") 在DNN中FPGA做了一些什么?
在DNN中FPGA做了一些什么?
引言
深度神經(jīng)網(wǎng)絡(deep nearal network)是機器學習發(fā)展20年來取得的最大突破,比如在語音識別方面,相比于傳統(tǒng)方法,其將錯誤率降低了30%;而在2011年的圖片識別競賽上,將錯誤率從26%降低到3.5%,這些使得處于發(fā)展低谷的人工智能突然熱門起來,從學術界擴展到工業(yè)界,甚至在google的alpha go擊敗了頂級圍棋大師李世石后,人工智能成為全民討論的熱門,所有的程序員都夢想轉(zhuǎn)行機器學習。
DNN中應用最廣泛的是CNN和RNN,CNN是一種卷積網(wǎng)絡,在圖片識別分類中用的較多,RNN可以處理時間序列的信息,比如視頻識別和語音識別。這些DNN結(jié)構通常很深,計算量也很大。比如VGG16用來處理1000種圖片類別,有550MB的權重數(shù)據(jù),完成一個分類就需要31Gop(operations)。為了降低計算量和訪問內(nèi)存時間,有兩種方法:量化和降低權重。量化是減小權重或者激活數(shù)據(jù)的精度,比如從32bit浮點量化到8bit甚至1bit,就減小了數(shù)據(jù)量。降低權重包括剪枝和結(jié)構簡化,這兩種方法可以去除多余的權重參數(shù)。
DNN包括訓練和推理兩個階段,訓練是一個學習過程,通過不斷的對權重進行迭代更新而使得網(wǎng)絡獲得智能。而推理階段是給出一定輸入后,網(wǎng)絡會根據(jù)之前學習到的知識,輸出準確結(jié)果。為了使得結(jié)果具有更高準確率,訓練是進行浮點運算,同時涉及到大量的微分運算,所以訓練通常由GPU完成。但是訓練是一次性的,當訓練完成,網(wǎng)絡就可以直接用于推斷而不需要再進行訓練。FPGA就是用于推理過程,相比于CPU,具有更加靈活可編程的特點。可以針對DNN的特性增加運算并行度,調(diào)整內(nèi)存訪問,比CPU獲得更高的實現(xiàn)效果。本章對自己基于FPGA進行DNN設計的經(jīng)驗做一個總結(jié),包括對網(wǎng)絡模型的一些體會,以及FPGA設計架構的一些思路,拋磚引玉,期待更多熱愛AI加速的同學們加入討論。
1
DNN模型
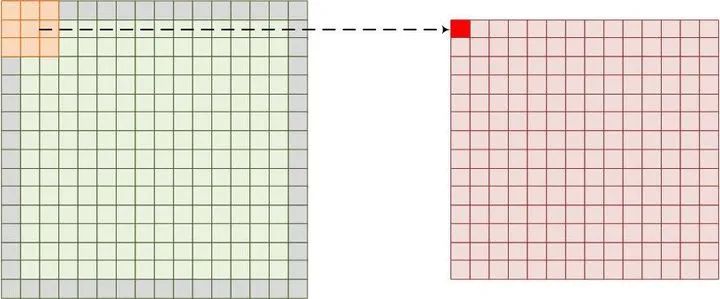
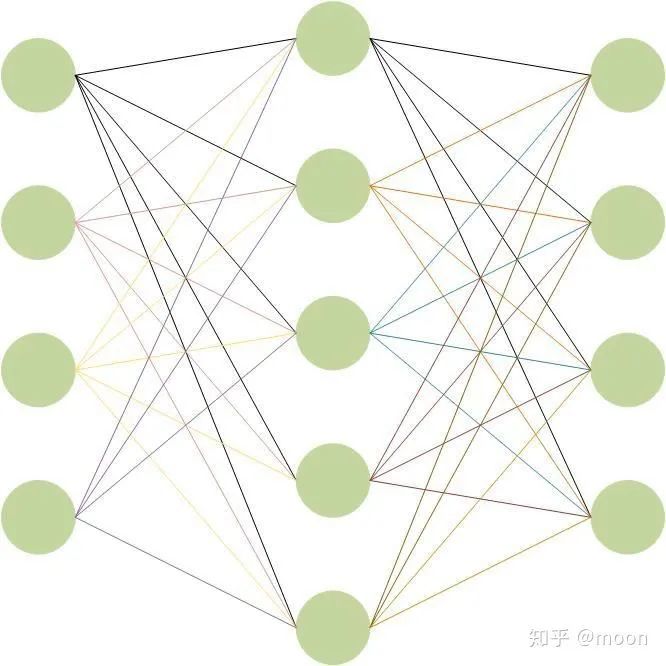
不論是CNN還是RNN,一個共同特點是整個網(wǎng)絡是由幾個相同的單元聯(lián)結(jié)形成的。CNN中基本的單元是神經(jīng)元,一個神經(jīng)元包含一個權重和激活函數(shù),其中權重是對輸入信息進行卷積(圖1.1),幾乎大部分運算量都集中在卷積運算中。激活函數(shù)是對卷積后的結(jié)果進行非線性運算,激活函數(shù)有很多,像Relu,sigmoid等。