 模型部署是打通AI應用的最后一公里
模型部署是打通AI應用的最后一公里
在深度學習產業落地過程中,我們經常能聽到一種說法——模型部署是打通AI應用的最后一公里!想要走通這一公里,看似簡單,但是真正實踐起來卻困難重重:顯卡利用率低、內存溢出、多線程調度奔潰、TensorRT加速算子不支持等等問題一直是深度學習模型最后部署的老大難問題。
在工業制造環境中,Windows系統有著廣泛的應用。為了更好的幫助工業用戶解決落地最后的一公里問題,飛槳聯合產業用戶,基于Windows系統,提供了工業級的部署Demo,支持圖像分類、目標檢測、實例分割和語義分割模型的部署,并提供了一鍵的TensorRT加速方式,極大的提升了部署的效率,同時支持多線程推理的方式,滿足了用戶多視頻輸入預測的需求!
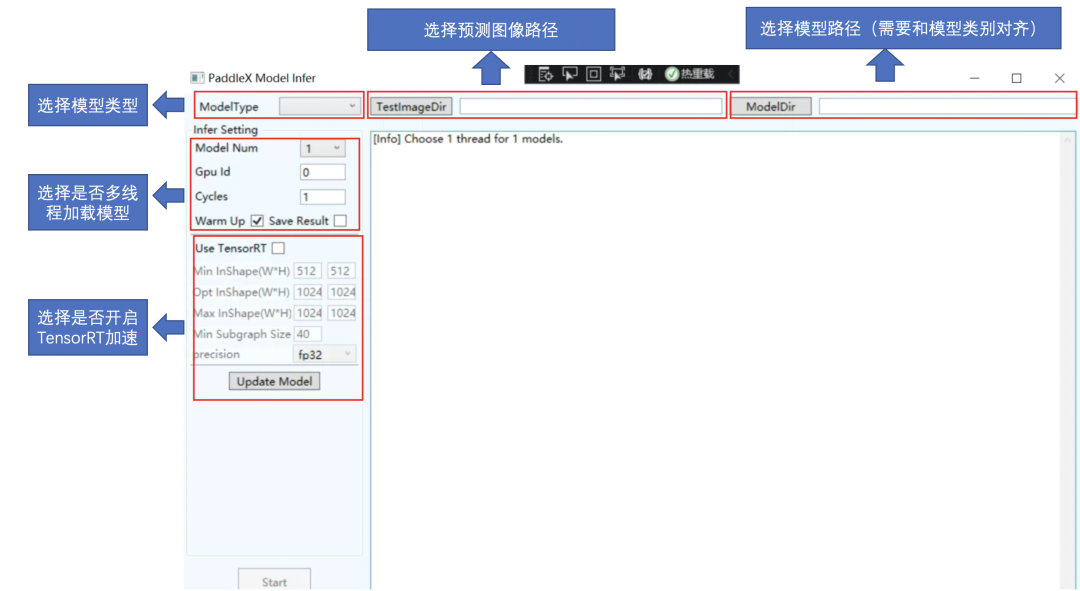
圖1部署開發示例說明
支持多種類別模型部署
滿足多種場景需求
為了更好的滿足用戶多種視覺任務場景,部署Demo基于PaddleX的Deployment模塊進行二次開發,不僅僅支持對PaddleX自身訓練的模型進行推理,同時支持PaddleClas、PaddleDetection、PaddleSeg視覺開發套件的模型,滿足多種場景需求。
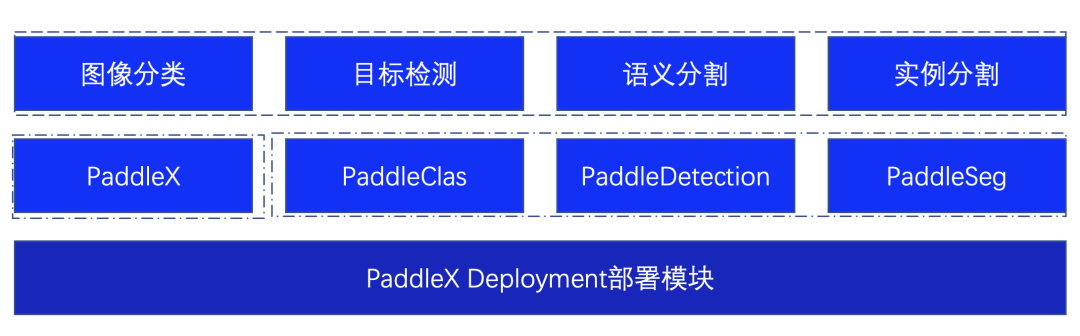
圖2 部署Demo支持模型說明
一鍵TensorRT加速
部署效率顯著提升
NVIDIA TensorRT 是一個高性能的深度學習預測庫,可為深度學習推理應用程序提供低延遲和高吞吐量。在部署Demo中集成了TensorRT預測庫,用戶只需一鍵啟動,即可進行高性能的部署。

圖3 部署Demo性能對比說明
為了更好的幫助用戶了解在工業制造場景部署的問題,飛槳邀請產業用戶現場coding,一步步帶著大家現場演示如何搭建部署開發示例,如何更高性能的應用在自己的產業落地中。
審核編輯 :李倩
-
AI
+關注
關注
88文章
34421瀏覽量
275771 -
圖像分類
+關注
關注
0文章
96瀏覽量
12118 -
工業制造
+關注
關注
0文章
420瀏覽量
28327
原文標題:TensorRT加速、多線程部署,打通工業高性能部署最后一公里
文章出處:【微信號:All_best_xiaolong,微信公眾號:大魚機器人】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
企業部署AI大模型怎么做

云翎智能巡檢終端:以“北斗+”破解森林巡檢“最后一公里”難題

Profinet轉Modbus TCP協議轉換技術,打通能耗監控‘最后一公里’
北斗有源終端:打通應急通信‘最后一公里’的關鍵技術

兆瀚DeepSeek一體機全新升級:內置Agent開發平臺,加速行業AI應用落地

添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
企業AI模型部署攻略
解決驗證“最后一公里”的挑戰:芯神覺Claryti如何助力提升調試效率

中軟國際模型工場加速各行業智能化進程





 工商網監
工商網監
評論