") 基于序列標(biāo)注的實(shí)體識(shí)別所存在的問題
基于序列標(biāo)注的實(shí)體識(shí)別所存在的問題
寫在前面
今天要跟大家分享的是西湖大學(xué)張?jiān)览蠋?018年發(fā)表在頂會(huì)ACL上的一篇中文實(shí)體識(shí)別論文Lattice LSTM。
論文名稱:《Chinese NER Using Lattice LSTM》
論文鏈接:https://arxiv.org/pdf/1805.02023.pdf
代碼地址:https://github.com/jiesutd/LatticeLSTM
分享這個(gè)工作主要原因是:這個(gè)工作本身質(zhì)量比較高,可以說是利用詞匯增強(qiáng)中文NER的開篇之作,并且思路清晰,創(chuàng)新有理有據(jù)。
本篇文章主要內(nèi)容將圍繞下圖中的兩點(diǎn)展開:

1. 基于序列標(biāo)注的實(shí)體識(shí)別所存在的問題
如下圖,這部分主要包含兩個(gè)內(nèi)容,即:經(jīng)典的LSTM-CRF實(shí)體識(shí)別模型及該類模型所存在的問題。

1.1 經(jīng)典LSTM-CRF模型
實(shí)體識(shí)別通常被當(dāng)作序列標(biāo)注任務(wù)來做,序列標(biāo)注模型需要對實(shí)體邊界和實(shí)體類別進(jìn)行預(yù)測,從而識(shí)別和提取出相應(yīng)的命名實(shí)體。在BERT出現(xiàn)以前,實(shí)體識(shí)別的SOTA模型是LSTM+CRF,模型本身很簡單:
首先利用嵌入方法將句子中的每個(gè)token轉(zhuǎn)化為向量再輸入LSTM(或BiLSTM);
然后使用LSTM對輸入的信息進(jìn)行編碼;
最后利用CRF對LSTM的輸出結(jié)果進(jìn)行序列標(biāo)注。
