") 如何為深度學(xué)習(xí)模型設(shè)計(jì)審計(jì)方案
如何為深度學(xué)習(xí)模型設(shè)計(jì)審計(jì)方案

當(dāng)您購(gòu)買最后一輛車時(shí),您是否檢查了制造商的安全等級(jí)或質(zhì)量保證。也許,像大多數(shù)消費(fèi)者一樣,你只是去試駕看看這輛車是否提供了你想要的所有特性和功能,從舒適的座椅到電子控制。
審計(jì)和質(zhì)量保證是許多行業(yè)的規(guī)范。考慮汽車制造業(yè),在汽車生產(chǎn)之前,在安全性、舒適性、網(wǎng)絡(luò)化等方面進(jìn)行嚴(yán)格的測(cè)試,然后再將其部署到最終用戶。基于此,我們提出了一個(gè)問(wèn)題:“我們?nèi)绾螢?a target="_blank">深度學(xué)習(xí)模型設(shè)計(jì)一個(gè)類似動(dòng)機(jī)的審計(jì)方案?”
人工智能在現(xiàn)實(shí)世界的應(yīng)用中獲得了廣泛的成功。當(dāng)前的人工智能模型尤其是深度神經(jīng)網(wǎng)絡(luò),不需要對(duì)所需行為類型的精確說(shuō)明。相反,它們需要大量的數(shù)據(jù)集用于培訓(xùn),或者需要設(shè)計(jì)一個(gè)必須隨時(shí)間優(yōu)化的獎(jiǎng)勵(lì)函數(shù)。
雖然這種形式的隱式監(jiān)督提供了靈活性,但它通常會(huì)導(dǎo)致算法針對(duì)人類設(shè)計(jì)者不希望的行為進(jìn)行優(yōu)化。在許多情況下,它還會(huì)導(dǎo)致災(zāi)難性后果和安全關(guān)鍵應(yīng)用程序的故障,如自動(dòng)駕駛和醫(yī)療保健。
由于這些模型很容易失敗,特別是在域轉(zhuǎn)移的情況下,因此在部署之前知道它們 MIG ht 失敗的時(shí)間非常重要。隨著深度學(xué)習(xí)研究越來(lái)越與現(xiàn)實(shí)世界的應(yīng)用相結(jié)合,我們必須提出正式審核深度學(xué)習(xí)模型的方案。
語(yǔ)義一致的單元測(cè)試
審計(jì)中最大的挑戰(zhàn)之一是理解如何獲得對(duì)最終用戶直接有用的人類可解釋規(guī)范。我們通過(guò)一系列語(yǔ)義一致的單元測(cè)試解決了這個(gè)問(wèn)題。每個(gè)單元測(cè)試驗(yàn)證輸入空間中受控和語(yǔ)義對(duì)齊的變化(例如,在人臉識(shí)別中,相對(duì)于相機(jī)的角度)是否滿足預(yù)定義規(guī)范(例如,精度超過(guò) 95% )。
我們通過(guò)直接驗(yàn)證生成模型的可解釋潛在空間中的語(yǔ)義對(duì)齊變化來(lái)執(zhí)行這些單元測(cè)試。我們的框架 AuditAI 彌補(bǔ)了軟件系統(tǒng)可解釋形式驗(yàn)證和深度神經(jīng)網(wǎng)絡(luò)可伸縮性之間的差距。
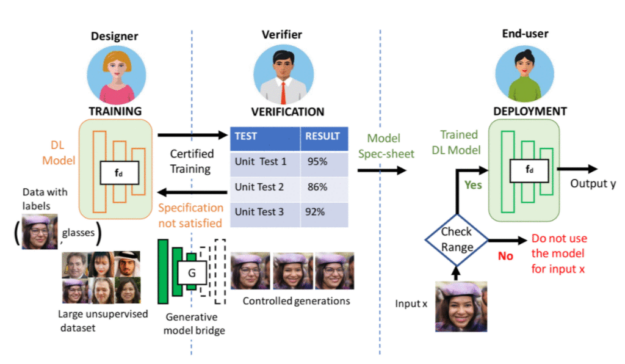
圖 1 。 AI 從項(xiàng)目到部署的一般機(jī)器學(xué)習(xí)過(guò)程。
考慮一個(gè)典型的機(jī)器學(xué)習(xí)生產(chǎn)流水線三方:部署模型的最終用戶、驗(yàn)證者和模型設(shè)計(jì)器。驗(yàn)證器在驗(yàn)證設(shè)計(jì)者的模型是否滿足最終用戶的需求方面起著關(guān)鍵作用。例如,單元測(cè)試 1 可以驗(yàn)證當(dāng)人臉角度在d度范圍內(nèi)時(shí),給定的人臉?lè)诸惸P褪欠癖3?95% 以上的準(zhǔn)確性。單元測(cè)試 2 可以檢查模型在何種照明條件下的準(zhǔn)確度超過(guò) 86% 。驗(yàn)證之后,最終用戶可以使用驗(yàn)證過(guò)的規(guī)范來(lái)確定在部署期間是否使用經(jīng)過(guò)培訓(xùn)的 DL 模型。
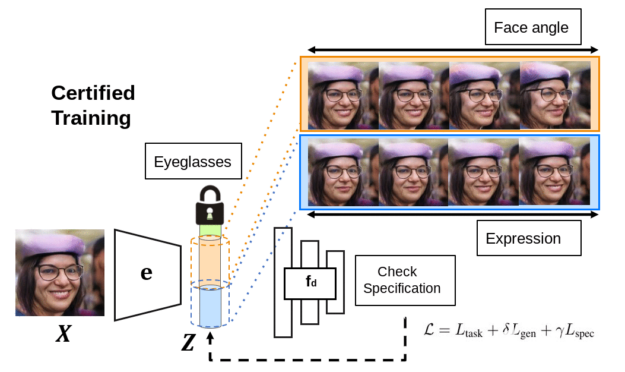
圖 2 。 Deep networks 接受認(rèn)證培訓(xùn),以確保可能滿足單元測(cè)試。
經(jīng)驗(yàn)證的部署
為了驗(yàn)證深層網(wǎng)絡(luò)的語(yǔ)義一致性,我們使用生成模型將其連接起來(lái),這樣它們共享相同的潛在空間和將輸入投射到潛在代碼的相同編碼器。除了驗(yàn)證單元測(cè)試是否滿足要求外,我們還可以執(zhí)行認(rèn)證培訓(xùn),以確保單元測(cè)試可能首先滿足要求。該框架具有吸引人的理論性質(zhì),我們?cè)诒疚闹姓故玖巳绾伪WC驗(yàn)證者能夠生成驗(yàn)證是真是假的證明。有關(guān)更多信息,請(qǐng)參閱語(yǔ)義規(guī)范[LINK]下的審核 AI 模型以驗(yàn)證部署。
