") JMEE利用句法樹以及GCN來建模多事件之間的關(guān)聯(lián)
JMEE利用句法樹以及GCN來建模多事件之間的關(guān)聯(lián)

寫在前面
今天要跟大家分享的是發(fā)表在EMNLP的一篇事件抽取的工作JMEE。JMEE針對的是多事件觸發(fā)詞及角色聯(lián)合抽取問題,其中多事件是指在待處理的同一文本范圍內(nèi)存在多個不同事件。
同一文本范圍內(nèi)的多個事件間通常具有一定的相關(guān)性,對相關(guān)性進(jìn)行建模將有助于消除事件觸發(fā)的歧義,提高事件抽取的效果。
本文分享的JMEE首先利用句法樹將輸入文本從序列模式轉(zhuǎn)換到句法依存圖模式,以此縮短token之間信息傳遞的距離;然后,在句法依存圖上利用圖卷積來進(jìn)行節(jié)點信息聚合;最后,為了利用多事件之間的關(guān)聯(lián),設(shè)計了self-attention機(jī)制來計算上下文表征向量。結(jié)合以上方法,JMEE在多事件句的事件抽取任務(wù)上相對于其他方法取得了一定的提升。

1. 背景知識
在正式開始分享論文內(nèi)容之前,我們先介紹下事件抽取。按照比較標(biāo)準(zhǔn)的定義,事件抽取本身包括兩個子任務(wù):
事件檢測(Event Detection):檢測觸發(fā)詞(最能代表一個事件發(fā)生的詞),同時還要正確判定其事件類型;
論元檢測(Argument Detection):檢測事件的相關(guān)元素,同時正確判定這些元素在這個事件中承擔(dān)的角色。
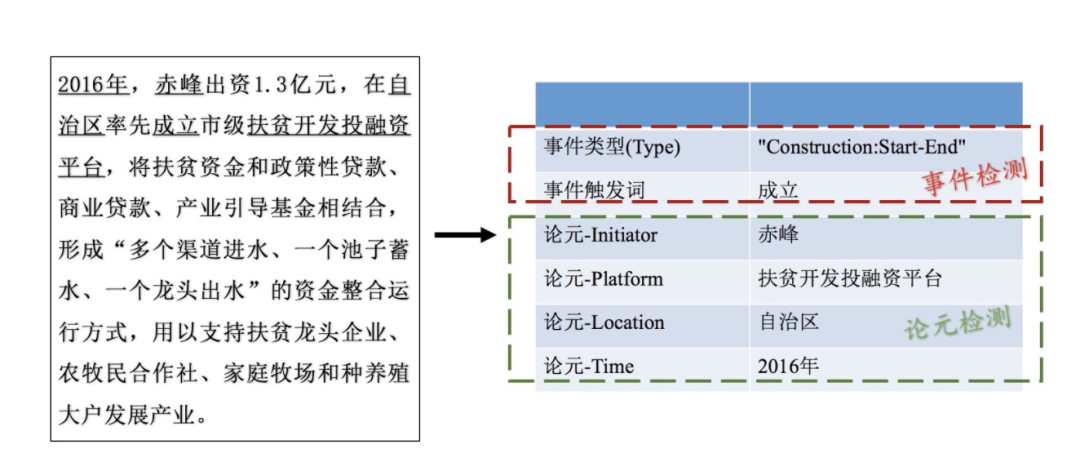
