 NVIDIA對 NeMo Megatron 框架進行更新 將訓練速度提高 30%
NVIDIA對 NeMo Megatron 框架進行更新 將訓練速度提高 30%

隨著大型語言模型(LLM)的規模和復雜性日益增加,NVIDIA 于今日宣布對 NeMo Megatron 框架進行更新,將訓練速度提高 30%。
此次更新包括兩項開創性的技術和一個超參數工具,用于優化和擴展任意數量 GPU 上的 LLM 訓練,這為使用 NVIDIA AI 平臺訓練和部署模型提供了新功能。
BLOOM 是全球最大的開放科學、開放存取多語言模型,具有 1760 億參數。該模型最近在NVIDIA AI 平臺上進行了訓練,支持 46 種語言和 13 種編程語言的文本生成。NVIDIA AI 平臺還提供了最強大的轉換器語言模型,具有 5300 億參數,Megatron-Turing NLG 模型 (MT-NLG) 。
LLMs 的最新進展
LLM 是當今最重要的先進技術之一,涉及從文本中學習的多達數萬億參數。但 LLM 的開發過程昂貴而耗時,需要深厚的技術知識、分布式基礎設施和全棧式方法。
LLM 也大大有助于推動實時內容生成、文本摘要、客服聊天機器人以及對話式AI問答界面的發展。
為了推動 LLM 的發展,人工智能(AI)社區正在繼續對 Microsoft DeepSpeed, Colossal-AI 和Hugging Face BigScience 和 Fairscale 等工具進行創新,這些工具均由 NVIDIA AI 平臺提供支持,包括 Megatron-LM、Apex 和其他 GPU 加速庫。
這些對 NVIDIA AI 平臺的全新優化有助于解決整個堆棧中現有的許多痛點。NVIDIA 期待著與 AI 社區合作,讓每個人都能享受到 LLM 的力量。
更快速構建 LLMs
NeMo Megatron 的最新更新令 GPT-3 模型的訓練速度提高了 30%,這些模型的規模從 220 億到 1 萬億個參數不等。現在使用 1024 個 NVIDIA A100 GPU 只需 24 天就可以訓練一個擁有 1750 億個參數的模型。相比推出新版本之前,獲得結果的時間縮短了 10 天或約 25 萬個小時的 GPU 計算。
