") 如何在OpenVINO 開發(fā)套件中“無縫”部署PaddlePaddle BERT模型
如何在OpenVINO 開發(fā)套件中“無縫”部署PaddlePaddle BERT模型

任務(wù)背景
01
情感分析
(Sentiment Analysis)
情感分析旨在對帶有情感色彩的主觀性文本進(jìn)行分析、處理、歸納和推理,其廣泛應(yīng)用于消費(fèi)決策、輿情分析、個性化推薦等領(lǐng)域,具有很高的商業(yè)價值。例如:食行生鮮自動生成菜品評論標(biāo)簽輔助用戶購買,并指導(dǎo)運(yùn)營采購部門調(diào)整選品和促銷策略;房天下向購房者和開發(fā)商直觀展示樓盤的用戶口碑情況,并對好評樓盤置頂推薦;國美搭建服務(wù)智能化評分系統(tǒng),客服運(yùn)營成本減少40%,負(fù)面反饋處理率100%。
02
自然語言處理(NLP)技術(shù)
自然語言處理(英語:Natural Language Process,簡稱NLP)是計算機(jī)科學(xué)、信息工程以及人工智能的子領(lǐng)域,專注于人機(jī)語言交互,探討如何處理和運(yùn)用自然語言。最近幾年,隨著深度學(xué)習(xí)以及相關(guān)技術(shù)的發(fā)展,NLP領(lǐng)域的研究取得一個又一個突破,研究者設(shè)計各種模型和方法,來解決NLP的各類問題,其中比較常見包括LSTM, BERT, GRU, Transformer, GPT等算法模型。
方案簡介
本方案采用PaddleNLP工具套件進(jìn)行模型訓(xùn)練,并基于OpenVINO 開發(fā)套件實現(xiàn)在Intel平臺上的高效能部署。本文將主要分享如何在OpenVINO 開發(fā)套件中“無縫”部署PaddlePaddle BERT模型,并對輸出結(jié)果做驗證。
01
PaddleNLP
PaddleNLP是一款簡單易用且功能強(qiáng)大的自然語言處理開發(fā)庫。聚合業(yè)界優(yōu)質(zhì)預(yù)訓(xùn)練模型并提供開箱即用的開發(fā)體驗,覆蓋NLP多場景的模型庫搭配產(chǎn)業(yè)實踐范例可滿足開發(fā)者靈活定制的需求。
02
OpenVINO 開發(fā)套件
OpenVINO 開發(fā)套件是Intel平臺原生的深度學(xué)習(xí)推理框架,自2018年推出以來,Intel已經(jīng)幫助數(shù)十萬開發(fā)者大幅提升了AI推理性能,并將其應(yīng)用從邊緣計算擴(kuò)展到企業(yè)和客戶端。英特爾于2022年巴塞羅那世界移動通信大會前夕,推出了英特爾 發(fā)行版OpenVINO 開發(fā)套件的全新版本。其中的新功能主要根據(jù)開發(fā)者過去三年半的反饋而開發(fā),包括更多的深度學(xué)習(xí)模型選擇、更多的設(shè)備可移植性選擇以及更高的推理性能和更少的代碼更改。為了更好地對Paddle模型進(jìn)行支持,新版OpenVINO 開發(fā)套件分別做了一下升級:
■直接支持Paddle格式模型
目前OpenVINO 開發(fā)套件2022.1發(fā)行版中已完成對PaddlePaddle模型的直接支持,OpenVINO 開發(fā)套件的Model Optimizer工具已經(jīng)可以直接完成對Paddle模型的離線轉(zhuǎn)化,同時runtime api接口也可以直接讀取加載Paddle模型到指定的硬件設(shè)備,省去了離線轉(zhuǎn)換的過程,大大提升了Paddle開發(fā)者在Intel平臺上部署的效率。經(jīng)過性能和準(zhǔn)確性驗證,在OpenVINO 開發(fā)套件2022.1發(fā)行版中,會有13個模型涵蓋5大應(yīng)用場景的Paddle模型將被直接支持,其中不乏像PPYolo和PPOCR這樣非常受開發(fā)者歡迎的網(wǎng)絡(luò)。
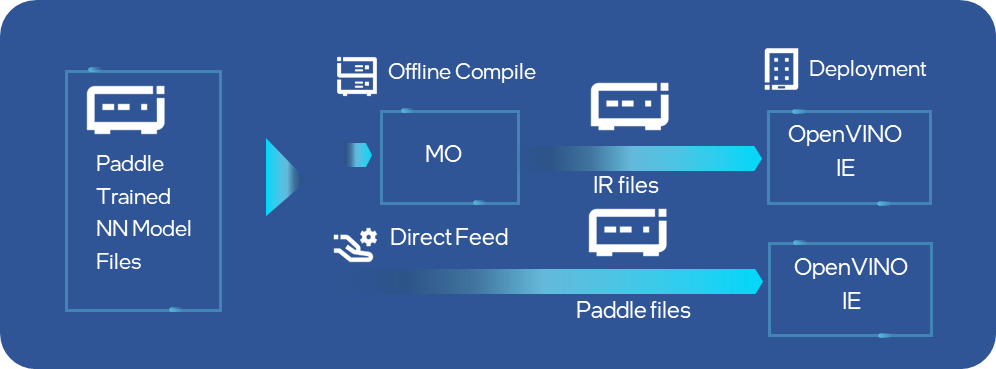
圖:OpenVINO 開發(fā)套件的MO和IE可以直接支持Paddle模型輸入
■ 全面引入動態(tài)輸入支持
為了適配更廣泛的模型種類,OpenVINO 2022.1版本的CPU Plugin已經(jīng)支持了動態(tài)input shape,讓開發(fā)者以更便捷的方式部署類似NLP或者OCR這樣的網(wǎng)絡(luò),OpenVINO 開發(fā)套件用戶可以在不需要對模型做reshape的前提下,任意送入不同shape的圖片或者向量作為輸入數(shù)據(jù),OpenVINO 開發(fā)套件會自動在runtime過程中對模型結(jié)構(gòu)與內(nèi)存空間進(jìn)行動態(tài)調(diào)整,進(jìn)一步優(yōu)化dynamic shape的推理性能。
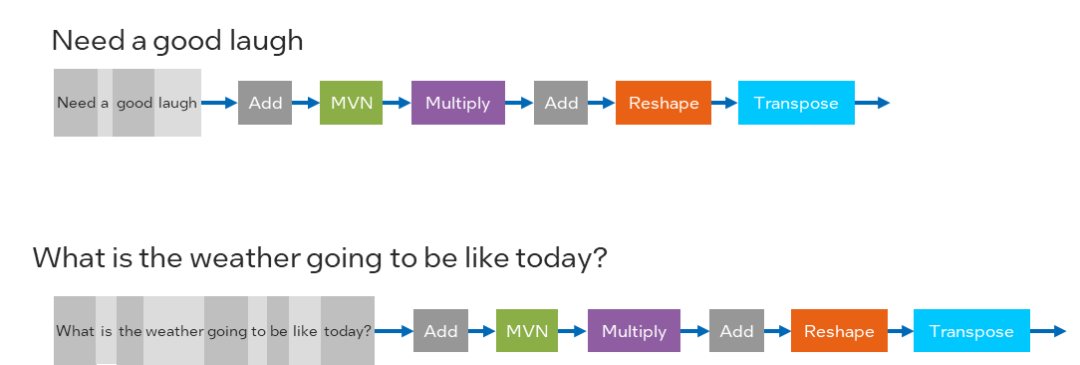
圖:在NLP中的Dynamic Input Shape
詳細(xì)介紹可以參考:https://docs.openvino.ai/latest/openvino_docs_OV_UG_DynamicShapes.html
BERT原理簡介
01
BERT結(jié)構(gòu)介紹
BERT (Bidirectional Encoder Representations from Transformers)以Transformer 編碼器為網(wǎng)絡(luò)基本組件,使用掩碼語言模型(Masked Language Model)和鄰接句子預(yù)測(Next Sentence Prediction)兩個任務(wù)在大規(guī)模無標(biāo)注文本語料上進(jìn)行預(yù)訓(xùn)練(pre-train),得到融合了雙向內(nèi)容的通用語義表示模型。