與 AuditAI 相比,基于像素的擾動(dòng)的神經(jīng)網(wǎng)絡(luò)驗(yàn)證和認(rèn)證訓(xùn)練涵蓋的潛在空間語(yǔ)義變化范圍要小得多。為了進(jìn)行定量比較,對(duì)于相同的驗(yàn)證誤差,我們將像素綁定到潛在空間,并將其與 AuditAI 的潛在空間綁定進(jìn)行比較。我們表明,在相同的驗(yàn)證誤差下, AuditAI 可以容忍比基于像素的對(duì)應(yīng)項(xiàng)(通過(guò) L2 范數(shù)測(cè)量)大 20% 左右的潛在變化。對(duì)于實(shí)現(xiàn)和實(shí)驗(yàn),我們使用 NVIDIA V100 GPU s 和 Python 以及 PyTorch 庫(kù)。
我們展示了與潛在空間中受控變化相對(duì)應(yīng)的生成輸出的定性結(jié)果。頂行顯示 AuditAI 的可視化,底行顯示 ImageNet 上 hen 類圖像、肺炎胸部 X 射線圖像和不同微笑程度的人臉的像素?cái)_動(dòng)可視化。從可視化中可以明顯看出,更廣泛的潛在變化對(duì)應(yīng)于生成的輸出中更廣泛的語(yǔ)義變化。
今后的工作
在本文中,我們開(kāi)發(fā)了一個(gè)深度學(xué)習(xí)( DL )模型審計(jì)框架。越來(lái)越多的人開(kāi)始關(guān)注 DL 模型中的固有偏見(jiàn),這些模型部署在廣泛的環(huán)境中,并且有多篇關(guān)于部署前審核 DL 模型的必要性的新聞文章。我們的框架將這個(gè)審計(jì)問(wèn)題形式化,我們認(rèn)為這是在部署期間提高 DL 模型的安全性和道德使用的一個(gè)步驟。
AuditAI 的局限性之一是其可解釋性受到內(nèi)置生成模型的限制。雖然在生成模型方面已經(jīng)取得了令人振奮的進(jìn)展,但我們認(rèn)為,在培訓(xùn)和部署過(guò)程中,整合領(lǐng)域?qū)I(yè)知識(shí)以減少潛在的數(shù)據(jù)集偏差和人為錯(cuò)誤非常重要。
目前, AuditAI 沒(méi)有將人類領(lǐng)域?qū)<抑苯蛹傻綄徲?jì)管道中。它間接地使用領(lǐng)域?qū)I(yè)知識(shí)來(lái)管理用于創(chuàng)建生成模型的數(shù)據(jù)集。納入前者將是今后工作的一個(gè)重要
關(guān)于作者
Homanga Bharadhwaj 是卡內(nèi)基梅隆大學(xué)計(jì)算機(jī)科學(xué)學(xué)院機(jī)器人研究所的博士生。他以前是多倫多大學(xué)和向量研究所的 MSC 學(xué)生,也是 IIT 坎普爾的一名本科生。這篇文章所涉及的工作是在 Homanga 在 NVIDIA 實(shí)習(xí)研究期間完成的。
Animesh Garg 是多倫多大學(xué)計(jì)算機(jī)科學(xué)助理教授 CVK3 NVIDIA 的資深研究科學(xué)家,也是向量研究所的一名教員。他在加州大學(xué)伯克利分校獲得博士學(xué)位,是斯坦福人工智能實(shí)驗(yàn)室的博士后。他致力于廣義自治的算法基礎(chǔ),使基于人工智能的機(jī)器人能夠與人類一起工作。他的工作在機(jī)器人學(xué)和機(jī)器學(xué)習(xí)領(lǐng)域獲得了多項(xiàng)研究獎(jiǎng)。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5309瀏覽量
106457 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5561瀏覽量
122811
發(fā)布評(píng)論請(qǐng)先 登錄
大模型時(shí)代的深度學(xué)習(xí)框架

用樹(shù)莓派搞深度學(xué)習(xí)?TensorFlow啟動(dòng)!

在OpenVINO?工具套件的深度學(xué)習(xí)工作臺(tái)中無(wú)法導(dǎo)出INT8模型怎么解決?
中軟國(guó)際審計(jì)智能體平臺(tái)接入DeepSeek滿血版大模型
廣和通正式推出AI玩具大模型解決方案
廣和通推出AI玩具大模型解決方案
Flexus X 實(shí)例 ultralytics 模型 yolov10 深度學(xué)習(xí) AI 部署與應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論