 AI/ML應用和處理器的架構探索
AI/ML應用和處理器的架構探索

行業背景
人工智能 (AI) 應用程序考慮了計算、存儲、內存、管道、通信接口、軟件和控制。此外,人工智能應用程序處理可以分布在處理器內的多核、PCIe 主干上的多個處理器板、分布在以太網網絡中的計算機、高性能計算機或跨數據中心的系統中。此外,人工智能處理器還具有巨大的內存大小要求、訪問時間限制、模擬和數字分布以及硬件-軟件分區。
問題
人工智能應用的架構探索很復雜,涉及多項研究。首先,我們可以針對單個問題,例如內存訪問,或者可以查看完整的處理器或系統。大多數設計都是從內存訪問開始的。有很多選擇——SRAM 與 DRAM、本地與分布式存儲、內存計算以及緩存反向傳播系數與丟棄。
第二個評估部門是總線或網絡拓撲。虛擬原型可以具有用于處理器內部的片上網絡、TileLink 或 AMBA AXI 總線、用于連接多處理器板和機箱的 PCIe 或以太網,以及用于訪問數據中心的 Wifi/5G/Internet 路由器。
使用虛擬原型的第三項研究是計算。這可以建模為處理器內核、多處理器、加速器、FPGA、Multi-Accumulate 和模擬處理。最后一部分是傳感器、網絡、數學運算、DMA、自定義邏輯、仲裁器、調度器和控制功能的接口。
此外,人工智能處理器和系統的架構探索具有挑戰性,因為它將數據密集型任務圖應用于硬件的全部功能。
模型構建
在 Mirabilis,我們使用 VisualSim 對 AI 應用程序進行架構探索。VisualSim 的用戶在具有大量 AI 硬件和軟件建模組件的圖形離散事件仿真平臺中非常快速地組裝虛擬原型。該原型可用于進行時間、吞吐量、功耗和服務質量的權衡。提供超過 20 種 AI 處理器和嵌入式系統模板,以加速開發新的 AI 應用程序。
為 AI 系統的權衡而生成的報告包括響應時間、吞吐量、緩沖區占用率、平均功率、能耗和資源效率。
ADAS模型構建
首先,讓我們考慮自動駕駛 (ADAS) 應用程序,這是圖 1 中的一種人工智能部署形式。ADAS 應用程序與計算機或電子控制單元 (ECU) 和網絡上的許多應用程序共存。 ADAS 任務的正確運行還依賴于現有系統的傳感器和執行器。
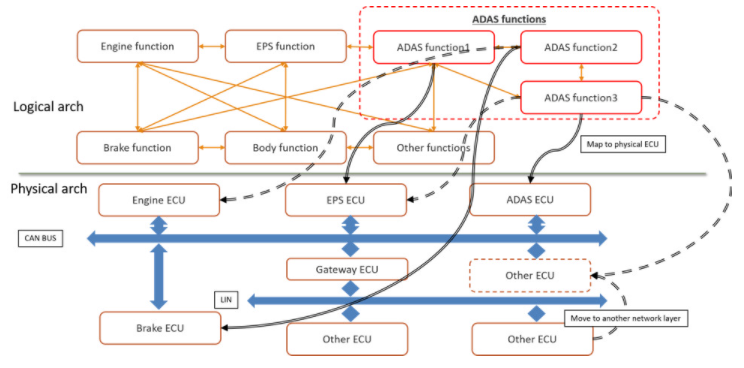
圖 1. 汽車設計中 AI 應用程序的邏輯到物理架構
早期的架構權衡可以測試和評估假設以快速識別瓶頸,并優化規范以滿足時序、吞吐量、功率和功能要求。在圖 1 中,您將看到體系結構模型需要硬件、網絡、應用程序任務、傳感器、衰減器和流量激勵來獲得對整個系統操作的可見性。圖 2 顯示了映射到物理架構的 ADAS 邏輯架構的實現。
