 只需添加幾行代碼,就能實現大模型的低成本訓練和微調
只需添加幾行代碼,就能實現大模型的低成本訓練和微調

不得不說,為了讓更多人能用上大模型,技術圈真是各出奇招!
模型不夠開放?有人自己上手搞免費開源版。
比如最近風靡全網的DALL·E Mini,Meta開放的OPT-175B(Open Pretrained Transformer)。
都是通過復刻的方式,讓原本不夠open的大模型,變成人人可用。
還有人覺得模型太大,個人玩家很難承受起天價成本。
所以提出異構內存、并行計算等方法,讓大模型訓練加速又降本。
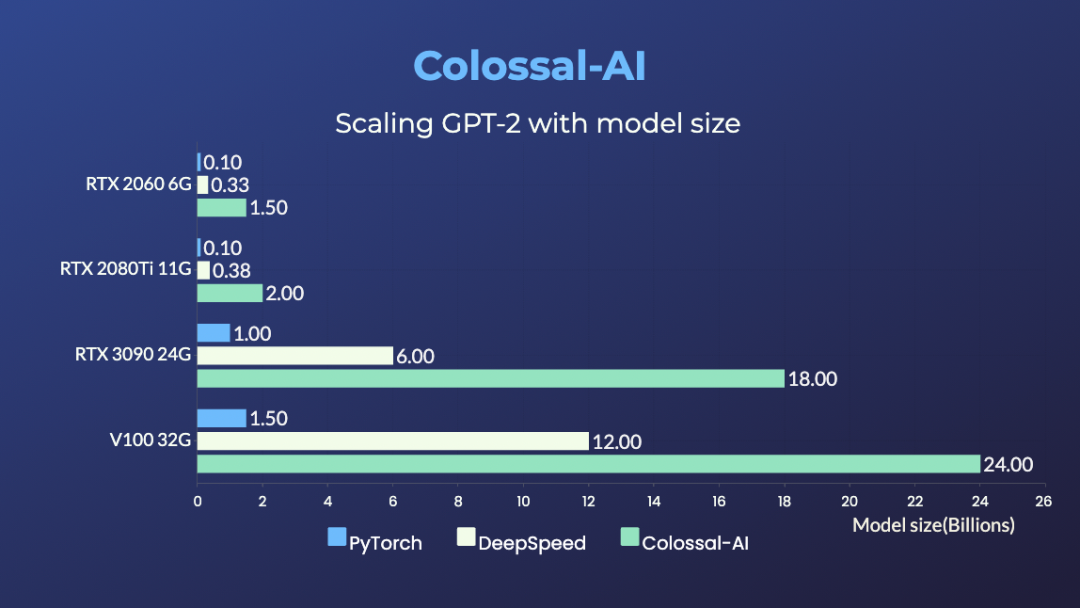
比如開源項目Colossal-AI,前不久剛實現了讓一塊英偉達3090就能單挑180億參數大模型。
而在這兩天,他們又來了一波上新:
無縫支持Hugging Face社區模型,只需添加幾行代碼,就能實現大模型的低成本訓練和微調。