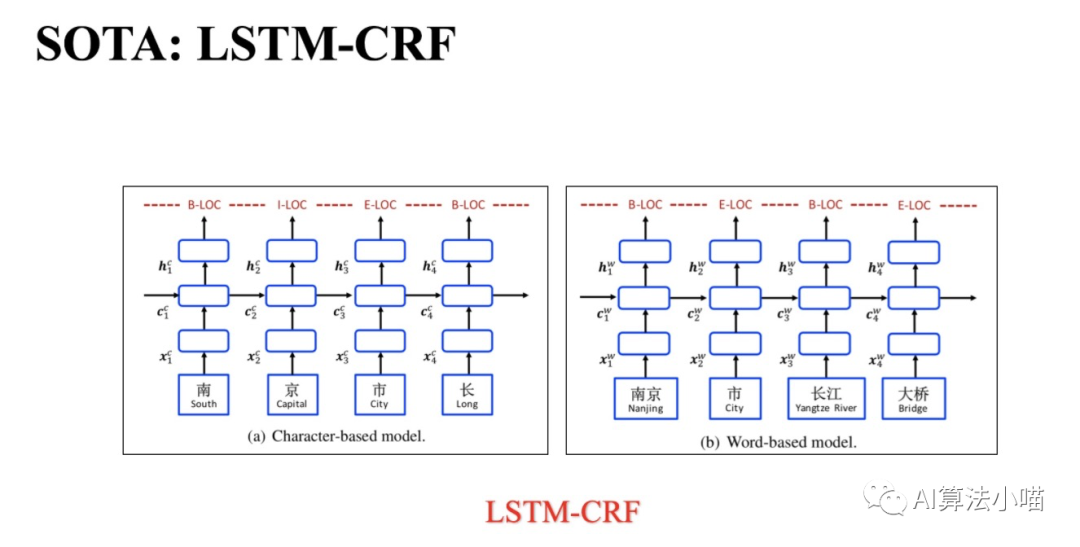
LSTM+CRF用在中文NER上,又可進(jìn)一步分為兩種:若token是詞,那么模型就屬于Word-based model;若token是字,那么模型就屬于Character-based Model。
(注:BERT+LSTM+CRF主要是將嵌入方法從Word2vec換成了BERT。)
1.2 誤差傳播與歧義問題

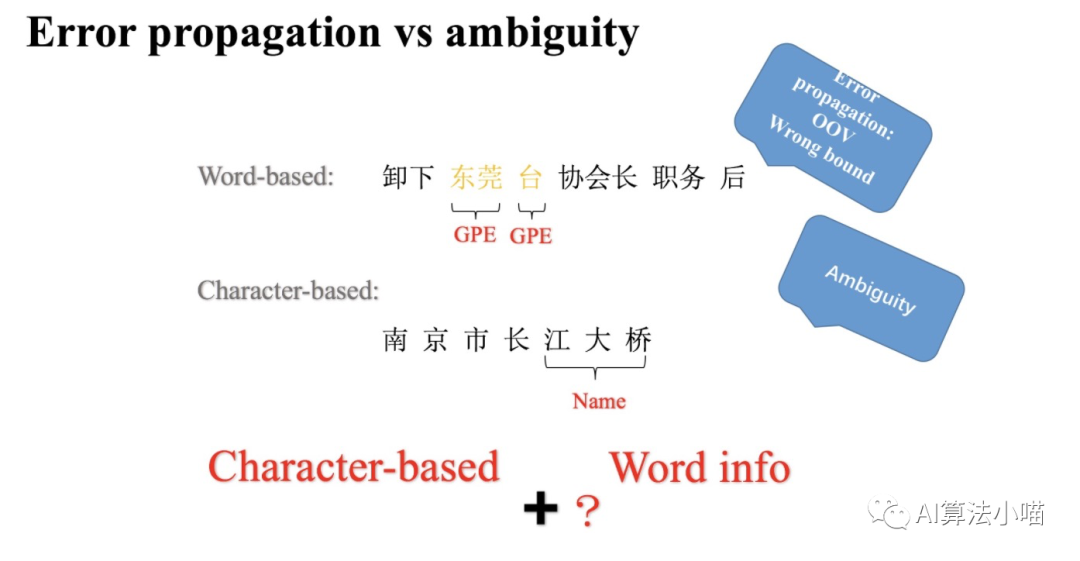
Word-based model存在誤差傳遞問題
Word-based model做實(shí)體識(shí)別需要先分詞,然后再對詞序列進(jìn)行實(shí)體識(shí)別即詞序列標(biāo)注。詞匯的邊界決定了實(shí)體的邊界,因此一旦出現(xiàn)分詞錯(cuò)誤就會(huì)影響實(shí)體邊界的判定。比如上圖中,利用分詞工具,“東莞臺(tái)協(xié)” 和 ”會(huì)長“ 被拆分成了“東莞”、“臺(tái)”、”協(xié)會(huì)長“,最終導(dǎo)致 ”東莞臺(tái)“ 被識(shí)別為了GPE。換句話說,Word-based model具有和其他兩階段模型同樣的誤差傳遞問題。
Character-based model存在歧義問題
既然分詞會(huì)有問題,那就不分詞。Character-based model直接在字的粒度上進(jìn)行實(shí)體識(shí)別即字序列標(biāo)注。許多研究工作表明,在中文NER上基于字的方法優(yōu)于基于詞的方法。但是,相比詞單字不具備完整語義。沒有利用句子里的詞的信息,難以應(yīng)對歧義問題,識(shí)別結(jié)果可能差強(qiáng)人意。如上圖,“會(huì)” 字本來應(yīng)該和 “長” 一起組成 “會(huì)長” ,但是最終模型卻將 “會(huì)” 與 “東莞臺(tái)協(xié)” 視為一個(gè)語塊兒,并將 “東莞臺(tái)協(xié)會(huì)” 預(yù)測為ORG。
