") 使用NVIDIA Triton模型分析器確定最佳AI模型服務(wù)配置
使用NVIDIA Triton模型分析器確定最佳AI模型服務(wù)配置
模型部署是 機(jī)器學(xué)習(xí) 生命周期的一個(gè)關(guān)鍵階段,在此階段,經(jīng)過(guò)培訓(xùn)的模型將集成到現(xiàn)有的應(yīng)用程序生態(tài)系統(tǒng)中。這往往是最繁瑣的步驟之一,在這些步驟中,目標(biāo)硬件平臺(tái)應(yīng)滿足各種應(yīng)用程序和生態(tài)系統(tǒng)約束,所有這些都不會(huì)影響模型的準(zhǔn)確性。
NVIDIA Triton 推理服務(wù)器 是一個(gè)開(kāi)源的模型服務(wù)工具,它簡(jiǎn)化了推理,并具有多個(gè)功能以最大限度地提高硬件利用率和推理性能。這包括以下功能:
并發(fā)模型執(zhí)行 ,使同一模型的多個(gè)實(shí)例能夠在同一系統(tǒng)上并行執(zhí)行。
Dynamic batching ,其中客戶端請(qǐng)求在服務(wù)器上分組,以形成更大的批。
優(yōu)化模型部署時(shí),需要做出幾個(gè)關(guān)鍵決策:
為了最大限度地提高利用率, NVIDIA Triton 應(yīng)在同一 CPU / GPU 上同時(shí)運(yùn)行多少個(gè)模型實(shí)例?
應(yīng)將多少傳入的客戶端請(qǐng)求動(dòng)態(tài)批處理在一起?
模型應(yīng)采用哪種格式?
應(yīng)以何種精度計(jì)算輸出?
這些關(guān)鍵決策導(dǎo)致了組合爆炸,每種型號(hào)和硬件選擇都有數(shù)百種可能的配置。通常,這會(huì)導(dǎo)致浪費(fèi)開(kāi)發(fā)時(shí)間或代價(jià)高昂的低于標(biāo)準(zhǔn)的服務(wù)決策。
在本文中,我們將探討 NVIDIA Triton 型號(hào)分析儀 可以自動(dòng)瀏覽目標(biāo)硬件平臺(tái)的各種服務(wù)配置,并根據(jù)應(yīng)用程序的需要找到最佳型號(hào)配置。這可以提高開(kāi)發(fā)人員的生產(chǎn)率,同時(shí)提高服務(wù)硬件的利用率。
NVIDIA Triton 型號(hào)分析儀
NVIDIA Triton Model Analyzer 是一個(gè)多功能 CLI 工具,有助于更好地了解通過(guò) NVIDIA Triton 推理服務(wù)器提供服務(wù)的模型的計(jì)算和內(nèi)存需求。這使您能夠描述不同配置之間的權(quán)衡,并為您的用例選擇最佳配置。
NVIDIA Triton 模型分析器可用于 NVIDIA Triton 推理服務(wù)器支持的所有模型格式: TensorRT 、 TensorFlow 、 PyTorch 、 ONNX 、 OpenVINO 和其他。
您可以指定應(yīng)用程序約束(延遲、吞吐量或內(nèi)存),以找到滿足這些約束的服務(wù)配置。例如,虛擬助理應(yīng)用程序可能有一定的延遲預(yù)算,以便最終用戶能夠?qū)崟r(shí)感受到交互。脫機(jī)處理工作流應(yīng)針對(duì)吞吐量進(jìn)行優(yōu)化,以減少所需硬件的數(shù)量,并盡可能降低成本。模型服務(wù)硬件中的可用內(nèi)存可能受到限制,并且需要針對(duì)內(nèi)存優(yōu)化服務(wù)配置。
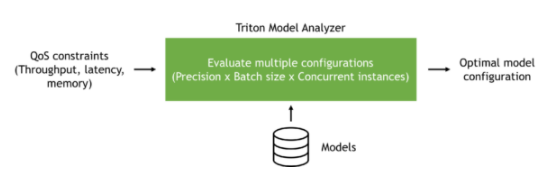
圖 1 :NVIDIA Triton 型號(hào)分析器概述。
我們以一個(gè)預(yù)訓(xùn)練模型為例,展示了如何使用 NVIDIA Triton 模型分析器,并在 Google 云平臺(tái)上的 VM 實(shí)例上優(yōu)化該模型的服務(wù)。然而,這里顯示的步驟可以在任何公共云上使用,也可以在具有 NVIDIA Triton 推理服務(wù)器支持的任何模型類型的前提下使用。
創(chuàng)建模型
在這篇文章中,我們使用預(yù)訓(xùn)練 BERT Hugging Face 的大型模型,采用 PyTorch 格式。 NVIDIA Triton 推理服務(wù)器可以使用其LibTorch后端為T(mén)orchScript模型提供服務(wù),也可以使用其 Python 后端為純 PyTorch 模型提供服務(wù)。為了獲得最佳性能,我們建議將 PyTorch 模型轉(zhuǎn)換為T(mén)orchScript格式。為此,請(qǐng)使用PyTorch的跟蹤功能。
