") 詳解MySQL三大日志的作用
詳解MySQL三大日志的作用

前言
MySQL日志 主要包括錯(cuò)誤日志、查詢?nèi)罩尽⒙樵內(nèi)罩尽⑹聞?wù)日志、二進(jìn)制日志幾大類。其中,比較重要的還要屬二進(jìn)制日志 binlog(歸檔日志)和事務(wù)日志 redo log(重做日志)和 undo log(回滾日志)。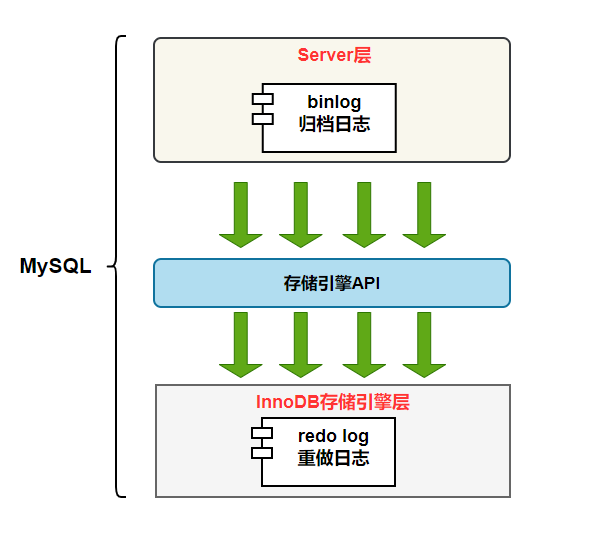
今天就來聊聊 redo log(重做日志)、binlog(歸檔日志)、兩階段提交、undo log (回滾日志)。
redo log
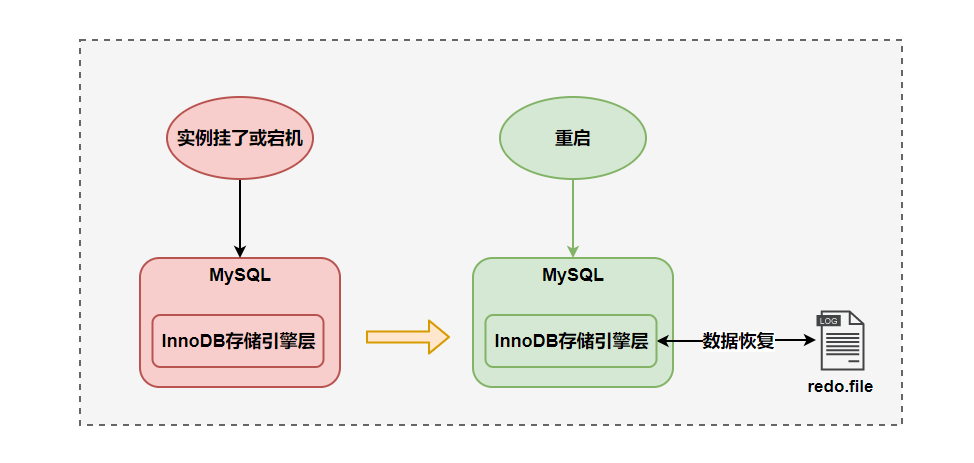
redo log(重做日志)是InnoDB存儲(chǔ)引擎獨(dú)有的,它讓MySQL擁有了崩潰恢復(fù)能力。
比如 MySQL 實(shí)例掛了或宕機(jī)了,重啟時(shí),InnoDB存儲(chǔ)引擎會(huì)使用redo log恢復(fù)數(shù)據(jù),保證數(shù)據(jù)的持久性與完整性。
MySQL 中數(shù)據(jù)是以頁為單位,你查詢一條記錄,會(huì)從硬盤把一頁的數(shù)據(jù)加載出來,加載出來的數(shù)據(jù)叫數(shù)據(jù)頁,會(huì)放入到 Buffer Pool 中。
后續(xù)的查詢都是先從 Buffer Pool 中找,沒有命中再去硬盤加載,減少硬盤 IO 開銷,提升性能。
更新表數(shù)據(jù)的時(shí)候,也是如此,發(fā)現(xiàn) Buffer Pool 里存在要更新的數(shù)據(jù),就直接在 Buffer Pool 里更新。
然后會(huì)把“在某個(gè)數(shù)據(jù)頁上做了什么修改”記錄到重做日志緩存(redo log buffer)里,接著刷盤到 redo log 文件里。
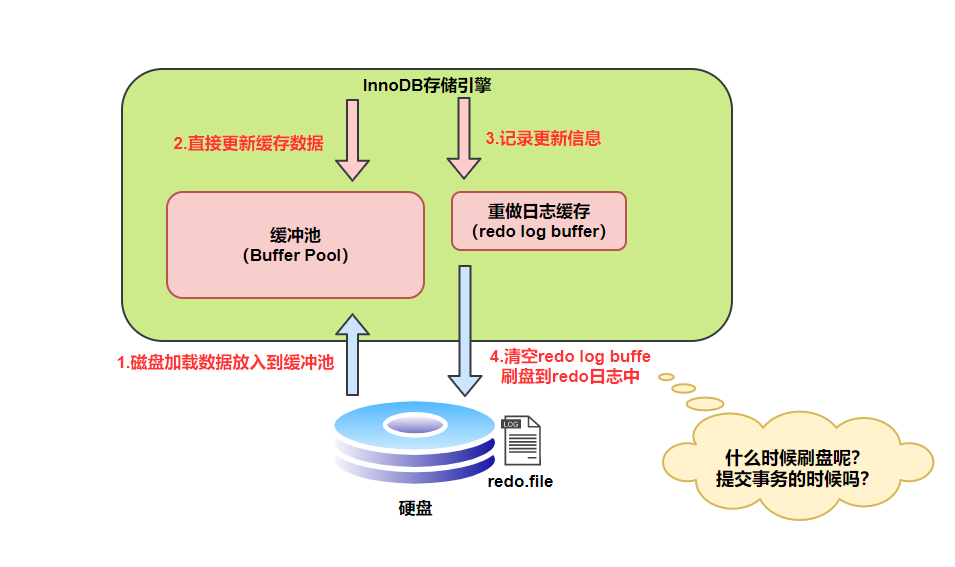
理想情況,事務(wù)一提交就會(huì)進(jìn)行刷盤操作,但實(shí)際上,刷盤的時(shí)機(jī)是根據(jù)策略來進(jìn)行的。
小貼士:每條 redo 記錄由“表空間號+數(shù)據(jù)頁號+偏移量+修改數(shù)據(jù)長度+具體修改的數(shù)據(jù)”組成
刷盤時(shí)機(jī)
InnoDB 存儲(chǔ)引擎為 redo log 的刷盤策略提供了 innodb_flush_log_at_trx_commit 參數(shù),它支持三種策略:
- 0 :設(shè)置為 0 的時(shí)候,表示每次事務(wù)提交時(shí)不進(jìn)行刷盤操作
- 1 :設(shè)置為 1 的時(shí)候,表示每次事務(wù)提交時(shí)都將進(jìn)行刷盤操作(默認(rèn)值)
- 2 :設(shè)置為 2 的時(shí)候,表示每次事務(wù)提交時(shí)都只把 redo log buffer 內(nèi)容寫入 page cache
innodb_flush_log_at_trx_commit 參數(shù)默認(rèn)為 1 ,也就是說當(dāng)事務(wù)提交時(shí)會(huì)調(diào)用 fsync 對 redo log 進(jìn)行刷盤
另外,InnoDB 存儲(chǔ)引擎有一個(gè)后臺(tái)線程,每隔1 秒,就會(huì)把 redo log buffer 中的內(nèi)容寫到文件系統(tǒng)緩存(page cache),然后調(diào)用 fsync 刷盤。
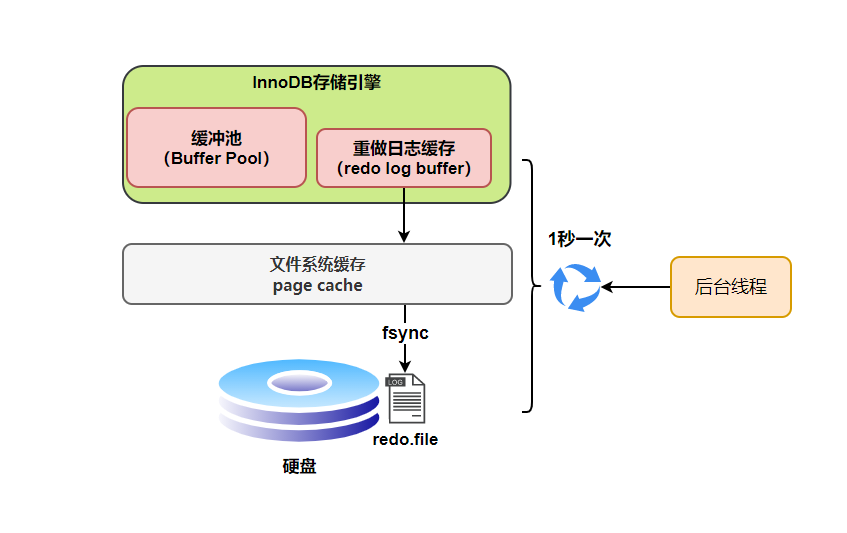
也就是說,一個(gè)沒有提交事務(wù)的 redo log 記錄,也可能會(huì)刷盤。
為什么呢?
因?yàn)樵谑聞?wù)執(zhí)行過程 redo log 記錄是會(huì)寫入redo log buffer 中,這些 redo log 記錄會(huì)被后臺(tái)線程刷盤。
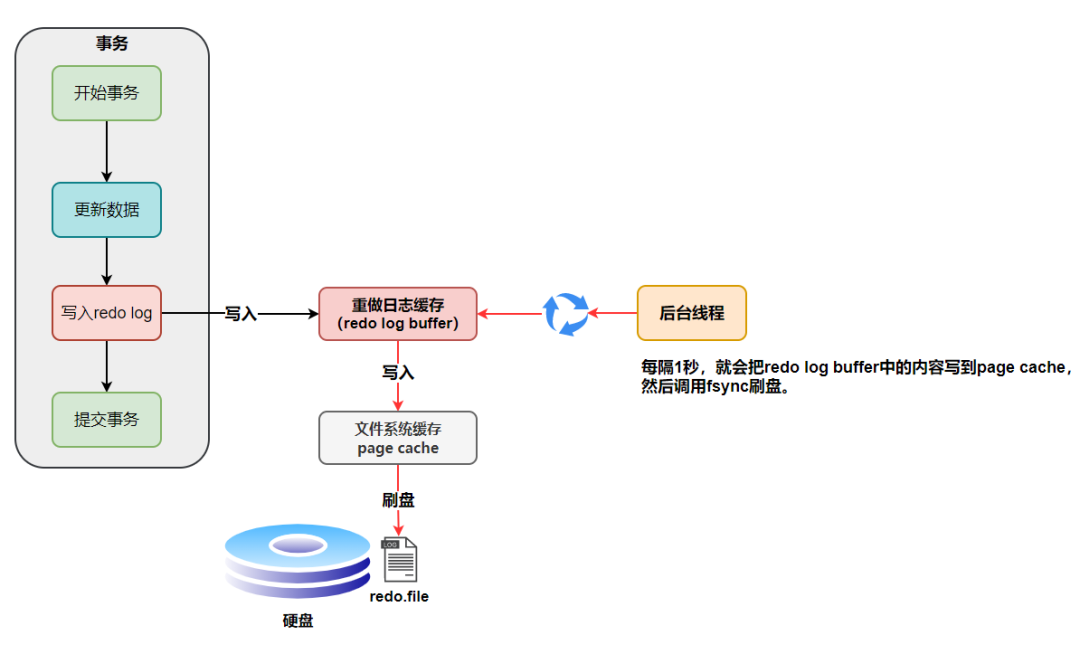
除了后臺(tái)線程每秒1次的輪詢操作,還有一種情況,當(dāng) redo log buffer 占用的空間即將達(dá)到 innodb_log_buffer_size 一半的時(shí)候,后臺(tái)線程會(huì)主動(dòng)刷盤。
下面是不同刷盤策略的流程圖。
innodb_flush_log_at_trx_commit=0
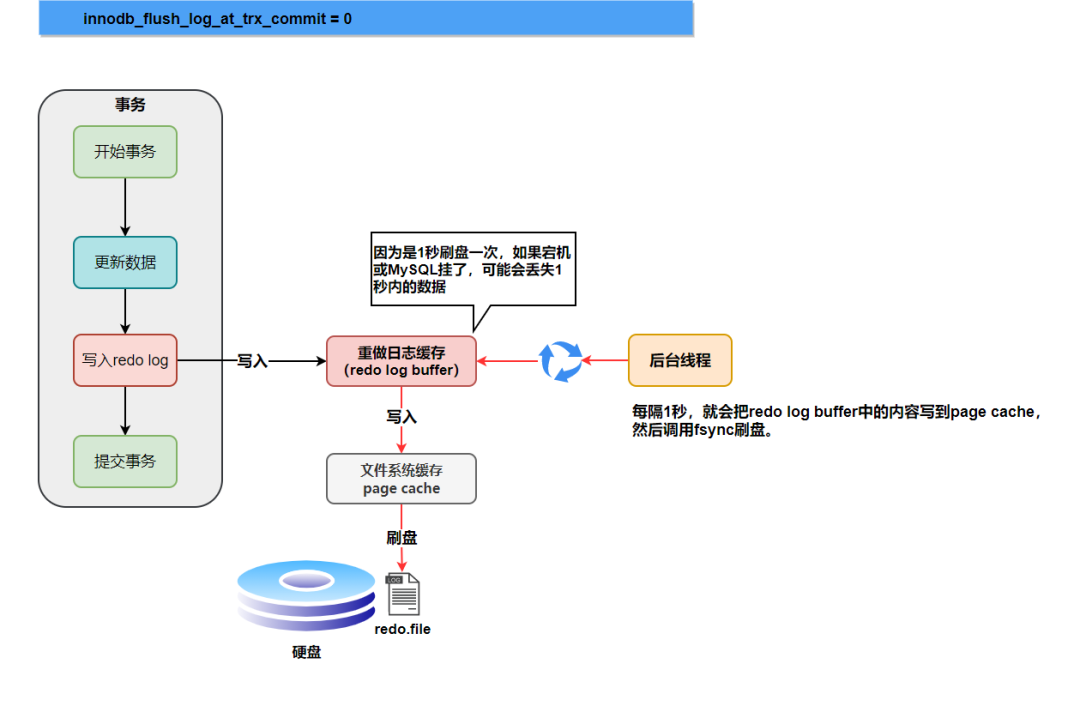
為0時(shí),如果MySQL掛了或宕機(jī)可能會(huì)有1秒數(shù)據(jù)的丟失。
innodb_flush_log_at_trx_commit=1
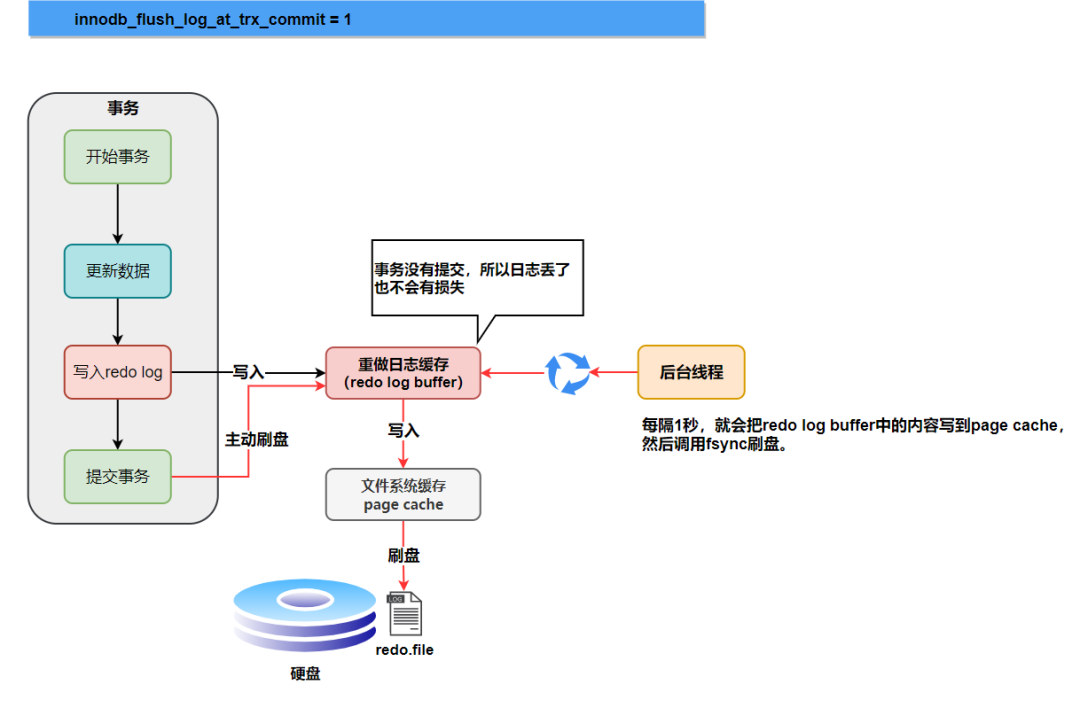
為1時(shí), 只要事務(wù)提交成功,redo log記錄就一定在硬盤里,不會(huì)有任何數(shù)據(jù)丟失。
如果事務(wù)執(zhí)行期間MySQL掛了或宕機(jī),這部分日志丟了,但是事務(wù)并沒有提交,所以日志丟了也不會(huì)有損失。