1.3 思考
既然Character-based model、Word-based model各有優(yōu)缺點(diǎn),那是否可以結(jié)合二者進(jìn)行互補(bǔ)呢?換句話說,我們在Character-based model里加入詞信息,這樣是不是就可以既利用了詞信息,又不會(huì)因?yàn)榉衷~錯(cuò)誤影響識(shí)別結(jié)果呢?實(shí)際上,Lattice LSTM正是這樣做的。接下來我們一起跟隨文章的后續(xù)內(nèi)容來學(xué)習(xí)Lattice LSTM。
2. 模型細(xì)節(jié)
這一節(jié)我們首先會(huì)介紹最簡單的詞信息利用方方法,然后再對Lattice LSTM進(jìn)行詳細(xì)介紹。

2.1 簡單直接的拼接法
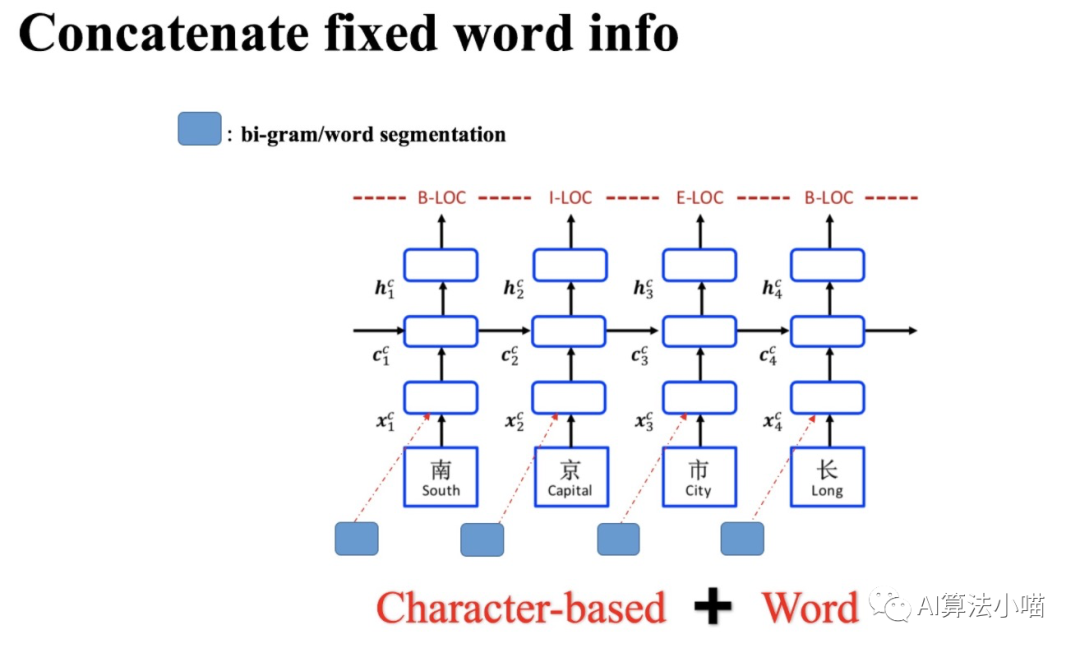
如上圖所示,最容易想到同時(shí)也是最簡單的詞信息利用方法就是直接拼接詞表征與字向量或者直接拼接詞表征與LSTM的輸出。16年的論文《A Convolution BiLSTM Neural Network Model for Chinese Event Extraction》[1]就采用了這樣的方法構(gòu)建了中文事件抽取模型,其模型結(jié)構(gòu)如下圖所示:
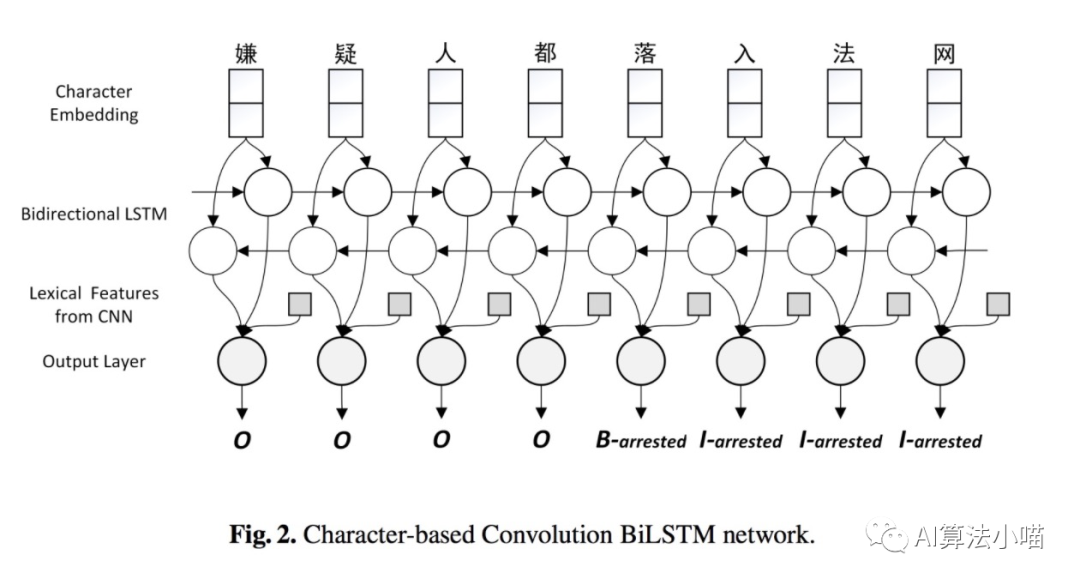
當(dāng)然這里詞表征可通過Word2Vec、Glove等詞向量模型獲得。也可以如16年的那篇事件抽取論文一樣利用CNN進(jìn)一步卷積獲得更上層的Local Context features,再將其拼接到模型中:
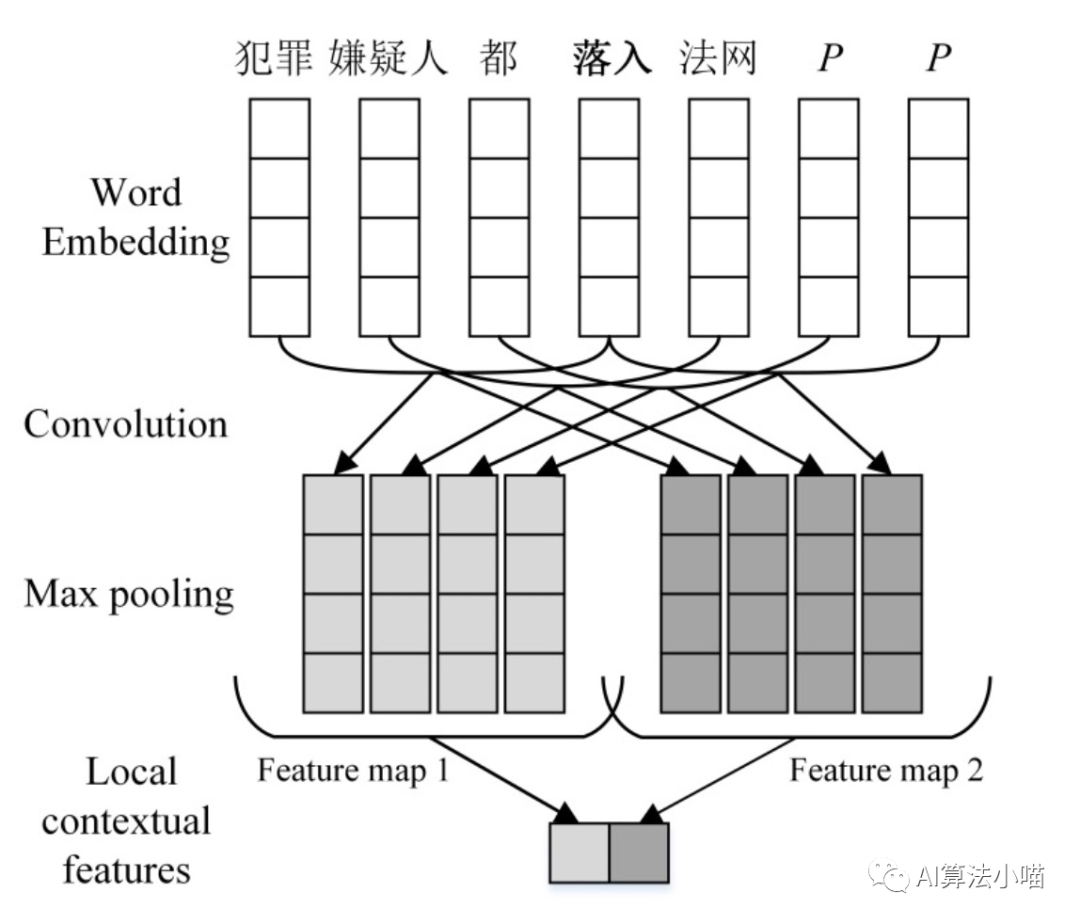