首先從 NGC 中拉出 PyTorch 容器,然后在容器中安裝transformers包。如果這是您第一次使用 NGC ,請(qǐng)創(chuàng)建一個(gè)帳戶。在本文中,我們使用了 22.04 版本的相關(guān)工具,這是撰寫(xiě)本文時(shí)的最新版本。 NVIDIA ( NVIDIA ) Triton 每月發(fā)布一次 cadence ,并在每個(gè)月底發(fā)布新版本。
docker pull nvcr.io/nvidia/pytorch:22.04-py3 docker run --rm -it -v $(pwd):/workspace nvcr.io/nvidia/pytorch:22.04-py3 /bin/bash pip install transformers
安裝transformers包后,運(yùn)行以下 Python 代碼下載預(yù)訓(xùn)練的 BERT 大型模型,并將其跟蹤為 TorchScript 格式。
from transformers import BertModel, BertTokenizer import torch model_name = "bert-large-uncased" tokenizer = BertTokenizer.from_pretrained(model_name) model = BertModel.from_pretrained(model_name, torchscript=True) max_seq_len = 512 sample = "This is a sample input text" tokenized = tokenizer(sample, return_tensors="pt", max_length=max_seq_len, padding="max_length", truncation=True) inputs = (tokenized.data['input_ids'], tokenized.data['attention_mask'], tokenized.data['token_type_ids']) traced_model = torch.jit.trace(model, inputs) traced_model.save("model.pt")
構(gòu)建模型存儲(chǔ)庫(kù)
使用 NVIDIA Triton 推理服務(wù)器為您的模型提供服務(wù)的第一步是創(chuàng)建模型存儲(chǔ)庫(kù)。在此存儲(chǔ)庫(kù)中,您將包括一個(gè)模型配置文件,該文件提供有關(guān)模型的信息。模型配置文件至少必須指定后端、模型的最大批大小以及輸入/輸出結(jié)構(gòu)。
對(duì)于這個(gè)模型,下面的代碼示例是模型配置文件。
platform: "pytorch_libtorch"
max_batch_size: 64
input [ { name: "INPUT__0" data_type: TYPE_INT64 dims: [ 512 ] }, { name: "INPUT__1" data_type: TYPE_INT64 dims: [ 512 ] }, { name: "INPUT__2" data_type: TYPE_INT64 dims: [ 512 ] }
]
output [ { name: "OUTPUT__0" data_type: TYPE_FP32 dims: [ -1, 1024 ] }, { name: "OUTPUT__1" data_type: TYPE_FP32 dims: [ 1024 ] }
]
將模型配置文件命名為config.pbtxt后,按照 存儲(chǔ)庫(kù)布局結(jié)構(gòu) 創(chuàng)建模型存儲(chǔ)庫(kù)。模型存儲(chǔ)庫(kù)的文件夾結(jié)構(gòu)應(yīng)類似于以下內(nèi)容:
. └── bert-large ├── 1 │ └── model.pt └── config.pbtxt
運(yùn)行 NVIDIA Triton 型號(hào)分析器
建議使用 Model Analyzer 的方法是自己構(gòu)建 Docker 映像:
git clone https://github.com/triton-inference-server/model_analyzer.git cd ./model_analyzer git checkout r22.04 docker build --pull -t model-analyzer .
