 LeetCode 560:和為K的子數組
LeetCode 560:和為K的子數組
大家好,我是吳師兄,
今天的題目來源于 LeetCode 第 560 號問題:和為 K 的子數組,難度為「中等」。
一、題目描述
給你一個整數數組nums和一個整數k,請你統計并返回該數組中和為k的子數組的個數。
示例 1:
輸入:nums =[1,1,1], k = 2
輸出:2
示例 2:
輸入:nums =[1,2,3], k = 3
輸出:2
提示:
-
1 <= nums.length <= 2 * 10^4 -
-1000 <= nums[i] <= 1000 -
-10^7 <= k <= 10^7
二、題目解析
補充知識點前綴和:前綴和指一個數組的某下標之前的所有數組元素的和(包含其自身)。
利用前綴和這種特點,可以快速的計算某個區間內的和,比如前 i 個元素的前綴和為preSum[i] = num[0] + nums[1] + ... + nums[i],而前 j 個元素的前綴和為preSum[j] = num[0] + nums[1] + ... + nums[j]。
那么區間[ i , j ]之間的子數組之和就是 **preSum[j] - preSum[i]**。
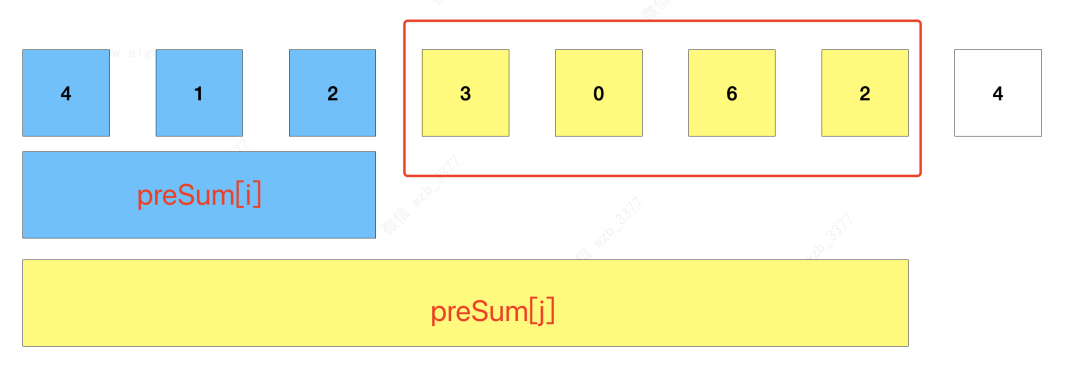
基于這種思路,可以先遍歷一次數組,求出前綴和數組。
題目這個時候就變成了需要尋找出多少個 i 和 j 的組合,使得 [ i , j ] 這個區間的和為 k。
classSolution{
publicintsubarraySum(int[]nums,intk){
intlen=nums.length;
int[]preSum=newint[len+1];
preSum[0]=0;
for(inti=0;i1]=preSum[i]+nums[i];
}
intcount=0;
for(inti=0;ifor(intj=i;jif(preSum[j+1]-preSum[i]==k){
count++;
}
}
}
returncount;
}
}
在計算過程中,有兩個 for 循環發生了嵌套,時間復雜度來到了 O(n^2) 級別。
需要優化。
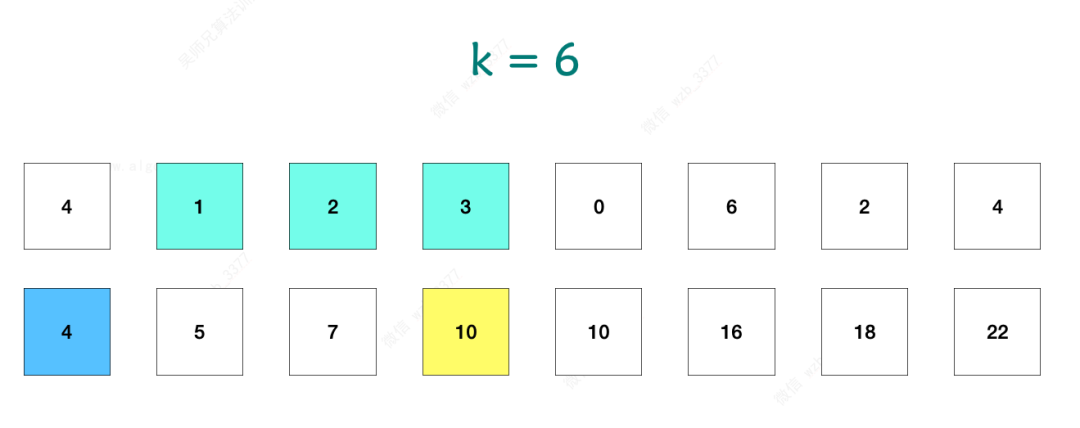
事實上,我們不需要去計算出具體是哪兩項的前綴和之差等于k,只需要知道等于 k 的前綴和之差出現的次數 count,所以我們可以在遍歷數組過程中,先去計算以 nums[i] 結尾的前綴和 pre,然后再去判斷之前有沒有存儲 pre - k 這種前綴和,如果有,那么 pre - k 到 pre 這中間的元素和就是 k 了。
具體操作如下:
1、利用哈希表,以前綴和為鍵,出現次數為對應的值,記錄 pre[i] 出現的次數。
2、開始從頭到尾遍歷 nums 數組,在遍歷過程中,會執行兩個操作。
3、存儲索引為 i 的這個元素時,前綴和的值是多少,并且把這個值出現的頻次存儲到 mp 中。
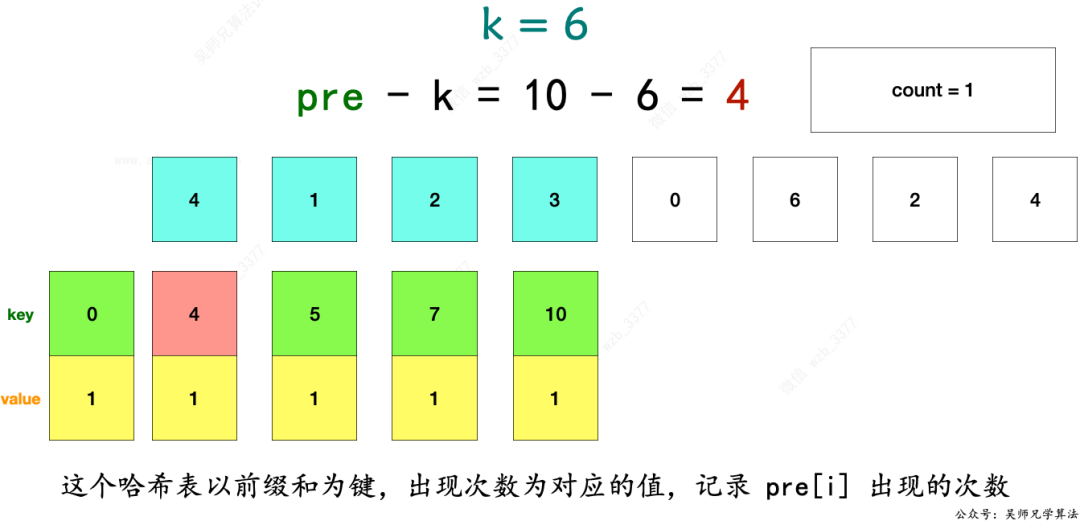
4、判斷之前有沒有存儲 pre - k 這種前綴和,如果有,說明 pre - k 到 pre 直接的那些元素值之和就是 k。
5、返回結果。
三、參考代碼
1、Java 代碼
//登錄AlgoMooc官網獲取更多算法圖解
//https://www.algomooc.com
//作者:程序員吳師兄
//代碼有看不懂的地方一定要私聊咨詢吳師兄呀
//和為 K 的子數組(LeetCode 560):https://leetcode.cn/problems/subarray-sum-equals-k/
classSolution{
publicintsubarraySum(int[]nums,intk){
//統計和為K的子數組的數量
intcount=0;
