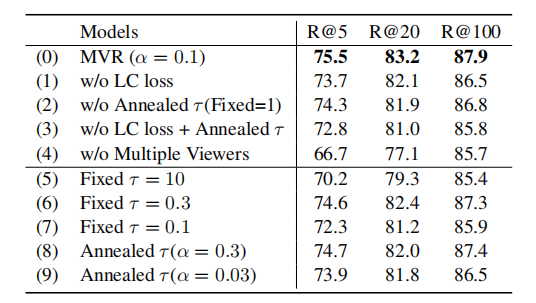
") 對(duì)比學(xué)習(xí)在開放域段落檢索和主題挖掘中的應(yīng)用
對(duì)比學(xué)習(xí)在開放域段落檢索和主題挖掘中的應(yīng)用

引言
對(duì)比學(xué)習(xí)是一種無(wú)監(jiān)督學(xué)習(xí)方法。它的改進(jìn)方向主要包括兩個(gè)部分:1.改進(jìn)正負(fù)樣本的抽樣策略 2.改進(jìn)對(duì)比學(xué)習(xí)框架 本篇主要介紹了3篇源自ACL2022的有關(guān)對(duì)比學(xué)習(xí)的文章,前2篇文章涉及開放域段落檢索,最后一篇文章涉及主題挖掘。
文章概覽
1. Multi-View Document Representation Learning for Open-domain Dense Retrieval
開放域密集檢索的多視圖文檔表示學(xué)習(xí) 論文地址:https://arxiv.org/pdf/2203.08372.pdf 密集檢索通常使用bi-encoder生成查詢和文檔的單一向量表示。然而,一個(gè)文檔通常可以從不同的角度回答多個(gè)查詢。因此,文檔的單個(gè)向量表示很難與多個(gè)查詢相匹配,并面臨著語(yǔ)義不匹配的問(wèn)題。文章提出了一種多視圖文檔表示學(xué)習(xí)框架,通過(guò)viewer生成多個(gè)嵌入。
2. Sentence-aware Contrastive Learning for Open-Domain Passage Retrieval
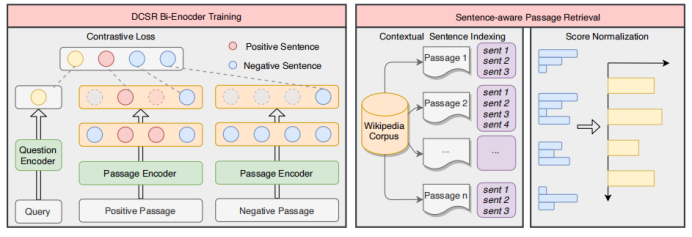
開放域段落檢索中的句子感知對(duì)比學(xué)習(xí) 論文地址:https://arxiv.org/pdf/2110.07524v3.pdf 一篇文章可能能夠回答多個(gè)問(wèn)題,這在對(duì)比學(xué)習(xí)中會(huì)導(dǎo)致嚴(yán)重的問(wèn)題,文中將其稱之為Contrastive Conflicts。基于此,文章提出了將段落表示分解為句子級(jí)的段落表示的方法,將其稱之為Dense Contextual Sentence Representation (DCSR)。
3. UCTopic: Unsupervised Contrastive Learning for Phrase Representations and Topic Mining
基于短語(yǔ)表示和主題挖掘的無(wú)監(jiān)督對(duì)比學(xué)習(xí) 論文地址:https://arxiv.org/pdf/2202.13469v1.pdf 高質(zhì)量的短語(yǔ)表示對(duì)于在文檔中尋找主題和相關(guān)術(shù)語(yǔ)至關(guān)重要。現(xiàn)有的短語(yǔ)表示學(xué)習(xí)方法要么簡(jiǎn)單地以無(wú)上下文的方式組合單詞,要么依賴于廣泛的注釋來(lái)感知上下文。文中提出了UCTopic(an Unsupervised Contrastive learning framework for phrase representations and TOPIC mining),用于上下文感知的短語(yǔ)表示和主題挖掘。
論文細(xì)節(jié)
1

1-1
動(dòng)機(jī)
密集檢索在大規(guī)模文檔集合的第一階段檢索方面取得了很大的進(jìn)展,這建立在bi-encoder生成查詢和文檔的單一向量表示的基礎(chǔ)上。然而,一個(gè)文檔通常可以從不同的角度回答多個(gè)查詢。因此,文檔的單個(gè)向量表示很難與多個(gè)查詢相匹配,并面臨著語(yǔ)義不匹配的問(wèn)題。文章提出了一種多視圖文檔表示學(xué)習(xí)框架,旨在生成多視圖嵌入來(lái)表示文檔,并強(qiáng)制它們與不同的查詢對(duì)齊。為了防止多視圖嵌入變成同一個(gè)嵌入,文章進(jìn)一步提出了一個(gè)具有退火溫度的全局-局部損失,以鼓勵(lì)多個(gè)viewer更好地與不同潛在查詢對(duì)齊。