現(xiàn)在已經(jīng)構(gòu)建了 Model Analyzer 映像,請(qǐng)旋轉(zhuǎn)容器:
docker run -it --rm --gpus all \ -v /var/run/docker.sock:/var/run/docker.sock \ -v:/models \ -v :/output \ -v :/config \ --net=host model-analyzer
不同的硬件配置可能會(huì)導(dǎo)致不同的最佳服務(wù)配置。因此,在最終提供模型的目標(biāo)硬件平臺(tái)上運(yùn)行模型分析器非常重要。
為了重現(xiàn)我們?cè)谶@篇文章中給出的結(jié)果,我們?cè)诠苍浦羞M(jìn)行了實(shí)驗(yàn)。具體來(lái)說(shuō),我們?cè)?Google 云平臺(tái)上使用了一個(gè) a2-highgpu-1g 實(shí)例,并使用了一個(gè) NVIDIA A100 GPU 。
A100 GPU 支持多實(shí)例 GPU ( MIG ),它可以通過(guò)將單個(gè) A100 GPU 拆分為七個(gè)分區(qū)來(lái)最大限度地提高 GPU 利用率,這些分區(qū)具有硬件級(jí)隔離,可以獨(dú)立運(yùn)行 NVIDIA Triton 服務(wù)器。為了簡(jiǎn)單起見(jiàn),我們?cè)谶@篇文章中沒(méi)有使用 MIG 。
Model Analyzer 支持 NVIDIA Triton 型號(hào)的自動(dòng)和手動(dòng)掃描不同配置。自動(dòng)配置搜索是默認(rèn)行為,并為所有配置啟用 dynamic batching 。在這種模式下,模型分析器將掃描不同的批大小和可以同時(shí)處理傳入請(qǐng)求的模型實(shí)例數(shù)。
掃掠的默認(rèn)范圍是最多五個(gè)模型實(shí)例和最多 128 個(gè)批次大小。這些 可以更改默認(rèn)值 。
現(xiàn)在創(chuàng)建一個(gè)名為sweep.yaml的配置文件,以分析前面準(zhǔn)備的 BERT 大型模型,并自動(dòng)掃描可能的配置。
model_repository: /models checkpoint_directory: /output/checkpoints/ output-model-repository-path: /output/bert-large profile_models: bert-large perf_analyzer_flags: input-data: "zero"
使用前面的配置,您可以分別獲得模型吞吐量和延遲的頂行號(hào)和底行號(hào)。
分析時(shí),模型分析器還將收集的測(cè)量值寫(xiě)入檢查點(diǎn)文件。它們位于指定的檢查點(diǎn)目錄中。您可以使用分析的檢查點(diǎn)創(chuàng)建數(shù)據(jù)表、摘要和結(jié)果的詳細(xì)報(bào)告。
配置文件就緒后,您現(xiàn)在可以運(yùn)行 Model Analyzer 了:
model-analyzer profile -f /config/sweep.yaml
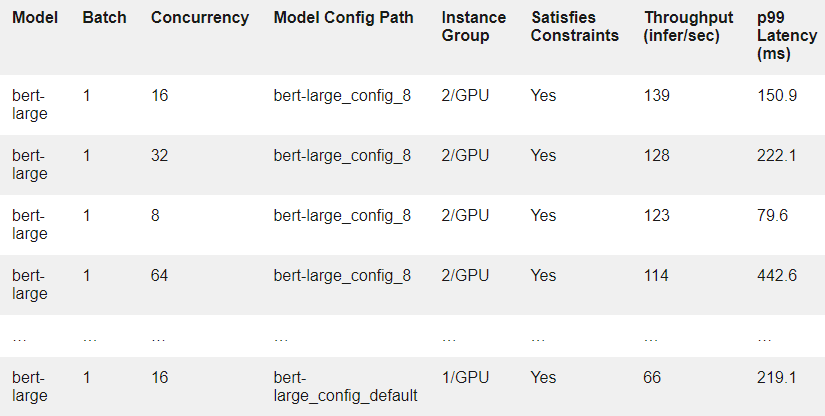
作為示例,表 1 顯示了結(jié)果中的幾行。每一行對(duì)應(yīng)于在假設(shè)的客戶端負(fù)載下在模型配置上運(yùn)行的實(shí)驗(yàn)。
要獲得測(cè)試的每個(gè)模型配置的更詳細(xì)報(bào)告,請(qǐng)使用model-analyzer report命令:
model-analyzer report --report-model-configs bert-large_config_default,bert-large_config_1,bert-large_config_2 --export-path /output --config-file /config/sweep.yaml --checkpoint-directory /output/checkpoints/
這將生成一個(gè)詳細(xì)說(shuō)明以下內(nèi)容的報(bào)告:
運(yùn)行分析的硬件
吞吐量與延遲的關(guān)系圖
GPU 內(nèi)存與延遲的關(guān)系圖
CLI 中所選配置的報(bào)告
對(duì)于任何 MLOps 團(tuán)隊(duì)來(lái)說(shuō),在將模型投入生產(chǎn)之前開(kāi)始分析都是一個(gè)很好的開(kāi)始。
不同的利益相關(guān)者,不同的約束條件
在典型的生產(chǎn)環(huán)境中,有多個(gè)團(tuán)隊(duì)?wèi)?yīng)該協(xié)同工作,以便在生產(chǎn)中大規(guī)模部署 AI 模型。例如,可能有一個(gè) MLOps 團(tuán)隊(duì)負(fù)責(zé)為管道穩(wěn)定性服務(wù)的模型,并處理應(yīng)用程序強(qiáng)加的服務(wù)級(jí)別協(xié)議( SLA )中的更改。另外,基礎(chǔ)架構(gòu)團(tuán)隊(duì)通常負(fù)責(zé)整個(gè) GPU / CPU 場(chǎng)。
假設(shè)一個(gè)產(chǎn)品團(tuán)隊(duì)要求 MLOps 團(tuán)隊(duì)在 30 毫秒的延遲預(yù)算內(nèi)處理 99% 的請(qǐng)求,為 BERT 大型服務(wù)器提供服務(wù)。 MLOps 團(tuán)隊(duì)?wèi)?yīng)考慮可用硬件上的各種服務(wù)配置,以滿足該要求。使用 Model Analyzer 可以消除執(zhí)行此操作時(shí)的大部分摩擦。
下面的代碼示例是一個(gè)名為latency_constraint.yaml的配置文件的示例,其中我們?cè)跍y(cè)得的延遲值的 99% 上添加了一個(gè)約束,以滿足給定的 SLA 。
model_repository: /models checkpoint_directory: /output/checkpoints/ analysis_models: bert-large: constraints: perf_latency_p99: max: 30 perf_analyzer_flags: input-data: "zero"
因?yàn)槟猩弦淮螔呙柚械臋z查點(diǎn),所以可以將它們重新用于 SLA 分析。運(yùn)行以下命令可以提供滿足延遲約束的前三種配置:
model-analyzer analyze -f latency_constraint.yaml
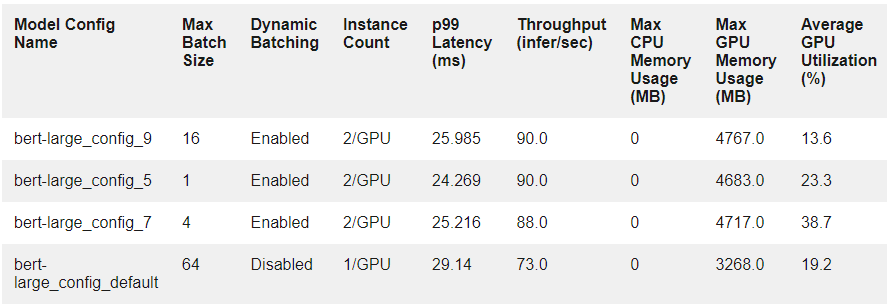
表 2 顯示了前三種配置的測(cè)量結(jié)果,以及它們與默認(rèn)配置的比較情況。

在大規(guī)模生產(chǎn)中,軟件和硬件約束會(huì)影響生產(chǎn)中的 SLA 。
假設(shè)應(yīng)用程序的約束已更改。該團(tuán)隊(duì)現(xiàn)在希望滿足同一型號(hào)的 p99 延遲為 50 ms ,吞吐量為每秒 30 多個(gè)推斷。還假設(shè)基礎(chǔ)設(shè)施團(tuán)隊(duì)能夠?yàn)槠涫褂昧舫?5000 MB 的 GPU 內(nèi)存。隨著約束數(shù)量的增加,手動(dòng)查找服務(wù)配置以滿足涉眾變得越來(lái)越困難。這就是對(duì)模型分析器這樣的解決方案的需求變得更加明顯的地方,因?yàn)槟F(xiàn)在可以在單個(gè)配置文件中同時(shí)指定所有約束。
以下名為multiple_constraint.yaml的示例配置文件結(jié)合了吞吐量、延遲和 GPU 內(nèi)存約束:
model_repository: /models checkpoint_directory: /output/checkpoints/ analysis_models: bert-large-pytorch: constraints: perf_throughput: min: 50 perf_latency_p99: max: 30 gpu_used_memory: max: 5000 perf_analyzer_flags: input-data: "zero"
使用此更新的約束,運(yùn)行以下命令:
model-analyzer analyze -f multiple_constraint.yaml