架構模型的一個很好的特性是能夠分離設計的所有部分,這樣就可以研究單個操作的性能。在圖 2 中,您會注意到現有任務被單獨列出,網絡與 ECU、傳感器生成和 ADAS 邏輯任務組織。ADAS 任務圖中的每個功能都映射到一個 ECU。
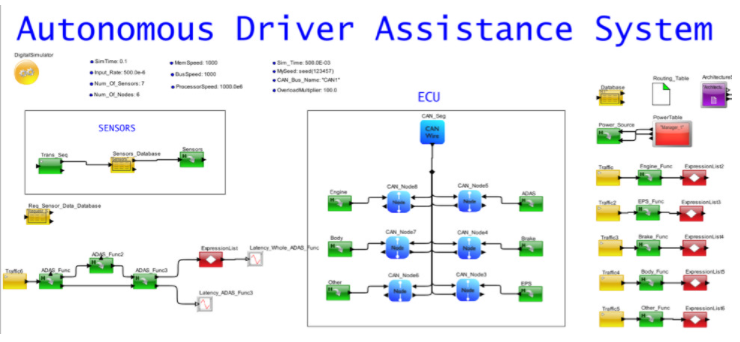
圖 2. ADAS 映射到 ECU 網絡的汽車系統系統模型
ADAS分析
當模擬圖2中的ADAS模型時,可以得到各種報告。在圖 3 中,顯示了完成 ADAS 任務的延遲以及電池為此任務耗散的相關熱量。其他感興趣的圖可以是測量的功率、網絡吞吐量、電池消耗、CPU 利用率和緩沖區占用。
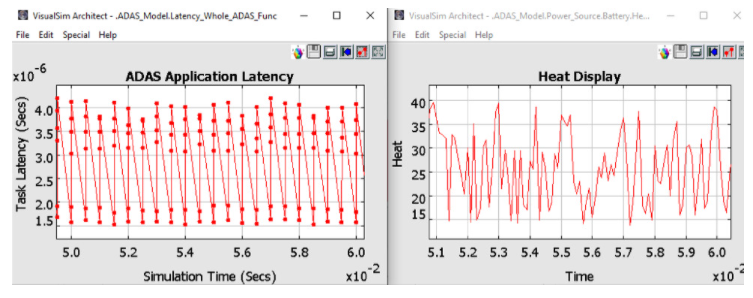
圖 3. ADAS 架構模型的分析報告
處理器模型構建
AI 處理器和系統的設計人員針對應用程序類型、訓練與推理、成本點、功耗和尺寸限制進行實驗。例如,設計人員可以將子網絡分配到流水線階段,權衡深度神經網絡 (DNN) 與傳統機器學習算法,測量 GPU、TPU、AI 處理器、FPGA 和傳統處理器上的算法性能,評估融合計算和內存的好處在芯片上計算類似于人腦功能的模擬技術對功率的影響,并構建具有針對單個應用程序的部分功能集的 SoC。
從 PowerPoint 到新 AI 處理器的第一個原型的時間非常短,第一個生產樣品不能有任何瓶頸或錯誤。因此,建模成為強制性的。
圖 4 顯示了 Google 張量處理器的內部視圖。框圖已轉換為圖 5 中的架構模型。處理器通過 PCIe 接口接收來自主機的請求。MM、TG2、TG3 和 TG4 是來自獨立主機的不同請求流。權重存儲在片外 DDR3 中并被調用到權重 FIFO。到達的請求在統一本地緩沖區中存儲和更新,并發送到矩陣多單元進行處理。當請求通過 AI 管道處理完畢后,將其返回到統一緩沖區以響應主機。
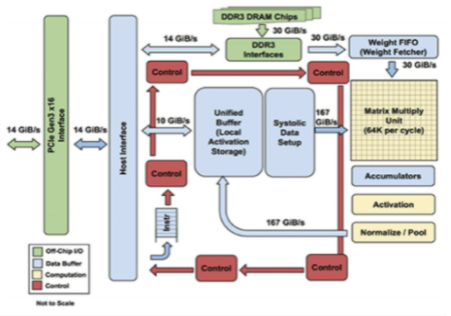
圖 4. 來自 Google 的 TPU-1
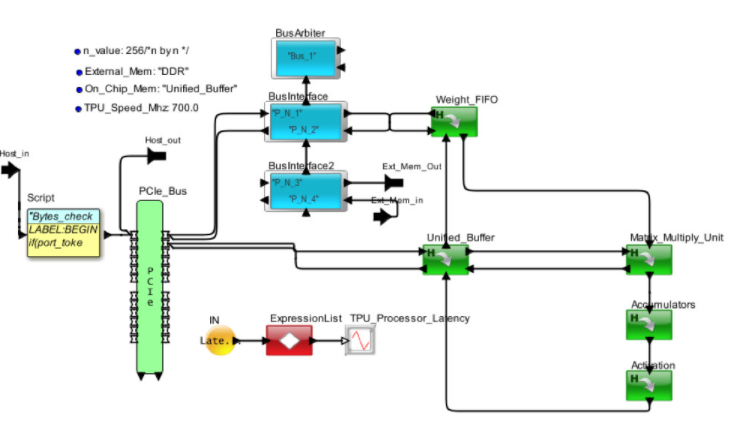
圖5. AI 硬件架構的 VisualSim 模型頂視圖
處理器模型分析
在圖 6 中,您可以查看片外 DDR3 中的延遲和反向傳播權重管理。延遲是從主機發送請求到接收響應的時間。您將看到 TG3 和 TG4 能夠分別保持低延遲,直到 200 us 和 350 us。MM 和 TG2 在模擬的早期就開始緩沖。由于這組流量配置文件存在大量緩沖并且延遲增加,因此當前的 TPU 配置不足以處理負載和處理。TG3 和 TG4 的更高優先級有助于維持更長的運營時間。
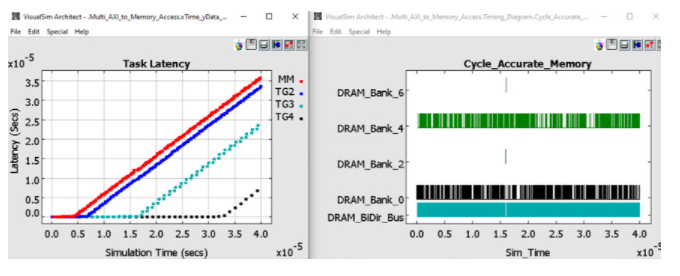
圖 6. 架構探索權衡的統計數據