innodb_flush_log_at_trx_commit=2

為2時(shí), 只要事務(wù)提交成功,redo log buffer中的內(nèi)容只寫入文件系統(tǒng)緩存(page cache)。
如果僅僅只是MySQL掛了不會(huì)有任何數(shù)據(jù)丟失,但是宕機(jī)可能會(huì)有1秒數(shù)據(jù)的丟失。
日志文件組
硬盤上存儲(chǔ)的 redo log 日志文件不只一個(gè),而是以一個(gè)日志文件組的形式出現(xiàn)的,每個(gè)的redo日志文件大小都是一樣的。
比如可以配置為一組4個(gè)文件,每個(gè)文件的大小是 1GB,整個(gè) redo log 日志文件組可以記錄4G的內(nèi)容。
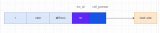
它采用的是環(huán)形數(shù)組形式,從頭開始寫,寫到末尾又回到頭循環(huán)寫,如下圖所示。
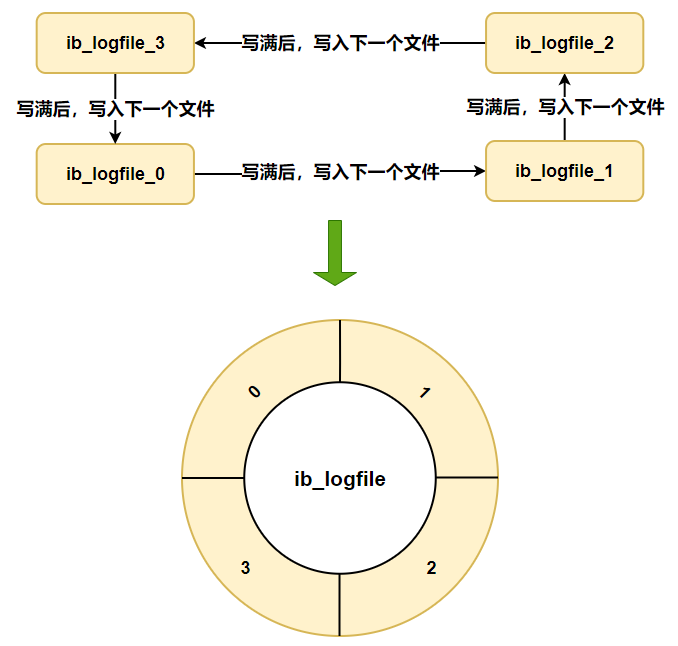
在個(gè)日志文件組中還有兩個(gè)重要的屬性,分別是 write pos、checkpoint
- write pos 是當(dāng)前記錄的位置,一邊寫一邊后移
- checkpoint 是當(dāng)前要擦除的位置,也是往后推移
每次刷盤 redo log 記錄到日志文件組中,write pos 位置就會(huì)后移更新。
每次 MySQL 加載日志文件組恢復(fù)數(shù)據(jù)時(shí),會(huì)清空加載過的 redo log 記錄,并把 checkpoint 后移更新。
write pos 和 checkpoint 之間的還空著的部分可以用來寫入新的 redo log 記錄。
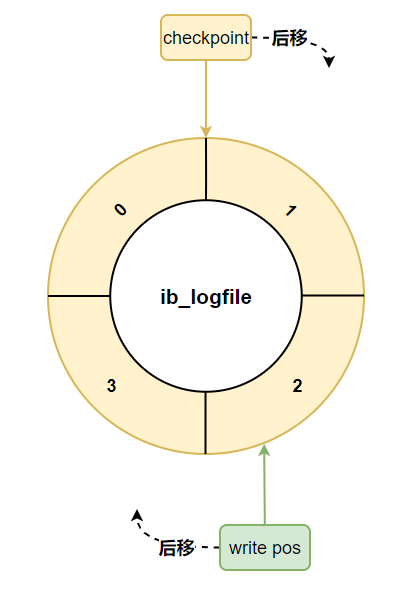
如果 write pos 追上 checkpoint ,表示日志文件組滿了,這時(shí)候不能再寫入新的 redo log 記錄,MySQL 得停下來,清空一些記錄,把 checkpoint 推進(jìn)一下。
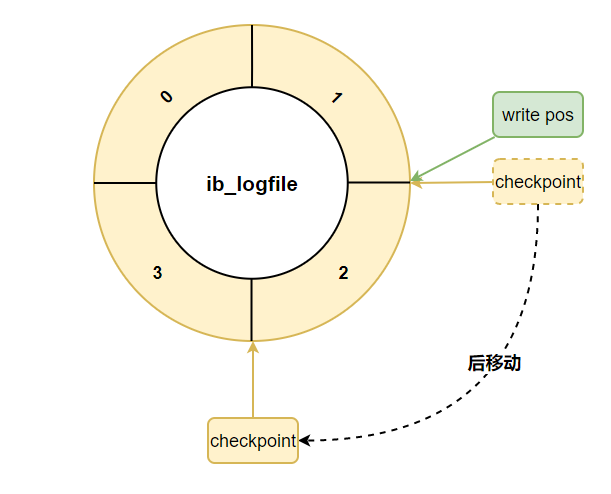
redo log 小結(jié)
相信大家都知道 redo log 的作用和它的刷盤時(shí)機(jī)、存儲(chǔ)形式。
現(xiàn)在我們來思考一個(gè)問題:只要每次把修改后的數(shù)據(jù)頁直接刷盤不就好了,還有 redo log 什么事?