當(dāng)然這不是本文的重點(diǎn),我們關(guān)注的是Lattice LSTM是如何引入詞信息的。
2.2 Lattice 與潛在詞
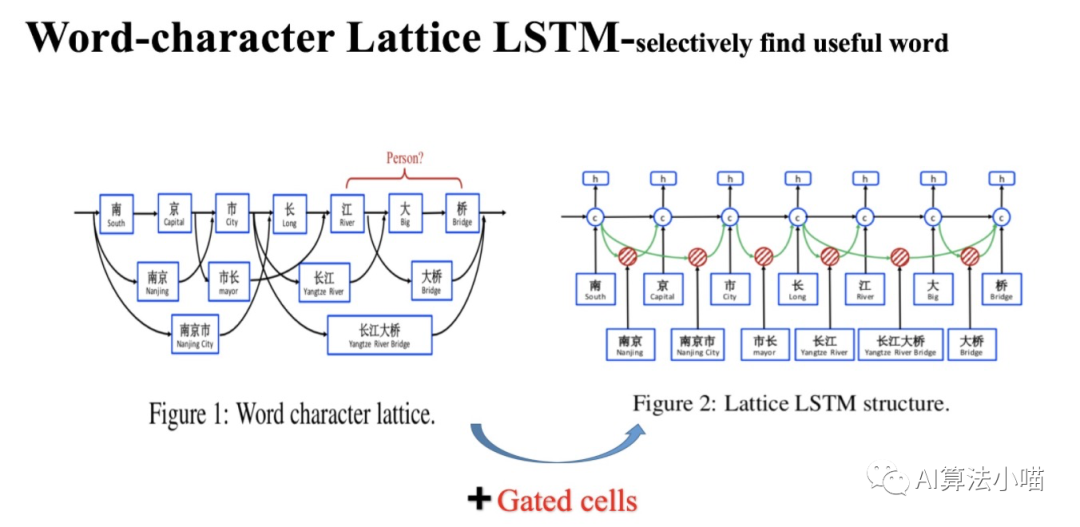
Lattice LSTM模型結(jié)構(gòu)如上圖右側(cè)所示。在正式開始介紹Lattice LSTM前,我們先來看看上圖左半部分。
(1)Lattice LSTM 名字來由
我們可以發(fā)現(xiàn)在上圖左側(cè)所示網(wǎng)絡(luò)中,除主干部分基于字的LSTM外,還連接了許多「格子」,每個(gè)「格子」里各含有一個(gè)潛在的詞,這些潛在詞所含有的信息將會(huì)與主干LSTM中相應(yīng)的Cell融合,看起來像一個(gè)「網(wǎng)格(Lattice)」。所以論文模型的名字就叫做Lattice LSTM,也就是有網(wǎng)格結(jié)構(gòu)的LSTM模型。
(2)詞典匹配獲得潛在詞
網(wǎng)格中的這些潛在詞是通過匹配輸入文本與詞典獲得的。比如通過匹配詞典, “南京市長江大橋”一句中就有“南京”、“市長”,“南京市”,“長江”,“大橋“,“長江大橋”等詞。
(3)潛在詞的影響
首先,“南京市長江大橋” 一句的正確結(jié)果應(yīng)當(dāng)是 “南京市-地點(diǎn)”、“長江大橋-地點(diǎn)”。如果我們直接利用Character-based model來進(jìn)行實(shí)體識(shí)別,可能獲得的結(jié)果是:“南京-地點(diǎn)”、“市長-職務(wù)”、“江大橋-人名”。現(xiàn)在利用詞典信息獲得了文本句的潛在詞:“南京”、“市長”,“南京市”,“長江”,“大橋“,“長江大橋” 等潛在詞。其中,“長江”、“大橋” 與 “長江大橋” 等詞信息的引入有利于模型,可以幫助模型避免犯 “江大橋-人名” 這樣的錯(cuò)誤;而 “市長” 這個(gè)詞的引入?yún)s可能會(huì)帶來歧義從而誤導(dǎo)模型,導(dǎo)致 “南京-地點(diǎn)”,“市長-職務(wù)” 這樣的錯(cuò)誤。