NeMo Megatron 是快速、高效、易于使用的端到端容器化框架,它可以用于收集數據、訓練大規模模型、根據行業標準基準評估模型,并且以最高水準的延遲和吞吐性能進行推理。
它讓 LLM 訓練和推理在各種 GPU 集群配置上變得簡單、可復制。目前,早期訪問用戶客戶可在NVIDIA DGX SuperPOD、NVIDIA DGX Foundry 以及 Microsoft Azure 上運行這些功能。對其他云平臺的支持也即將推出。
另外,用戶還可以在 NVIDIA LaunchPad上進行功能試用。LaunchPad 是一項免費計劃,可提供短期內訪問 NVIDIA 加速基礎設施上的動手實驗室目錄的機會。
NeMo Megatron 是 NeMo 的一部分,開源框架 NeMo,用于為對話式 AI、語音 AI 和生物學構建高性能和靈活的應用程序。
兩項加速 LLM 訓練的新技術
此次更新包括兩項用于優化和擴展 LLM 訓練的新技術——序列并行(SP)和選擇性激活重計算(SAR)。
SP 通過注意到變換器層中尚未并行化的區域在序列維度是獨立的,以此擴展張量級模型的并行性。
沿序列維度分割層,可以將算力以及最重要的內激活內存分布到張量并行設備上。激活是分布式的,因此可以將更多的激活保存到反向傳播中,而無需重新計算。
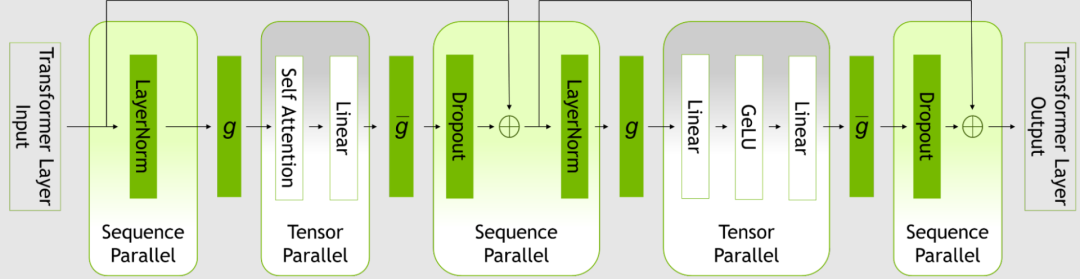
圖1. Transformer 層內的并行模式
SAR 通過注意到不同的激活在重計算時需要不同數量的運算,改善了內存限制迫使重新計算部分(但不是所有)激活的情況。
可以只對每個 Transformer 層中占用大量內存,但重新計算成本不高的部分設置檢查點和進行重新計算,而不是針對整個變換器層。
有關更多信息,請參見減少大型 Transformer 模型中的激活重計算: https://arxiv.org/abs/2205.05198
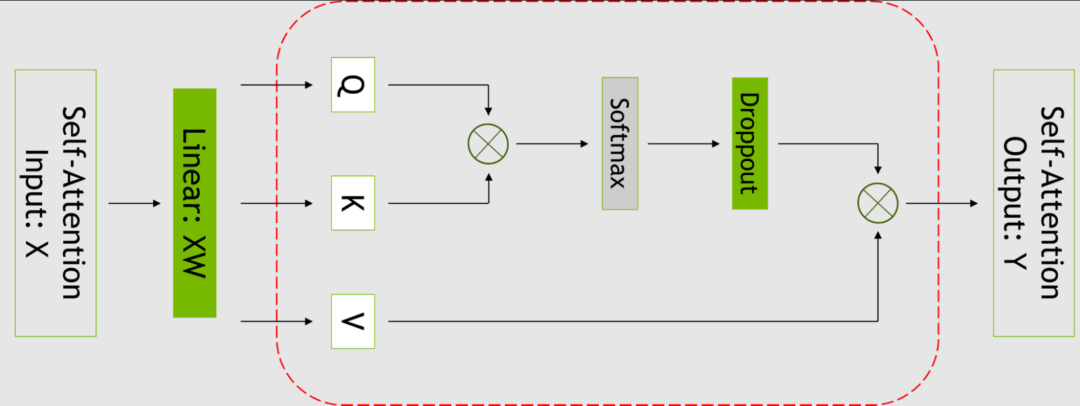
圖2. 自注意力塊。紅色虛線表示使用選擇性激活重計算的區域