上圖是一個直觀的例子。圖中左側(cè)是常見的無結(jié)構(gòu)化文本,右側(cè)是事件抽取結(jié)果。事件檢測發(fā)現(xiàn)了 "成立" 這個觸發(fā)詞,并且判定其事件類型為 "Construction" ;論元檢測則發(fā)現(xiàn)了事件"construction" 發(fā)生的時間、地點、執(zhí)行者以及所作用的對象。
2. 多事件
在第一節(jié)所示的例子里,一個句子中只出現(xiàn)了一個事件。實際上,更常見的情形是一個句子中存在多個事件:

這里暫稱只含一個事件的句子為單事件句,含多個事件的句子為多事件句。相對于單事件句而言,多事件句的事件抽取是相對更難。
論文原文說 “因為多個事件之間往往是相互關(guān)聯(lián)的,所以多事件抽取才更難” 。個人不太認(rèn)可這個因果關(guān)系的說法。一方面,小喵覺得“多個事件判定比一個事件判定要難” 這個說法沒問題,但不是因為事件之間的相關(guān)性讓這個問題變得難;另一方面,事件之間的相關(guān)性真正的作用是有助于多事件場景中事件類型的判定。
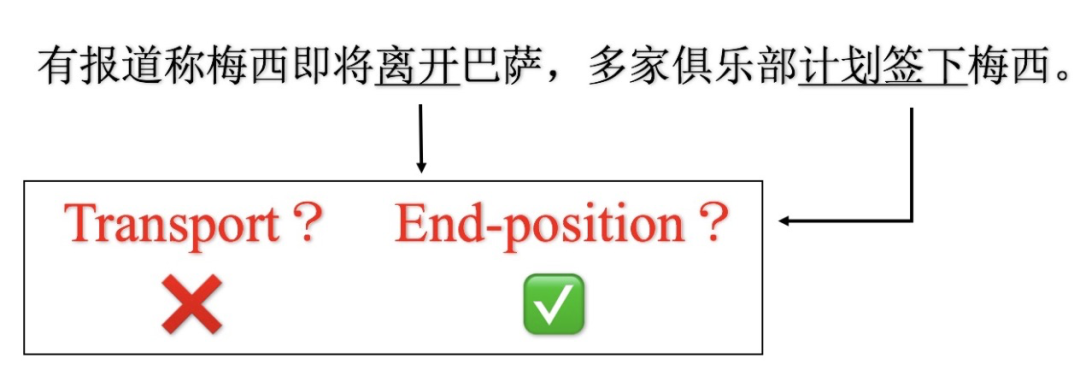
在多事件場景下單獨對每一個事件進(jìn)行判定很有可能出錯。假設(shè)我們不知道 "巴薩" 代表的是“巴薩羅那足球俱樂部” ,那么“梅西即將離開巴薩"中的 “離開” 可能是“離開某個地方”,也可以是 “不在為球隊效力” ;但是結(jié)合“計劃簽下”這個事件的意思,我們可以知道 “離開” 不是 “離開某個地方” 而是 “不在為球隊效力”。
3. JMEE核心思想
3.1 整體思想
JMEE主要是通過引入句法樹構(gòu)建詞網(wǎng)絡(luò)以及后續(xù)的GCN、self-attention來捕獲事件間的相關(guān)性,從而獲得更好的詞/字的語義表征,在此基礎(chǔ)上再進(jìn)行后續(xù)的工作。其中,引入句法樹是關(guān)鍵的關(guān)鍵。
