 高效框架互操作性第3部分:使用E2E管道實現零拷貝
高效框架互操作性第3部分:使用E2E管道實現零拷貝

介紹
高效的管道設計對數據科學家至關重要。在編寫復雜的端到端工作流時,您可以從各種構建塊中進行選擇,每種構建塊都專門用于特定任務。不幸的是,在數據格式之間重復轉換容易出錯,而且會降低性能。讓我們改變這一點!
在本系列博客中,我們將討論高效框架互操作性的不同方面:
在第一個職位中,我們討論了不同內存布局以及異步內存分配的內存池的優缺點,以實現零拷貝功能。
在第二職位中,我們強調了數據加載/傳輸過程中出現的瓶頸,以及如何使用遠程直接內存訪問( RDMA )技術緩解這些瓶頸。
在本文中,我們將深入討論端到端管道的實現,展示所討論的跨數據科學框架的最佳數據傳輸技術。
要了解有關框架互操作性的更多信息,請查看我們在 NVIDIA 的 GTC 2021 年會議上的演示。
讓我們深入了解以下方面的全功能管道的實現細節:
從普通 CSV 文件解析 20 小時連續測量的電子 CTR 心電圖( ECG )。
使用傳統信號處理技術將定制 ECG 流無監督分割為單個心跳。
用于異常檢測的變分自動編碼器( VAE )的后續培訓。
結果的最終可視化。
對于前面的每個步驟,都使用了不同的數據科學庫,因此高效的數據轉換是一項至關重要的任務。最重要的是,在將數據從一個基于 GPU 的框架復制到另一個框架時,應該避免昂貴的 CPU 往返。
零拷貝操作:端到端管道
說夠了!讓我們看看框架的互操作性。在下面,我們將逐步討論端到端管道。如果你是一個不耐煩的人,你可以直接在這里下載完整的 Jupyter 筆記本。源代碼可以在最近的RAPIDS docker 容器中執行。
Getting started
In order to make it easier to have all those libraries up and running, we have used the RAPIDS 0.19 container on Ubuntu 18.04 as a base container, and then added a few missing libraries viapip install.
We encourage you to run this notebook on the latest RAPIDS container. Alternatively, you can also set up aconda virtual environment. In both cases, please visitRAPIDS release selectorfor installation details.
Finally, please find below the details of the container we used when creating this notebook . For reproducibility purposes, please use the following command:
foo@bar:~$ docker pull rapidsai/rapidsai-dev:21.06-cuda11.0-devel-ubuntu18.04-py3.7
foo@bar:~$ docker run --gpus all --rm -it -p 8888:8888 -p 8787:8787 -p 8786:8786 \
-v ~:/rapids/notebooks/host rapidsai/rapidsai-dev:21.06-cuda11.0-devel-ubuntu18.04-py3.7
步驟 1 :數據加載
在第一步中,我們下載 20 小時的 ele CTR 心電圖作為 CSV 文件,并將其寫入磁盤(見單元格 1 )。之后,我們解析 CSV 文件中的 500 MB 標量值,并使用 RAPIDS “ blazing fast CSV reader ”(參見單元格 2 )將其直接傳輸到 GPU 。現在,數據駐留在 GPU 上,并將一直保留到最后。接下來,我們使用cuxfilter( ku 交叉濾波器)框架繪制由 2000 萬個標量數據點組成的整個時間序列(見單元格 3 )。
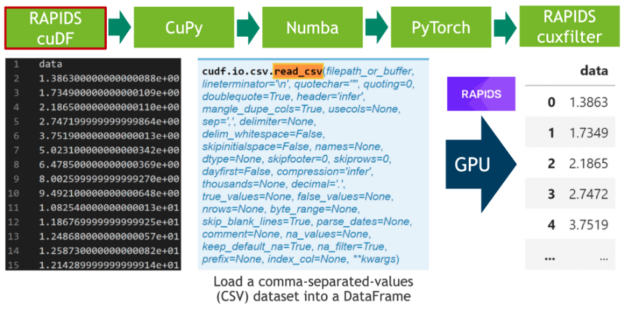
圖 1 :使用 RAPIDS CSV 解析器解析逗號分隔值( CSV )。
def retrieve_as_csv(url, root="./data"):
# local import because we will never see them again ;)
import os
import urllib
import zipfile
import numpy as np
from scipy.io import loadmat
filename = os.path.join(root, 'ECG_one_day.zip')
if not os.path.isdir(root):
os.makedirs(root)
if not os.path.isfile(filename):
urllib.request.urlretrieve(url, filename)
with zipfile.ZipFile(filename, 'r') as zip_ref:
zip_ref.extractall(root)
stream = loadmat(os.path.join(root, 'ECG_one_day','ECG.mat'))['ECG'].flatten()
csvname = os.path.join(root, 'heartbeats.csv')
if not os.path.isfile(csvname):
np.savetxt(csvname, stream[:-140000], delimiter=",", header="heartbeats", comments="")
# store the data as csv on disk
url = "https://www.cs.ucr.edu/~eamonn/ECG_one_day.zip"
retrieve_as_csv(url)
import cudf
heartbeats_cudf = cudf.read_csv("data/heartbeats.csv", dtype='float32')
heartbeats_cudf
| heartbeats | |
|---|---|
| 0 | -0.020 |
| 1 | -0.010 |
| 2 | -0.005 |
| 3 | -0.005 |
| 4 | -0.005 |
| ... | ... |
| 19999995 | -0.005 |
| 19999996 | 0.015 |
| 19999997 | 0.005 |
| 19999998 | -0.005 |
| 19999999 | 0.000 |
20000000 rows × 1 columns
Next, we will create a chart from theheartbeats_cudfDataFrame by making use of RAPIDScuxfilterlibrary.
