") 關(guān)于Next-ViT 的建模能力
關(guān)于Next-ViT 的建模能力
來(lái)自字節(jié)跳動(dòng)的研究者提出了一種能在現(xiàn)實(shí)工業(yè)場(chǎng)景中有效部署的下一代視覺(jué) Transformer,即 Next-ViT。Next-ViT 能像 CNN 一樣快速推斷,并有 ViT 一樣強(qiáng)大的性能。
由于復(fù)雜的注意力機(jī)制和模型設(shè)計(jì),大多數(shù)現(xiàn)有的視覺(jué) Transformer(ViT)在現(xiàn)實(shí)的工業(yè)部署場(chǎng)景中不能像卷積神經(jīng)網(wǎng)絡(luò)(CNN)那樣高效地執(zhí)行。這就帶來(lái)了一個(gè)問(wèn)題:視覺(jué)神經(jīng)網(wǎng)絡(luò)能否像 CNN 一樣快速推斷并像 ViT 一樣強(qiáng)大?
近期一些工作試圖設(shè)計(jì) CNN-Transformer 混合架構(gòu)來(lái)解決這個(gè)問(wèn)題,但這些工作的整體性能遠(yuǎn)不能令人滿意。基于此,來(lái)自字節(jié)跳動(dòng)的研究者提出了一種能在現(xiàn)實(shí)工業(yè)場(chǎng)景中有效部署的下一代視覺(jué) Transformer——Next-ViT。從延遲 / 準(zhǔn)確性權(quán)衡的角度看,Next-ViT 的性能可以媲美優(yōu)秀的 CNN 和 ViT。

Next-ViT 的研究團(tuán)隊(duì)通過(guò)開(kāi)發(fā)新型的卷積塊(NCB)和 Transformer 塊(NTB),部署了友好的機(jī)制來(lái)捕獲局部和全局信息。然后,該研究提出了一種新型混合策略 NHS,旨在以高效的混合范式堆疊 NCB 和 NTB,從而提高各種下游任務(wù)的性能。