換句話說,通過詞典引入的詞信息有的具有正向作用,有的則不然。當(dāng)然,人為去篩除對模型不利的詞是不可能的,所以我們希望把潛在詞通通都丟給模型,讓模型自己去選擇有正向作用的詞,從而避免歧義。Lattice LSTM正是這么做的:它在Character-based LSTM+CRF的基礎(chǔ)上,將潛在詞匯信息融合進(jìn)去,從而使得模型在獲得字信息的同時(shí),也可以有效地利用詞的先驗(yàn)信息。
2.3 Lattice LSTM 模型細(xì)節(jié)
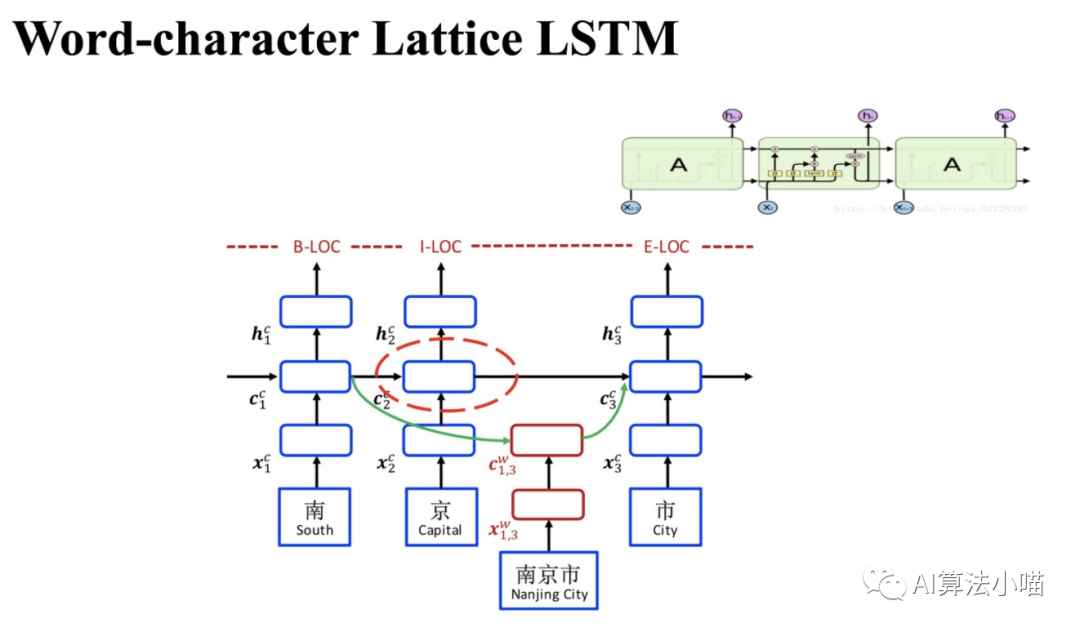
如上圖所示,Lattice LSTM模型的主干部分是基于字的LSTM-CRF(Character-based LSTM+CRF):
若當(dāng)前輸入的字在詞典中不存在任何以它結(jié)尾的詞時(shí):主干上Cell之間的傳遞就和正常的LSTM一樣。也就是說,這個(gè)時(shí)候Lattice LSTM退化成了基本LSTM。
若當(dāng)前輸入的字在詞典中存在以它結(jié)尾的詞時(shí):需要通過紅色Cell (見2.2節(jié)圖右側(cè))引入相關(guān)的潛在詞信息,然后與主干上基于字的LSTM中相應(yīng)的Cell進(jìn)行融合。
接下來,我們先簡單展示下LSTM的基本單元,再介紹紅色Cell,最后再介紹信息融合部分。
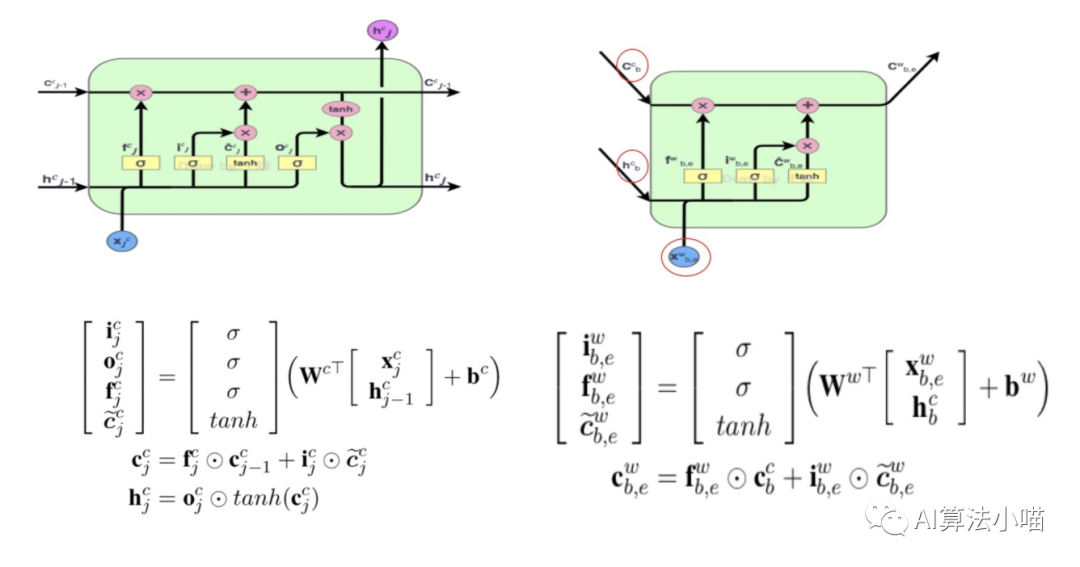
2.3.1 LSTM 單元
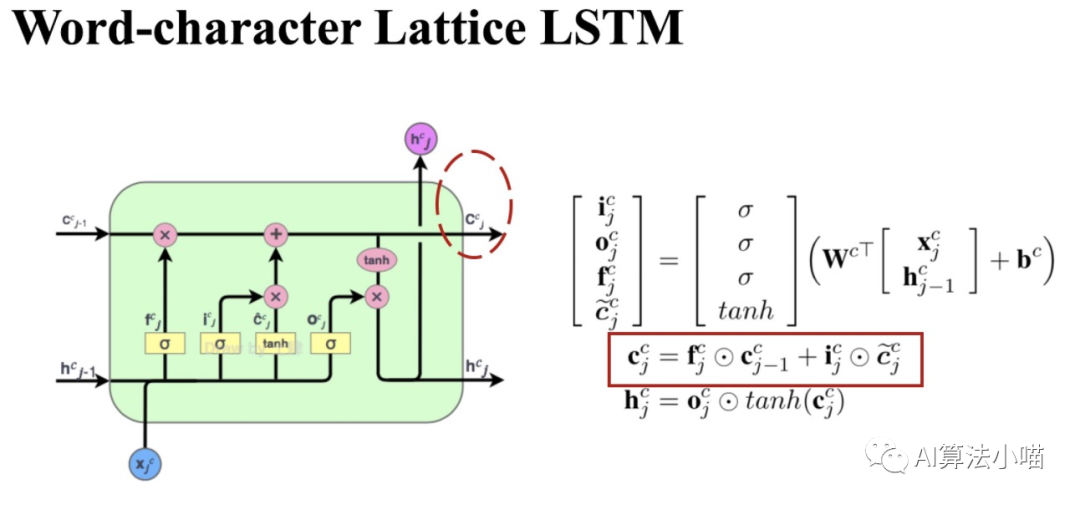