它們不都是刷盤么?差別在哪里?
1Byte=8bit
1KB=1024Byte
1MB=1024KB
1GB=1024MB
1TB=1024GB
實(shí)際上,數(shù)據(jù)頁大小是16KB,刷盤比較耗時(shí),可能就修改了數(shù)據(jù)頁里的幾 Byte 數(shù)據(jù),有必要把完整的數(shù)據(jù)頁刷盤嗎?
而且數(shù)據(jù)頁刷盤是隨機(jī)寫,因?yàn)橐粋€(gè)數(shù)據(jù)頁對應(yīng)的位置可能在硬盤文件的隨機(jī)位置,所以性能是很差。
如果是寫 redo log,一行記錄可能就占幾十 Byte,只包含表空間號、數(shù)據(jù)頁號、磁盤文件偏移量、更新值,再加上是順序?qū)懀运⒈P速度很快。
所以用 redo log 形式記錄修改內(nèi)容,性能會(huì)遠(yuǎn)遠(yuǎn)超過刷數(shù)據(jù)頁的方式,這也讓數(shù)據(jù)庫的并發(fā)能力更強(qiáng)。
其實(shí)內(nèi)存的數(shù)據(jù)頁在一定時(shí)機(jī)也會(huì)刷盤,我們把這稱為頁合并,講
Buffer Pool的時(shí)候會(huì)對這塊細(xì)說
binlog
redo log 它是物理日志,記錄內(nèi)容是“在某個(gè)數(shù)據(jù)頁上做了什么修改”,屬于 InnoDB 存儲(chǔ)引擎。
而 binlog 是邏輯日志,記錄內(nèi)容是語句的原始邏輯,類似于“給 ID=2 這一行的 c 字段加 1”,屬于MySQL Server 層。
不管用什么存儲(chǔ)引擎,只要發(fā)生了表數(shù)據(jù)更新,都會(huì)產(chǎn)生 binlog 日志。
那 binlog 到底是用來干嘛的?
可以說MySQL數(shù)據(jù)庫的數(shù)據(jù)備份、主備、主主、主從都離不開binlog,需要依靠binlog來同步數(shù)據(jù),保證數(shù)據(jù)一致性。
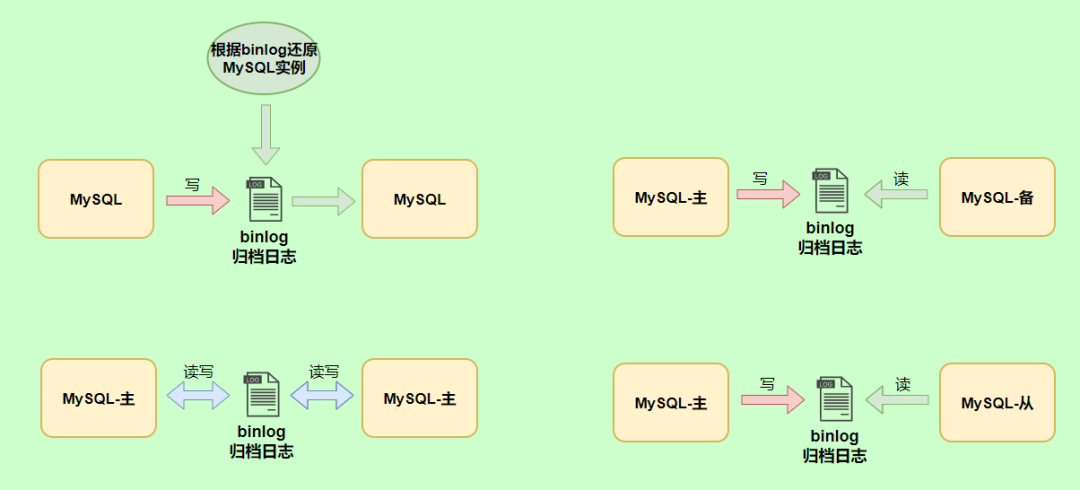
binlog會(huì)記錄所有涉及更新數(shù)據(jù)的邏輯操作,并且是順序?qū)憽?/span>
記錄格式
binlog 日志有三種格式,可以通過binlog_format參數(shù)指定。
- statement
- row
- mixed