3.2 為什么要引入句法樹
我們來看下為什么要引入句法樹。
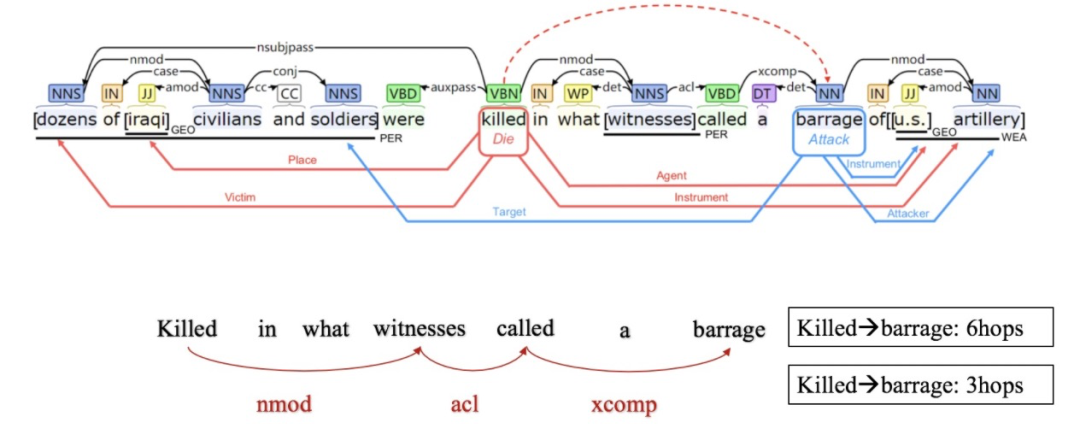
上圖例子中共有兩個觸發(fā)詞,即:“killed”和“barrage”,他們之間間隔了5個其他詞。換句話說,從“killed” 到“barrage”需要6步 (6hop,6跳)。實際上,多個事件觸發(fā)詞之間的距離可能遠(yuǎn)大于我們例子中的6。
另一方面,句中兩個詞的距離往往大于其在依存樹中的距離,比如“killed”和“barrage”在句子中的距離為6,但在句法樹中他們的距離僅僅為3。上圖底部我用紅色箭頭標(biāo)出了3跳的路徑,紅色的3個箭頭組成了一個shortcut path。通過這個shortcut path,我們就可以使用較少的跳數(shù),使信息從"killed"轉(zhuǎn)移向"barrage"。也就是說,從句法樹建模詞與詞的依賴關(guān)系更容易也更直接。
所以JMEE引入句法樹,利用句法樹的依賴關(guān)系連接詞/字,縮短詞/字之間的信息傳遞需要的距離(跳數(shù));此外,引入句法樹后也可以自然地從圖卷積的角度來進(jìn)行后續(xù)的操作。
4. 模型細(xì)節(jié)
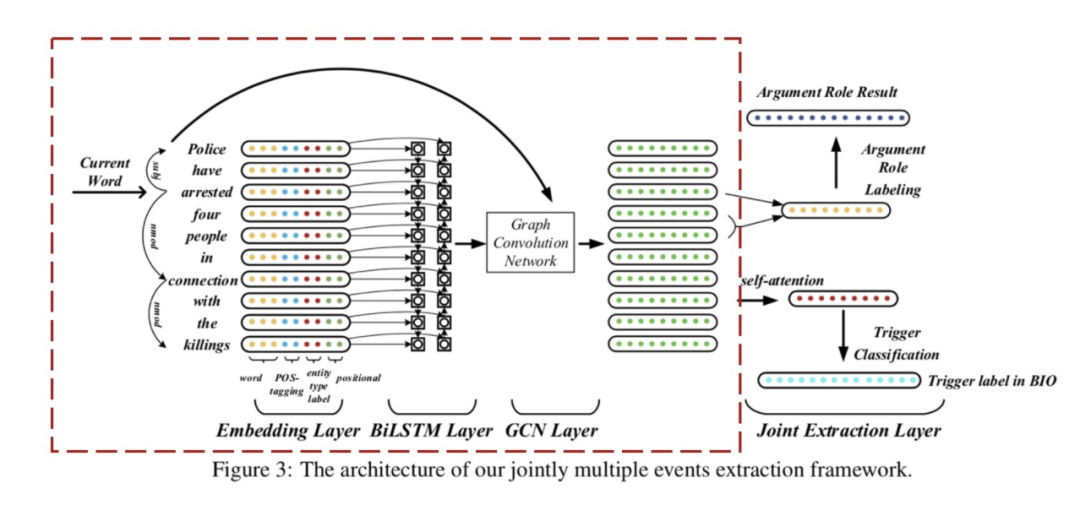
現(xiàn)在我們來看下JMEE模型的具體細(xì)節(jié)。JMEE整體框架大體上包括4部分:詞嵌入、句法圖卷積模塊、觸發(fā)詞檢測模塊、論元檢測模塊。實際上,一直到句法圖卷積模塊都是在做表示學(xué)習(xí)。
4.1 詞嵌入
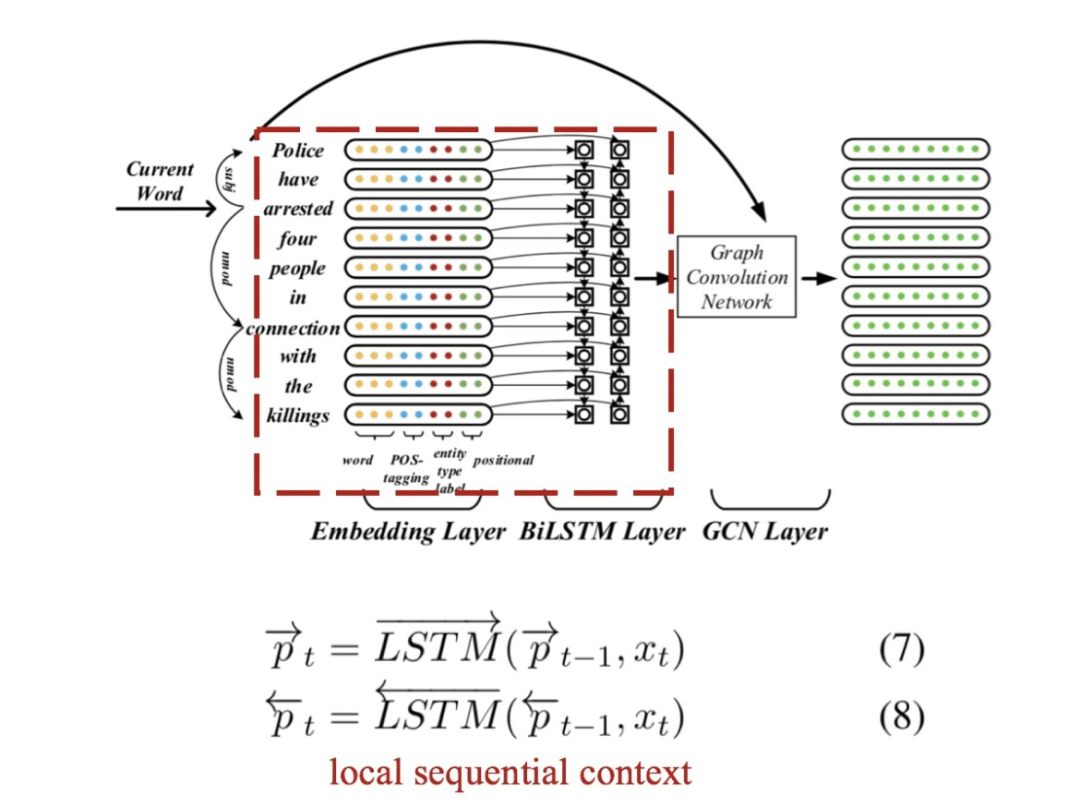