基本的CNN網(wǎng)絡結(jié)構如圖1.2,網(wǎng)絡每層都由多個神經(jīng)元構成,每個神經(jīng)元的輸入來自上一層的輸出,本層輸出作為下一層的輸入。每層的輸入通道是上一層神經(jīng)元的個數(shù),輸出通道是這一層神經(jīng)元個數(shù)。每個神經(jīng)元對應不同輸入通道的數(shù)據(jù)都有不同的權重數(shù)據(jù)(即kernel),這些權重和對應輸入通道的圖像完成卷積之后再求和,最后通過非線性激活函數(shù)給出輸出通道的值。我們用偽代碼來表示一層網(wǎng)絡的運算過程:
For(int o=0;o
其中內(nèi)四層循環(huán)是圖像和權重的卷積運算,F(xiàn)PGA就是利用這6層循環(huán)進行加速。從這偽代碼中可以看出每個乘法都是相互獨立的,不會依賴于其他運算,而加法包含兩種,一種是在卷積運算中,另外一種是每個輸入通道卷積后的數(shù)據(jù)要求和。
圖1.1 圖像卷積
圖1.2 CNN網(wǎng)絡結(jié)構
另外一種比較常用的網(wǎng)絡是RNN,這是一種循環(huán)神經(jīng)網(wǎng)絡,具有記憶功能,可以處理時序信息。這里重點介紹一下LSTM網(wǎng)絡,LSTM也是一種RNN。但是其增加了多個門控:記憶門,輸入門,輸出門等。這些門解決了梯度消失和發(fā)散的問題,能夠處理更長時序的信息。所以在語音識別和視頻識別方面有重要應用。LSTM原理的介紹可以參見本公眾號歷史文章《LSTM原理》。FPGA更多的關心其中有哪些運算,LSTM中主要包含矩陣乘法,向量求和,激活操作,向量點乘等。矩陣乘法消耗最多的運算資源,如何優(yōu)化這種運算是FPGA實現(xiàn)加速的關鍵。
對于矩陣乘法,根據(jù)其乘法順序有一下幾種方式。
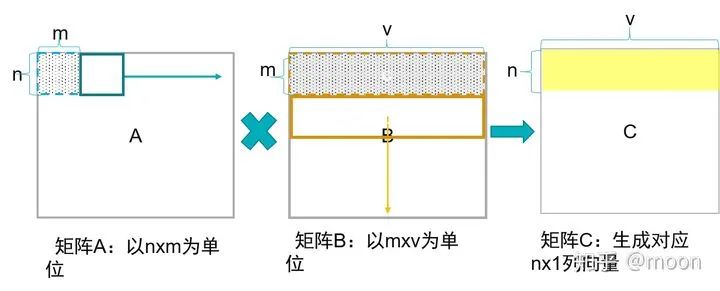
1) 小矩陣x小矩陣
A每次獲得nxm塊數(shù)據(jù),和B的mxv塊數(shù)據(jù)相乘,然后A移動nxm塊,B向下移動mxv塊,再次相乘并且和之前結(jié)果累加,當A移動到右端,B同時移動到底端,完成C中nxv矩陣塊。A中數(shù)據(jù)復用率在V次。
圖1.3 小矩陣x小矩陣
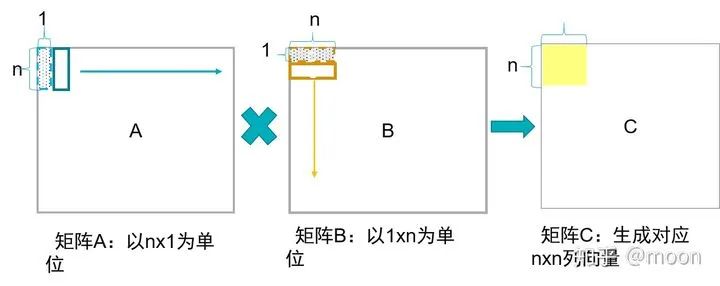
2) 列向量x行向量
A每次獲得nx1列向量,B獲得1xn行向量,二者進行叉乘,得到nxn個矩陣數(shù)據(jù),然后A向右移動,同時B向下移動,二者叉乘結(jié)果和上一次進行累加,最后當A移動到右端,B到底端,得到了一個nxn大小的C矩陣塊。A中數(shù)據(jù)復用率在n次。
圖1.4列向量x行向量
對比這兩種計算方式,第一種A數(shù)據(jù)復用率取決于B矩陣列大小。A可以看做權重,B看做輸入的圖像或者聲音信息,如果輸入信息“寬度不夠”,那么權重利用率低,就會造成運算比搬運數(shù)據(jù)慢,造成帶寬瓶頸。第二種方式A僅僅需要n個數(shù),就能參與n*n次乘法,利用率較高。這能夠很大緩解帶寬瓶頸。但是如果B的寬度較小或者B為向量,那么就會造成算力較低,搬運進n個數(shù)只能計算n次乘法。如何選擇需要根據(jù)實際情況來決定。