//記錄遍歷到索引為i的這個元素時,前綴和的值是多少
intpre=0;
//利用哈希表,以前綴和為鍵,出現次數為對應的值,記錄pre[i]出現的次數
HashMapmp=newHashMap<>();
//一開始,需要設置前綴和為0時,出現的次數為1次
//這一行的作用就是為了應對nums[0]+nums[1]+...+nums[i]==k這種情況
//如數組[1,2,3,6]
//這個數組的累加和數組為[1,3,【6】,12]
//如果k=6,假如mp中沒有預先存儲(0,1)
//那么來到累加和為6的位置時,這時mp中存儲的就只有兩個數據(1,1),(3,1)
//想去判斷mp.containsKey(pre-k),這時pre-k=6-6=0
//但map中沒有(0,1),
//因為這個時候忽略了從下標0累加到下標i等于k的情況
//僅僅是統計了從下標大于0到某個位置等于k的所有答案
mp.put(0,1);
//開始從頭到尾遍歷nums數組,在遍歷過程中,會執行兩個操作
//1、存儲索引為i的這個元素時,前綴和的值是多少,并且把這個值出現的頻次存儲到mp中
//2、判斷之前有沒有存儲pre-k這種前綴和,如果有,說明pre-k到pre直接的那些元素值之和就是k
for(inti=0;i//存儲索引為i的這個元素時,前綴和的值是多少
pre+=nums[i];
//判斷之前有沒有存儲pre-k這種前綴和
if(mp.containsKey(pre-k)){
//如果有,說明pre-k到pre直接的那些元素值之和就是k
//找到了一組,累加到count上
count+=mp.get(pre-k);
}
//這個值出現的頻次存儲到mp中
// getOrDefault:當 Map 集合中有這個 key 時,就使用這個 key 對應的 value 值
//如果沒有就使用默認值defaultValue
mp.put(pre,mp.getOrDefault(pre,0)+1);
}
//返回結果
returncount;
}
}
2、C++ 代碼
classSolution{
public:
intsubarraySum(vector<int>&nums,intk){
//統計和為K的子數組的數量
intcount=0;
//記錄遍歷到索引為i的這個元素時,前綴和的值是多少
intpre=0;
//利用哈希表,以前綴和為鍵,出現次數為對應的值,記錄pre[i]出現的次數
unordered_map<int,int>mp;
//一開始,需要設置前綴和為0時,出現的次數為1次
//這一行的作用就是為了應對nums[0]+nums[1]+...+nums[i]==k這種情況
//如數組[1,2,3,6]
//這個數組的累加和數組為[1,3,【6】,12]
//如果k=6,假如mp中沒有預先存儲(0,1)
//那么來到累加和為6的位置時,這時mp中存儲的就只有兩個數據(1,1),(3,1)
//想去判斷mp.containsKey(pre-k),這時pre-k=6-6=0
//但map中沒有(0,1),
//因為這個時候忽略了從下標0累加到下標i等于k的情況
//僅僅是統計了從下標大于0到某個位置等于k的所有答案
mp[0]=1;
//開始從頭到尾遍歷nums數組,在遍歷過程中,會執行兩個操作
//1、存儲索引為i的這個元素時,前綴和的值是多少,并且把這個值出現的頻次存儲到mp中
//2、判斷之前有沒有存儲pre-k這種前綴和,如果有,說明pre-k到pre直接的那些元素值之和就是k
for(inti=0;i//存儲索引為i的這個元素時,前綴和的值是多少
pre+=nums[i];
//判斷之前有沒有存儲pre-k這種前綴和
if(mp.find(pre-k)!=mp.end()){
//如果有,說明pre-k到pre直接的那些元素值之和就是k
//找到了一組,累加到count上