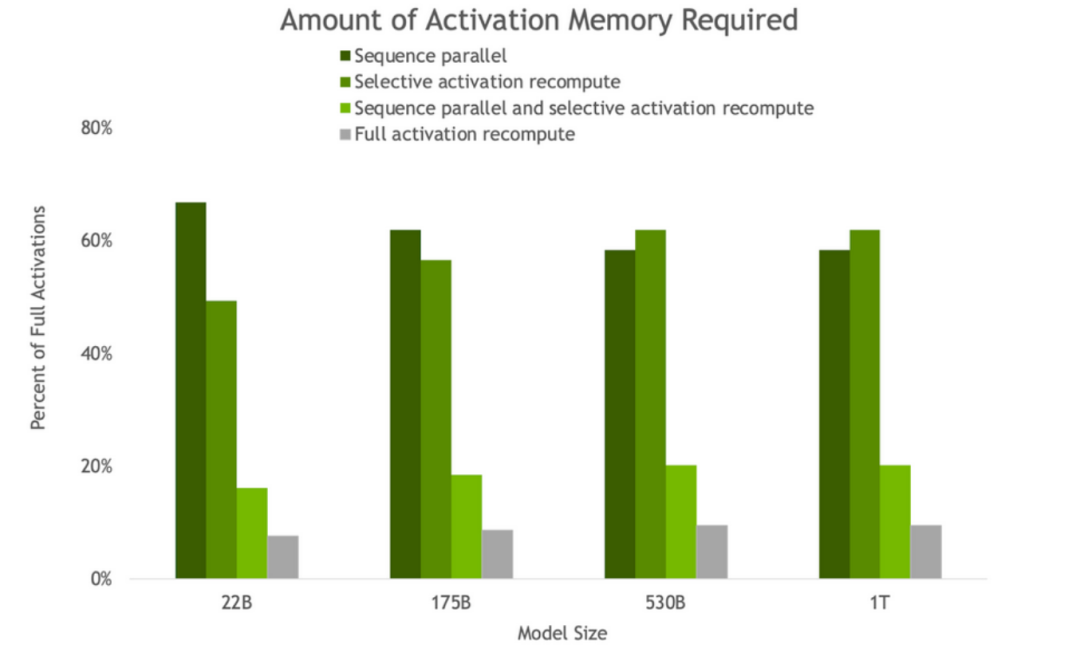
圖3. 反向傳播中因 SP 和 SAR 的存在而獲得的激活內存量。隨著模型大小的增加,SP 和 SAR 都會產生類似的內存節省,將內存需求減少約 5 倍。
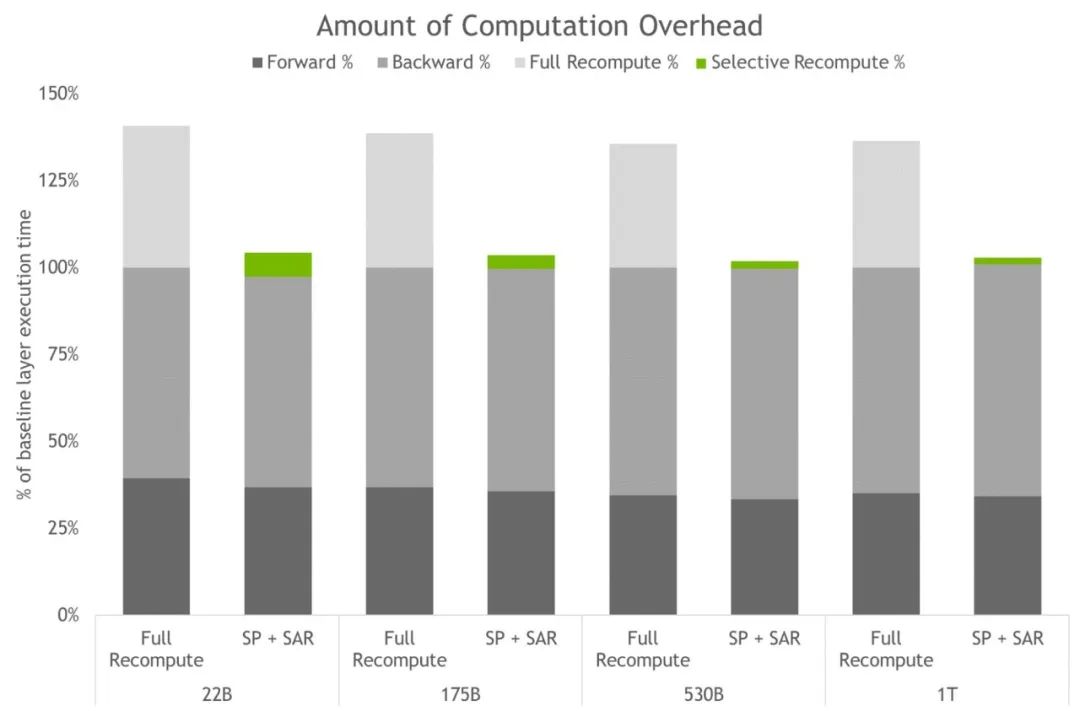
圖4. 完全激活重計算和 SP+SAR 的計算開銷。條形圖表示每層的前向、反向和重計算時間細分。基線代表沒有重計算和序列并行時的情況。這些技術有效地減少了所有激活被重計算而不是保存時產生的開銷。最大模型的開銷從 36% 下降到僅為 2%。
運用 LLM 的力量,還需要高度優化的推理策略。用戶可以十分輕松地將訓練好的模型用于推理并使用 P-tuning 和提示調整功能優化不同的用例。
這些功能是輕量化微調的有效替代方案,使 LLM 能夠適應新的用例,而不需要采取微調全部預訓練模型這種繁瑣的方法。在這項技術中,原始模型的參數并沒有被改變,因此避免了與微調模型相關的災難性的“遺忘”問題。
有關更多信息,請參見采用 P-Tuning 解決非英語下游任務: https://developer.nvidia.com/blog/adapting-p-tuning-to-solve-non-english-downstream-tasks/
用于訓練和推理的新超參數工具
在分布式基礎設施中為 LLM 尋找模型配置十分耗時。NeMo Megatron 帶來了超參數工具,它能夠自動找到最佳訓練和推理配置,而不需要修改代碼,這使 LLM 從第一天起就能在訓練中獲得推理收斂性,避免了在尋找高效模型配置上所浪費的時間。
該工具對不同的參數使用啟發法和經驗網格搜索來尋找具有最佳吞吐量的配置,包括數據并行性、張量并行性、管道并行性、序列并行性、微批大小和激活檢查點設置層的數量(包括選擇性激活重計算)。
通過使用超參數工具以及在 NGC 容器上的 NVIDIA 測試,NVIDIA 在 24 小時內就得到了 175B GPT-3 模型的最佳訓練配置(見圖5)。與使用完整激活重計算的通用配置相比,NVIDIA 將吞吐量速度提高了 20%-30%。對于參數超過 200 億的模型,NVIDIA 使用這些最新技術將吞吐量速度進一步提升 10%-20%。