大量實(shí)驗(yàn)表明,Next-ViT 在各種視覺(jué)任務(wù)的延遲 / 準(zhǔn)確性權(quán)衡方面明顯優(yōu)于現(xiàn)有的 CNN、ViT 和 CNN-Transformer 混合架構(gòu)。在 TensorRT 上,Next-ViT 與 ResNet 相比,在 COCO 檢測(cè)任務(wù)上高出 5.4 mAP(40.4 VS 45.8),在 ADE20K 分割上高出 8.2% mIoU(38.8% VS 47.0%)。同時(shí),Next-ViT 達(dá)到了與 CSWin 相當(dāng)?shù)男阅埽⑶彝评硭俣忍岣吡?3.6 倍。在 CoreML 上,Next-ViT 在 COCO 檢測(cè)任務(wù)上比 EfficientFormer 高出 4.6 mAP(42.6 VS 47.2),在 ADE20K 分割上高出 3.5% mIoU(從 45.2% 到 48.7%)。
方法
Next-ViT 的整體架構(gòu)如下圖 2 所示。Next-ViT 遵循分層金字塔架構(gòu),在每個(gè)階段配備一個(gè) patch 嵌入層和一系列卷積或 Transformer 塊。空間分辨率將逐步降低為原來(lái)的 1/32,而通道維度將按階段擴(kuò)展。
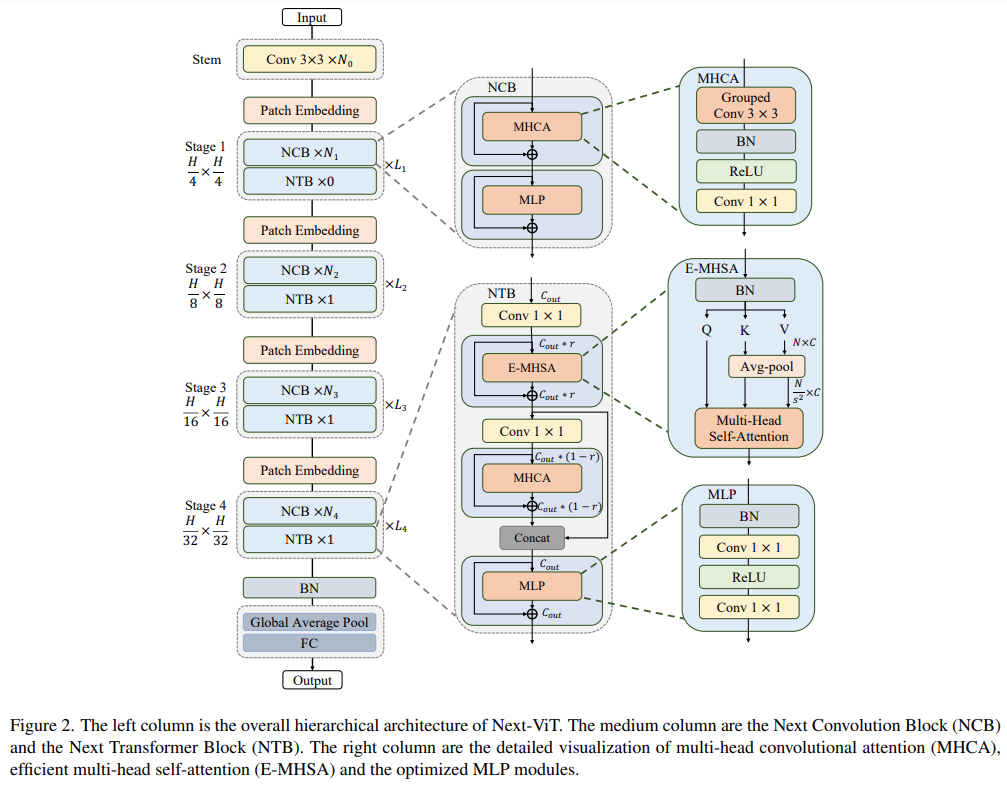
研究者首先深入設(shè)計(jì)了信息交互的核心模塊,并分別開(kāi)發(fā)強(qiáng)大的 NCB 和 NTB 來(lái)模擬視覺(jué)數(shù)據(jù)中的短期和長(zhǎng)期依賴關(guān)系。NTB 中還進(jìn)行了局部和全局信息的融合,進(jìn)一步提高了建模能力。最后,為了克服現(xiàn)有方法的固有缺陷,該研究系統(tǒng)地研究了卷積和 Transformer 塊的集成方式,提出了 NHS 策略,來(lái)堆疊 NCB 和 NTB 構(gòu)建新型 CNN-Transformer 混合架構(gòu)。
NCB
