide-to-accuracy-precision-recall-for-product-developers
https://www.mage.ai/blog/product-developers-guide-to-ml-regression-model-metrics
每個模型都有基線指標(biāo)。我們可以使用「模式類別」作為分類模型的基線指標(biāo)。如果你的模型優(yōu)于基準(zhǔn)線,那么恭喜你,這是一個好的開始。如果模型能力還沒有達到基準(zhǔn)水平,這說明你的模型還沒有從數(shù)據(jù)中獲得有價值的見解(insight)。為了提高性能,還有很多事情要做。 當(dāng)然還有一個情況就是模型的表現(xiàn)「太過優(yōu)秀」了,比如 99% 的準(zhǔn)確率和 99% 的召回率。這并不是什么好事,可能表示你的模型存在一定的問題。一個可能的原因是「數(shù)據(jù)泄露」,我們將在「消除數(shù)據(jù)泄漏功能」部分討論如何解決此問題。 改進模型的策略 一般來說,模型調(diào)優(yōu)有 3 個方向:選擇更好的算法,調(diào)優(yōu)模型參數(shù),改進數(shù)據(jù)。 比較不同算法 比較多個算法是提高模型性能的一個簡單的想法,不同的算法適合不同類型的數(shù)據(jù)集,我們可以一起訓(xùn)練它們,找到表現(xiàn)最好的那個。例如對于分類模型,我們可以嘗試邏輯回歸、支持向量機、XGBoost、神經(jīng)網(wǎng)絡(luò)等。
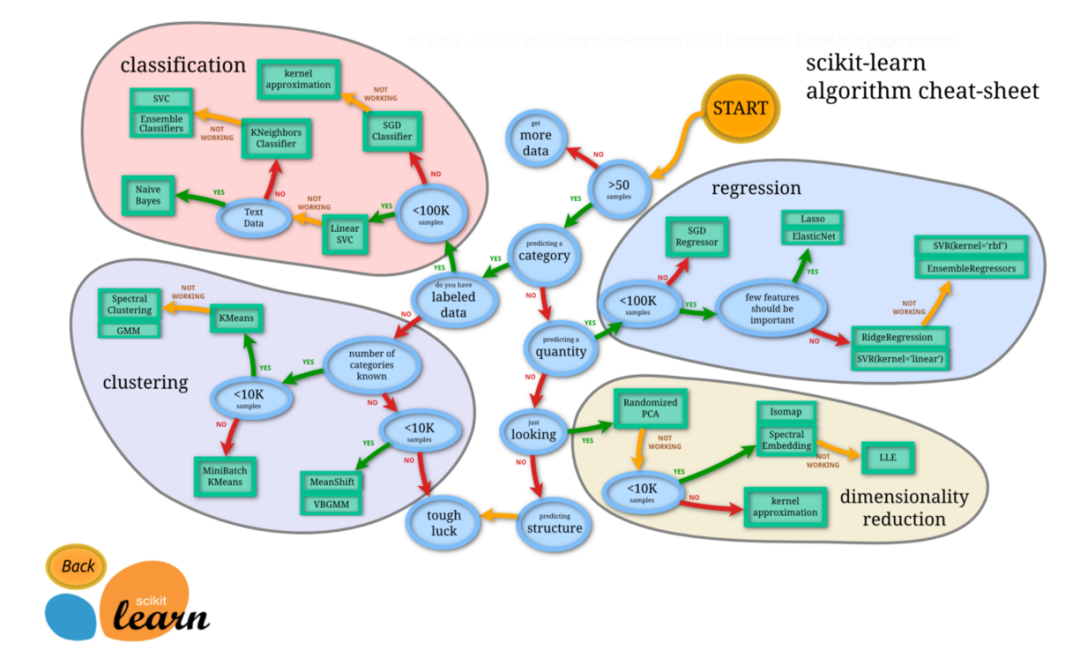
圖源:https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html 超參數(shù)調(diào)優(yōu) 超參數(shù)調(diào)優(yōu)是一種常用的模型調(diào)優(yōu)方法。在機器學(xué)習(xí)模型中,學(xué)習(xí)過程開始之前需要選擇的一些參數(shù)被稱為超參數(shù)。比如決策樹允許的最大深度,以及隨機森林中包含的樹的數(shù)量。超參數(shù)明顯影響學(xué)習(xí)過程的結(jié)果。調(diào)整超參數(shù)可以讓我們在學(xué)習(xí)過程中很快獲得最佳結(jié)果。
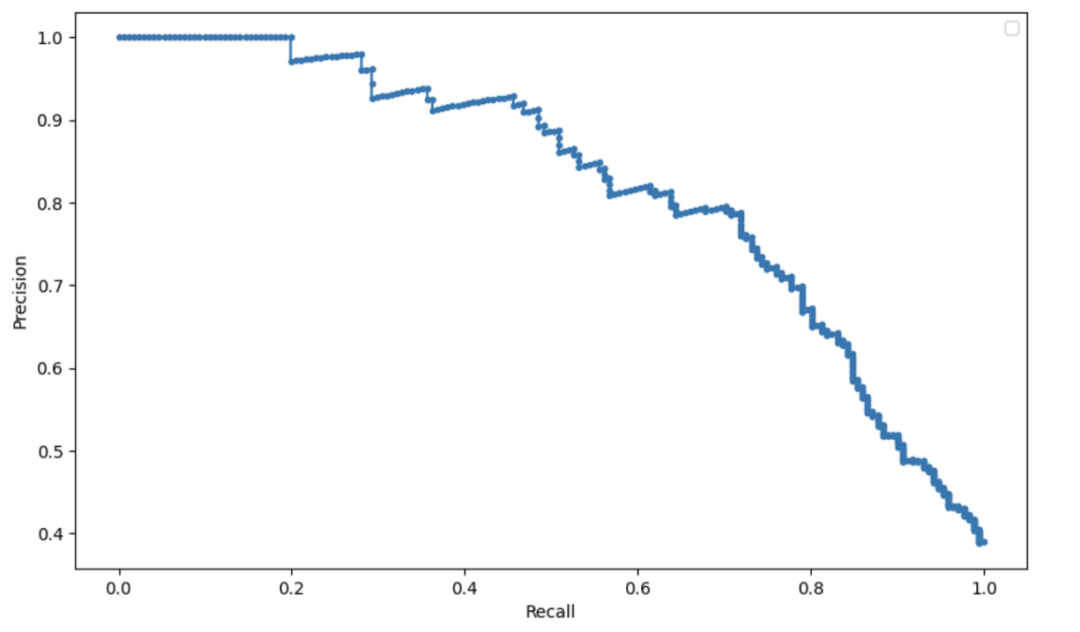