以預(yù)訓(xùn)練產(chǎn)生的通用語義表示模型為基礎(chǔ),結(jié)合任務(wù)適配的簡單輸出層,微調(diào)(fine-tune)后即可應(yīng)用到下游的NLP任務(wù),效果通常也較直接在下游的任務(wù)上訓(xùn)練的模型更優(yōu)。此前BERT即在GLUE評測任務(wù)上取得了SOTA的結(jié)果。
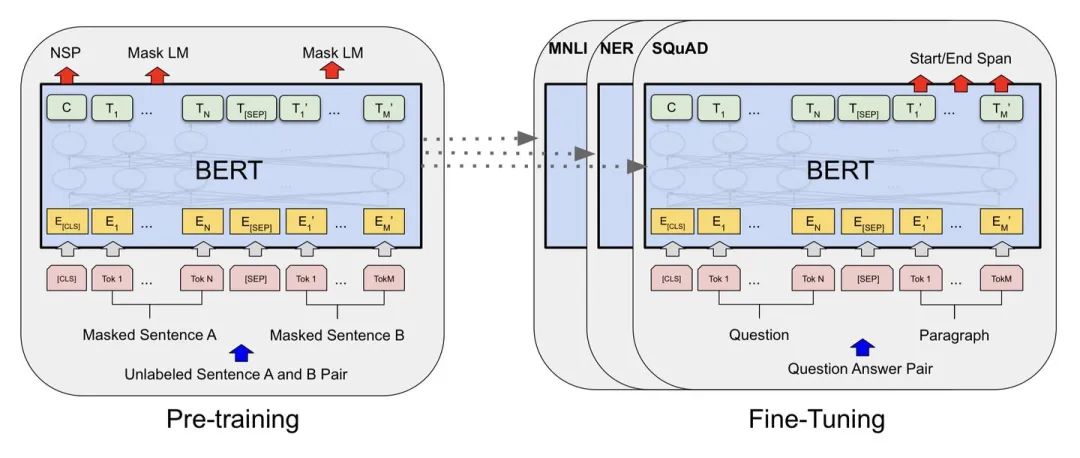
圖:BERT的2階段訓(xùn)練任務(wù)
不難發(fā)現(xiàn),其模型結(jié)構(gòu)是Transformer的Encoder層,只需要將特定任務(wù)的輸入,輸出插入到Bert中,利用Transformer強(qiáng)大的注意力機(jī)制就可以模擬很多下游任務(wù)。(句子對關(guān)系判斷,單文本主題分類,問答任務(wù)(QA),單句貼標(biāo)簽(命名實體識別)),BERT的訓(xùn)練過程可以分成預(yù)訓(xùn)練和微調(diào)兩部分組成。
02
預(yù)訓(xùn)練任務(wù)(Pre-training)
BERT是一個多任務(wù)模型,它的任務(wù)是由兩個自監(jiān)督任務(wù)組成,即MLM和NSP。
■Task #1:Masked Language Model
所謂MLM是指在訓(xùn)練的時候隨即從輸入預(yù)料上mask掉一些單詞,然后通過的上下文預(yù)測該單詞,該任務(wù)非常像我們在中學(xué)時期經(jīng)常做的完形填空。正如傳統(tǒng)的語言模型算法和RNN匹配那樣,MLM的這個性質(zhì)和Transformer的結(jié)構(gòu)是非常匹配的。
■Task #2: Next Sentence Prediction
Next Sentence Prediction(NSP)的任務(wù)是判斷句子B是否是句子A的下文。如果是的話輸出’IsNext‘,否則輸出’NotNext‘。訓(xùn)練數(shù)據(jù)的生成方式是從平行語料中隨機(jī)抽取的連續(xù)兩句話,其中50%保留抽取的兩句話,它們符合IsNext關(guān)系,另外50%的第二句話是隨機(jī)從預(yù)料中提取的,它們的關(guān)系是NotNext的。
微調(diào)任務(wù) (Fine-tuning)
在海量單預(yù)料上訓(xùn)練完BERT之后,便可以將其應(yīng)用到NLP的各個任務(wù)中了。以下展示了BERT在11個不同任務(wù)中的模型,它們只需要在BERT的基礎(chǔ)上再添加一個輸出層便可以完成對特定任務(wù)的微調(diào)。這些任務(wù)類似于我們做過的文科試卷,其中有選擇題,簡答題等等。微調(diào)的任務(wù)包括:
■基于句子對的分類任務(wù)
■基于單個句子的分類任務(wù)
■問答任務(wù)
■命名實體識別
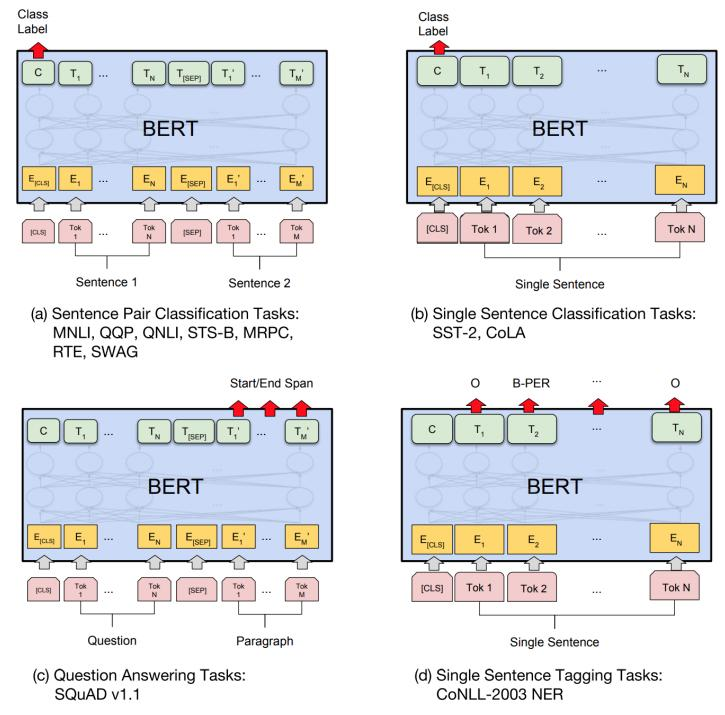
圖:BERT的4大下游微調(diào)任務(wù)
訓(xùn)練與部署流程
本示例包含PaddleNLP訓(xùn)練和OpenVINO 開發(fā)套件部署兩部分組成。
01
環(huán)境安裝
打開命令行終端,分別輸入以下命令,完成本地環(huán)境安裝和配置。
1.1安裝PaddlePaddle (AI studio環(huán)境中可以略過)
如果是CPU訓(xùn)練環(huán)境需要執(zhí)行以下命令進(jìn)行安裝:
如果是GPU訓(xùn)練環(huán)境需要執(zhí)行以下命令進(jìn)行安裝:
1.2安裝PaddleNLP與相關(guān)依賴
下載PaddleNLP:
安裝PaddleNLP相關(guān)依賴:
1.3安裝OpenVINO 開發(fā)套件
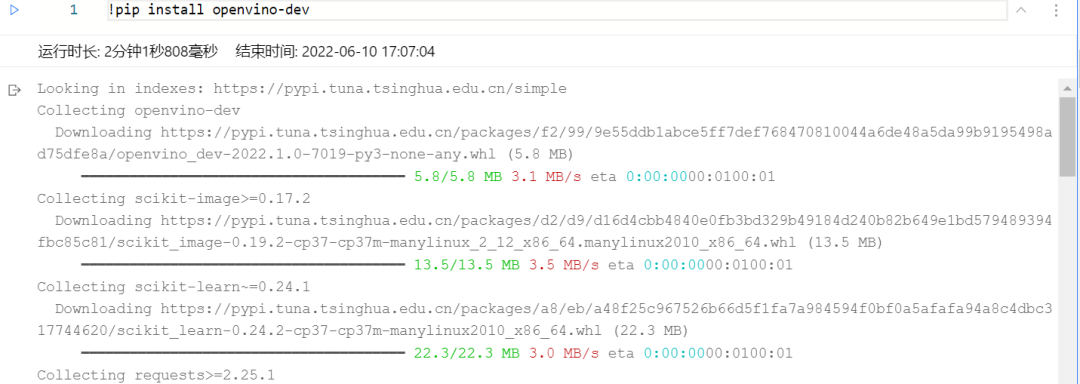
02
訓(xùn)練部分
訓(xùn)練部分是BERT在 Paddle 2.0上的開源實現(xiàn),可以分為數(shù)據(jù)準(zhǔn)備,BERT Encoder預(yù)訓(xùn)練,SST2情感分類任務(wù)微調(diào)以及推理模型導(dǎo)出這四個步驟。
可以參考Paddle官方的案例說明,對以下過程做了簡要匯總,地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/bert

圖:Paddle BERT模型訓(xùn)練流程
除此之外,我們也可以借助Paddle AI studio直接運(yùn)行訓(xùn)練腳本(無腦點(diǎn)擊運(yùn)行就可以了: )),鏈接如下:
https://aistudio.baidu.com/aistudio/projectdetail/4193790?contributionType=1
2.1步驟一:數(shù)據(jù)準(zhǔn)備(可略過)
PaddleNLP中BERT任務(wù)下自帶的create_pretraining_data.py 是創(chuàng)建預(yù)訓(xùn)練程序所需數(shù)據(jù)的腳本。其以文本文件(使用換行符換行和空白符分隔,data目錄下提供了部分示例數(shù)據(jù))為輸入,經(jīng)由BERT tokenizer進(jìn)行tokenize后再做生成sentence pair正負(fù)樣本、掩碼token等處理,最后輸出hdf5格式的數(shù)據(jù)文件。使用方式如下,在命令行輸入:
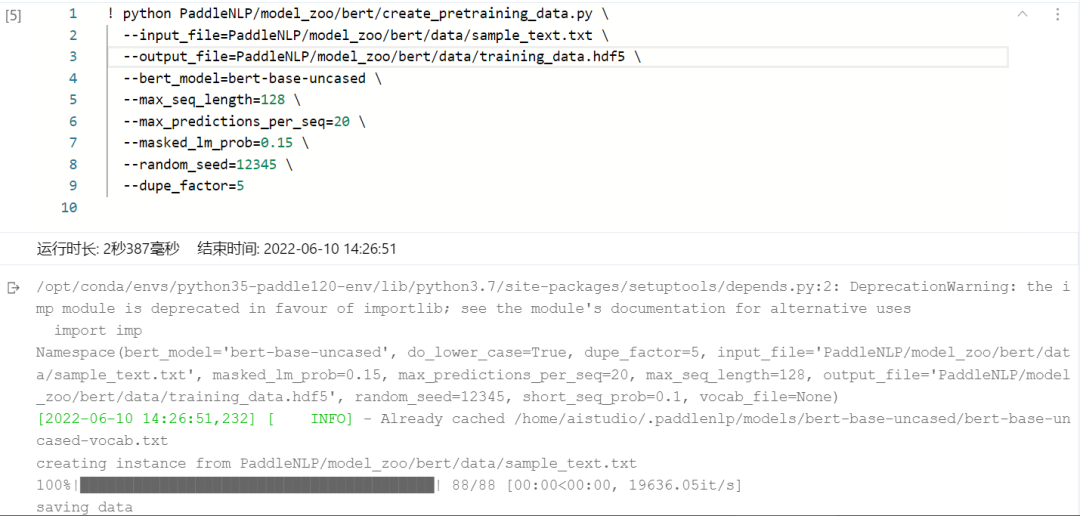