研究者分析了幾種經(jīng)典結(jié)構(gòu)設(shè)計(jì),如下圖 3 所示。ResNet [9] 提出的 BottleNeck 塊由于其在大多數(shù)硬件平臺(tái)上固有的歸納偏置和易于部署的特性,長(zhǎng)期以來(lái)一直在視覺(jué)神經(jīng)網(wǎng)絡(luò)中占據(jù)主導(dǎo)地位。不幸的是,與 Transformer 塊相比,BottleNeck 塊的有效性欠佳。ConvNeXt 塊 [20] 通過(guò)模仿 Transformer 塊的設(shè)計(jì),對(duì) BottleNeck 塊進(jìn)行了現(xiàn)代化改造。雖然 ConvNeXt 塊提高了網(wǎng)絡(luò)性能,但它在 TensorRT/CoreML 上的推理速度受到低效組件的嚴(yán)重限制。Transformer 塊在各種視覺(jué)任務(wù)中取得了優(yōu)異的成績(jī),然而 Transformer 塊的推理速度比 TensorRT 和 CoreML 上的 BottleNeck 塊要慢得多,因?yàn)槠渥⒁饬C(jī)制比較復(fù)雜,這在大多數(shù)現(xiàn)實(shí)工業(yè)場(chǎng)景中是難以承受的。
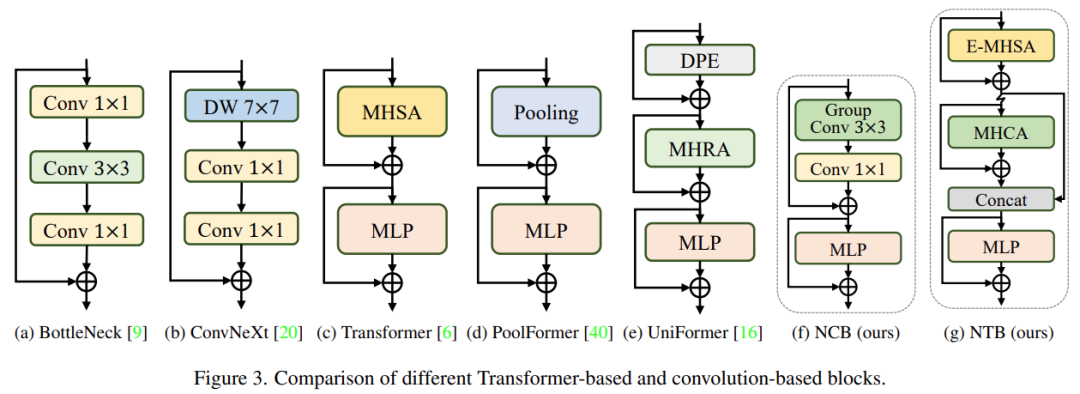
為了克服上述幾種塊的問(wèn)題,該研究提出了 Next Convolution Block (NCB),它在保持 BottleNeck 塊的部署優(yōu)勢(shì)的同時(shí)獲得了 Transformer 塊的突出性能。如圖 3(f) 所示,NCB 遵循 MetaFormer (已被證實(shí)對(duì) Transformer 塊至關(guān)重要) 的一般架構(gòu)。
此外,一個(gè)高效的基于注意力的 token 混合器同樣重要。該研究設(shè)計(jì)了一種多頭卷積注意力(MHCA)作為部署卷積操作的高效 token 混合器,并在 MetaFormer [40] 的范式中使用 MHCA 和 MLP 層構(gòu)建 NCB。
NTB