前面我們說引入句法樹依賴關(guān)系后,很自然地就可以用圖卷積的方式來做相應(yīng)的詞的表征了。但實際上,JMEE并沒有一上來就這么做。因為如果完全依靠句法樹里的依賴關(guān)系,某些詞的左右詞所涵蓋的local context可能就被忽視了(本來直接一步或幾步就能達(dá)到卻變成需要很多步之后才能到了)。所以,JMEE選擇先利用雙向LSTM來捕獲這種local context:
其中為輸入文本中第個token(詞或字)的表征向量,其利用了實體、詞性、位置等信息,具體地由以下四個向量拼接而成:
的詞嵌入(word embedding):從預(yù)先訓(xùn)練好的詞向量模型中獲得,JMEE選擇的詞向量模型為Glove;
的詞性嵌入(Pos-tagging label embedding):利用隨機(jī)初始化Pos-tagging label embedding table將的詞性標(biāo)簽轉(zhuǎn)換成實值向量;
的位置嵌入(Positional embedding):假設(shè)是當(dāng)前詞,那么為與的相對距離;利用隨機(jī)初始化的Position embedding tabel將轉(zhuǎn)換為實值向量;
的實體類型的嵌入:利用隨機(jī)初始化的entity label embeeding label將對應(yīng)的BIO實體類別標(biāo)簽如B-Name轉(zhuǎn)換為實值向量。
LSTM層的輸出作為圖卷積的初始值。
4.2 圖卷積
文章沒有給出具體的網(wǎng)絡(luò)圖,所以下面我們直接來看公式。
圖卷積部分整體上是比較簡單的,把句中詞/字當(dāng)作網(wǎng)絡(luò)圖中的節(jié)點,利用節(jié)點的鄰居來加權(quán)表征節(jié)點自己。這里的關(guān)鍵在于鄰居節(jié)點以及邊類型的定義。
節(jié)點