汽車設計施工
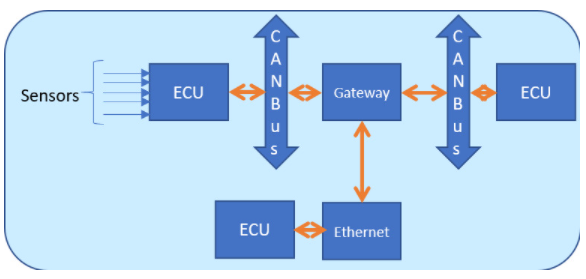
圖 7. 帶有 CAN 總線、傳感器和 ECU 的汽車網絡
當今的汽車設計包含許多需要大量機器學習和推理的安全和自動駕駛功能。可用的時間表將決定處理是在 ECU 完成還是發送到數據中心。例如,可以在本地進行制動決策,同時可以將空調溫度的變化發送到遠程處理。兩者都需要一些基于輸入傳感器和攝像頭的人工智能。
圖 7 是包含 ECU、CAN-FD、以太網和網關的網絡框圖。
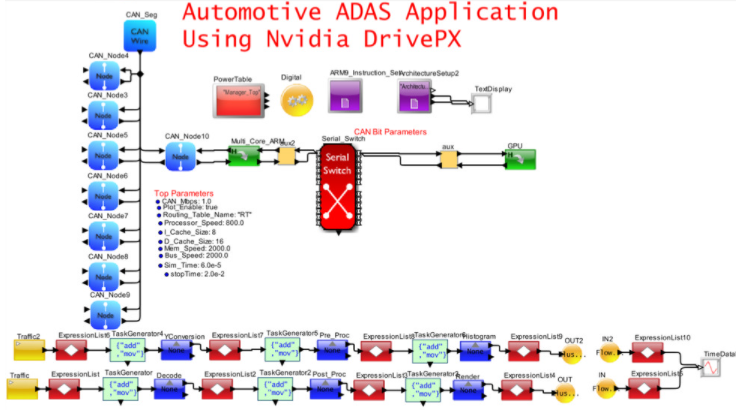
圖 8. 自動駕駛和 E/E 架構的 VisualSim 模型
圖 8 捕獲了圖 7 的一部分,它將 CAN-FD 網絡與包含多個 ARM 內核和一個 GPU 的高性能 Nvidia DrivePX 集成。以太網/TSN/AVB 和網關已從模型中移除以簡化視圖。在此模型中,重點是了解 SoC 的內部行為。該應用程序是由車輛上的攝像頭傳感器觸發的 MPEG 視頻捕獲、處理和渲染。
汽車設計分析
圖 9 顯示了 AMBA 總線和 DDR3 內存的統計數據。您可以看到跨多個主服務器的工作負載分布。可以評估應用程序管道的瓶頸,確定最高周期時間的任務、內存使用情況以及每個單獨任務的延遲。
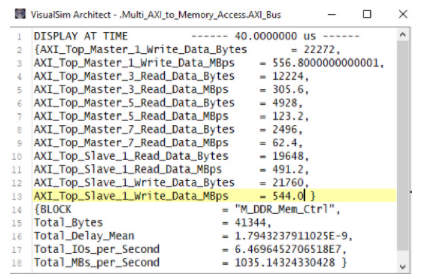
圖 9. 總線和內存活動報告
用例和流量模式應用于作為硬件、RTOS 和網絡組合的架構模型。周期性流量配置文件用于對雷達、激光雷達和攝像頭進行建模,而用例可以是自動駕駛、聊天機器人、搜索、學習、推理、大數據處理、圖像識別和疾病檢測。用例和流量可以根據輸入速率、數據大小、處理時間、優先級、依賴性、先決條件、反向傳播循環、系數、任務圖和內存訪問而變化。通過改變屬性在系統模型上模擬用例。這會生成各種統計數據和圖表,包括緩存命中率、流水線利用率、拒絕的請求數、每條指令或任務的瓦特數、吞吐量、緩沖區占用率和狀態圖。
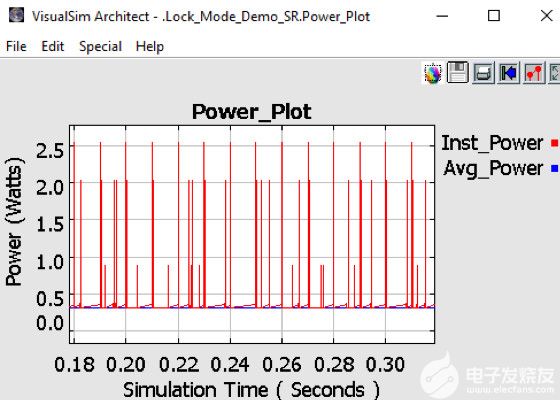
圖 10. 實時測量 AI 處理器的功耗
圖 10 顯示了系統和芯片的功耗。除了散熱、電池充電消耗率和電池生命周期變化外,該模型還可以捕捉動態功率變化。該模型繪制了每個設備的狀態活動、相關的瞬時峰值和系統的平均功率。獲得有關功耗的早期反饋有助于熱和機械團隊設計外殼和冷卻方法。大多數機箱對每個板都有最大功率限制。這種早期的功耗信息可用于執行架構與性能的權衡,從而尋找降低功耗的方法。
進一步的探索場景
以下是一些突出使用 AI 架構模型和分析的附加示例。