NCB 已經(jīng)有效地學(xué)習(xí)了局部表征,下一步需要捕獲全局信息。Transformer 架構(gòu)具有很強(qiáng)的捕獲低頻信號(hào)的能力,這些信號(hào)能夠提供全局信息(例如全局形狀和結(jié)構(gòu))。
然而,相關(guān)研究已經(jīng)發(fā)現(xiàn),Transformer 塊可能會(huì)在一定程度上惡化高頻信息,例如局部紋理信息。不同頻段的信號(hào)在人類視覺(jué)系統(tǒng)中是必不可少的,它們以某種特定的方式融合,以提取更多本質(zhì)和獨(dú)特的特征。
受這些已知結(jié)果的影響,該研究開(kāi)發(fā)了 Next Transformer Block (NTB),以在輕量級(jí)機(jī)制中捕獲多頻信號(hào)。此外,NTB 可用作有效的多頻信號(hào)混頻器,進(jìn)一步增強(qiáng)整體建模能力。
NHS
近期一些工作努力將 CNN 和 Transformer 結(jié)合起來(lái)進(jìn)行高效部署。如下圖 4(b)(c) 所示,它們幾乎都在淺層階段采用卷積塊,在最后一兩個(gè)階段僅堆疊 Transformer 塊,這種結(jié)合方式在分類任務(wù)上是有效的。但該研究發(fā)現(xiàn)這些混合策略很容易在下游任務(wù)(例如分割和檢測(cè))上達(dá)到性能飽和。原因是,分類任務(wù)僅使用最后階段的輸出進(jìn)行預(yù)測(cè),而下游任務(wù)(例如分割和檢測(cè))通常依賴每個(gè)階段的特征來(lái)獲得更好的結(jié)果。這是因?yàn)閭鹘y(tǒng)的混合策略只是在最后幾個(gè)階段堆疊 Transformer 塊,淺層無(wú)法捕獲全局信息。
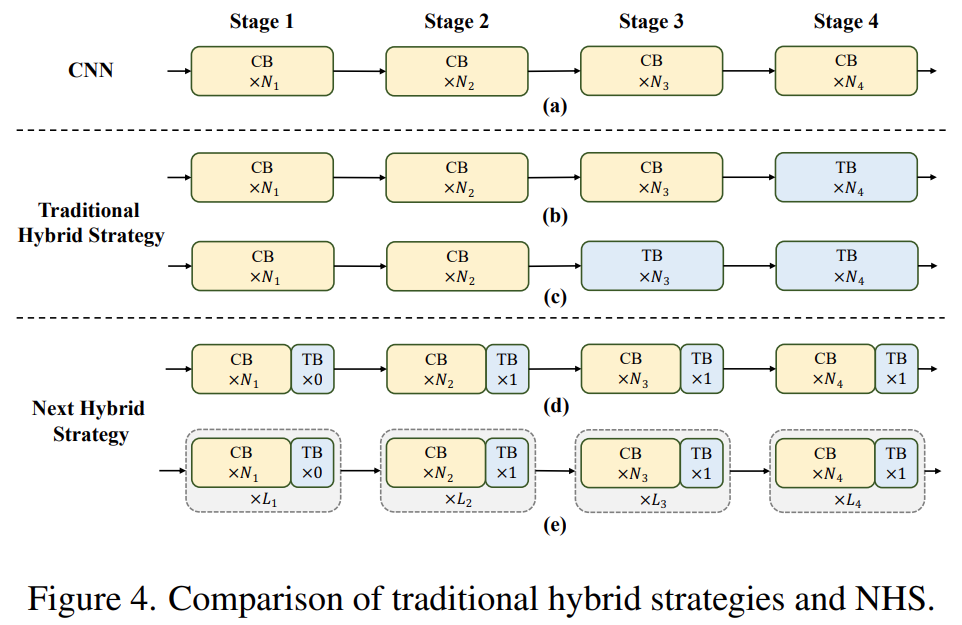
該研究提出了一種新的混合策略 (NHS),創(chuàng)造性地將卷積塊 (NCB) 和 Transformer 塊 (NTB) 與 (N + 1) * L 混合范式結(jié)合在一起。NHS 在控制 Transformer 塊比例的情況下,顯著提升了模型在下游任務(wù)上的性能,并實(shí)現(xiàn)了高效部署。