Model Analyzer 現(xiàn)在將以下提供的服務(wù)配置作為前三個(gè)選項(xiàng),并顯示它們與默認(rèn)配置的比較情況。

總結(jié)
隨著企業(yè)發(fā)現(xiàn)自己在生產(chǎn)中提供越來(lái)越多的模型,手動(dòng)或基于啟發(fā)式做出模型服務(wù)決策變得越來(lái)越困難。手動(dòng)執(zhí)行此操作會(huì)導(dǎo)致浪費(fèi)開(kāi)發(fā)時(shí)間或模型服務(wù)決策不足,這需要自動(dòng)化工具。
在本文中,我們探討了 NVIDIA Triton 模型分析器如何能夠找到滿足應(yīng)用程序 SLA 和各種涉眾需求的模型服務(wù)配置。我們展示了如何使用模型分析器掃描各種配置,以及如何使用它來(lái)滿足指定的服務(wù)約束。
盡管我們?cè)谶@篇文章中只關(guān)注一個(gè)模型,但仍有計(jì)劃讓模型分析器同時(shí)對(duì)多個(gè)模型執(zhí)行相同的分析。例如,您可以在相同的 GPU 上運(yùn)行的不同模型上定義約束,并對(duì)每個(gè)約束進(jìn)行優(yōu)化。
我們希望您能分享我們對(duì) Model Analyzer 將節(jié)省多少開(kāi)發(fā)時(shí)間的興奮,并使您的 MLOps 團(tuán)隊(duì)能夠做出明智的決策。
關(guān)于作者
Arun Raman 是 NVIDIA 的高級(jí)解決方案架構(gòu)師,專門(mén)從事消費(fèi)互聯(lián)網(wǎng)行業(yè)的 edge 、 cloud 和 on-prem 人工智能應(yīng)用。在目前的職位上,他致力于端到端 AI 管道,包括預(yù)處理、培訓(xùn)和推理。除了從事人工智能工作外,他還研究了一系列產(chǎn)品,包括網(wǎng)絡(luò)路由器和交換機(jī)、多云基礎(chǔ)設(shè)施和服務(wù)。他擁有達(dá)拉斯德克薩斯大學(xué)電氣工程碩士學(xué)位。
Burak Yoldeir 是 NVIDIA 的高級(jí)數(shù)據(jù)科學(xué)家,專門(mén)為消費(fèi)互聯(lián)網(wǎng)行業(yè)生產(chǎn)人工智能應(yīng)用程序。除了前端和后端企業(yè)軟件開(kāi)發(fā)之外, Burak 還從事廣泛的 AI 應(yīng)用程序開(kāi)發(fā)。他擁有加拿大不列顛哥倫比亞大學(xué)電氣和計(jì)算機(jī)工程博士學(xué)位。
審核編輯:郭婷
-
Google
+關(guān)注
關(guān)注
5文章
1788瀏覽量
58689 -
NVIDIA
+關(guān)注
關(guān)注
14文章
5247瀏覽量
105805 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86237
發(fā)布評(píng)論請(qǐng)先 登錄
首創(chuàng)開(kāi)源架構(gòu),天璣AI開(kāi)發(fā)套件讓端側(cè)AI模型接入得心應(yīng)手
英偉達(dá)GTC25亮點(diǎn):NVIDIA Dynamo開(kāi)源庫(kù)加速并擴(kuò)展AI推理模型
利用RAKsmart服務(wù)器托管AI模型訓(xùn)練的優(yōu)勢(shì)
AI模型托管原理
NVIDIA推出面向RTX AI PC的AI基礎(chǔ)模型
NVIDIA推出多個(gè)生成式AI模型和藍(lán)圖
Triton編譯器的優(yōu)勢(shì)與劣勢(shì)分析
Triton編譯器在機(jī)器學(xué)習(xí)中的應(yīng)用
NVIDIA推出全新生成式AI模型Fugatto
AI模型托管原理分析
AI模型市場(chǎng)分析
使用AI大模型進(jìn)行數(shù)據(jù)分析的技巧
NVIDIA助力提供多樣、靈活的模型選擇
英偉達(dá)推出全新NVIDIA AI Foundry服務(wù)和NVIDIA NIM推理微服務(wù)
NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論