2.2步驟二:GPU訓(xùn)練(可略過)
使用paddle.distributed.launch配置項運(yùn)行run_pretrain.py訓(xùn)練腳本,可以在多卡GPU環(huán)境下啟動BERT預(yù)訓(xùn)練任務(wù)。命令行指令如下:
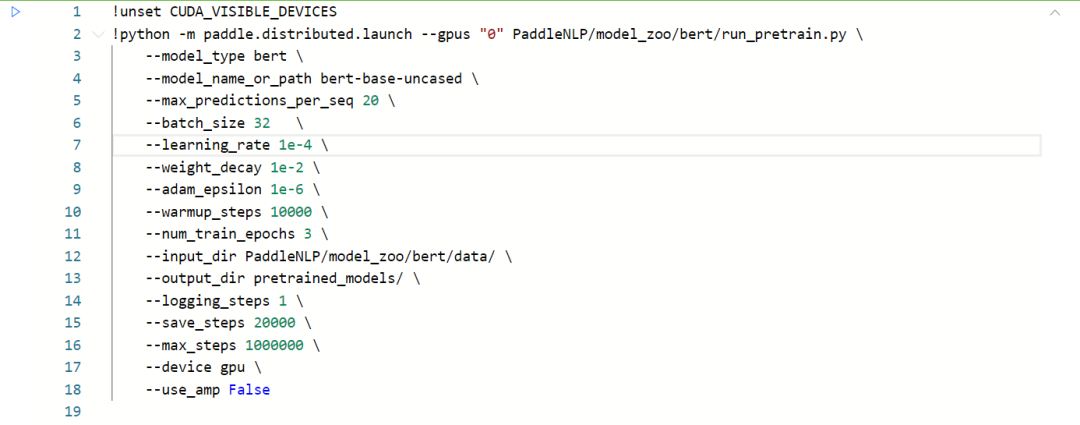
■model_type指示了模型類型,使用BERT模型時設(shè)置為bert即可。
■model_name_or_path指示了某種特定配置的模型,對應(yīng)有其預(yù)訓(xùn)練模型和預(yù)訓(xùn)練時使用的 tokenizer。若模型相關(guān)內(nèi)容保存在本地,這里也可以提供相應(yīng)目錄地址。
■input_dir表示輸入數(shù)據(jù)的目錄,該目錄下所有文件名中包含training的文件將被作為訓(xùn)練數(shù)據(jù)。output_dir 表示模型的保存目錄。

2.3步驟三:模型Fine-tunning
如果自己沒有準(zhǔn)備訓(xùn)練數(shù)據(jù)集的話,也可以跳過前面的步驟,直接使用huggingface提供的預(yù)訓(xùn)練模型進(jìn)行Fine-tuning,以GLUE中的SST-2任務(wù)為例,該腳本會自動下載SST-2任務(wù)中所需要的英文數(shù)據(jù)集,啟動Fine-tuning的方式如下:
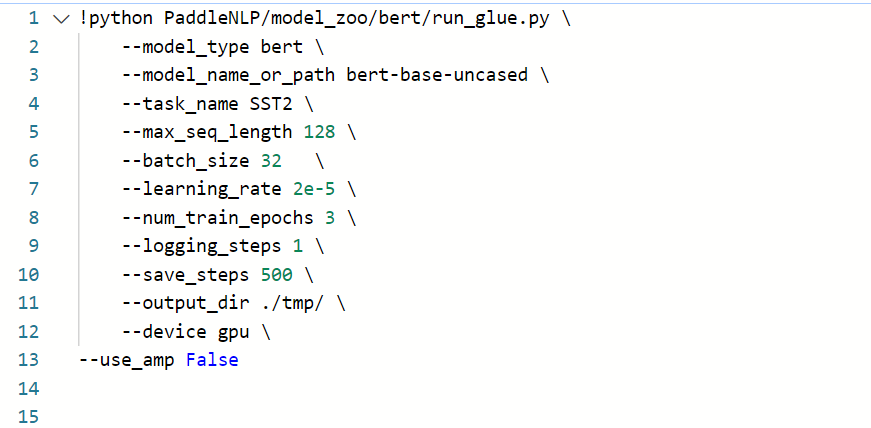
■model_name_or_path指示了某種特定配置的模型,對應(yīng)有其預(yù)訓(xùn)練模型和預(yù)訓(xùn)練時使用的 tokenizer。若模型相關(guān)內(nèi)容保存在本地,這里也可以提供相應(yīng)目錄地址。注:bert-base-uncased等對應(yīng)使用的預(yù)訓(xùn)練模型轉(zhuǎn)自huggingface/transformers
可以看到啟動Fine-tuning任務(wù)以后,腳本會自動下載bert-base-uncased預(yù)訓(xùn)練模型,以及用于Fine-tuning的bert-base-uncased-vocab.txt數(shù)據(jù)集。
當(dāng)訓(xùn)練任務(wù)到達(dá)預(yù)先設(shè)定的step輪數(shù)以后,便會停止訓(xùn)練,并且將.pdparam格式的模型權(quán)重保存在tmp目錄下。
2.4步驟四:模型導(dǎo)出
在Fine-tuning完成后,我們可以使用如下方式導(dǎo)出希望用來預(yù)測的Paddle靜態(tài)模型,并保存在infer_model路徑下:
導(dǎo)出后的模型文件包含以下內(nèi)容時,推理時需要保證這三個文件在同一個目錄下:
model.pdmodel, model.pdiparams.info, model.pdiparams
圖:導(dǎo)出后的Paddle BERT靜態(tài)模型文件
03
部署部分
該示例將基于OpenVINO 開發(fā)套件進(jìn)行Paddle的靜態(tài)模型部署,需要開發(fā)者提前準(zhǔn)備好用于做部署的Intel平臺硬件,可以是個人電腦,也可以是云服務(wù)器虛機(jī)。整體流程可以分為以下幾個步驟:

圖:BERT模型部署流程
對于情感分析任務(wù),BERT網(wǎng)絡(luò)的識別流程可以分成以下幾個步驟:
■ 輸入語句文本,并轉(zhuǎn)為相應(yīng)的Token ID
■ 為每一行Token ID添加Padding,使其保持長度一致
■ Token ID作為輸入數(shù)據(jù)送入BERT模型進(jìn)行推理 (模型內(nèi)流程邏輯參考下圖),通過Embedding Layer將一個詞映射成為固定維度的稠密向量,降維后的向量會再通過Encoder提取Self-attentions后的向量間的關(guān)系特征,最后經(jīng)過Classifier對情感分類任務(wù)做出判斷。
■ 獲取模型結(jié)果數(shù)據(jù),通過后處理函數(shù),計算分類標(biāo)簽與每一類標(biāo)簽的置信度
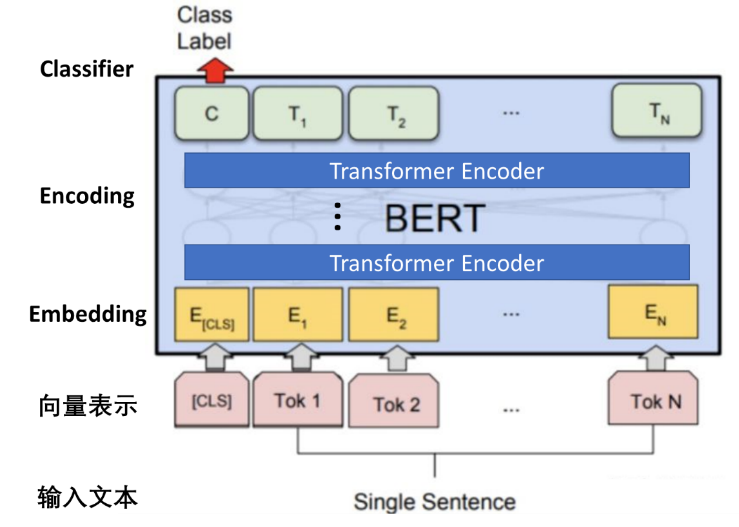
圖:BERT for SST2模型內(nèi)部邏輯
BERT for SST2的輸入的編碼向量(長度不固定)是2個嵌入特征的單位和,這2個詞嵌入特征是:
■ input_ids:輸入文本被轉(zhuǎn)化為token后的單個字的id;
■ segment_ids:就是句子級別(上下句)的標(biāo)簽,用于區(qū)分兩個句子,例如B是否是A的下文(對話場景,問答場景等)。由于在情感分析任務(wù)中沒有下句,所以這里segment_ids為全部為0的向量。
3.1步驟一:文本Token表示
定義數(shù)據(jù)轉(zhuǎn)換模塊,將原始的輸入語句轉(zhuǎn)化為input_ids與segment_ids,作為輸入數(shù)據(jù)。這邊我們將會使用PaddleNLP自帶的tokenizer()方法進(jìn)行轉(zhuǎn)換。
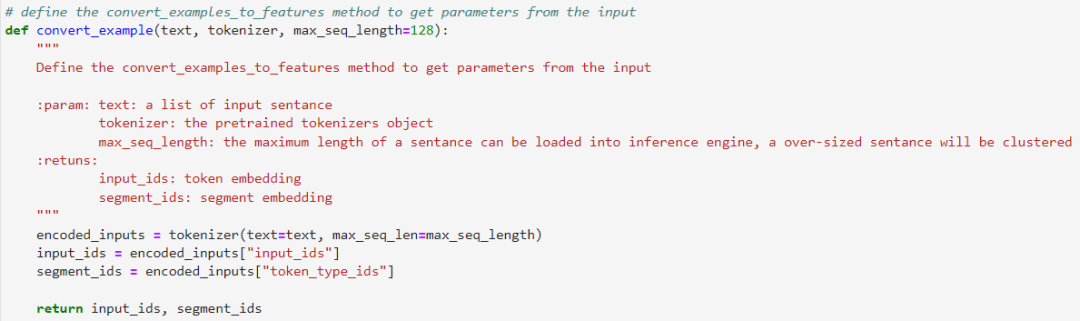
3.2步驟二:Padding
需要保證input_ids與segment_ids數(shù)組在axis0方向的長度一致,由于這邊input_ids與segment_ids均為一維數(shù)組,所以也可以不進(jìn)行該操作。
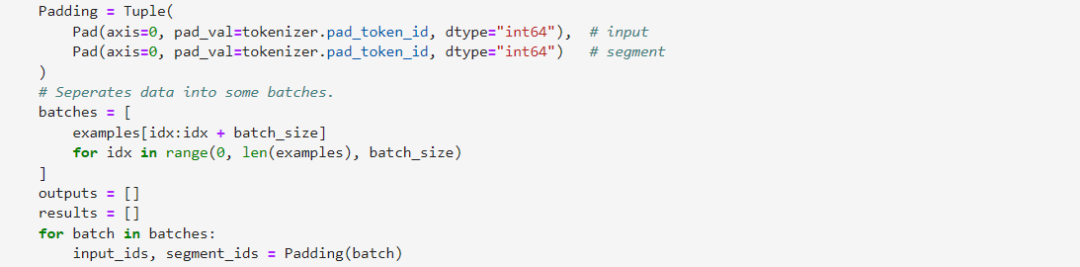