首先,為了賦予淺層捕獲全局信息的能力,該研究提出了一種(NCB×N+NTB×1)模式混合策略,在每個(gè)階段依次堆疊 N 個(gè) NCB 和一個(gè) NTB,如圖 4(d) 所示。具體來(lái)說(shuō),Transformer 塊 (NTB) 放置在每個(gè)階段的末尾,使得模型能夠?qū)W習(xí)淺層中的全局表征。該研究進(jìn)行了一系列實(shí)驗(yàn)來(lái)驗(yàn)證所提出的混合策略的優(yōu)越性,不同混合策略的性能如下表 1 所示。
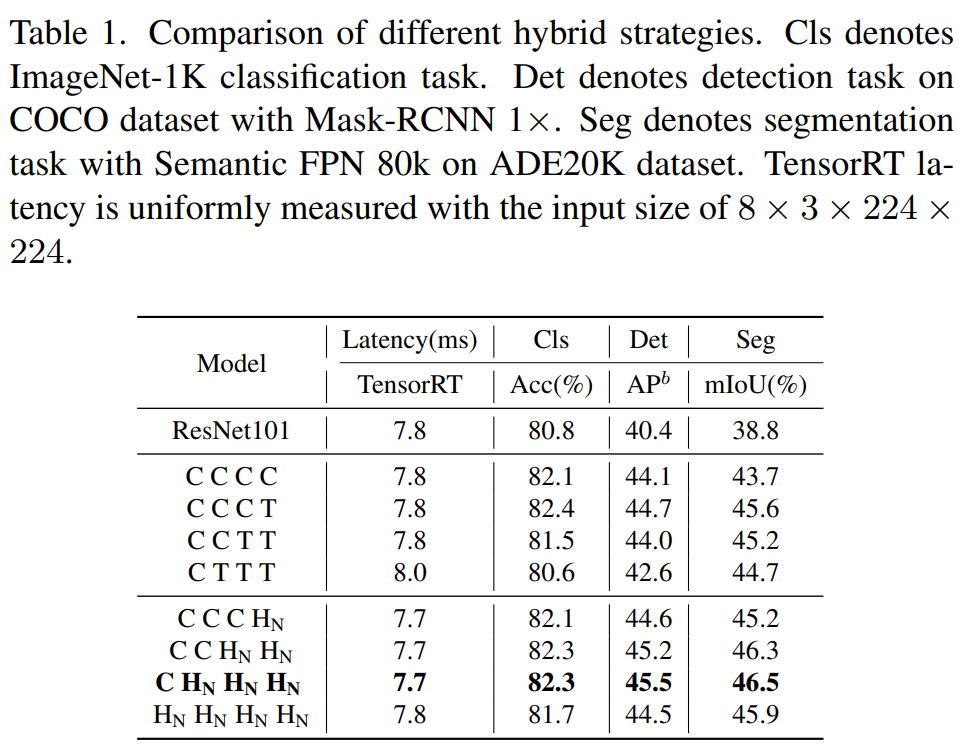
此外,如下表 2 所示,大模型的性能會(huì)逐漸達(dá)到飽和。這種現(xiàn)象表明,通過(guò)擴(kuò)大 (NCB × N + NTB × 1) 模式的 N 來(lái)擴(kuò)大模型大小,即簡(jiǎn)單地添加更多的卷積塊并不是最佳選擇,(NCB × N + NTB × 1)模式中的 N 值可能會(huì)嚴(yán)重影響模型性能。
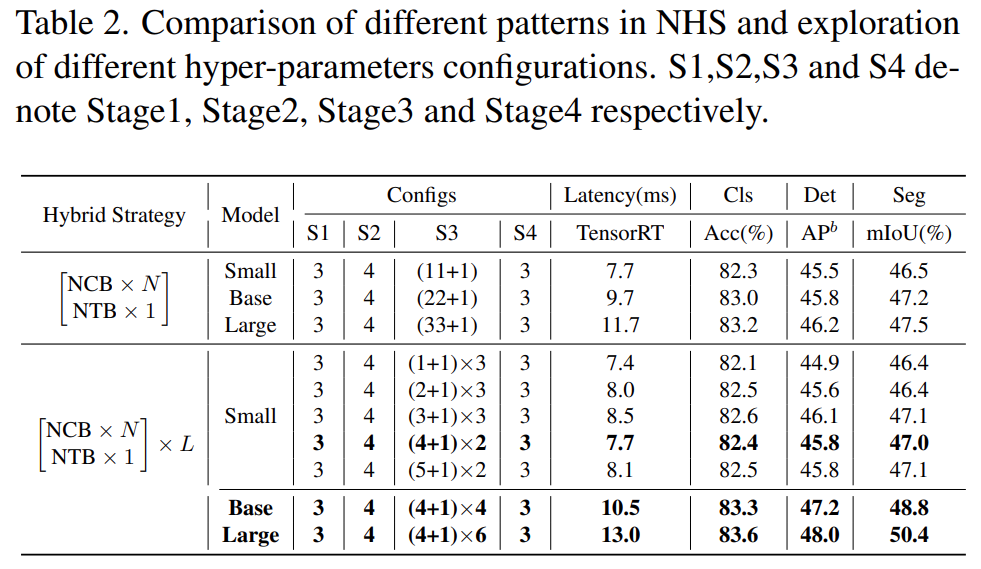
因此,研究者開(kāi)始通過(guò)廣泛的實(shí)驗(yàn)探索 N 的值對(duì)模型性能的影響。如表 2(中)所示,該研究在第三階段構(gòu)建了具有不同 N 值的模型。為了構(gòu)建具有相似延遲的模型以進(jìn)行公平比較,該研究在 N 值較小時(shí)堆疊 L 組 (NCB × N + NTB × 1) 模式。
如表 2 所示,第三階段 N = 4 的模型實(shí)現(xiàn)了性能和延遲之間的最佳權(quán)衡。該研究通過(guò)在第三階段擴(kuò)大 (NCB × 4 + NTB × 1) × L 模式的 L 來(lái)進(jìn)一步構(gòu)建更大的模型。如表 2(下)所示,Base(L = 4)和 Large(L = 6)模型的性能相對(duì)于小模型有顯著提升,驗(yàn)證了所提出的(NCB × N + NTB × 1)× L 模式的一般有效性。
