 使用NVIDIA開源模型實現更快的訓練和推理
使用NVIDIA開源模型實現更快的訓練和推理
SE(3)-Transformers 是在NeurIPS 2020上推出的多功能圖形神經網絡。 NVIDIA 剛剛發布了一款開源優化實現,它使用的內存比基線正式實施少9倍,速度比基線正式實施快21倍。
SE(3)-Transformer 在處理幾何對稱性問題時非常有用,如小分子處理、蛋白質精制或點云應用。它們可以是更大的藥物發現模型的一部分,如RoseTTAFold和此 AlphaFold2 的復制。它們也可以用作點云分類和分子性質預測的獨立網絡(圖 1 )。
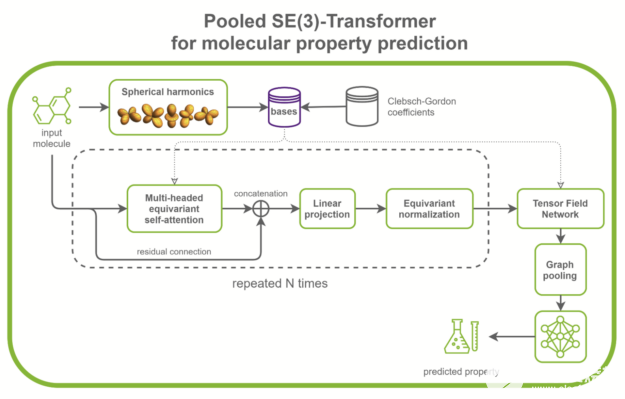
圖 1 用于分子性質預測的典型 SE ( 3 ) – transformer 的結構。
在/PyTorch/DrugDiscovery/SE3Transformer存儲庫中, NVIDIA 提供了在QM9 數據集上為分子性質預測任務訓練優化模型的方法。 QM9 數據集包含超過 10 萬個有機小分子和相關的量子化學性質。
訓練吞吐量提高 21 倍
與基線實施相比, NVIDIA 實現提供了更快的訓練和推理。該實現對 SE(3)-Transformers 的核心組件,即張量場網絡( TFN )以及圖形中的自我注意機制進行了優化。
考慮到注意力層超參數的某些條件得到滿足,這些優化大多采取操作融合的形式。
由于這些,與基線實施相比,訓練吞吐量增加了 21 倍,利用了最近 GPU NVIDIA 上的張量核。
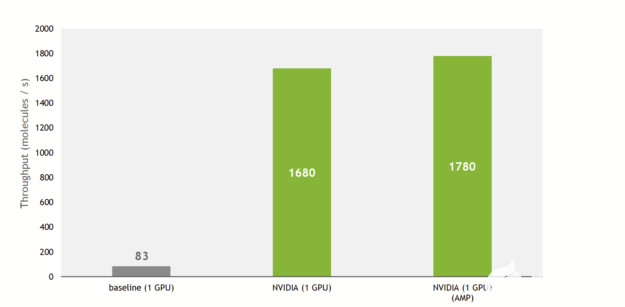
圖 2 A100 GPU 上的訓練吞吐量。批次大小為 100 的 QM9 數據集。
此外, NVIDIA 實現允許使用多個 GPU 以數據并行方式訓練模型,充分利用 DGX A100 ( 8x A100 80GB )的計算能力。
把所有東西放在一起,在 NVIDIA DGX A100 上, SE(3)-Transformer現在可以在 QM9 數據集上在 27 分鐘內進行訓練。作為比較,原始論文的作者指出,培訓在硬件上花費了 2 。 5 天( NVIDIA GeForce GTX 1080 Ti )。
更快的培訓使您能夠在搜索最佳體系結構的過程中快速迭代。隨著內存使用率的降低,您現在可以訓練具有更多注意層或隱藏通道的更大模型,并向模型提供更大的輸入。
內存占用率降低 9 倍
SE(3)-Transformer 是已知的記憶重模型,這意味著喂養大輸入,如大蛋白質或許多分批小分子是一項挑戰。對于 GPU 內存有限的用戶來說,這是一個瓶頸。
這一點在DeepLearningExamples上的 NVIDIA 實現中已經改變。圖 3 顯示,由于 NVIDIA 優化和對混合精度的支持,與基線實現相比,訓練內存使用減少了 9 倍。
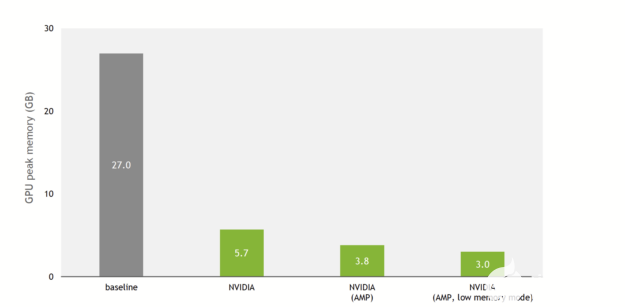
圖 3 SE ( 3 ) – transformer s 的基線實現和 NVIDIA 實現之間的訓練峰值內存消耗比較。在 QM9 數據集上每批使用 100 個分子。 V100 32-GB GPU 。