We will get something similar to the following chart, but with a few nice features:
- The data is maintained in the GPU memory and operations like groupby aggregations, sorting and querying are done on the GPU itself, only returning the result as the output to the charts.
- The output is an interactive chart, facilitating data exploration.
import cuxfilter as cux
from cuxfilter.charts.datashader import line
# Chart width and height
WIDTH=600
HEIGHT=300
# 20 hours ECG look like a mess
heartbeats_cudf['x'] = heartbeats_cudf.index
line_cux = line(x='x', y='heartbeats', add_interaction=False)
_ = cux.DataFrame.from_dataframe(heartbeats_cudf).dashboard([line_cux])
line_cux.chart.title.text = 'ECG stream'
line_cux.chart.title.align = 'center'
line_cux.chart.width = WIDTH
line_cux.chart.height = HEIGHT
line_cux.view()[0]
步驟 2 :數據分割
在下一步中,我們使用傳統的信號處理技術將 20 小時的 ECG 分割成單個心跳。我們通過將 ECG 流與高斯分布的二階導數(也稱為里克爾小波)進行卷積來實現這一點,以便分離原型心跳中初始峰值的相應頻帶。使用 CuPy (一種 CUDA 加速的密集線性代數和陣列運算庫)可以方便地進行小波采樣和基于 FFT 的卷積運算。直接結果是,存儲 ECG 數據的 RAPIDS cuDF 數據幀必須使用 DLPack 作為零拷貝機制轉換為 CuPy 陣列。
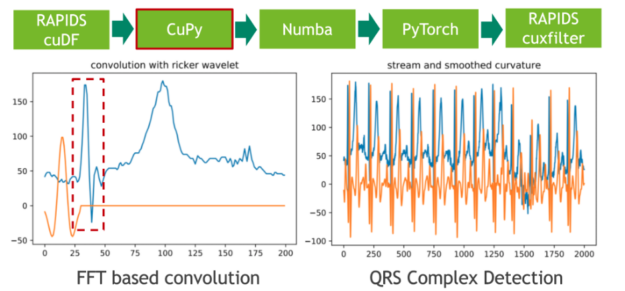
圖 2 :使用 CuPy 將 ele CTR 心圖( ECG )流與固定寬度的 Ricker 小波卷積。
卷積的特征響應(結果)測量流中每個位置的固定頻率內容的存在。請注意,我們選擇小波的方式使局部最大值對應于心跳的初始峰值。
view rawCell040506.ipynb hosted with ![]() by GitHub
by GitHub
步驟 3 :局部極大值檢測
在下一步中,我們使用非最大抑制( NMS )的 1D 變體將這些極值點映射到二進制門。 NMS 確定流中每個位置的對應值是否為預定義窗口(鄰域)中的最大值。這個令人尷尬的并行問題的 CUDA 實現非常簡單。在我們的示例中,我們使用即時編譯器 Numba 實現無縫的 Python 集成。 Numba 和 Cupy 都將 CUDA 陣列接口實現為零拷貝機制,因此可以完全避免從 Cupy 陣列到 Numba 設備陣列的顯式轉換。
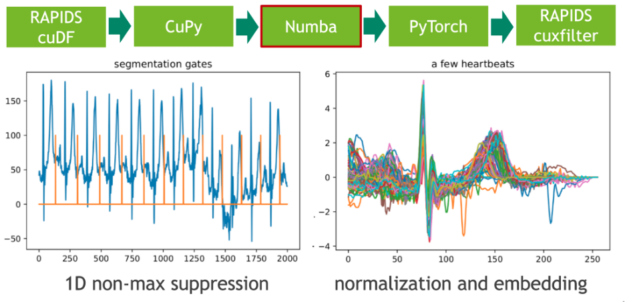
圖 3 :使用 Numba JIT 的 1D 非最大抑制和嵌入心跳。
每個心跳的長度是通過計算門位置的相鄰差分(有限階導數)來確定的。我們通過使用謂詞門== 1 過濾索引域,然后調用 cupy 。 diff ()來實現這一點。得到的直方圖描述了長度分布。
Inspecting heart beat lengths
The binary mask gate_cupy is 1 for each position that starts a heartbeat and 0 otherwise. Subsequently, we want to transform this dense representation with many zeroes to a sparse one where one only stores the indices in the stream that start a heartbeat. You could write a CUDA-kernel usingwarp-aggregated atomicsfor that purpose. In CuPy, however, this can be achieved easier by filtering the index domain with the predicate gate==1. An adjacent difference (discrete derivative cupy.diff) computes the heartbeat lengths as index distance between positive gate positions. Finally, the computed lengths are visualized in a histogram.
def indices_and_lengths_cupy(gate):