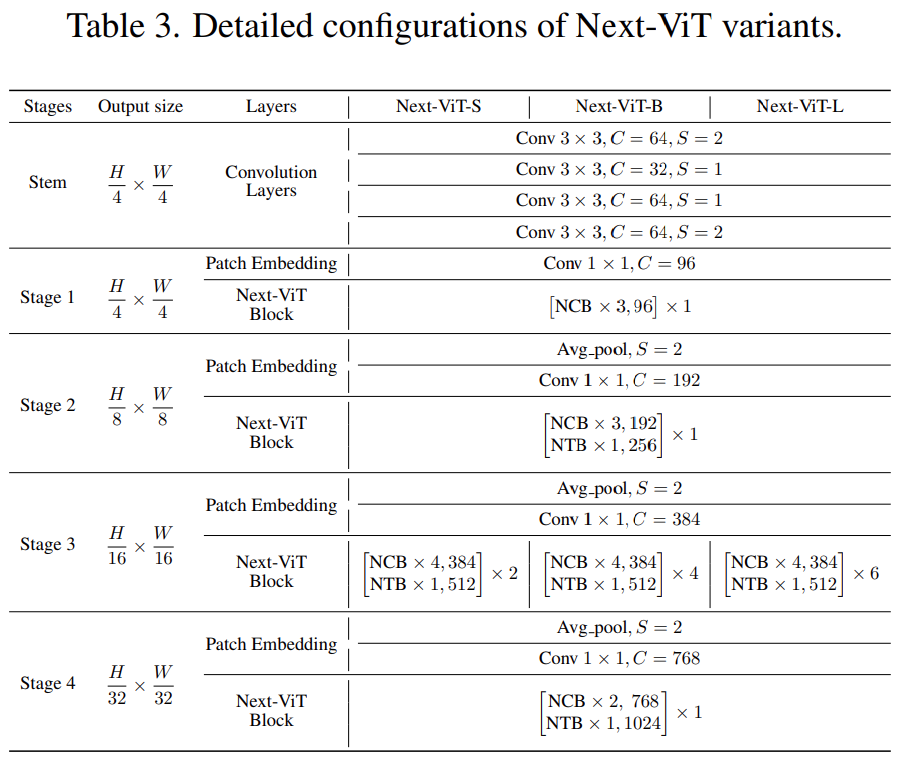
最后,為了提供與現(xiàn)有 SOTA 網(wǎng)絡(luò)的公平比較,研究者提出了三個(gè)典型的變體,即 Next-ViTS/B/L。
實(shí)驗(yàn)結(jié)果
ImageNet-1K 上的分類任務(wù)
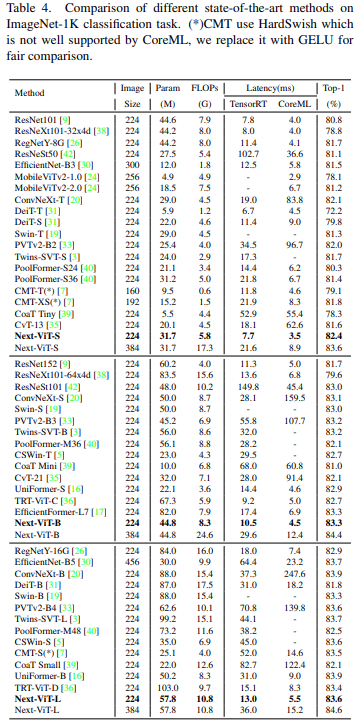
與最新的 SOTA 方法(例如 CNN、ViT 和混合網(wǎng)絡(luò))相比,Next-ViT 在準(zhǔn)確性和延遲之間實(shí)現(xiàn)了最佳權(quán)衡,結(jié)果如下表 4 所示。
ADE20K 上的語(yǔ)義分割任務(wù)
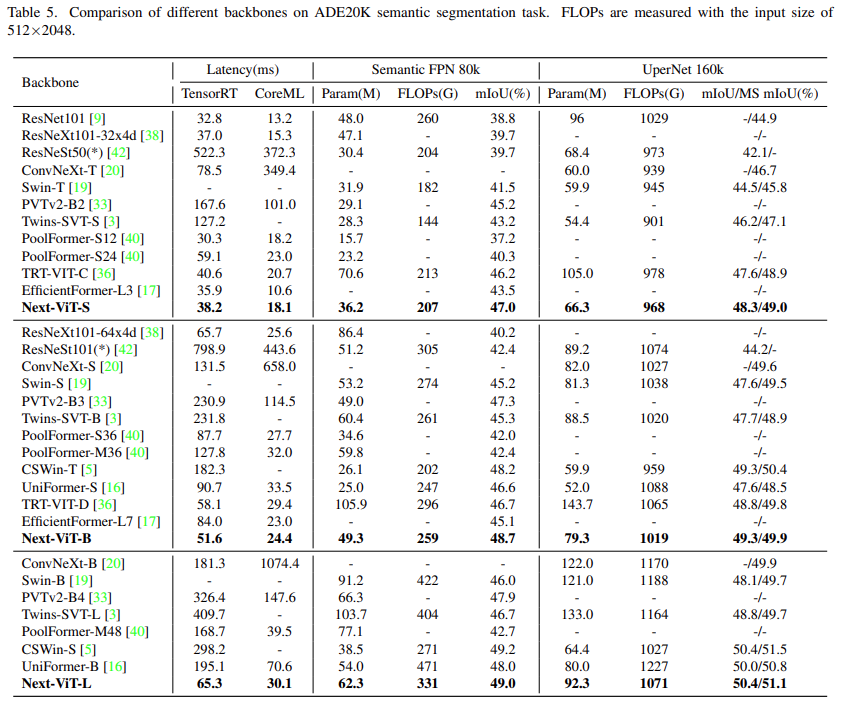
該研究將 Next-ViT 與 CNN、ViT 和最近一些混合架構(gòu)針對(duì)語(yǔ)義分割任務(wù)進(jìn)行了比較。如下表 5 所示,大量實(shí)驗(yàn)表明,Next-ViT 在分割任務(wù)上具有出色的潛力。
目標(biāo)檢測(cè)和實(shí)例分割
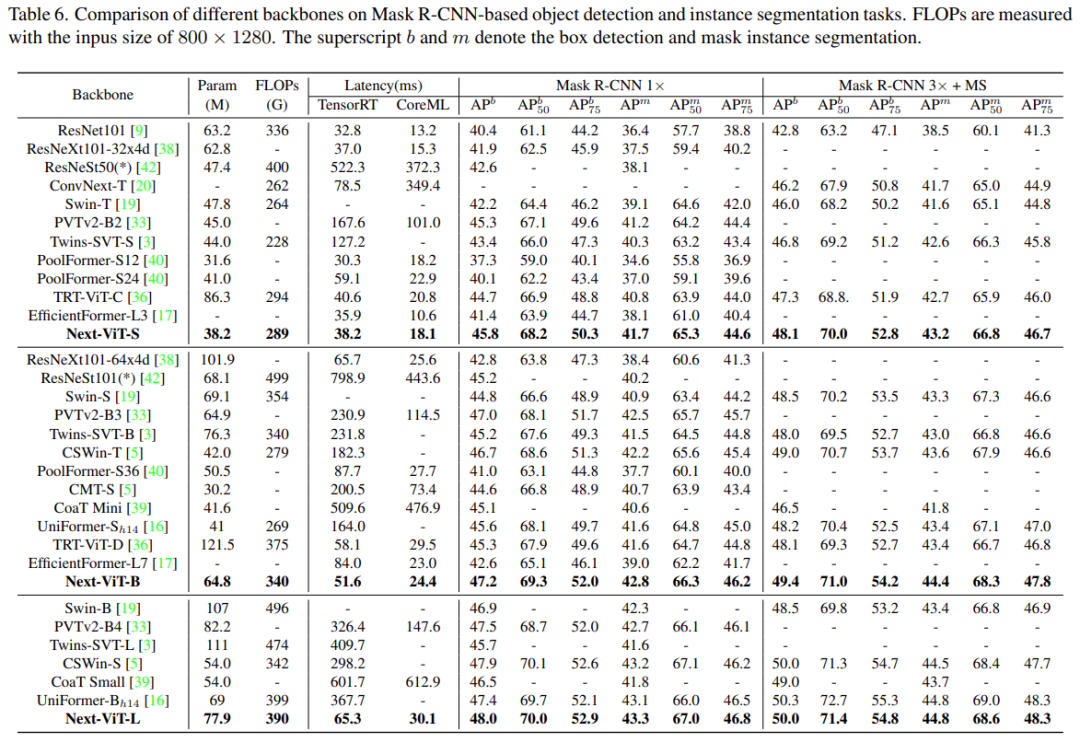
在目標(biāo)檢測(cè)和實(shí)例分割任務(wù)上,該研究將 Next-ViT 與 SOTA 模型進(jìn)行了比較,結(jié)果如下表 6 所示。
消融實(shí)驗(yàn)和可視化
為了更好地理解 Next-ViT,研究者通過(guò)評(píng)估其在 ImageNet-1K 分類和下游任務(wù)上的性能來(lái)分析每個(gè)關(guān)鍵設(shè)計(jì)的作用,并將輸出特征的傅里葉譜和熱圖可視化,以顯示 Next-ViT 的內(nèi)在優(yōu)勢(shì)。