指定statement,記錄的內(nèi)容是SQL語句原文,比如執(zhí)行一條update T set update_time=now() where id=1,記錄的內(nèi)容如下。
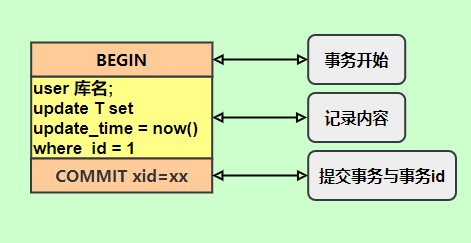
同步數(shù)據(jù)時(shí),會(huì)執(zhí)行記錄的SQL語句,但是有個(gè)問題,update_time=now()這里會(huì)獲取當(dāng)前系統(tǒng)時(shí)間,直接執(zhí)行會(huì)導(dǎo)致與原庫的數(shù)據(jù)不一致。
為了解決這種問題,我們需要指定為row,記錄的內(nèi)容不再是簡單的SQL語句了,還包含操作的具體數(shù)據(jù),記錄內(nèi)容如下。
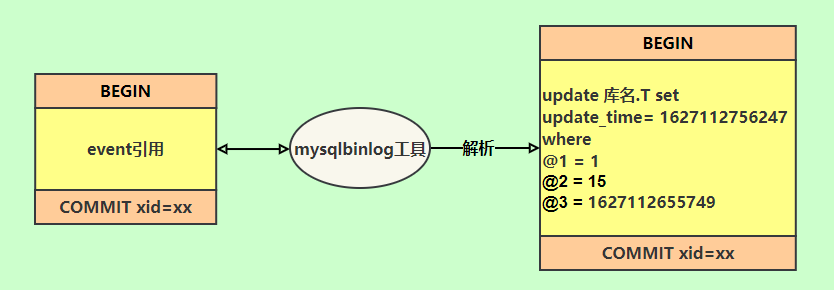
row格式記錄的內(nèi)容看不到詳細(xì)信息,要通過mysqlbinlog工具解析出來。
update_time=now()變成了具體的時(shí)間update_time=1627112756247,條件后面的@1、@2、@3 都是該行數(shù)據(jù)第 1 個(gè)~3 個(gè)字段的原始值(假設(shè)這張表只有 3 個(gè)字段)。
這樣就能保證同步數(shù)據(jù)的一致性,通常情況下都是指定為row,這樣可以為數(shù)據(jù)庫的恢復(fù)與同步帶來更好的可靠性。
但是這種格式,需要更大的容量來記錄,比較占用空間,恢復(fù)與同步時(shí)會(huì)更消耗IO資源,影響執(zhí)行速度。
所以就有了一種折中的方案,指定為mixed,記錄的內(nèi)容是前兩者的混合。
MySQL會(huì)判斷這條SQL語句是否可能引起數(shù)據(jù)不一致,如果是,就用row格式,否則就用statement格式。
寫入機(jī)制
binlog的寫入時(shí)機(jī)也非常簡單,事務(wù)執(zhí)行過程中,先把日志寫到binlog cache,事務(wù)提交的時(shí)候,再把binlog cache寫到binlog文件中。
因?yàn)橐粋€(gè)事務(wù)的binlog不能被拆開,無論這個(gè)事務(wù)多大,也要確保一次性寫入,所以系統(tǒng)會(huì)給每個(gè)線程分配一個(gè)塊內(nèi)存作為binlog cache。
我們可以通過binlog_cache_size參數(shù)控制單個(gè)線程 binlog cache 大小,如果存儲(chǔ)內(nèi)容超過了這個(gè)參數(shù),就要暫存到磁盤(Swap)。