要知道,Hugging Face作為當下最流行的AI庫之一,提供了超過5萬個AI模型的實現,是許多AI玩家訓練大模型的首選。
而Colossal-AI這波操作,是讓公開模型的訓練微調變得更加切實可行。
并且在訓練效果上也有提升。
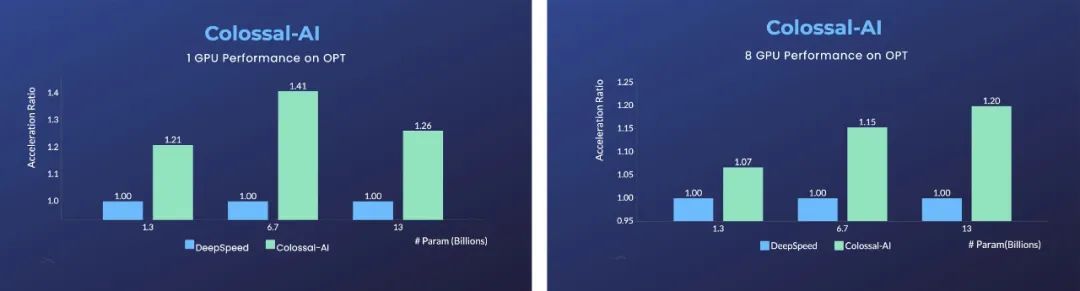
單張GPU上,相比于微軟的DeepSpeed,使用Colossal-AI的自動優化策略,最快能實現40%的加速。
而PyTorch等傳統深度學習框架,在單張GPU上已經無法運行如此大的模型。
對于使用8張GPU的并行訓練,僅需在啟動命令中添加-nprocs 8就能實現。
這波下來,可以說是把個人AI玩家需要考慮的成本、效率、實操問題,都拿捏住了~
無需修改代碼邏輯
光說不練假把式。
下面就以OPT為例,詳細展開看看Colossal-AI的新功能到底怎么用。
OPT,全稱為Open Pretrained Transformer。
它由Meta AI發布,對標GPT-3,最大參數量可達1750億。
最大特點就是,GPT-3沒有公開模型權重,而OPT開源了所有代碼及權重。
因此,每一位開發者都能在此基礎上開發個性化的下游任務。
下面的舉例,就是根據OPT提供的預訓練權重,進行因果語言模型(Casual Language Modelling)的微調。
主要分為兩個步驟:
-
添加配置文件
-
運行啟動
第一步,是根據想進行的任務添加配置文件。
比如在一張GPU上,以異構訓練為例,只需在配置文件里加上相關配置項,并不需要更改代碼的訓練邏輯。
比如,tensor_placement_policy決定了異構訓練的策略,參數可以為CUDA、CPU及auto。
每個策略的優點不同、適應的情況也不一樣。
CUDA:將全部模型參數都放置于GPU上,適合不offload時仍然能進行訓練的傳統場景。
CPU:將模型參數都放置在CPU內存中,僅在GPU顯存中保留當前參與計算的權重,適合超大模型的訓練。
auto:根據實時的內存信息,自動決定保留在GPU顯存中的參數量,這樣能最大化利用GPU顯存,同時減少CPU-GPU之間的數據傳輸。
對于普通用戶來說,使用auto策略是最便捷的。
這樣可以由Colossal-AI自動化地實時動態選擇最佳異構策略,最大化計算效率。
from colossalai.zero.shard_utils import TensorShardStrategyzero = dict(model_config=dict(shard_strategy=TensorShardStrategy(),tensor_placement_policy="auto"),optimizer_config=dict(gpu_margin_mem_ratio=0.8))
第二步,是在配置文件準備好后,插入幾行代碼來啟動新功能。
首先,通過一行代碼,使用配置文件來啟動Colossal-AI。
Colossal-AI會自動初始化分布式環境,讀取相關配置,然后將配置里的功能自動注入到模型及優化器等組件中。
colossalai.launch_from_torch(config='./configs/colossalai_zero.py')
然后,還是像往常一樣定義數據集、模型、優化器、損失函數等。
比如直接使用原生PyTorch代碼,在定義模型時,只需將模型放置于ZeroInitContext下初始化即可。
在這里,使用的是Hugging Face提供的OPTForCausalLM模型以及預訓練權重,在Wikitext數據集上進行微調。
with ZeroInitContext(target_device=torch.cuda.current_device(),shard_strategy=shard_strategy,shard_param=True):model = OPTForCausalLM.from_pretrained('facebook/opt-1.3b'config=config)
接下來,只需要調用colossalai.initialize,便可將配置文件里定義的異構內存功能統一注入到訓練引擎中,即可啟動相應功能。
train_dataloader, eval_dataloader, lr_scheduler = colossalai.initialize(model=model,optimizer=optimizer,criterion=criterion,train_dataloader=train_dataloader,test_dataloader=eval_dataloader,lr_scheduler=lr_scheduler)