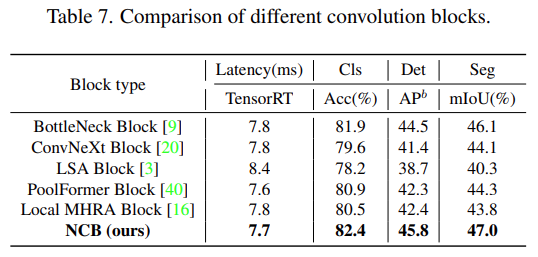
如下表 7 所示,NCB 在所有三個(gè)任務(wù)上實(shí)現(xiàn)了最佳延遲 / 準(zhǔn)確性權(quán)衡。
對(duì)于 NTB 塊,該研究探討了 NTB 的收縮率 r 對(duì) Next-ViT 整體性能的影響,結(jié)果如下表 8 所示,減小收縮率 r 將減少模型延遲。
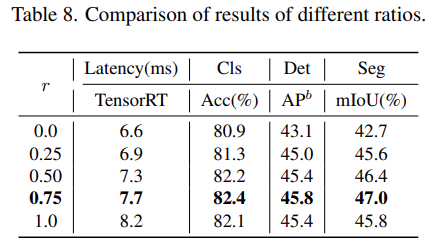
此外,r = 0.75 和 r = 0.5 的模型比純 Transformer (r = 1) 的模型具有更好的性能。這表明以適當(dāng)?shù)姆绞饺诤隙囝l信號(hào)將增強(qiáng)模型的表征學(xué)習(xí)能力。特別是,r = 0.75 的模型實(shí)現(xiàn)了最佳的延遲 / 準(zhǔn)確性權(quán)衡。這些結(jié)果說(shuō)明了 NTB 塊的有效性。
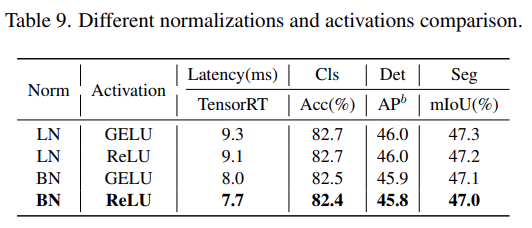
該研究進(jìn)一步分析了 Next-ViT 中不同歸一化層和激活函數(shù)的影響。如下表 9 所示,LN 和 GELU 雖然帶來(lái)一些性能提升,但在 TensorRT 上的推理延遲明顯更高。另一方面,BN 和 ReLU 在整體任務(wù)上實(shí)現(xiàn)了最佳的延遲 / 準(zhǔn)確性權(quán)衡。因此,Next-ViT 統(tǒng)一使用 BN 和 ReLU,以便在現(xiàn)實(shí)工業(yè)場(chǎng)景中進(jìn)行高效部署。
最后,該研究可視化了 ResNet、Swin Transformer 和 Next-ViT 的輸出特征的傅里葉譜和熱圖,如下圖 5(a) 所示。ResNet 的頻譜分布表明卷積塊傾向于捕獲高頻信號(hào)、難以關(guān)注低頻信號(hào);ViT 擅長(zhǎng)捕捉低頻信號(hào)而忽略高頻信號(hào);而Next-ViT 能夠同時(shí)捕獲高質(zhì)量的多頻信號(hào),這顯示了 NTB 的有效性。