3.3步驟三:模型推理
部署代碼里最核心的部分就是要定義基于OpenVINO 開發(fā)套件的預(yù)測器,這里使用CPU作為模型的部署平臺,可以看到通過read_model這個函數(shù)接口我們可以直接讀取原始的.pdmodel格式模型,省去了之前繁雜的離線轉(zhuǎn)化過程。此外我們需要通過compile_model這個函數(shù)講讀取后的模型在指定的硬件平臺進(jìn)行加載和編譯。最后創(chuàng)建infer_request推理請求進(jìn)行推理任務(wù)部署。

由于輸入語句的長度往往不一致,這也導(dǎo)致編碼后的向量長度也不一致,這里OpenVINO 開發(fā)套件CPU Plugin的支持上已經(jīng)全面引入了Dynamic Shape功能,無需再手動調(diào)整輸入數(shù)據(jù)的長度,OpenVINO 開發(fā)套件會在runtime過程中自動匹配并動態(tài)申請一定的內(nèi)存空間進(jìn)行推理,優(yōu)化性能表現(xiàn)。

由于新版OpenVINO 開發(fā)套件已經(jīng)全面支持Intel 12代酷睿處理器,為了取得更佳的推理性能,我們建議使用最新的硬件平臺進(jìn)行測試。
3.4步驟四:結(jié)果后處理
此處得到的結(jié)果數(shù)據(jù)為兩種不同評價的可能性,我們需要將其通過softmax函數(shù)還原成百分比形式,并且找到可能性最大的那個評價序號所對應(yīng)的標(biāo)簽(Positive,Negative)。

最后我們找一組測試語句作為輸入數(shù)據(jù),將其封裝成List以后,送入到識別器中進(jìn)行識別,可以發(fā)現(xiàn)結(jié)果都是符合我們的先驗預(yù)期的。
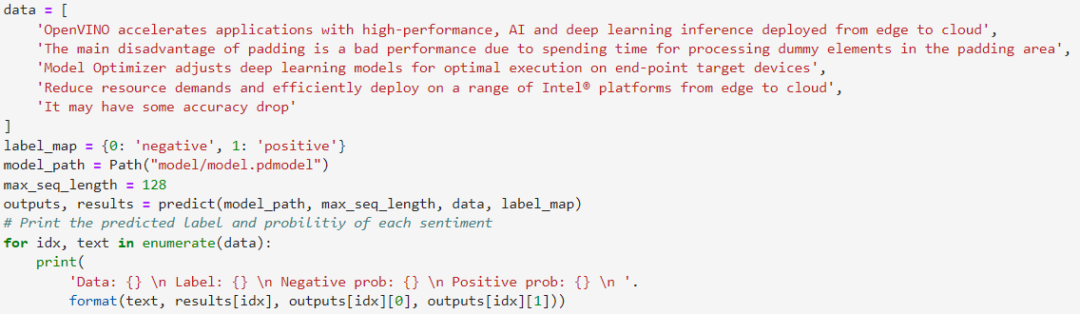
該示例程序可以可以準(zhǔn)確按SST2情感二分類任務(wù)要求,輸出每段輸入語句的分類情感標(biāo)簽,并獲得每種情感對應(yīng)的參考置信度。

小結(jié)
作為發(fā)布至今近4年以來最大的一次更新,OpenVINO 2022.1版本為了更好地支持NLP與語音相關(guān)的模型,在CPU plugin中已全面支持了動態(tài)input shape,并通過與百度PaddlePaddle框架的深度集成,用更便捷的API接口,更豐富的模型支持,提升雙方開發(fā)者在模型部署側(cè)的使用體驗,真正實現(xiàn)對PaddleNLP模型的“無縫”轉(zhuǎn)化與部署。
通過本次的全流程示例,我們看到OpenVINO 開發(fā)套件對Paddle BERT模型已經(jīng)做到了很好的適配,從而加速在Intel平臺上的推理。以下github repository中已為大家提前準(zhǔn)備好了OpenVINO 開發(fā)套件部署的參考實現(xiàn)與.pdmodel格式的BERT預(yù)訓(xùn)練模型。