上圖左側(cè)展示了一個(gè)LSTM 單元(Cell)的內(nèi)部結(jié)構(gòu),右側(cè)展示了Cell的計(jì)算過程。在每個(gè)Cell中都有三個(gè)門控,即輸入門、遺忘門和輸出門。如上圖右側(cè)計(jì)算公式所示,這三個(gè)門實(shí)際上是0~1的小數(shù),其值是根據(jù)當(dāng)前時(shí)刻輸入 和前一時(shí)刻Cell的輸出的hidden state計(jì)算得到的:
輸入門:決定當(dāng)前輸入有多少可以加入Cell State,即 ;
遺忘門:決定Cell State要保留多少信息,即 。
輸出門:決定更新后的Cell State有多少可以被輸出,即 。
純粹的基于字的LSTM可以完全基于上述計(jì)算過程去計(jì)算,而Lattice LSTM則有所不同。
2.3.2紅色Cell
前面我們提過「如果當(dāng)前字在詞典中存在以它結(jié)尾的詞時(shí),需要通過紅色Cell引入相關(guān)潛在詞信息,與主干上基于字的LSTM中相應(yīng)Cell進(jìn)行融合」。以下圖中 "市" 字為例,句子中潛在的以它結(jié)尾的詞有:"南京市"。所以,對于"市"字對應(yīng)的Cell而言,還需要考慮 “南京市” 這個(gè)詞的信息。
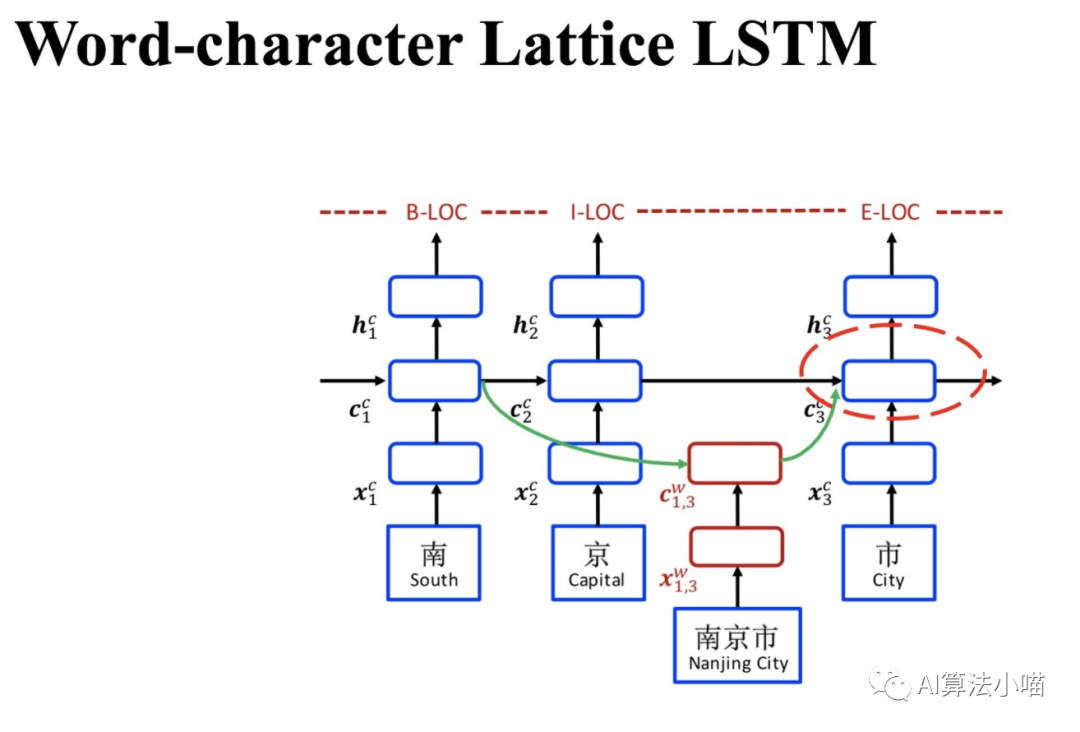
紅色Cell的內(nèi)部結(jié)構(gòu)與主干上LSTM的Cell很類似。接下來,我們具體來看下紅色Cell內(nèi)部計(jì)算過程。
(1) 紅色Cell 的輸入
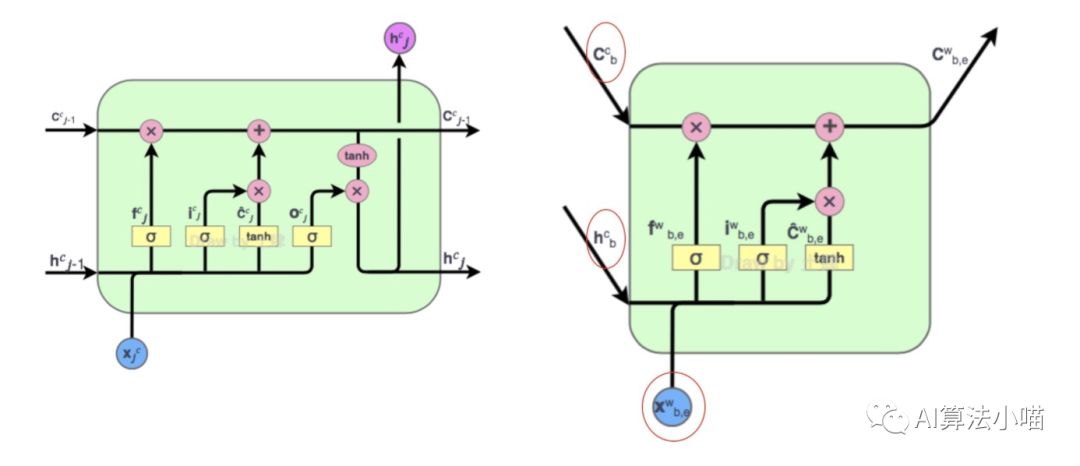
與上圖左側(cè)LSTM的Cell對比,上圖右側(cè)紅色Cell有兩種類型的輸入:
潛在詞的首字對應(yīng)的LSTM單元輸出的Hidden State以及Cell State
潛在詞的詞向量。
(2) 紅色Cell 的輸出
???????????