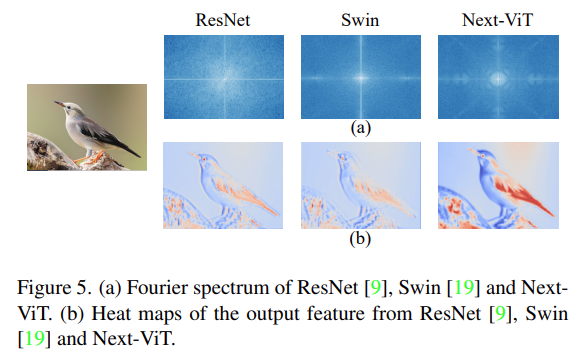
此外,如圖 5(b)所示,Next-ViT 能比 ResNet 和 Swin 捕獲更豐富的紋理信息和更準(zhǔn)確的全局信息,這說(shuō)明 Next-ViT 的建模能力更強(qiáng)。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4785瀏覽量
101266 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7191瀏覽量
89767 -
混頻器
+關(guān)注
關(guān)注
10文章
685瀏覽量
45866
原文標(biāo)題:解鎖CNN和Transformer正確結(jié)合方法,字節(jié)跳動(dòng)提出有效的下一代視覺(jué)Transformer
文章出處:【微信號(hào):CVSCHOOL,微信公眾號(hào):OpenCV學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
【書籍評(píng)測(cè)活動(dòng)NO.56】極速探索HarmonyOS NEXT:純血鴻蒙應(yīng)用開(kāi)發(fā)實(shí)踐
華為鴻蒙NEXT系統(tǒng)的優(yōu)勢(shì)與劣勢(shì)
使用ReMEmbR實(shí)現(xiàn)機(jī)器人推理與行動(dòng)能力
華為HarmonyOS NEXT 10月8日開(kāi)啟公測(cè)

OpenAI宣布啟動(dòng)GPT Next計(jì)劃
HarmonyOS NEXT Developer Beta1中的Kit
鴻蒙NEXT首次將AI能力融入系統(tǒng)
HDC 2024上,HarmonyOS NEXT有哪些精彩亮點(diǎn)值得期待?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論