我們非常建議使用公開可用的庫幫助進行超參數(shù)調(diào)整,例如 optuna。 用召回率換精度 對于分類模型,我們通常用 2 個指標(biāo)來衡量模型的性能:精度和召回率。根據(jù)問題的不同,你可能需要優(yōu)化召回率或精度中的一個。有一種快速的方法來調(diào)整模型以在兩個指標(biāo)之間進行權(quán)衡。分類模型預(yù)測標(biāo)簽類別的概率,因此我們可以簡單地修改概率閾值來修改召回率和精度。 例如,如果我們建立一個模型來預(yù)測乘客在泰坦尼克號沉船事故中是否生還,該模型可以預(yù)測乘客生還或死亡的概率。果概率高于 50%,模型將預(yù)測乘客會幸存,反之乘客死亡。如果我們想要更高的精度,我們可以增加概率閾值。然后,該模型將預(yù)測較少的乘客幸存,但會更精確。
特征工程 除了選擇最佳算法和調(diào)優(yōu)參數(shù)外,我們還可以從現(xiàn)有數(shù)據(jù)中生成更多特征,這被稱為特征工程。 創(chuàng)建新的特征 構(gòu)建新的特征需要一定的領(lǐng)域知識和創(chuàng)造力。這是一個構(gòu)建新特征的例子:
創(chuàng)建一個功能來計算文本中的字母數(shù)。
創(chuàng)建一個功能來計算文本中的單詞數(shù)。
創(chuàng)建一個理解文本含義的特征(例如詞嵌入)。
過去 7 天、30 天或 90 天的聚合用戶事件計數(shù)。
從日期或時間戳特征中提取「日」、「月」、「年」和「假期后的天數(shù)」等特征。
使用公共數(shù)據(jù)集來增加訓(xùn)練數(shù)據(jù) 當(dāng)你窮盡從現(xiàn)有數(shù)據(jù)集中生成新特征的想法時,另一個想法是從公共數(shù)據(jù)集中獲取特征。假如你正在構(gòu)建一個用來預(yù)測用戶是否會轉(zhuǎn)換為會員的模型,可用的數(shù)據(jù)集中卻沒有太多的用戶信息,只有「電子郵件」和「公司」屬性。那么你就可以從第三方獲取用戶和公司以外的數(shù)據(jù),如用戶地址、用戶年齡、公司規(guī)模等等,這些數(shù)據(jù)可以用于豐富你的訓(xùn)練數(shù)據(jù)。
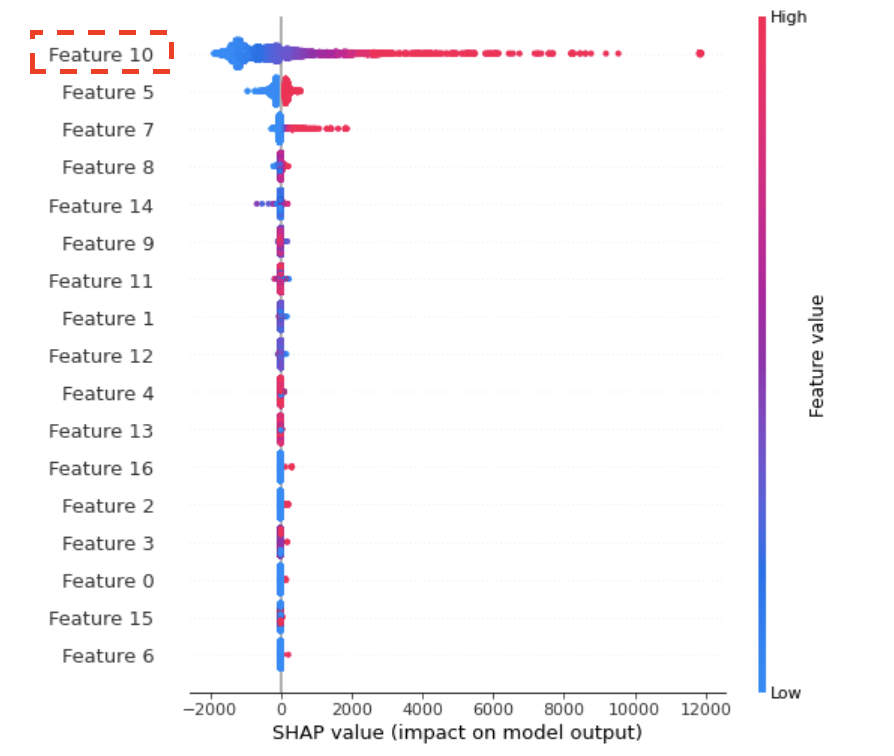