# all indices 0 1 2 3 4 5 6 ...
iota = cp.arange(len(gate))
# after filtering with gate==1 it becomes 3 6 10
indices = iota[gate == 1]
lengths = cp.diff(indices)
return indices, lengths
from cuxfilter.charts import bar
# inspect the segment lengths, we will later prune very long and short segments
indices_cupy, lengths_cupy = indices_and_lengths_cupy(gate_cupy)
# currently, cuxfilter doesn't support histogram chart with density=True,
# so we will create a histogram chart from a bar chart
BINS=30
lengths_hist_cupy = cp.histogram(lengths_cupy, bins=BINS, density=True)
hist_range = cp.max(lengths_cupy) - cp.min(lengths_cupy)
hist_width = int(hist_range/BINS)
lengths_cudf = cudf.DataFrame({'length': lengths_hist_cupy[0]})
lengths_cudf = lengths_cudf.loc[lengths_cudf.index.repeat(hist_width)]
lengths_cudf['x'] = cp.arange(0, BINS * hist_width) + cp.min(lengths_cupy)
bar_cux = bar(x='x', y='length', add_interaction=False)
_ = cux.DataFrame.from_dataframe(lengths_cudf).dashboard([bar_cux])
bar_cux.chart.title.text = 'Segment lengths'
bar_cux.chart.title.align = 'center'
bar_cux.chart.left[0].axis_label = ""
bar_cux.chart.width = WIDTH
bar_cux.chart.height = HEIGHT
bar_cux.view()[0]
步驟 4 :候選修剪和嵌入
我們打算使用固定長度的輸入矩陣在心跳集上訓練(卷積)變分自動編碼器( VAE )。用 CUDA 內核可以實現心跳信號在零向量中的嵌入。在這里,我們再次使用 Numba 進行候選修剪和嵌入。
Candidate pruning and embedding in fixed length vectors
In a later stage we intend to train a Variational Autoencoder (VAE) with fixed-length input and thus the heartbeats must be embedded in a data matrix of fixed shape. According to the histogram the majority of length is somewhere in the range between 100 and 250. The embedding is accomplished with Numba kernel. A warp of 32 consecutive threads works on each heartbeat. The first thread in a warp (leader) checks if the heartbeat exhibits a valid length and increments a row counter in an atomic manner to determine the output row in the data matrix. Subsequently, the target row is communicated to the remaining 31 threads in the warp using the warp-intrinsic shfl_sync (broadcast). In a final step, we (re-)use the threads in the warp to write the values to the output row in the data matrix in a warp-cyclic fashion (warp-stride loop). Finally, we plot a few of the zero-embedded heartbeats and observe approximate alignment of the QRS complex -- exactly what we wanted to achieve.