除了對單精度和混合精度進行改進外,還提供了低內存模式。啟用此標志后,模型在 TF32 ( NVIDIA 安培體系結構)或 FP16 ( NVIDIA 安培體系結構、 NVIDIA 圖靈體系結構和 NVIDIA 伏特體系結構)精度上運行,模型將切換到以吞吐量換取額外內存節省的模式。
實際上,在具有 V100 32-GB GPU 的 QM9 數據集上,基線實現可以在內存耗盡之前擴展到 100 的批大小。 NVIDIA 實現每批最多可容納 1000 個分子(混合精度,低內存模式)。
對于處理以氨基酸殘基為節點的蛋白質的研究人員來說,這意味著你可以輸入更長的序列并增加每個殘基的感受野。
SE(3)-Transformers 優化
與基線相比, NVIDIA 實現提供了一些優化。
融合鍵與值計算
在“自我注意”層中,將計算關鍵幀、查詢和值張量。查詢是圖形節點特征,是輸入特征的線性投影。另一方面,鍵和值是圖形邊緣特征。它們是使用 TFN 層計算的。這是 SE(3)-Transformer 中大多數計算發生的地方,也是大多數參數存在的地方。
基線實現使用兩個獨立的 TFN 層來計算鍵和值。在 NVIDIA 實現中,這些被融合在一個 TFN 中,通道數量增加了一倍。這將啟動的小型 CUDA 內核數量減少一半,并更好地利用 GPU 并行性。徑向輪廓是 TFN 內部完全連接的網絡,也與此優化融合。概覽如圖 4 所示。
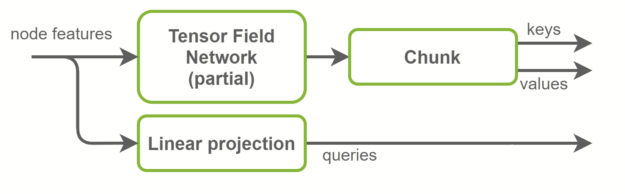
圖 4 NVIDIA 實現中的鍵、查詢和值計算。鍵和值一起計算,然后沿通道維度分塊。
TFN 合并
SE(3)-Transformer 內部的功能除了其通道數量外,還有一個degreed,它是一個正整數。程度特征d有維度2d+1. TFN 接受不同程度的特征,使用張量積組合它們,并輸出不同程度的特征。
對于輸入為 4 度、輸出為 4 度的圖層,將考慮所有度的組合:理論上,必須計算 4 × 4 = 16 個子圖層。
這些子層稱為成對 TFN 卷積。圖 5 顯示了所涉及的子層的概述,以及每個子層的輸入和輸出維度。對給定輸出度(列)的貢獻相加,以獲得最終特征。
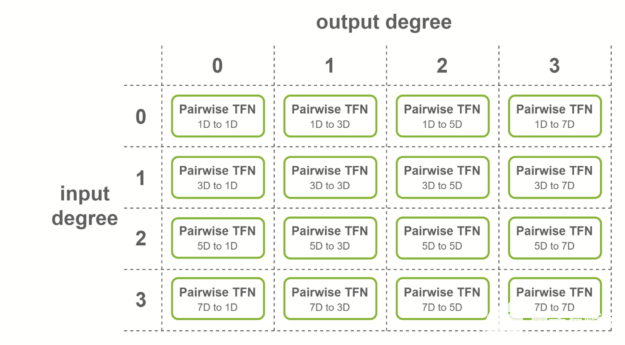
圖 5 TFN 層中涉及的成對卷積,輸入為 4 度,輸出為 4 度。
NVIDIA 在滿足 TFN 層上的某些條件時,提供多級融合以加速這些卷積。通過創建尺寸為 16 倍的形狀,熔合層可以更有效地使用張量核。以下是應用熔合卷積的三種情況:
輸出功能具有相同數量的通道
輸入功能具有相同數量的通道
這兩種情況都是正確的
第一種情況是,所有輸出特征具有相同數量的通道,并且輸出度數的范圍從 0 到最大度數。在這種情況下,使用輸出融合特征的融合卷積。該融合層用于 SE(3)-Transformers 的第一個 TFN 層。
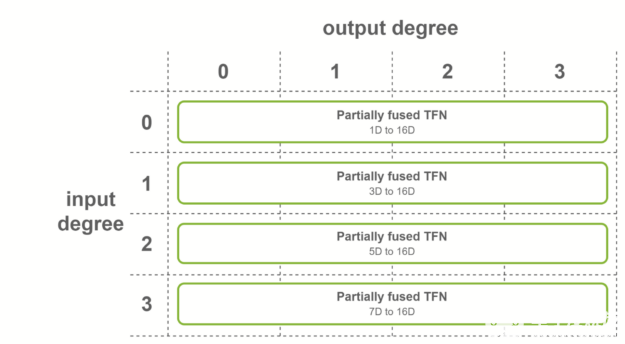
圖 6 每個輸出度的部分熔融 TFN 。