特征選擇 添加更多特征并不總是好的。去除不相關(guān)和嘈雜的特征有助于減少模型訓(xùn)練時間并提高模型性能。scikit-learn 中有多種特征選擇方法可以用來去除不相關(guān)的特征。 刪除數(shù)據(jù)泄露(data leakage)特征 正如上文提到的,一種場景是模型的性能「非常好」。但是在部署模型并在生產(chǎn)中使用這些模型時,性能會變得很差。造成這個問題的原因可能是「數(shù)據(jù)泄露」,這是模型訓(xùn)練的一個常見陷阱。數(shù)據(jù)泄露是指使用一些發(fā)生在目標(biāo)變量之后的特征,并包含目標(biāo)變量的信息。然而現(xiàn)實生活中的預(yù)測不會有那些數(shù)據(jù)泄露特征。 例如想要預(yù)測用戶是否會打開電子郵件,特征可能就包括用戶是否點擊了電子郵件。模型一旦看到用戶點擊了它,那么就預(yù)測用戶 100% 會打開它。然而在現(xiàn)實生活中,我們無法知道是否有人在打開電子郵件之前沒有點擊它。 我們可以使用 SHAP 值 debug 數(shù)據(jù)泄露問題,用 SHAP 庫繪制圖表可以顯示出影響最大的特征以及它們?nèi)绾味ㄏ蛴绊懩P偷妮敵觥H绻卣髋c目標(biāo)變量高度相關(guān)并且權(quán)重非常高,那么它們可能是數(shù)據(jù)泄露特征,我們可以將它們從訓(xùn)練數(shù)據(jù)中刪除。
更多數(shù)據(jù) 獲取更多訓(xùn)練數(shù)據(jù)是提高模型性能一種明顯而有效的方法。更多的訓(xùn)練數(shù)據(jù)能夠讓模型找到更多見解,并獲得更高的準(zhǔn)確率。
那么,什么時候該停止調(diào)優(yōu)了? 你需要知道如何開始,也需要知道在何時停止,很多時候怎樣才算足夠是一個難以回答的問題。模型的提升仿佛是無限的,沒有終點:總會有新想法帶來新數(shù)據(jù)、創(chuàng)建新功能或算法的新調(diào)整。首先,最低限度的標(biāo)準(zhǔn)是模型性能至少應(yīng)優(yōu)于基線指標(biāo)。一旦滿足了最低標(biāo)準(zhǔn),我們應(yīng)該采用以下流程來改進模型并判斷何時停止:
嘗試所有改進模型的策略。
將模型性能與你必須驗證的其他一些指標(biāo)進行比較,以驗證模型是否有意義。
在進行了幾輪模型調(diào)整后,評估一下繼續(xù)修改和性能提升百分點之間的性價比。