可以發(fā)現(xiàn),因?yàn)樾蛄袠?biāo)記是在字級別,所以與左側(cè)LSTM的Cell相比,紅色Cell沒有輸出門,即它不輸出hidden state。
以“市”字為例,其潛在詞為“南京市“,所以、 來自于"南”字, 代表“南京市”的詞向量,紅色Cell內(nèi)部具體計(jì)算過程如下圖右側(cè)所示:
依托 “南” 字的hidden state與 “南京市” 的詞向量 計(jì)算輸入門 、遺忘門 以及狀態(tài)更新量 :
依托 “南” 字的Cell state、與 “南京市” 相關(guān)的狀態(tài)更新量 計(jì)算 “南京市“ 的Cell State:
最終紅色Cell只會(huì)向 "市" 字傳遞Cell State。
2.3.3 信息融合
(1)潛在詞的輸入門
現(xiàn)在對于主干上的Cell來說,除狀態(tài)更新量 外,還多了一個(gè)來自潛在詞的Cell State。潛在詞的信息不會(huì)全部融入當(dāng)前字的 Cell,需要進(jìn)行取舍,所以Lattice LSTM設(shè)計(jì)了額外的輸入門,其計(jì)算如下:
(2) 加權(quán)融合
前面我們舉的例子中都只有一個(gè)潛在詞。但實(shí)際上,對部分字來說可能會(huì)在詞典中匹配上很多詞,例如 “橋” 這個(gè)字就可以在詞典中匹配出 “大橋” 和 “長江大橋” 。為了將這些潛在詞與字信息融合,Lattice LSTM做了一個(gè)類似Attention的操作:
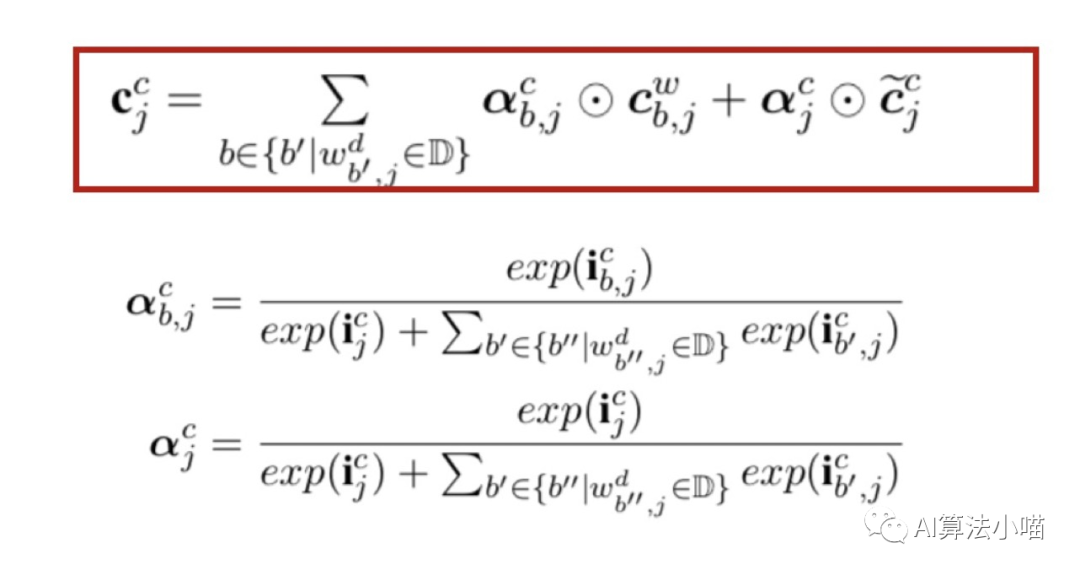
簡單地說,就是當(dāng)前字相應(yīng)的輸入門和所有以當(dāng)前字為尾字的候選詞的輸入門做歸一計(jì)算出權(quán)重,然后利用計(jì)算出的權(quán)重進(jìn)行向量加權(quán)融合。
以 “橋” 字為例,它有兩個(gè)潛在詞,即 “長江大橋” 與 “大橋” 。那么對 “橋” 字而言,它會(huì)收到三對值,分別是:“橋” 字的輸入門 與 狀態(tài) ;潛在詞 "長江大橋" 相關(guān)的輸入門 與Cell State;潛在詞 "大橋" 相關(guān)的輸入門 與Cell State,為了獲得最終 “橋” 的hidden State,需要經(jīng)過如下計(jì)算:
"長江大橋" 的權(quán)重:
“大橋” 的權(quán)重:
“橋“ 的權(quán)重:
加權(quán)融合獲得“橋“ 的Cell state:
“橋“ 的hidden state:
3. 實(shí)驗(yàn)
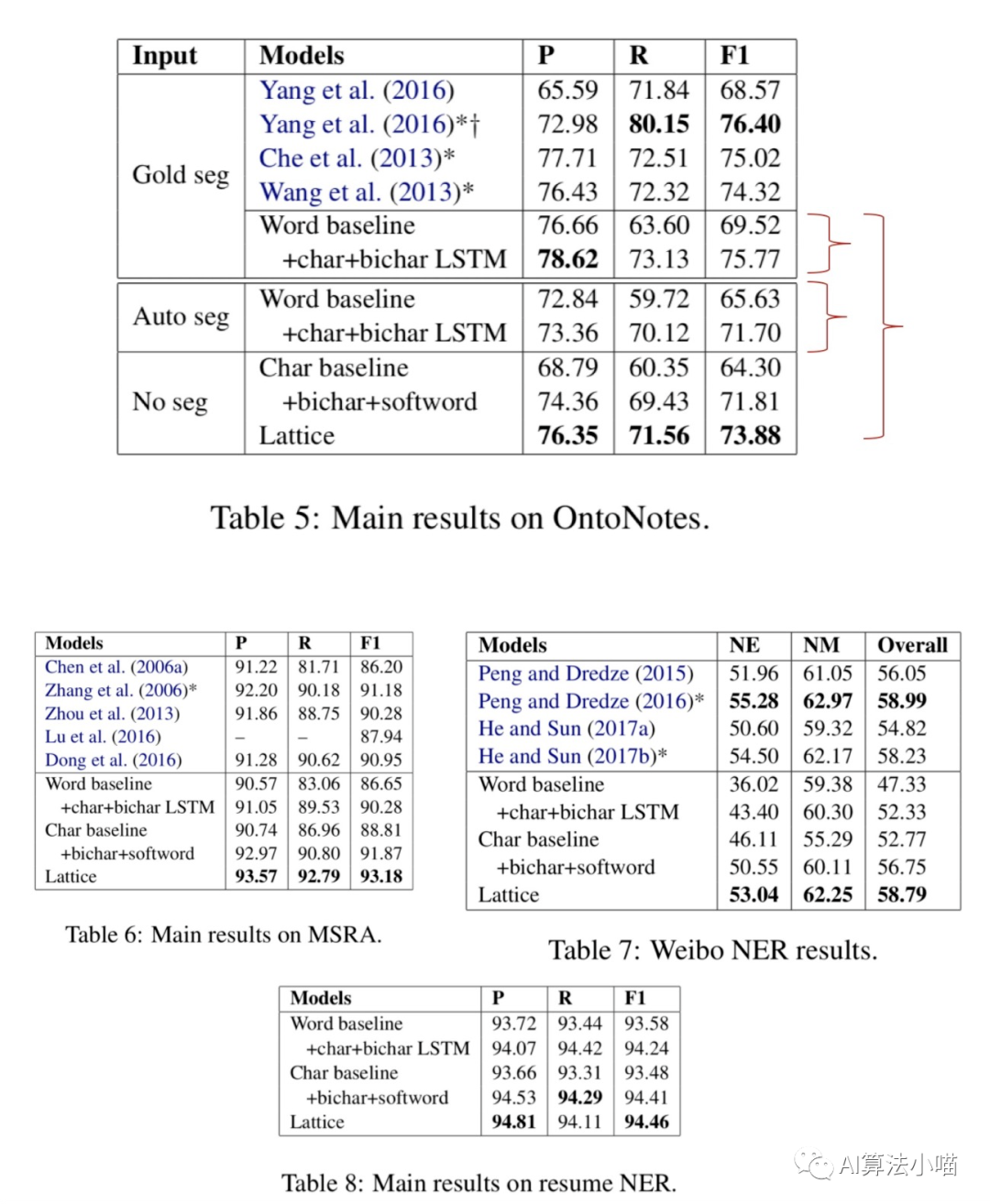
論文在Onto Notes、MSRA、微博NER、簡歷這4個(gè)數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn)。從實(shí)驗(yàn)結(jié)果可以看出Lattice LSTM比其他對比方法有一定的提升。本文不深入探討實(shí)驗(yàn)部分,感興趣的讀者可下載論文原文進(jìn)行閱讀。
總結(jié)
今天我們分享了中文實(shí)體識(shí)別模型Lattice LSTM,這是中文NLP領(lǐng)域非常重要的人物~張?jiān)览蠋熕麄兊墓ぷ鳌]記錯(cuò)的話,18年跟隨導(dǎo)師參加NLPCC會(huì)議時(shí),第一次見到張?jiān)览蠋煟羁谈杏X張?jiān)览蠋煶藢W(xué)術(shù)能力強(qiáng)以外,為人也非常真誠,很nice。