binlog日志刷盤流程如下
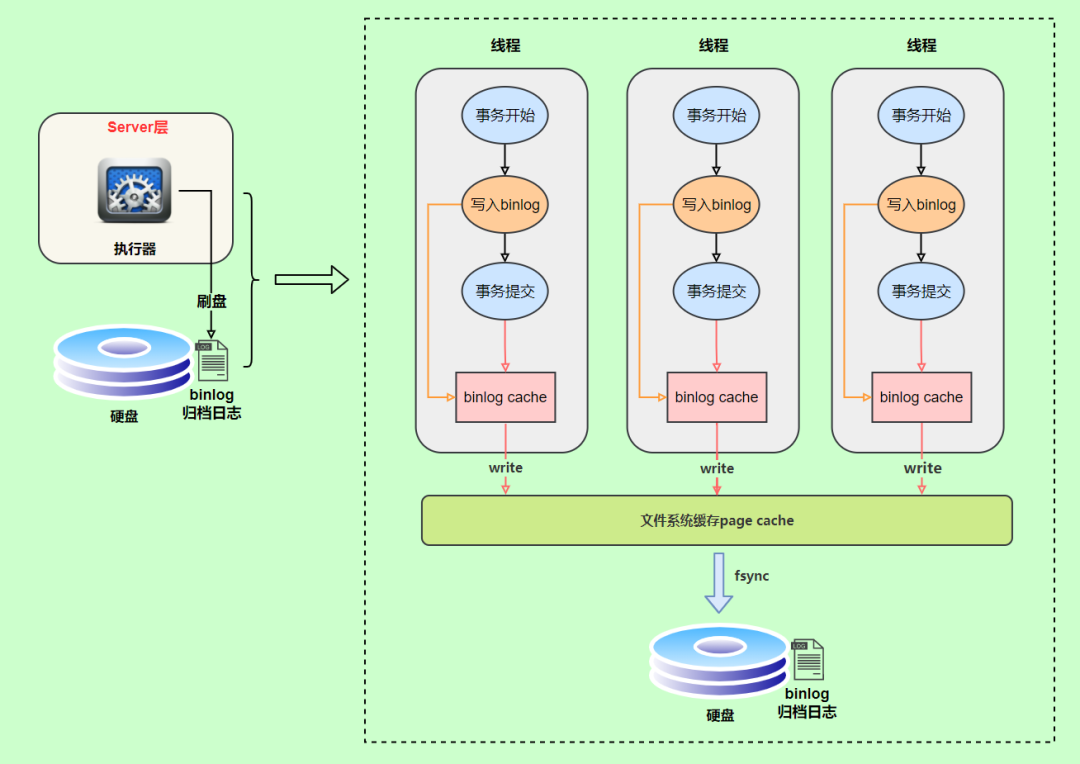
- 上圖的 write,是指把日志寫入到文件系統(tǒng)的 page cache,并沒有把數(shù)據(jù)持久化到磁盤,所以速度比較快
- 上圖的 fsync,才是將數(shù)據(jù)持久化到磁盤的操作
write和fsync的時(shí)機(jī),可以由參數(shù)sync_binlog控制,默認(rèn)是0。
為0的時(shí)候,表示每次提交事務(wù)都只write,由系統(tǒng)自行判斷什么時(shí)候執(zhí)行fsync。
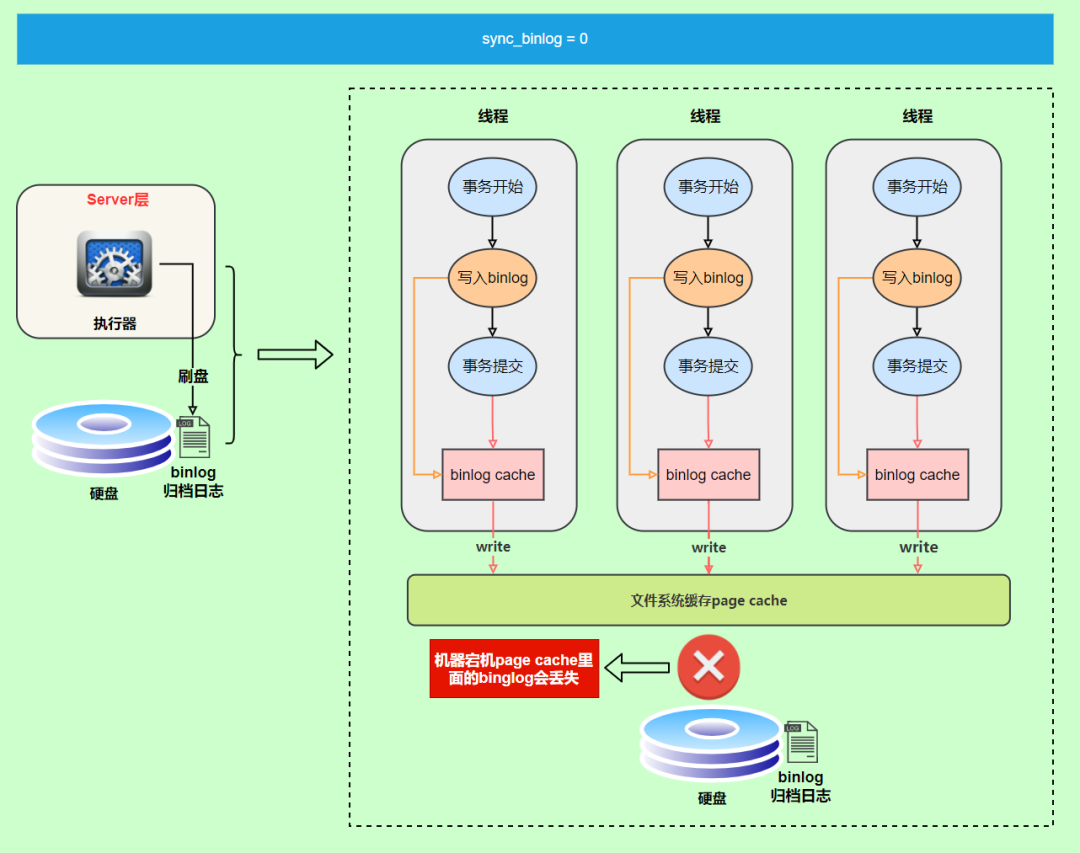
雖然性能得到提升,但是機(jī)器宕機(jī),page cache里面的 binglog 會(huì)丟失。
為了安全起見,可以設(shè)置為1,表示每次提交事務(wù)都會(huì)執(zhí)行fsync,就如同binlog 日志刷盤流程一樣。
最后還有一種折中方式,可以設(shè)置為N(N>1),表示每次提交事務(wù)都write,但累積N個(gè)事務(wù)后才fsync。
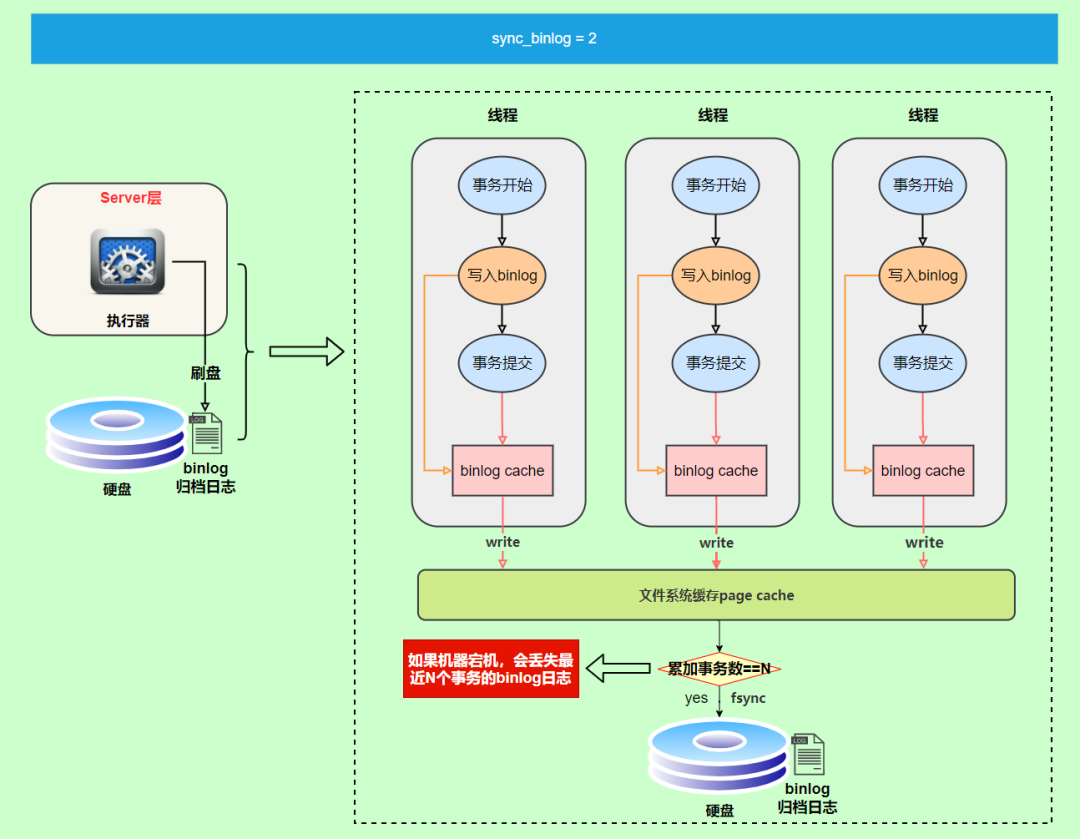
在出現(xiàn)IO瓶頸的場景里,將sync_binlog設(shè)置成一個(gè)比較大的值,可以提升性能。
同樣的,如果機(jī)器宕機(jī),會(huì)丟失最近N個(gè)事務(wù)的binlog日志。
兩階段提交
redo log(重做日志)讓InnoDB存儲(chǔ)引擎擁有了崩潰恢復(fù)能力。
binlog(歸檔日志)保證了MySQL集群架構(gòu)的數(shù)據(jù)一致性。
雖然它們都屬于持久化的保證,但是則重點(diǎn)不同。
在執(zhí)行更新語句過程,會(huì)記錄redo log與binlog兩塊日志,以基本的事務(wù)為單位,redo log在事務(wù)執(zhí)行過程中可以不斷寫入,而binlog只有在提交事務(wù)時(shí)才寫入,所以redo log與binlog的寫入時(shí)機(jī)不一樣。
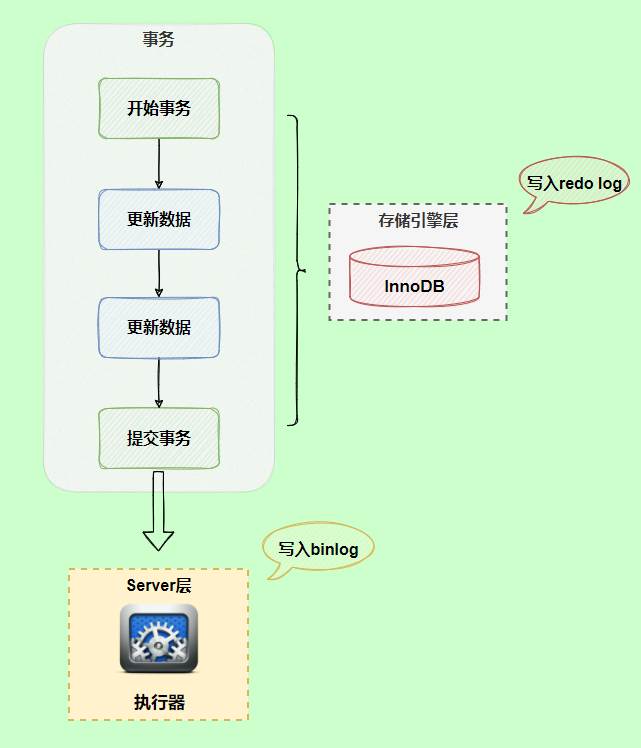
回到正題,redo log與binlog兩份日志之間的邏輯不一致,會(huì)出現(xiàn)什么問題?