https://github.com/OpenVINO-dev-contest/openvino_notebooks/tree/PaddleBert/notebooks/005-hello-paddle-nlp
除此之外,為了方便大家了解并快速掌握OpenVINO 開發(fā)套件的使用,我們還提供了一系列開源的Jupyter notebook demo。運(yùn)行這些notebook,就能快速了解在不同場景下如何利用OpenVINO 開發(fā)套件實現(xiàn)一系列、包括OCR在內(nèi)的、計算機(jī)視覺及自然語言處理任務(wù)。OpenVINO notebooks的資源可以在Github這里下載安裝:
https://github.com/openvinotoolkit/openvino_notebooks
審核編輯 :李倩
-
自然語言處理
+關(guān)注
關(guān)注
1文章
628瀏覽量
14137 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22597
原文標(biāo)題:基于OpenVINO? “無縫”部署 PaddleNLP 模型 | 開發(fā)者實戰(zhàn)
文章出處:【微信號:英特爾物聯(lián)網(wǎng),微信公眾號:英特爾物聯(lián)網(wǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
在V2板子上部署豆包模型調(diào)試指南
SC171開發(fā)套件V3 技術(shù)資料
AI端側(cè)部署案例(SC171開發(fā)套件V3)
AI端側(cè)部署開發(fā)(SC171開發(fā)套件V3)
首創(chuàng)開源架構(gòu),天璣AI開發(fā)套件讓端側(cè)AI模型接入得心應(yīng)手
如何部署OpenVINO?工具套件應(yīng)用程序?
構(gòu)建開源OpenVINO?工具套件后,模型優(yōu)化器位于何處呢?
在OpenVINO?工具套件的深度學(xué)習(xí)工作臺中無法導(dǎo)出INT8模型怎么解決?
使用工具套件2020.2從ncappzoo運(yùn)行模型和演示OpenVINO?報錯怎么解決?
OpenVINO?工具套件插件對YOLOv5s模型和scatterUpate層的支持范圍是什么?
C#集成OpenVINO?:簡化AI模型部署

C#中使用OpenVINO?:輕松集成AI模型!
基于哪吒開發(fā)板部署YOLOv8模型

使用OpenVINO Model Server在哪吒開發(fā)板上部署模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論