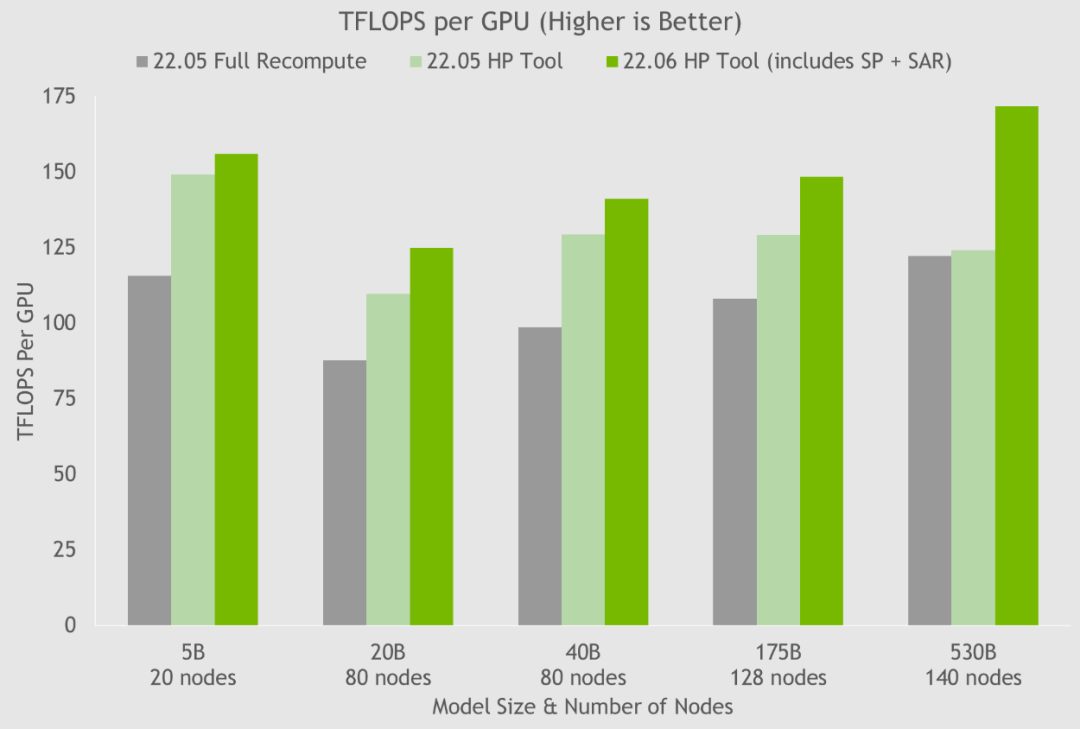
圖5. HP 工具在幾個容器上的結果顯示了通過序列并行和選擇性激活重計算實現的速度提升,其中每個節點都是 NVIDIA DGX A100。
超參數工具還可以找到在推理過程中實現最高吞吐量或最低延遲的模型配置。模型可以設置延遲和吞吐量限制,該工具也將推薦合適的配置。
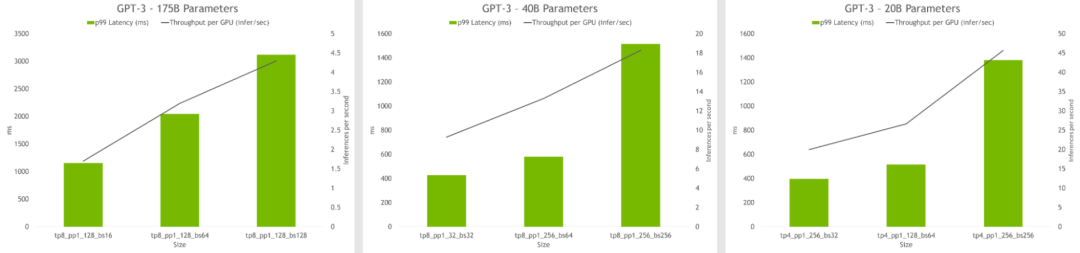
圖6. HP 工具的推理結果顯示每個 GPU 的吞吐量和不同配置的延遲。最佳配置包括高吞吐量和低延時。
-
機器人
+關注
關注
213文章
29748瀏覽量
212905 -
NVIDIA
+關注
關注
14文章
5309瀏覽量
106418 -
AI
+關注
關注
88文章
35164瀏覽量
280000
原文標題:NVIDIA AI 平臺大幅提高大型語言模型的性能
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA Isaac Lab可用環境與強化學習腳本使用指南

NVIDIA Isaac Sim與NVIDIA Isaac Lab的更新
ServiceNow攜手NVIDIA構建150億參數超級助手
企業使用NVIDIA NeMo微服務構建AI智能體平臺
NVIDIA NeMo Guardrails引入三項全新NIM微服務
NVIDIA 發布保障代理式 AI 應用安全的 NIM 微服務
NVIDIA宣布NVIDIA Isaac重要更新
簡述NVIDIA Isaac的重要更新

NVIDIA技術助力Pantheon Lab數字人實時交互解決方案
NVIDIA與合作伙伴推出代理式AI Blueprint
NVIDIA助力企業創建定制AI應用
日本企業借助NVIDIA產品加速AI創新
NVIDIA Nemotron-4 340B模型幫助開發者生成合成訓練數據

NVIDIA 攜手全球合作伙伴推出 NIM Agent Blueprints,助力企業打造屬于自己的 AI





 工商網監
工商網監
評論