1. 360度激光掃描儀、立體攝像頭、魚眼攝像頭、毫米波雷達、聲納或激光雷達的自動駕駛系統,通過網關連接到多個IEEE802.1Q網絡上的20個ECU。該原型用于測試 OEM 硬件配置的功能包,以確定硬件和網絡要求。主動安全行動的響應時間是主要標準。
2. 用于學習和推理任務的人工智能處理器是使用由 32 個內核、32 個加速器、4 個 HBM2.0、8 個 DDR5、多個 DMA 和完整緩存一致性構建的片上網絡骨干定義的。該模型使用 RISC-V、ARM Z1 和專有內核的變體進行了試驗。實現的目標是鏈路上的 40Gbps,同時保持較低的路由器頻率并重新訓練網絡路由。
3. 需要一個 32 層的深度神經網絡,將內存從 40GB 降低到 7GB 以下。數據吞吐量和響應時間沒有改變。該模型設置有用于處理和反向傳播的內存訪問行為的功能流程圖。對于不同的數據大小和任務圖,該模型確定了數據的丟棄量以及各種片外 DRAM 大小和 SSD 存儲選項。任務圖隨任意數量的圖和幾個輸入和輸出而變化。
4. 使用ARM處理器和AXI總線進行低成本AI處理的通用SoC。目標是獲得最低的每瓦功率,從而最大限度地提高內存帶寬。乘法累加函數被卸載到向量指令,加密到 IP 核,以及自定義算法到加速器。構建該模型的明確目的是評估不同的高速緩存存儲器層次結構以提高命中率和總線拓撲以減少延遲。
5. 模數 AI 處理器需要對功耗進行徹底分析,并對所達到的吞吐量進行準確分析。在該模型中,非線性控制在離散事件模擬器中建模為一系列線性函數,以加快模擬時間。在這種情況下,對功能進行了測試以檢查行為并衡量真正的節能效果。
審核編輯:郭婷
-
存儲器
+關注
關注
38文章
7651瀏覽量
167391 -
神經網絡
+關注
關注
42文章
4814瀏覽量
103608 -
soc
+關注
關注
38文章
4388瀏覽量
222754
發布評論請先 登錄
龍芯處理器支持WINDOWS嗎?
技術分享 | 如何在2k0300(LoongArch架構)處理器上跑通qt開發流程

Cadence推出Tensilica NeuroEdge 130 AI協處理器
光子 AI 處理器的核心原理及突破性進展
在線研討會 @4/10 ASTRA?賦能邊緣 AI:探索 Synaptics SL &amp; SR 處理器的無限可能

端側 AI 音頻處理器:集成音頻處理與 AI 計算能力的創新芯片
迅為3A6000_7A2000核心主板龍芯全國產處理器LoongArch架構
對稱多處理器和非對稱多處理器的區別
簡述微處理器的指令集架構
AMD全新處理器擴大數據中心CPU的領先地位
AMD推出全新銳龍AI 300系列處理器
ARM處理器和CISC處理器的區別
X86架構處理器有哪些優點和缺點
微處理器的指令集架構介紹






 工商網監
工商網監
評論