對NLP感興趣的讀者可以關(guān)注下張?jiān)澜淌谒麄兊钠渌ぷ鳌.?dāng)然還有國內(nèi)NLP領(lǐng)域的其他大師的工作,比如劉知遠(yuǎn)老師、車萬翔老師、劉挺老師、孫茂松老師、邱錫鵬老師等等。想要往科研方向深入的,也可以申請去他們那里讀博。當(dāng)然每個(gè)老師研究方向各有側(cè)重點(diǎn),我記得當(dāng)年關(guān)注到劉知遠(yuǎn)老師是因?yàn)樗麄兊闹R(shí)圖譜表示學(xué)習(xí)工作(TransE等)。
關(guān)注公眾號的讀者里可能有些不是NLP方向的也建議可以關(guān)注關(guān)注以上老師的工作。其實(shí)當(dāng)年我們參加這些會(huì)議的時(shí)候也不是做NLP方向的,但是交叉學(xué)科的工作多聽聽多看看總是有益處的。譬如我和我的同學(xué)們,現(xiàn)在多數(shù)都轉(zhuǎn)到了NLP方向,在各個(gè)公司里從事NLP算法研究員、NLP算法工程師等工作。
好了,本文就到這里,今天比較啰嗦,哈哈哈。還是一樣,如果本文對你有幫助的話,歡迎點(diǎn)贊&在看&分享,這對我繼續(xù)分享&創(chuàng)作優(yōu)質(zhì)文章非常重要。感謝!
參考資料 [1]
《A Convolution BiLSTM Neural Network Model for Chinese Event Extraction》: https://eprints.lancs.ac.uk/id/eprint/83783/1/160.pdf
審核編輯 :李倩
-
模型
+關(guān)注
關(guān)注
1文章
3499瀏覽量
50065 -
識(shí)別
+關(guān)注
關(guān)注
3文章
173瀏覽量
32190 -
LSTM
+關(guān)注
關(guān)注
0文章
60瀏覽量
3987
原文標(biāo)題:一文詳解中文實(shí)體識(shí)別模型 Lattice LSTM
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
AI時(shí)代 圖像標(biāo)注不要沒苦硬吃

東軟集團(tuán)入選國家數(shù)據(jù)局?jǐn)?shù)據(jù)標(biāo)注優(yōu)秀案例
大模型預(yù)標(biāo)注和自動(dòng)化標(biāo)注在OCR標(biāo)注場景的應(yīng)用
用于LEGIC Advant UID/序列號的NFC讀卡器,為什么無法讀取這些卡的UID/序列號?
自動(dòng)化標(biāo)注技術(shù)推動(dòng)AI數(shù)據(jù)訓(xùn)練革新
AI自動(dòng)圖像標(biāo)注工具SpeedDP將是數(shù)據(jù)標(biāo)注行業(yè)發(fā)展的重要引擎
標(biāo)貝數(shù)據(jù)標(biāo)注在智能駕駛訓(xùn)練中的落地案例

標(biāo)貝數(shù)據(jù)標(biāo)注案例分享:車載語音系統(tǒng)數(shù)據(jù)標(biāo)注
淺析基于自動(dòng)駕駛的4D-bev標(biāo)注技術(shù)

能否在TAS5731初始化之前識(shí)別到TAS5731存在?
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】全書概覽與時(shí)間序列概述
深度學(xué)習(xí)中的時(shí)間序列分類方法
車載語音識(shí)別系統(tǒng)語音數(shù)據(jù)采集標(biāo)注案例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論