我們以update語句為例,假設(shè)id=2的記錄,字段c值是0,把字段c值更新成1,SQL語句為update T set c=1 where id=2。
假設(shè)執(zhí)行過程中寫完redo log日志后,binlog日志寫期間發(fā)生了異常,會(huì)出現(xiàn)什么情況呢?
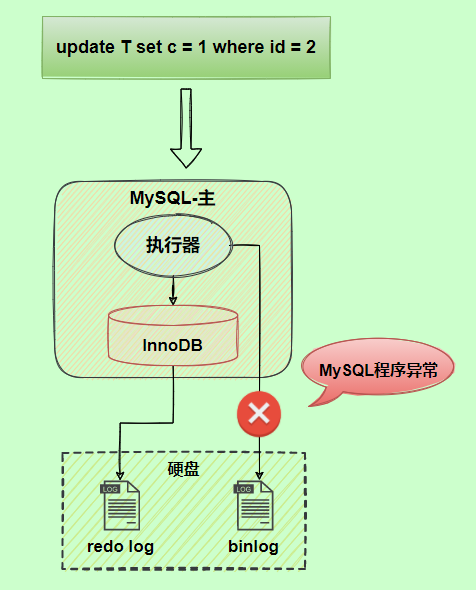
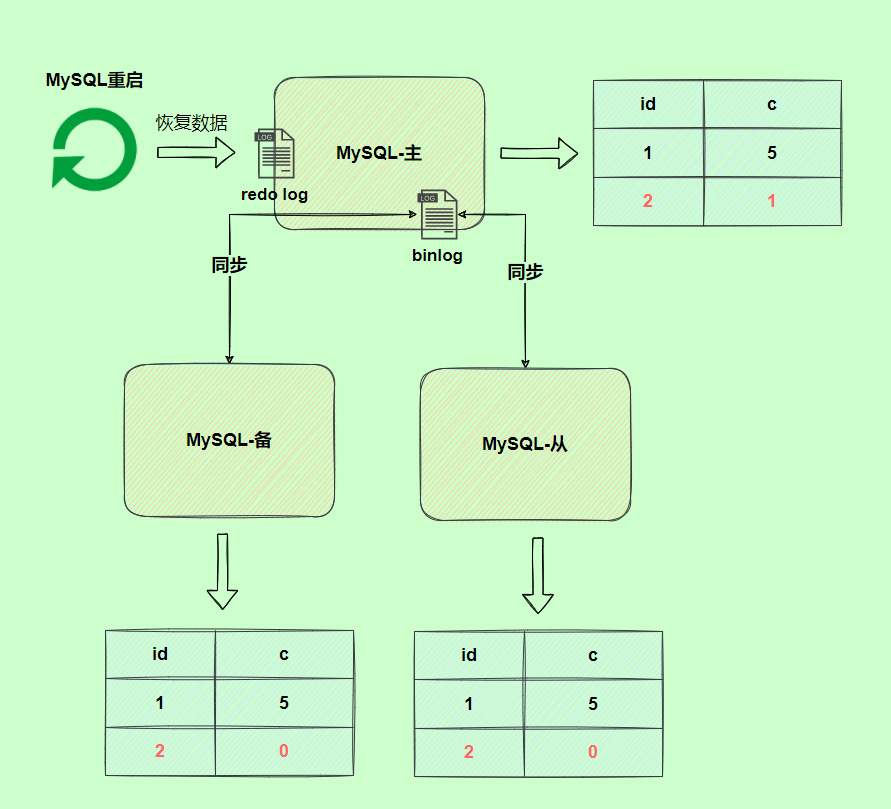
由于binlog沒寫完就異常,這時(shí)候binlog里面沒有對應(yīng)的修改記錄。因此,之后用binlog日志恢復(fù)數(shù)據(jù)時(shí),就會(huì)少這一次更新,恢復(fù)出來的這一行c值是0,而原庫因?yàn)?/span>redo log日志恢復(fù),這一行c值是1,最終數(shù)據(jù)不一致。
為了解決兩份日志之間的邏輯一致問題,InnoDB存儲(chǔ)引擎使用兩階段提交方案。
原理很簡單,將redo log的寫入拆成了兩個(gè)步驟prepare和commit,這就是兩階段提交。
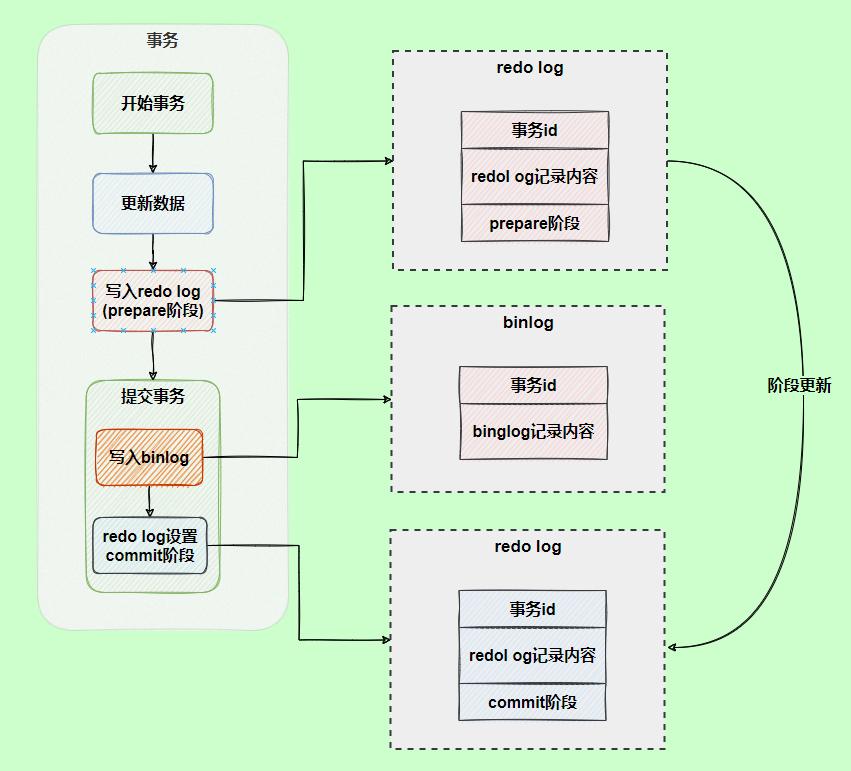
使用兩階段提交后,寫入binlog時(shí)發(fā)生異常也不會(huì)有影響,因?yàn)?/span>MySQL根據(jù)redo log日志恢復(fù)數(shù)據(jù)時(shí),發(fā)現(xiàn)redo log還處于prepare階段,并且沒有對應(yīng)binlog日志,就會(huì)回滾該事務(wù)。
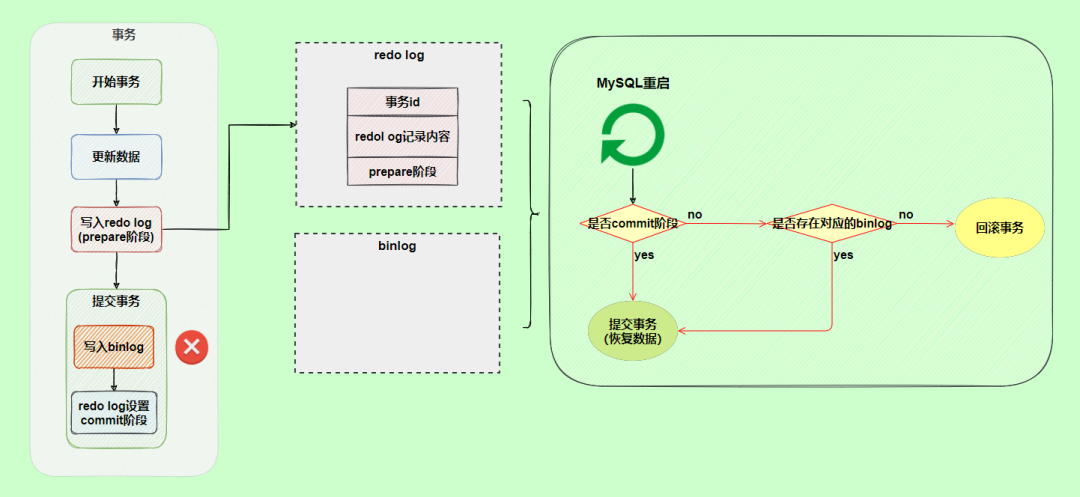
再看一個(gè)場景,redo log設(shè)置commit階段發(fā)生異常,那會(huì)不會(huì)回滾事務(wù)呢?