第二種情況是,所有輸入特征具有相同數量的通道,并且輸入度數的范圍從 0 到最大度數。在這種情況下,使用對融合輸入特征進行操作的融合卷積。該融合層用于 SE(3)-Transformers 的最后一層 TFN 。
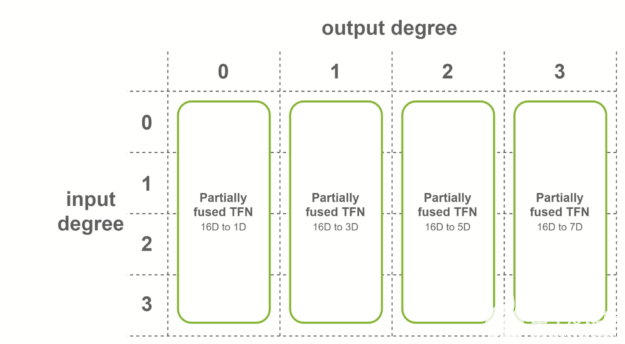
圖 7 每個輸入度的部分熔融 TFN 。
在最后一種情況下,當兩個條件都滿足時,使用完全融合的卷積。這些卷積作為輸入融合特征,輸出融合特征。這意味著每個 TFN 層只需要一個子層。內部 TFN 層使用此融合級別。
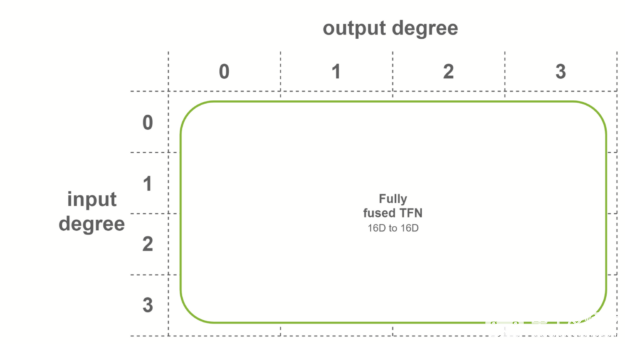
圖 8 全熔合 TFN
基預計算
除了輸入節點特性外, TFN 還需要基矩陣作為輸入。每個圖邊都有一組矩陣,這些矩陣取決于目標節點和源節點之間的相對位置。
在基線實現中,這些矩陣在前向傳遞開始時計算,并在所有 TFN 層中共享。它們依賴于球形 h ARM ,計算起來可能很昂貴。由于輸入圖不會隨著 QM9 數據集而改變(沒有數據擴充,沒有迭代位置細化),這就引入了跨時代的冗余計算。
NVIDIA 實現提供了在培訓開始時預計算這些基礎的選項。整個數據集迭代一次,基緩存在 RAM 中。前向傳遞開始時的計算基數過程被更快的 CPU 到 GPU 內存拷貝所取代。
關于作者
Alexandre Milesi 是 NVIDIA 的深度學習算法工程師。他擁有法國 UTC 的機器學習碩士學位,以及法國索邦大學的機器人和多智能體系統碩士學位。在加入 NVIDIA 之前, Alexandre 是伯克利實驗室的附屬研究員,使用深度強化學習解決電子 CTR ical 網格問題。在 NVIDIA ,他的工作集中于藥物發現和計算機視覺的 DL 算法,包括等變圖神經網絡。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5274瀏覽量
105936 -
機器學習
+關注
關注
66文章
8497瀏覽量
134227 -
深度學習
+關注
關注
73文章
5557瀏覽量
122581
發布評論請先 登錄
在阿里云PAI上快速部署NVIDIA Cosmos Reason-1模型
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
英偉達GTC2025亮點 NVIDIA推出Cosmos世界基礎模型和物理AI數據工具的重大更新
英偉達GTC25亮點:NVIDIA Dynamo開源庫加速并擴展AI推理模型
NVIDIA發布全球首個開源人形機器人基礎模型Isaac GR00T N1
NVIDIA 推出開放推理 AI 模型系列,助力開發者和企業構建代理式 AI 平臺

YOLOv5類中rgb888p_size這個參數要與模型推理和訓練的尺寸一致嗎?一致會達到更好的效果?
壁仞科技支持DeepSeek-V3滿血版訓練推理
Qwen大模型助力開發低成本AI推理方案
阿里云開源推理大模型QwQ
NVIDIA助力麗蟾科技打造AI訓練與推理加速解決方案

NVIDIA助力提供多樣、靈活的模型選擇
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據






 工商網監
工商網監
評論