@cuda.jit
def zero_padding_kernel(signal, indices, counter, lower, upper, out):
"""using warp intrinsics to speedup the calcuation"""
for candidate in range(cuda.blockIdx.x, indices.shape[0]-1, cuda.gridDim.x):
length = indices[candidate+1]-indices[candidate]
# warp-centric: 32 threads process one signal
if lower <= length <= upper:
entry = 0
if cuda.threadIdx.x == 0:
# here we select in thread 0 what will be the target row
entry = cuda.atomic.add(counter, 0, 1)
# broadcast the target row to all other threads
# all 32 threads (warp) know the value
entry = cuda.shfl_sync(0xFFFFFFFF, entry, 0)
for index in range(cuda.threadIdx.x, upper, 32):
out[entry, index] = signal[indices[candidate]+index] if index < length else 0.0
def zero_padding_numba(signal, indices, lengths, lower=100, upper=256):
mask = (lower <= lengths) * (lengths <= upper)
num_entries = int(cp.sum(mask))
out = cp.empty((num_entries, upper), dtype=signal.dtype)
counter = cp.zeros(1).astype(cp.int64)
zero_padding_kernel[80*32, 32](signal, indices, counter, lower, upper, out)
cuda.synchronize()
print("removed", 100-100*num_entries/len(lengths), "percent of the candidates")
return out
# let's prune the short and long segments (heartbeats) and normalize them
data_cupy = zero_padding_numba(heartbeats_cupy, indices_cupy, lengths_cupy, lower=100, upper=256)
removed 3.3824004429883274 percent of the candidates
# looks good, they are approximately aligned
HEARTBEATS_SAMPLE = 10
data_cudf = cudf.DataFrame({'y_{}'.format(i):data_cupy[i] for i in range(HEARTBEATS_SAMPLE)})
data_cudf['x'] = cp.arange(0, data_cupy.shape[1])
data_cudf = data_cudf.astype('float64')
stacked_lines_cux = stacked_lines(x='x', y=['y_{}'.format(i) for i in range(HEARTBEATS_SAMPLE)],
legend=False, add_interaction=False,
colors = ["red", "grey", "black", "purple", "pink",
"yellow", "brown", "green", "orange", "blue"])
_ = cux.DataFrame.from_dataframe(data_cudf).dashboard([stacked_lines_cux])
stacked_lines_cux.chart.title.text = 'A few heartbeats'
stacked_lines_cux.chart.title.align = 'center'
stacked_lines_cux.chart.width = WIDTH
stacked_lines_cux.chart.height = HEIGHT
stacked_lines_cux.view()[0]
步驟 5 :異常值檢測
在這一步中,我們在 75% 的數據上訓練 VAE 模型。 DLPack 再次用作零拷貝機制,將 CuPy 數據矩陣映射到 PyTorch 張量。
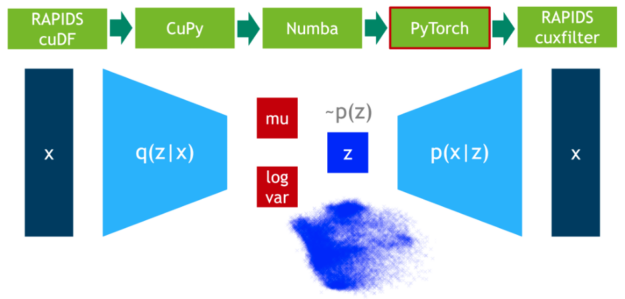
圖 4 :使用 PyTorch 訓練可變自動編碼器。
Installing PyTorch...
WARNING: Running pip as root will break packages and permissions. You should install packages reliably by using venv: https://pip.pypa.io/warnings/venv
Subsequently, we define the network topology. Here, we use a convolutional version but you could also experiment with a classicalMLP VAE.