2
量化和減少權重
雖然浮點數(shù)能夠表示更高的數(shù)據(jù)精度和更大的數(shù)據(jù)寬度,但是浮點數(shù)據(jù)占用的存儲資源和運算資源都較大,造成推理時間較長。隨著網(wǎng)絡的復雜和加深,對推理延時的要求越來越高,因此通過必要手段來壓縮網(wǎng)絡模型,降低推理延時顯得非常重要。壓縮網(wǎng)絡模型主要有兩種方式:量化和減少權重。
1) 定點化。
通過仿射變換將浮點數(shù)等效的映射到定點數(shù)空間,比如對于一個分布范圍在(Xmin, Xmax)的權重數(shù)據(jù),需要映射到(0,N-1)區(qū)間,其中N是定點可以表示的數(shù)據(jù)范圍。浮點數(shù)就可以通過一個尺度和偏移量來表示為:
其中Z為0點偏移量,也是定點數(shù)據(jù),S為尺度大小,用浮點數(shù)表示。在計算卷積的時候,就可以將尺度因子提取出來進行后處理,而乘法和加法運算使用定點完成。比如對于一個卷積運算可以表示為:
2) 二值化
二值化就是將參數(shù)量化到兩個值{-1, 1},和一個尺度參數(shù)。二值化網(wǎng)絡大大降低了運算和參數(shù)存儲,但是也對網(wǎng)絡精度有很大削弱,所以應用范圍很窄,比如用在MNIST和CIFAR-10這樣比較小的數(shù)據(jù)集中。對于定點乘法一般都是用DSP實現(xiàn),所以算力大小受到了FPGA中DSP數(shù)量的限制。而二值化網(wǎng)絡的乘法運算可以通過簡單的邏輯來實現(xiàn),不在受限于DSP資源,可以大大提高算力。將浮點轉(zhuǎn)化為二值有兩種方式,一種是設定閾值,超過閾值設為1,小于設為-1。即:
其中概率為:
隨機rounding不會導致參數(shù)分布發(fā)生偏移。
1) log量化
在一個2為底的對數(shù)表達中,參數(shù)被量化為一個2的冪次數(shù)據(jù)和尺度數(shù)。對數(shù)表達可以通過少量的bit位數(shù)涵蓋寬闊的數(shù)據(jù)范圍。比如3bit數(shù)據(jù),最大為8,用2的冪次表達可以涵蓋從0到255個數(shù)據(jù)范圍。使用了log表達的乘法就可以用移位操作來實現(xiàn)了,這大大節(jié)省了DSP的使用。
量化的方式主要分為兩種:一種是訓練后量化,一種是在訓練過程中量化。訓練后量化省去了重新量化,但是可能對精度造成較大損失。訓練過程量化,是在進行前向網(wǎng)絡計算的時候,使用量化參數(shù),而在反向傳播過程中存儲了浮點參數(shù),更新浮點參數(shù)。過程如下:
減少權重的方法也有很多,比如剪枝和結(jié)構化參數(shù)。剪枝是去除不重要的神經(jīng)元連接,大大減少了權重數(shù)據(jù),而結(jié)構化參數(shù)是通過設定閾值,讓某一塊的參數(shù)集體為0,這樣降低了參數(shù)存儲和計算量。這兩種方法的詳細介紹請見公眾號之前的文章。
3
FPGA中并行方法
CNN中可以進行并行化運算的結(jié)構有:輸入通道,輸出通道,圖像卷積。這其中輸出通道之間是沒有依賴關系的,而輸入通道的結(jié)果是需要求和的。圖像卷積每行輸出像素之間沒有依賴關系,但是每個結(jié)果像素是對應原來圖像多個像素的。即一個卷積核涵蓋大小的像素和對應卷積核相乘后累加。
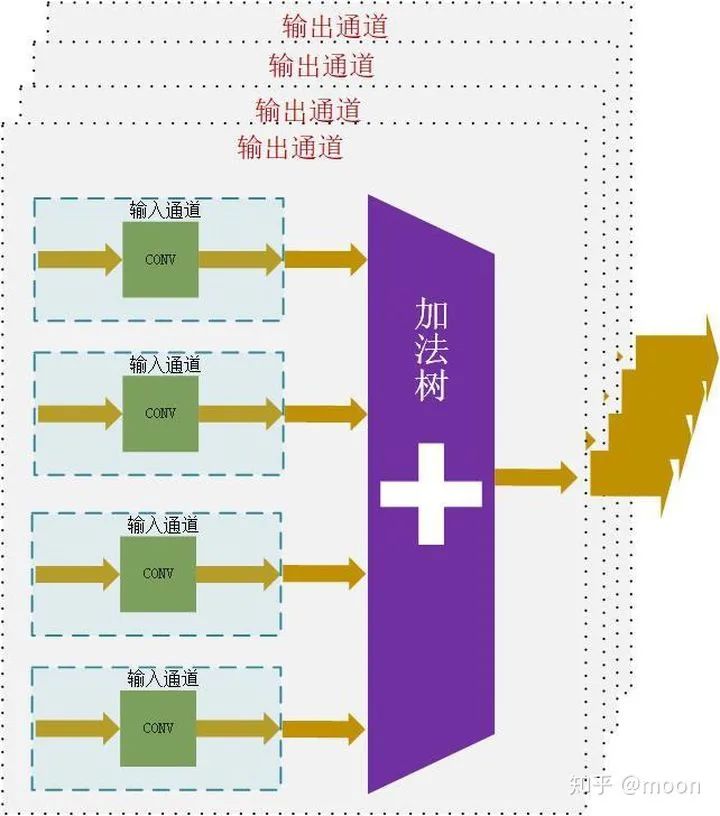
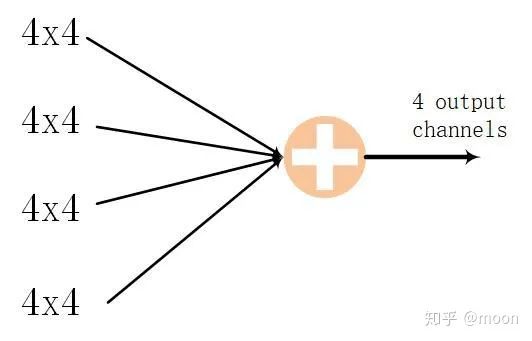
神經(jīng)網(wǎng)絡中輸入輸出通道數(shù)量通常都較大,從輸入輸出通道上并行是一個很好的加速方法。比如我們選擇4個輸入通道和4個輸出通道,如圖3.1所示。
圖3.1 輸入輸出通道并行化
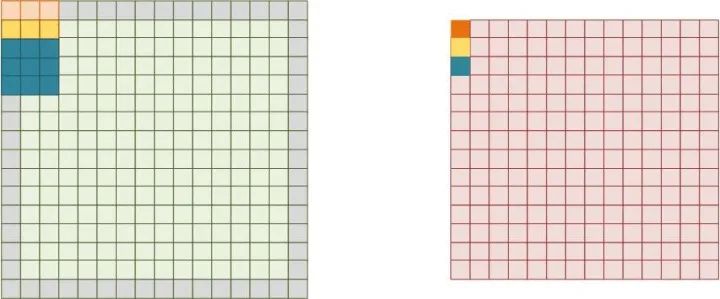
這樣就可以同時并行4x4個卷積運算,對于一個網(wǎng)絡層為16(輸入通道)x16(輸出通道)的卷積運算,應用上述結(jié)構,就可以這樣拆分來運算(圖3.2):每次都完成4x4通道運算,因為有16個輸入通道,進行4次這樣的運算,就可以輸出4個輸出通道數(shù)據(jù)。以同樣方法進行4次就實現(xiàn)了16x16網(wǎng)絡層的卷積運算。
因為輸入通道之間需要求和運算,所以使用了加法樹。隨著輸入通道變大,加法樹級數(shù)會變深。假設使用2輸入加法模塊,那么上述4通道結(jié)構的加法樹級數(shù)就是2。在進行FPGA設計的時候這是一個需要考慮的問題,輸入通道越多,加法樹的fan-in越大,那么在高速時鐘情況下,不同路徑時間的延時就會影響時序性能了。如果輸出通道變大,那么feature map數(shù)據(jù)的扇出就會變大,因為同一個feature map是被所有輸出通道共享的。
圖3.2 通過4次4x4運算,然后求和完成4輸出通道數(shù)據(jù)
輸入輸出通道的并行數(shù)收到了網(wǎng)絡層大小以及fan-in和fan-out的限制,不可能太大。所以要增加并行度還需要繼續(xù)探索圖像卷積。首先我們想到卷積不是多個像素和卷積核進行乘法嘛,那么我們也將這些乘法并行起來就可以啦。但是這樣存在一個問題就是:卷積核大小是不固定的,比如3x3卷積核中9個乘法被同時執(zhí)行,那么等到了1x1卷積核,就會只有1個乘法器被使用,降低了乘法器利用率。因此這樣并行不靈活。并行運算最好找到不存在依賴關系的運算。每行像素的輸出是并行的,沒有依賴關系的。那么就可以同時進行多行的卷積運算,而一個卷積核內(nèi)的乘法和加法就可以用一個乘法器和累加器來做,這樣就能適應不同卷積核大小的運算。多行并行運算如圖3.3。
圖3.3 3行卷積并行運算