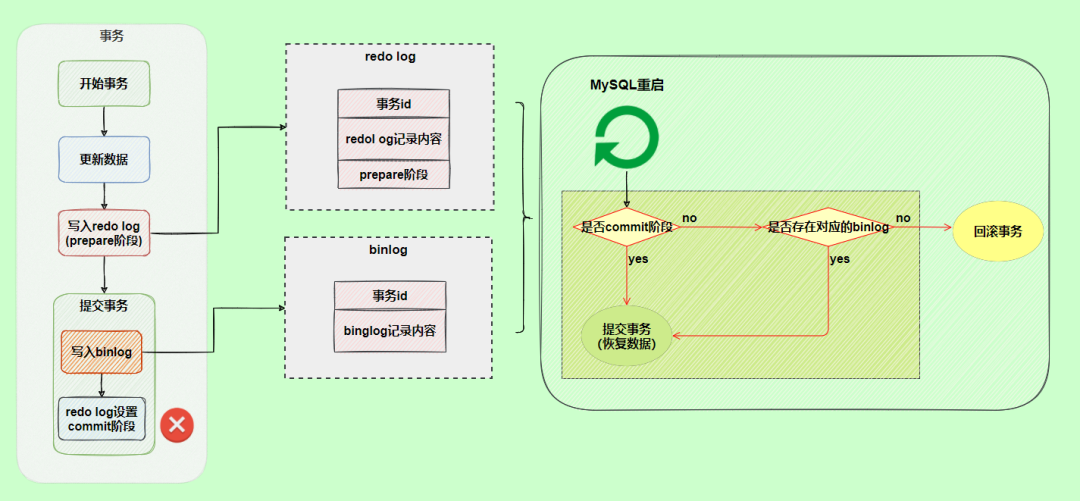
并不會(huì)回滾事務(wù),它會(huì)執(zhí)行上圖框住的邏輯,雖然redo log是處于prepare階段,但是能通過事務(wù)id找到對應(yīng)的binlog日志,所以MySQL認(rèn)為是完整的,就會(huì)提交事務(wù)恢復(fù)數(shù)據(jù)。
undo log
數(shù)據(jù)庫事務(wù)四大特性中有一個(gè)是原子性,具體來說就是原子性是指對數(shù)據(jù)庫的一系列操作,要么全部成功,要么全部失敗,不可能出現(xiàn)部分成功的情況。
我們知道如果想要保證事務(wù)的原子性,就需要在異常發(fā)生時(shí),對已經(jīng)執(zhí)行的操作進(jìn)行回滾,在 MySQL 中,恢復(fù)機(jī)制是通過 回滾日志(undo log) 實(shí)現(xiàn)的,所有事務(wù)進(jìn)行的修改都會(huì)先先記錄到這個(gè)回滾日志中,然后再執(zhí)行相關(guān)的操作。
如果執(zhí)行過程中遇到異常的話,我們直接利用 回滾日志 中的信息將數(shù)據(jù)回滾到修改之前的樣子即可!并且,回滾日志會(huì)先于數(shù)據(jù)持久化到磁盤上。這樣就保證了即使遇到數(shù)據(jù)庫突然宕機(jī)等情況,當(dāng)用戶再次啟動(dòng)數(shù)據(jù)庫的時(shí)候,數(shù)據(jù)庫還能夠通過查詢回滾日志來回滾將之前未完成的事務(wù)。
另外,MVCC 的實(shí)現(xiàn)依賴于:隱藏字段、Read View、undo log。在內(nèi)部實(shí)現(xiàn)中,InnoDB 通過數(shù)據(jù)行的 DB_TRX_ID 和 Read View 來判斷數(shù)據(jù)的可見性,如不可見,則通過數(shù)據(jù)行的 DB_ROLL_PTR 找到 undo log 中的歷史版本。
每個(gè)事務(wù)讀到的數(shù)據(jù)版本可能是不一樣的,在同一個(gè)事務(wù)中,用戶只能看到該事務(wù)創(chuàng)建 Read View 之前已經(jīng)提交的修改和該事務(wù)本身做的修改。
總結(jié)
MySQL InnoDB 引擎使用 redo log(重做日志) 保證事務(wù)的持久性,使用 undo log(回滾日志) 來保證事務(wù)的原子性。
MySQL數(shù)據(jù)庫的數(shù)據(jù)備份、主備、主主、主從都離不開binlog,需要依靠binlog來同步數(shù)據(jù),保證數(shù)據(jù)一致性。
審核編輯:湯梓紅
-
MySQL
+關(guān)注
關(guān)注
1文章
869瀏覽量
28069 -
日志
+關(guān)注
關(guān)注
0文章
144瀏覽量
10886 -
binlog
+關(guān)注
關(guān)注
0文章
7瀏覽量
1334
原文標(biāo)題:大廠基本功 | MySQL 三大日志 ( binlog、redo log 和 undo log ) 的作用?
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
0基礎(chǔ)學(xué)Mysql:mysql入門視頻教程!
日志系統(tǒng)在應(yīng)用中的重要作用
確保數(shù)據(jù)零丟失!阿里云數(shù)據(jù)庫RDS for MySQL 三節(jié)點(diǎn)企業(yè)版正式商用
詳談MySQL數(shù)據(jù)庫的不同日志和源碼
MySQL事務(wù)日志
MySQL中的redo log是什么
關(guān)于Mysql的20道問題詳解
基于mysql自有方式采集獲取監(jiān)控?cái)?shù)據(jù)
MYSQL事務(wù)的底層原理詳解
oracle數(shù)據(jù)庫alert日志作用
詳解journalctl日志管理






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論