舉個例子,假設(shè)當(dāng)前節(jié)點是下圖中的“arrested”,它的鄰居節(jié)點就是與它通過句法依賴直接關(guān)聯(lián)的詞“police”、“connection”。注意,可能包括自己,因為可能有自環(huán)。
邊及邊類型
至于節(jié)點間的連邊以及邊類型,JMEE直接利用的是句法依賴關(guān)系。所以,這個例子中節(jié)點 “police“ 與節(jié)點 “arrested”,連邊類型為:
節(jié)點“police“ 與節(jié)點 “connection” 相連,連邊類型為:
圖卷積
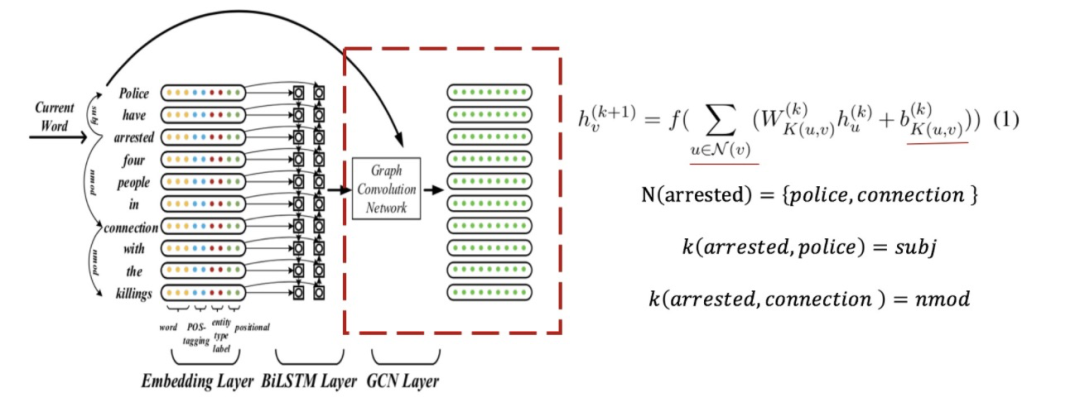
圖卷積模塊的第層,節(jié)點的圖卷積向量為:
這里表示邊(u,v)的類型標(biāo)簽;而、則分別是與類型標(biāo)簽的相關(guān)的權(quán)重參數(shù)和偏置參數(shù);是激活函數(shù);詞嵌入模塊的最終輸出,即。
連邊類別重新定義
假設(shè),句法依賴關(guān)系共有種,再加上反向邊和自環(huán)后,一層圖卷積層就會有個權(quán)重參數(shù)和偏置參數(shù),這個參數(shù)量太大了。為了減少參數(shù)量,JMEE重新定義了邊類型,最終只維護(hù)了3種類型標(biāo)簽:
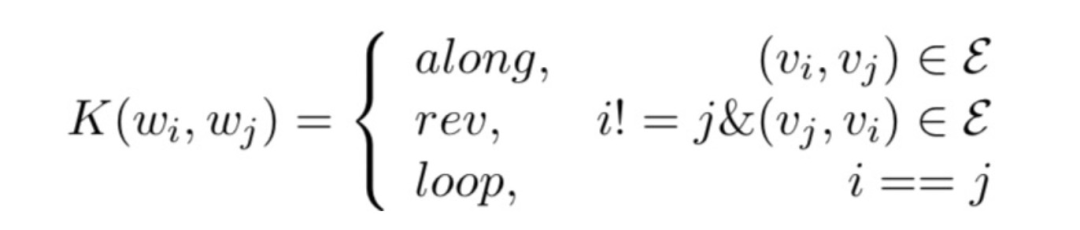
門控機(jī)制、highway units
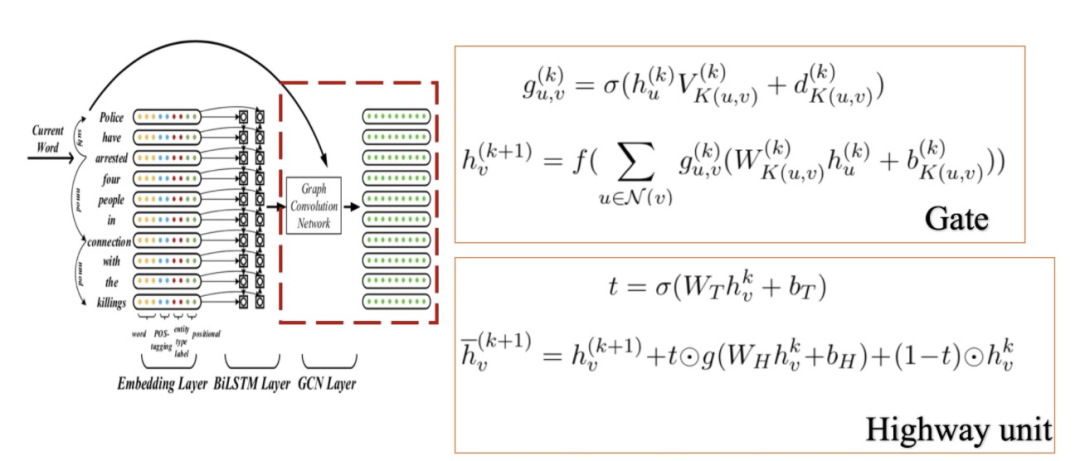
前面圖卷積的公式相當(dāng)于每次卷積的時候每個鄰居都對當(dāng)前節(jié)點的表征做了貢獻(xiàn)。但實際上,不是所有的鄰居或者說所有的邊都是有益于表征的,有些詞可能會增加歧義性。所以,JMEE增加門控機(jī)制,為有不同類型標(biāo)簽的邊分配不同的權(quán)重,這也可以看成是加權(quán)鄰居的貢獻(xiàn):