采用以上輸入輸出通道的架構,缺點就是fan-out和fan-in較大,加法樹級數(shù)較大。有沒有什么方法可以降低fan-in和fan-out呢?如果將輸入通道的求和也使用累加來實現(xiàn),那就變成只有一個PE完成卷積運算以及不同通道的求和。但是一個PE卻降低了并行度,那么可以想到增加串行的PE數(shù)量來增加輸入并行度,即演變?yōu)橐涣蠵E來實現(xiàn)輸入通道求和。由于PE排序上的空間限制,導致后邊一個PE的計算相比于前一個PE要有1個周期延時,如果將數(shù)據(jù)從從PE間的移動打一拍,那正好可以在第二個PE計算出來的同時完成和前一個PE的求和,這就是脈動的關鍵所在。更具體的脈動陣列講解請看公眾號之前文章。
圖3.4 加法樹轉(zhuǎn)化為脈動結(jié)構
4
存儲結(jié)構
即使經(jīng)過了量化和剪枝等處理,網(wǎng)絡的參數(shù)也非常大(如表4.1),這在有限的FPGA資源下是無法全部存儲于片上的。因此需要一個片外存儲器(DDR)來存儲權重和信息數(shù)據(jù),在需要數(shù)據(jù)的時候從片外搬上片上來進行計算,并將結(jié)果存儲到片外存儲器。
表4.1 幾種網(wǎng)絡壓縮前和壓縮后大小對比
表4.2 幾種Xilinx器件存儲資源
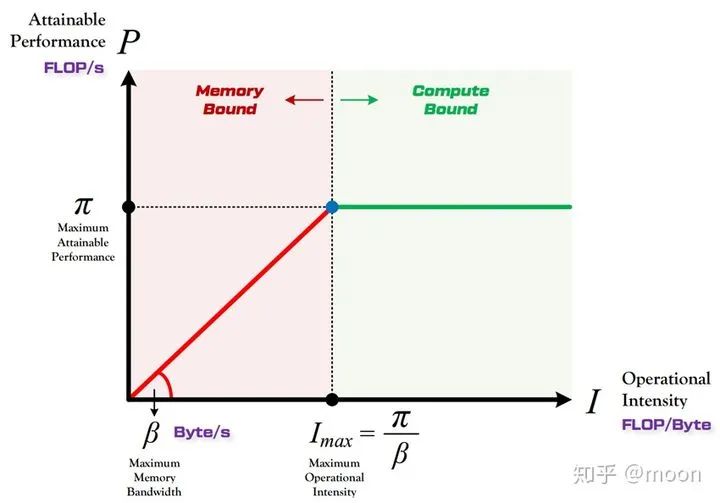
這時候影響網(wǎng)絡推理延時的因素就不僅僅包含算力的大小了,還需要考慮片上存儲大小,ddr帶寬,權重和信息數(shù)據(jù)復用率的影響。帶寬和算力對推理延時的綜合作用可以通過roofline圖來表示。所謂“Roof-line”,指的就是由計算平臺的算力和帶寬上限這兩個參數(shù)所決定的“屋頂”形態(tài)。Roofline的縱坐標表示算力,屋頂代表了FPGA所能達到的最大算力,橫坐標表示每byte數(shù)據(jù)可以參與多少次運算,表示了權重和信息數(shù)據(jù)的復用率。由roofline劃分出兩個瓶頸區(qū)域,一個是算力瓶頸,一個是帶寬瓶頸。當權重和數(shù)據(jù)復用率較高,即I大于FPGA所能達到的最大算力對應的復用率的時候,F(xiàn)PGA算力就是瓶頸,但是這種情況是好事情,因為FPGA的運算資源達到了100%的利用。如果數(shù)據(jù)復用率較低的時候,那么帶寬就成為瓶頸,因為在當前帶寬下,載入到片上的數(shù)據(jù)無法支持最大算力,這時候FPGA運算資源利用率沒有被全部利用,存在等待數(shù)據(jù)情形。
圖4.1 roofline圖
在一個CNN中,網(wǎng)絡越往后圖像大小越小,輸入輸出通道數(shù)量變大,這導致的結(jié)果就是權重參數(shù)的復用率變低,這個時候FPGA計算資源利用率就會降低。這個時候帶寬大小以及片上存儲就成為瓶頸。考慮片上存儲后,通過一個簡單模型來分析FPGA計算資源利用率。容易知道數(shù)據(jù)量和復用率同總計算量的關系:
其中D為數(shù)據(jù)量,I為數(shù)據(jù)復用率。那么FPGA運算資源自用率就可以表示為:
5
指令
指令實際上是一些控制FPGA流程的信息,比如載入多少數(shù)據(jù),進行哪些運算(conv,pool等)。這些控制信息會根據(jù)不同的網(wǎng)絡結(jié)構編輯好,存儲成二進制文件放到ddr中。通過FPGA讀入來控制操作。這些指令大體上包括以下幾種:
1) load weights/image:從ddr中加載權重或者image數(shù)據(jù)到片上來。這其中會包含ddr首地址,需要讀入的數(shù)據(jù)長度等信息。
2) conv:這個主要進行卷積運算,包括卷積核大小,圖像大小,輸入輸出通道等信息。
3) activate:激活函數(shù)的控制,控制是否進行激活操作。
4) save image:將運算完的結(jié)果存儲到ddr中,包括ddr地址,長度等信息。
總結(jié)
FPGA的靈活可配置結(jié)構非常適合不斷變化的網(wǎng)絡結(jié)構,同時其并行化和pipeline優(yōu)勢可以用于神經(jīng)網(wǎng)絡的加速。在進行FPGA設計的時候,需要考慮到并行化方式,存儲結(jié)構,如何平衡帶寬和算力之間的關系。
審核編輯 :李倩
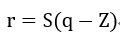
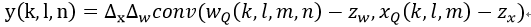
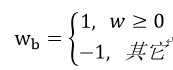
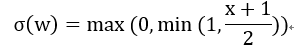
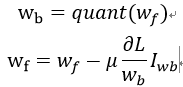



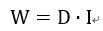
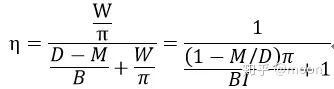
-
FPGA
+關注
關注
1643文章
21973瀏覽量
614341 -
神經(jīng)元
+關注
關注
1文章
368瀏覽量
18760 -
dnn
+關注
關注
0文章
61瀏覽量
9227
原文標題:在DNN中FPGA做了什么?
文章出處:【微信號:zhuyandz,微信公眾號:FPGA之家】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Debian和Ubuntu哪個好一些?
樹莓派在自動化控制項目中的一些潛在應用

使用ADS828采集模擬信號,隨著CLK的提高,采集到的數(shù)據(jù)會有一些毛刺怎么解決?
賽靈思低溫失效的原因,有沒有別的方法或者一些見解?
針對ZYNQ+ULTRASCALE的FPGA供電的一些疑問求解答
FPGA復位的8種技巧
一些常見的動態(tài)電路

分享一些常見的電路
FPGA和ASIC在大模型推理加速中的應用







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論