如果模型表現(xiàn)良好,并且在嘗試了一些想法后幾乎沒有繼續(xù)改進,請將模型部署到生產(chǎn)過程中并測量實際性能。
如果真實條件下的性能和測試環(huán)境中類似,那你的模型就算可以用了。如果生產(chǎn)性能比訓(xùn)練中的性能差,則說明訓(xùn)練中存在一些問題,這可能是因為過擬合或者數(shù)據(jù)泄露。這意味著還需要重新調(diào)整模型。
結(jié)論 模型調(diào)優(yōu)是一個漫長而復(fù)雜的過程,包含模型的重新訓(xùn)練、新想法的試驗、效果評估和指標(biāo)對比。通過本文介紹的思路,希望你可以將自己的機器學(xué)習(xí)技術(shù)提升到更高的水平。
審核編輯 :李倩
-
算法
+關(guān)注
關(guān)注
23文章
4710瀏覽量
95419 -
模型
+關(guān)注
關(guān)注
1文章
3521瀏覽量
50445 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8503瀏覽量
134649
原文標(biāo)題:收藏 | 機器學(xué)習(xí)模型調(diào)優(yōu)3大策略
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Nginx在企業(yè)環(huán)境中的調(diào)優(yōu)策略
機器學(xué)習(xí)模型市場前景如何
xgboost超參數(shù)調(diào)優(yōu)技巧 xgboost在圖像分類中的應(yīng)用
cmp在機器學(xué)習(xí)中的作用 如何使用cmp進行數(shù)據(jù)對比
MCF8316A調(diào)優(yōu)指南

MCT8316A調(diào)優(yōu)指南
MCT8315A調(diào)優(yōu)指南
AI大模型與傳統(tǒng)機器學(xué)習(xí)的區(qū)別
TDA3xx ISS調(diào)優(yōu)和調(diào)試基礎(chǔ)設(shè)施
大數(shù)據(jù)從業(yè)者必知必會的Hive SQL調(diào)優(yōu)技巧
智能調(diào)優(yōu),使步進電機安靜而高效地運行
MMC SW調(diào)優(yōu)算法
TAS58xx系列通用調(diào)優(yōu)指南





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論