還是得靠GPU+CPU異構
而能夠讓用戶實現如上“傻瓜式”操作的關鍵,還是AI系統本身要足夠聰明。
發揮核心作用的是Colossal-AI系統的高效異構內存管理子系統Gemini。
它就像是系統內的一個總管,在收集好計算所需的信息后,動態分配CPU、GPU的內存使用。
具體工作原理,就是在前面幾個step進行預熱,收集PyTorch動態計算圖中的內存消耗信息。
在預熱結束后,計算一個算子前,利用收集的內存使用記錄,Gemini將預留出這個算子在計算設備上所需的峰值內存,并同時從GPU顯存移動一些模型張量到CPU內存。
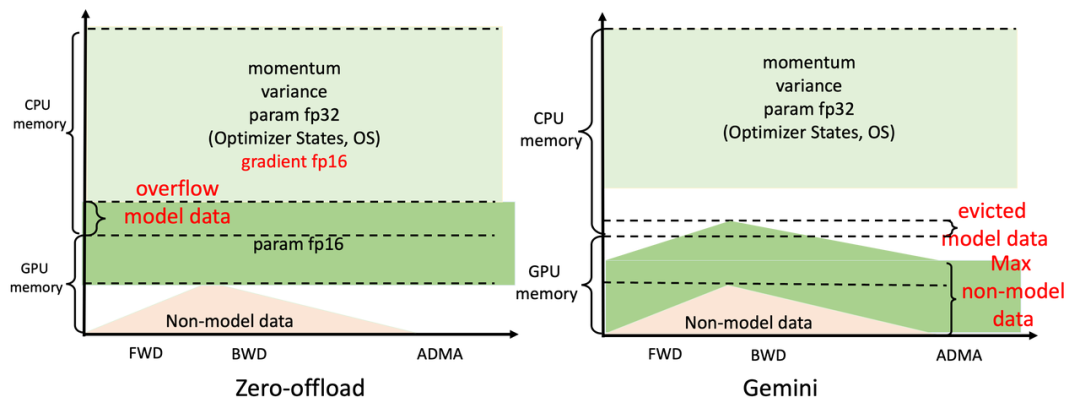
Gemini內置的內存管理器給每個張量都標記一個狀態信息,包括HOLD、COMPUTE、FREE等。
然后,根據動態查詢到的內存使用情況,不斷動態轉換張量狀態、調整張量位置。
帶來的直接好處,就是能在硬件非常有限的情況下,最大化模型容量和平衡訓練速度。
要知道,業界主流方法ZeRO (Zero Reduency Optimizer),盡管也利用CPU+GPU異構內存的方法,但是由于是靜態劃分,還是會引起系統崩潰、不必要通信量等問題。
而且,使用動態異構CPU+GPU內存的辦法,還能用加內存條的辦法來擴充內存。
怎么也比買高端顯卡劃算多了。
目前,使用Colossal-AI的方法,RTX 2060 6GB普通游戲本能訓練15億參數模型;RTX 3090 24GB主機直接單挑180億參數大模型;Tesla V100 32GB連240億參數都能拿下。
除了最大化利用內存外,Colossal-AI還使用分布式并行的方法,讓訓練速度不斷提升。
它提出同時使用數據并行、流水并行、2.5維張量并行等復雜并行策略。
方法雖復雜,但上手卻還是非常“傻瓜操作”,只需簡單聲明,就能自動實現。
無需像其他系統和框架侵入代碼,手動處理復雜的底層邏輯。
parallel = dict(pipeline=2,tensor=dict(mode='2.5d', depth = 1, size=4))
Colossal-AI還能做什么?
實際上,自開源以來,Colossal-AI已經多次在GitHub及Papers With Code熱榜位列世界第一,在技術圈小有名氣。
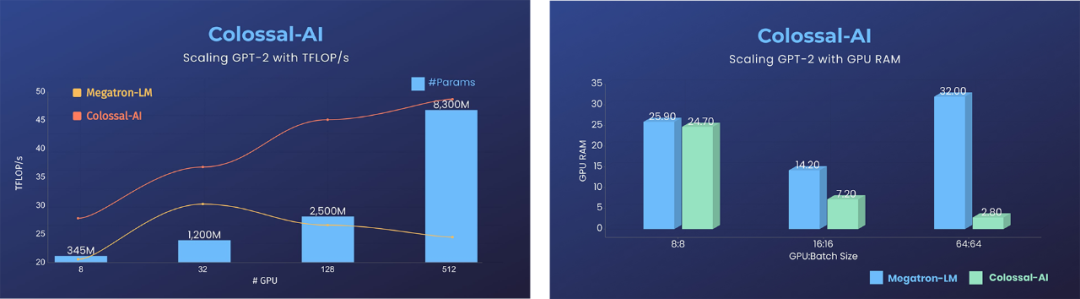
除了如上提到的用單張GPU訓練大模型外,Colossal-AI在擴展至數十張甚至數百張GPU的大規模并行場景時,相比于英偉達Megatron-LM等現有系統,性能可以翻倍,使用資源可以降低至其十分之一之下。
換算一下,在預訓練GPT-3等超大AI模型上,節省的費用可以達到數百萬元。
據透露,Colossal-AI相關的解決方案已經被自動駕駛、云計算、零售、醫藥、芯片等行業的知名廠商用上了。
與此同時,他們也非常注重開源社區建設,提供中文教程、開放用戶社群論壇,根據大家的需求反饋不斷更新迭代。
比如我們發現,之前有粉絲留言詢問,Colossal-AI能否直接加載Hugging Face上的一些模型?
好嘛,這次更新就來了。

所以,對于大模型訓練,你覺得現在還有哪些難點亟需解決呢?
審核編輯 :李倩
-
開源
+關注
關注
3文章
3695瀏覽量
43852 -
模型
+關注
關注
1文章
3522瀏覽量
50447 -
代碼
+關注
關注
30文章
4900瀏覽量
70793 -
大模型
+關注
關注
2文章
3148瀏覽量
4087
原文標題:1塊GPU+幾行代碼,大模型訓練提速40%!無縫支持HuggingFace,來自國產開源項目?
文章出處:【微信號:iotmag,微信公眾號:iotmag】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用OpenVINO?訓練擴展對水平文本檢測模型進行微調,收到錯誤信息是怎么回事?
讓大模型訓練更高效,奇異摩爾用互聯創新方案定義下一代AI計算
阿里巴巴Qwen大模型助力開發低成本DeepSeek替代方案
Qwen大模型助力開發低成本AI推理方案
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
大模型訓練框架(五)之Accelerate
英偉達推出基石世界模型Cosmos,解決智駕與機器人具身智能訓練數據問題

使用ReMEmbR實現機器人推理與行動能力
從零開始訓練一個大語言模型需要投資多少錢?







 工商網監
工商網監
評論