其中,為邊的權(quán)重。圖卷積存在一個問題,即over-smooth/information over propagation。換句話說,節(jié)點在拓?fù)渖匣ハ鄠鞑バ畔ⅲ闷渌?jié)點的信息更新自己的信息(匯聚節(jié)點信息),當(dāng)卷積深度不斷增加時,處于同一連通分支的節(jié)點的表征會趨于一致。針對這個問題,JMEE增加了highway units。最終在原始信息、轉(zhuǎn)移信息加新的表征信息共同作用下,獲得節(jié)點的圖卷積向量:
這里,通常被稱為transform gate,則稱為carry gate。個人覺得這個思想與跟殘差網(wǎng)絡(luò)思想(允許原始輸入信息直接傳輸?shù)胶竺娴膶又校╊愃啤?/p>
4.3 事件、論元檢測
事件檢測和事件論元檢測部分都是分類模型。

將每個token(詞/字)做為當(dāng)前token,再經(jīng)過詞嵌入及句法圖卷積模塊都獲得了所有token的向量表示。進(jìn)一步,為了利用事件觸發(fā)詞之間的關(guān)聯(lián)關(guān)系,JMEE設(shè)計了self-attention機(jī)制用于信息聚合。簡單地說,JMEE認(rèn)為在判斷一個token的觸發(fā)詞標(biāo)簽時需要考慮到其他可能的觸發(fā)詞的信息,比如前面例子中的“離開”與“計劃簽下”。具體地,假設(shè)(文本序列中的第個token)為當(dāng)前token,那么與之相關(guān)的上下文向量按如下方式計算:
這里代表歸一化操作。可以看到主要由兩部分組成,其一是的向量,其二是其余token的向量按attention權(quán)重加權(quán)后的表征。
事件檢測
對進(jìn)行觸發(fā)詞標(biāo)簽判定,只需要將其上下文向量送入一個簡單的分類器,如下:
這里的是非線性激活函數(shù),最終就是的觸發(fā)詞標(biāo)簽。JMEE標(biāo)簽體系選取的是BIO,所以經(jīng)過事件檢測模塊就可以得到類似于序列標(biāo)注的結(jié)果如“O,...,O,B-Name,I-Name,O,...,O,B-Loc,I-Loc,I-Loc,O,...,O”。我們基于這個結(jié)果序列就可以獲得候選事件觸發(fā)詞。
論元檢測
顯然候選事件觸發(fā)詞、實體都是連續(xù)的文本片段(即tokens的子序列)。對每一對候選觸發(fā)詞和實體,我們從向量中獲得其相關(guān)子序列中每個token的向量,然后利用max-pooling匯聚向量信息獲得候選觸發(fā)詞的向量以及實體的向量。將和拼接后送入全連接層進(jìn)行論元角色的判定:
結(jié)果表示的是第個實體在第個候選觸發(fā)詞所對應(yīng)的事件中扮演的角色。這里需要補(bǔ)充一點,一般事件抽取認(rèn)為輸入文本中的實體即是候選論元,所以JMEE做論元檢測時同于對實體進(jìn)行角色分類。
5. 實驗
5.1 實驗數(shù)據(jù)
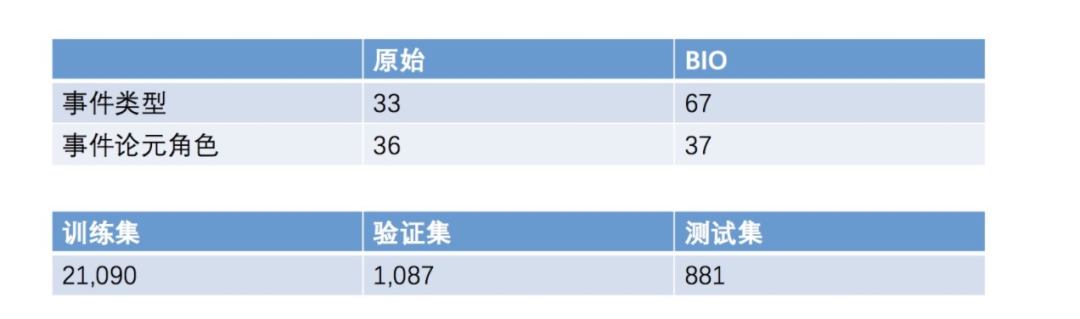
實驗數(shù)據(jù)選擇的是ACE2005,下面是它的具體信息:
5.2 實驗結(jié)果
整體性能比對
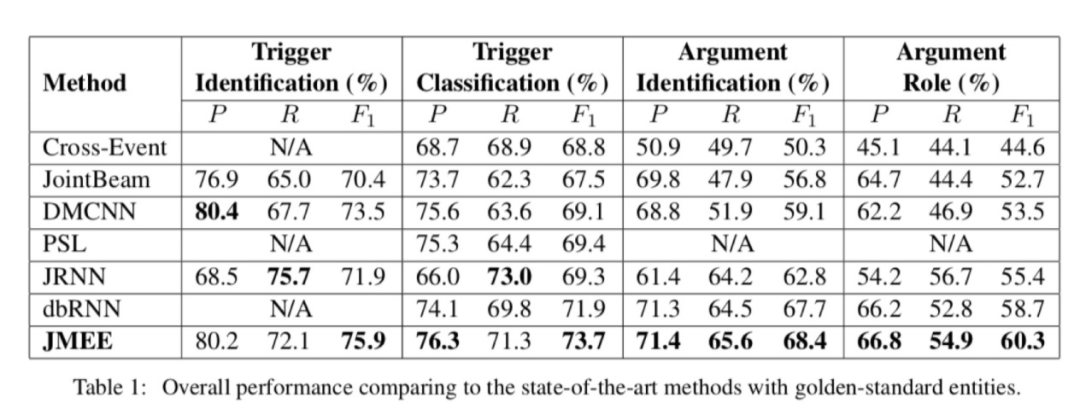
從JMEE與其他方法的整體性能比對結(jié)果來看,無論是在事件檢測(觸發(fā)詞識別、觸發(fā)詞分類)還是論元檢測(論元識別、論元角色分類),JMEE都取得了最佳的效果。
單事件、多事件場景比對
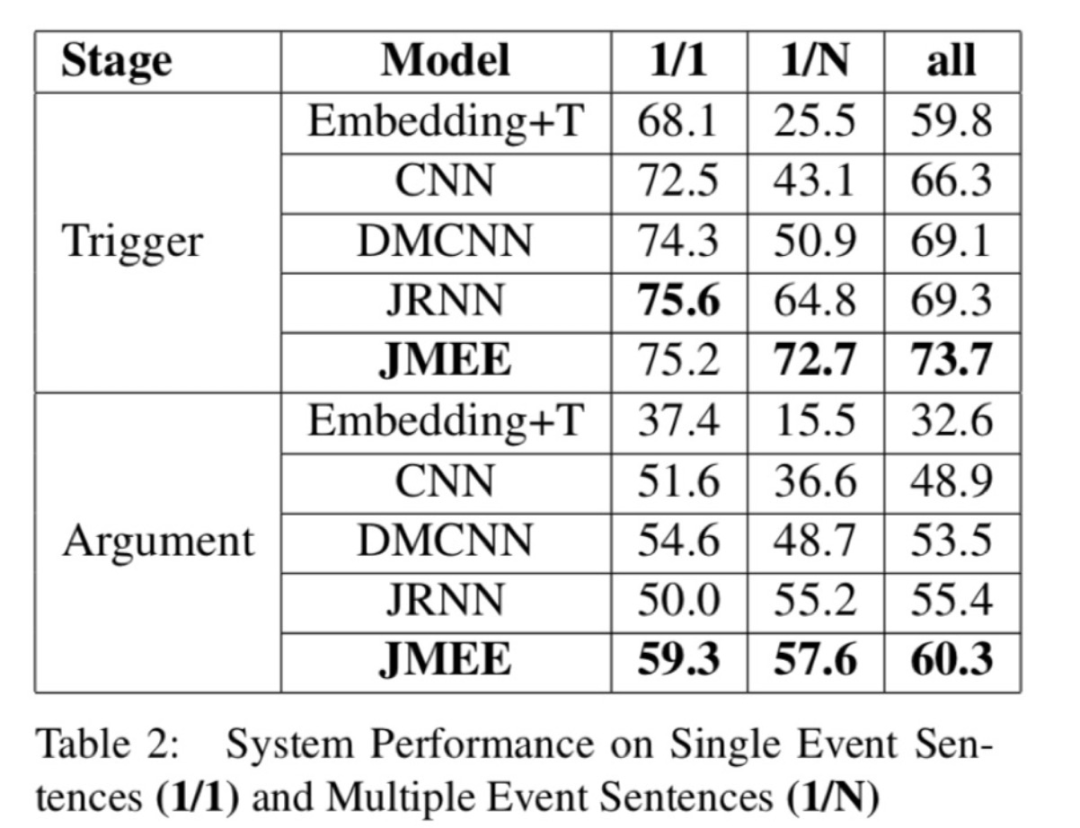