import torch
class Swish(torch.nn.Module):
def __init__(self):
super().__init__()
self.alpha = torch.nn.Parameter(torch.tensor([1.0], requires_grad=True))
def forward(self, x):
return x*torch.sigmoid(self.alpha.to(x.device)*x)
class Downsample1d(torch.nn.Module):
def __init__(self):
super().__init__()
self.filter = torch.tensor([1.0, 2.0, 1.0]).view(1, 1, 3)
def forward(self, x):
w = torch.cat([self.filter]*x.shape[1], dim=0).to(x.device)
return torch.nn.functional.conv1d(x, w, stride=2, padding=1, groups=x.shape[1])
class LightVAE(torch.nn.Module):
def __init__(self, num_dims):
super(LightVAE, self).__init__()
self.num_dims = num_dims
assert num_dims & num_dims-1 == 0, "num_dims must be power of 2"
self.down = Downsample1d()
self.up = torch.nn.Upsample(scale_factor=2)
self.sigma = Swish()
self.conv0 = torch.nn.Conv1d(1, 2, kernel_size=3, stride=1, padding=1)
self.conv1 = torch.nn.Conv1d(2, 4, kernel_size=3, stride=1, padding=1)
self.conv2 = torch.nn.Conv1d(4, 8, kernel_size=3, stride=1, padding=1)
self.convA = torch.nn.Conv1d(8, 2, kernel_size=3, stride=1, padding=1)
self.convB = torch.nn.Conv1d(8, 2, kernel_size=3, stride=1, padding=1)
self.restore = torch.nn.Linear(2, 8*num_dims//8)
self.conv3 = torch.nn.Conv1d( 8, 4, kernel_size=3, stride=1, padding=1)
self.conv4 = torch.nn.Conv1d( 4, 2, kernel_size=3, stride=1, padding=1)
self.conv5 = torch.nn.Conv1d( 2, 1, kernel_size=3, stride=1, padding=1)
def encode(self, x):
x = x.view(-1, 1, self.num_dims)
x = self.down(self.sigma(self.conv0(x)))
x = self.down(self.sigma(self.conv1(x)))
x = self.down(self.sigma(self.conv2(x)))
return torch.mean(self.convA(x), dim=(2,)), \
torch.mean(self.convB(x), dim=(2,))
def reparameterize(self, mu, logvar):
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return mu + eps*std
def decode(self, z):
x = self.restore(z).view(-1, 8, self.num_dims//8)
x = self.sigma(self.conv3(self.up(x)))
x = self.sigma(self.conv4(self.up(x)))
return self.conv5(self.up(x)).view(-1, self.num_dims)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return self.decode(z), mu, logvar
# Reconstruction + KL divergence losses summed over all elements and batch
def loss_function(recon_x, x, mu, logvar):
MSE = torch.sum(torch.mean(torch.square(recon_x-x), dim=1))
# see Appendix B from VAE paper:
# Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014
# https://arxiv.org/abs/1312.6114
# 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KLD = -0.1 * torch.sum(torch.mean(1 + logvar - mu.pow(2) - logvar.exp(), dim=1))
return MSE + KLD
Pytorch expects its dedicated tensor type and thus we need to map the CuPy array data_cupy to a FloatTensor. We perform that again using zero-copy functionality via DLPack. The remaining code is plain Pytorch program that trains the VAE on the training set for 10 epochs using the Adam optimizer.
# zero-copy to pytorch tensors using dlpack
from torch.utils import dlpack
cp.random.seed(42)
cp.random.shuffle(data_cupy)
split = int(0.75*len(data_cupy))
trn_torch = dlpack.from_dlpack(data_cupy[:split].toDlpack())
tst_torch = dlpack.from_dlpack(data_cupy[split:].toDlpack())
dim = trn_torch.shape[1]
model = LightVAE(dim).to('cuda')
optimizer = torch.optim.Adam(model.parameters())