count+=mp[pre-k];
}
//這個值出現的頻次存儲到mp中
mp[pre]++;
}
//返回結果
returncount;
}
};
3、Python 代碼
classSolution:
defsubarraySum(self,nums:List[int],k:int)->int:
#統計和為K的子數組的數量
count=0
#記錄遍歷到索引為i的這個元素時,前綴和的值是多少
pre=0
#利用哈希表,以前綴和為鍵,出現次數為對應的值,記錄pre[i]出現的次數
mp=collections.defaultdict(int)
#一開始,需要設置前綴和為0時,出現的次數為1次
#這一行的作用就是為了應對nums[0]+nums[1]+...+nums[i]==k這種情況
#如數組[1,2,3,6]
#這個數組的累加和數組為[1,3,【6】,12]
#如果k=6,假如mp中沒有預先存儲(0,1)
#那么來到累加和為6的位置時,這時mp中存儲的就只有兩個數據(1,1),(3,1)
#想去判斷mp.containsKey(pre-k),這時pre-k=6-6=0
#但map中沒有(0,1),
#因為這個時候忽略了從下標0累加到下標i等于k的情況
#僅僅是統計了從下標大于0到某個位置等于k的所有答案
mp[0]=1
#開始從頭到尾遍歷nums數組,在遍歷過程中,會執行兩個操作
#1、存儲索引為i的這個元素時,前綴和的值是多少,并且把這個值出現的頻次存儲到mp中
#2、判斷之前有沒有存儲pre-k這種前綴和,如果有,說明pre-k到pre直接的那些元素值之和就是k
foriinrange(len(nums)):
#存儲索引為i的這個元素時,前綴和的值是多少
pre+=nums[i]
#判斷之前有沒有存儲pre-k這種前綴和
#如果有,說明pre-k到pre直接的那些元素值之和就是k
#找到了一組,累加到count上
#利用defaultdict的特性,當presum-k不存在時,返回的是0
count+=mp[pre-k]
#這個值出現的頻次存儲到mp中
# getOrDefault:當 Map 集合中有這個 key 時,就使用這個 key 對應的 value 值
#如果沒有就使用默認值defaultValue
mp[pre]+=1
#返回結果
returncount
四、復雜度分析
時間復雜度:O(n),其中 n 為數組的長度。我們遍歷數組的時間復雜度為 O(n),中間利用哈希表查詢刪除的復雜度均為 O(1),因此總時間復雜度為 O(n)。
空間復雜度:O(n),其中 n 為數組的長度。哈希表在最壞情況下可能有 n 個不同的鍵值,因此需要 O(n) 的空間復雜度。
審核編輯 :李倩
-
數組
+關注
關注
1文章
419瀏覽量
26379 -
leetcode
+關注
關注
0文章
20瀏覽量
2429
原文標題:LeetCode 560:和為 K 的子數組
文章出處:【微信號:TheAlgorithm,微信公眾號:算法與數據結構】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
MultiGABSE-AU物理層PMA子層及PMD子層的相關機制
數組的下標為什么可以是負數
FMC子卡設計方案:202-基于TI DSP TMS320C6678、Xilinx K7 FPGA XC7K325T的高速數據處理核心板
數組名之間可以直接賦值嗎
指針數組和二維數組有沒有區別
Q1和非Q1器件的TPS54340/360/540/560和TPS54340B/360B/540B/560B之間的差異

labview字符串數組轉化為數值數組
使用stm32l451片子,對ad7606進行3通道100k采樣值跳動問題?
面試常考+1:函數指針與指針函數、數組指針與指針數組






 工商網監
工商網監
評論