從 純粹的單事件抽取(1/1) 和 純粹的多事件抽取(1/N) 比對結(jié)果來看,在多事件抽取場景下,尤其在事件檢測任務(wù)上JMEE相對于對比方法的提升更大。
總結(jié)
今天我們分享了事件抽取模型JMEE,它主要是利用了句法樹、GCN以及self-attention來建模多事件之間的關(guān)聯(lián),從而提升多事件場景下事件抽取的效果。
審核編輯:劉清
-
圖卷積網(wǎng)絡(luò)
+關(guān)注
關(guān)注
0文章
8瀏覽量
1575 -
GCN
+關(guān)注
關(guān)注
0文章
5瀏覽量
2402 -
LSTM
+關(guān)注
關(guān)注
0文章
60瀏覽量
4048
原文標(biāo)題:一文詳解多事件抽取模型JMEE
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
一種基于決策樹的飛機(jī)級故障診斷建模方法研究
依存句法分析器的簡單實現(xiàn)
基于CRF序列標(biāo)注的中文依存句法分析器的Java實現(xiàn)
基于本體和句法分析的領(lǐng)域分詞的實現(xiàn)
基于集合枚舉樹的最小預(yù)測集挖掘算法
利用UML映射工具實現(xiàn)系統(tǒng)可靠性建模
基于FP_樹的時空關(guān)聯(lián)規(guī)則挖掘算法研究
基于八叉樹的三維地質(zhì)建模系統(tǒng)設(shè)計研究李燦輝
Quasi-TreeIJSTMs一種針對句法樹的混合神經(jīng)網(wǎng)絡(luò)模型的介紹和實驗分析
什么是Transition-based基于轉(zhuǎn)移的框架?
自然語言處理中極其重要的句法分析
什么是句法分析





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論