# let's train a VAE
NUM_EPOCHS = 10
BATCH_SIZE = 1024
trn_loader = torch.utils.data.DataLoader(trn_torch, batch_size=BATCH_SIZE, shuffle=True)
tst_loader = torch.utils.data.DataLoader(tst_torch, batch_size=BATCH_SIZE, shuffle=False)
model.train()
for epoch in range(NUM_EPOCHS):
trn_loss = 0.0
for data in trn_loader:
optimizer.zero_grad()
recon_batch, mu, logvar = model(data)
loss = loss_function(recon_batch, data, mu, logvar)
loss.backward()
trn_loss += loss.item()
optimizer.step()
print('====> Epoch: {} Average loss: {:.4f}'.format(
epoch, trn_loss / len(trn_loader.dataset)))
====> Epoch: 0 Average loss: 0.0186 ====> Epoch: 1 Average loss: 0.0077 ====> Epoch: 2 Average loss: 0.0066 ====> Epoch: 3 Average loss: 0.0063 ====> Epoch: 4 Average loss: 0.0061 ====> Epoch: 5 Average loss: 0.0060 ====> Epoch: 6 Average loss: 0.0059 ====> Epoch: 7 Average loss: 0.0059 ====> Epoch: 8 Average loss: 0.0058 ====> Epoch: 9 Average loss: 0.0058
步驟 6 :結果可視化
在最后一步中,我們可視化剩余 25% 數據的潛在空間。
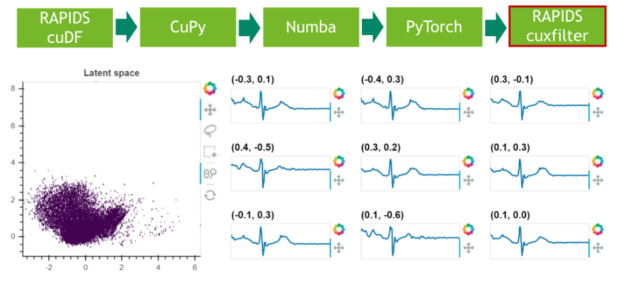
圖 5 :使用 RAPIDS cuxfilter 對潛在空間進行采樣和可視化。
Let's check if the test loss is in the same range:
# it will be used to visualize a scatter char
mu_cudf = cudf.DataFrame()
model.eval()
with torch.no_grad():
tst_loss = 0
for data in tst_loader:
recon_batch, mu, logvar = model(data)
tst_loss += loss_function(recon_batch, data, mu, logvar).item()
mu_cudf = mu_cudf.append(cudf.DataFrame(mu, columns=['x', 'y']))
tst_loss /= len(tst_loader.dataset)
print('====> Test set loss: {:.4f}'.format(tst_loss))
====> Test set loss: 0.0074
Finally, we visualize the latent space which is an approximate isotropic Gaussian centered around the origin:
from cuxfilter.charts import scatter
scatter_chart_cux = scatter(x='x', y='y', pixel_shade_type="linear",
legend=False, add_interaction=False)
_ = cux.DataFrame.from_dataframe(mu_cudf).dashboard([scatter_chart_cux])
scatter_chart_cux.chart.title.text = 'Latent space'
scatter_chart_cux.chart.title.align = 'center'
scatter_chart_cux.chart.width = WIDTH
scatter_chart_cux.chart.height = 2*HEIGHT
scatter_chart_cux.view()[0]
結論
從這篇和前面的博文中可以看出,互操作性對于設計高效的數據管道至關重要。在不同的框架之間復制和轉換數據是一項昂貴且極其耗時的任務,它為數據科學管道增加了零價值。數據科學工作負載變得越來越復雜,多個軟件庫之間的交互是常見的做法。 DLPack 和 CUDA 陣列接口是事實上的數據格式標準,保證了基于 GPU 的框架之間的零拷貝數據交換。
對外部內存管理器的支持是一個很好的特點,在評估您的管道將使用哪些軟件庫時要考慮。例如,如果您的任務同時需要數據幀和數組數據操作,那么最好選擇 RAPIDS cuDF + CuPy 庫。它們都受益于 GPU 加速,支持 DLPack 以零拷貝方式交換數據,并共享同一個內存管理器 RMM 。或者, RAPIDS cuDF + JAX 也是一個很好的選擇。然而,后一種組合 或許需要額外的開發工作來利用內存使用,因為 JAX 缺乏對外部內存分配器的支持。
在處理大型數據集時,數據加載和數據傳輸瓶頸經常出現。 NVIDIA GPU 直接技術起到了解救作用,它支持將數據移入或移出 GPU 內存,而不會加重 CPU 的負擔,并將不同節點上 GPU 之間傳輸數據時所需的數據副本數量減少到一個。
關于作者
Christian Hundt 在德國美因茨的 Johannes Gutenberg 大學( JGU )獲得了理論物理的文憑學位。在他的博士論文中,他研究了時間序列數據挖掘算法在大規模并行架構上的并行化。作為并行和分布式體系結構組的博士后研究員,他專注于各種生物醫學應用的高效并行化,如上下文感知的元基因組分類、基因集富集分析和胸部 mri 的深層語義圖像分割。他目前的職位是深度學習解決方案架構師,負責協調盧森堡的 NVIDIA 人工智能技術中心( NVAITC )的技術合作。
Miguel Martinez 是 NVIDIA 的高級深度學習數據科學家,他專注于 RAPIDS 和 Merlin 。此前,他曾指導過 Udacity 人工智能納米學位的學生。他有很強的金融服務背景,主要專注于支付和渠道。作為一個持續而堅定的學習者, Miguel 總是在迎接新的挑戰。
審核編輯:郭婷
-
編碼器
+關注
關注
45文章
3786瀏覽量
137580 -
NVIDIA
+關注
關注
14文章
5282瀏覽量
106041 -
gpu
+關注
關注
28文章
4925瀏覽量
130902
發布評論請先 登錄
干貨分享 | TSMaster AUTOSAR E2E使用說明

樂鑫 ESP32-C6 通過 Thread 1.4 互操作性認證


互操作性對智能家居的重要性






 工商網監
工商網監
評論