1-2
模型
開放域段落檢索是給定一個(gè)由數(shù)百萬(wàn)個(gè)段落組成的超大文本語(yǔ)料庫(kù),其目的是檢索一個(gè)最相關(guān)的段落集合,作為一個(gè)給定問(wèn)題的證據(jù)。密集檢索已成為開放域段落檢索的重要有效方法。典型的密集檢索器通常采用雙編碼器結(jié)構(gòu),雙編碼器受制于單向量表示,面臨表示能力的上界。在上圖中,我們還發(fā)現(xiàn)單個(gè)向量表示不能很好地匹配多視圖查詢。該文檔對(duì)應(yīng)于反映不同觀點(diǎn)的四個(gè)不同的問(wèn)題,每個(gè)問(wèn)題都匹配不同的句子和答案。為了解決這個(gè)問(wèn)題,文章提出了Multi-View document Representations learning framework, MVR。
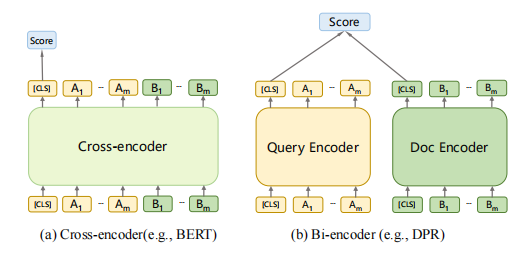
1-3 基于cross-encoder的模型需要計(jì)算昂貴的cross-attention,所以cross-encoder不用于第一階段的大規(guī)模檢索,而通常被用于第二階段的排序中。在第一階段檢索中,bi-encoder是最常被采用的架構(gòu),因?yàn)樗梢允褂肁NN加速。
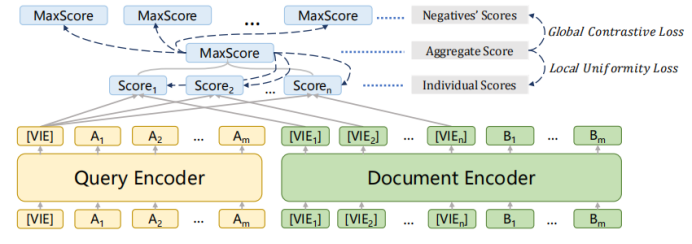
1-4 模型采用上述的bi-encoder結(jié)構(gòu),這種結(jié)構(gòu)能夠預(yù)先計(jì)算好query和document的向量,提升檢索速度。Encoder采用bert。一些工作發(fā)現(xiàn)[CLS]能夠匯集整個(gè)句子/文檔的含義。為了獲得更加精細(xì)的語(yǔ)義表示,使用多個(gè)[VIE]來(lái)替代[CLS],將[VIE]添加在文檔的開頭,為了避免多個(gè)[VIE]對(duì)原始輸入句子位置編碼的影響,將的位置id設(shè)置為0。由于查詢比文檔短得多,并且通常表示一個(gè)具體的含義,因此只為查詢生成一個(gè)嵌入。查詢和文檔之間的相似度分?jǐn)?shù)如下式計(jì)算,其中sim代表兩個(gè)向量的內(nèi)積。 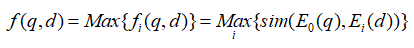 為了鼓勵(lì)多個(gè)viewer更好地適應(yīng)不同的潛在查詢,文章提出了一個(gè)配備退火溫度的全局-局部損失。損失函數(shù):
為了鼓勵(lì)多個(gè)viewer更好地適應(yīng)不同的潛在查詢,文章提出了一個(gè)配備退火溫度的全局-局部損失。損失函數(shù): 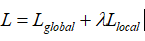 其中:
其中:
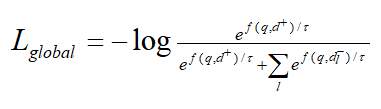
記文檔正樣本為d+,負(fù)樣本為。全局對(duì)比損失繼承自傳統(tǒng)的bi-encoder結(jié)構(gòu)。
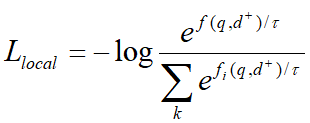
強(qiáng)制與query更加緊密的對(duì)齊,并與其他viewer區(qū)別開來(lái)。為了進(jìn)一步鼓勵(lì)更多不同的viewer被激活,文章采用了下式中的退火溫度。 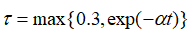 剛開始時(shí),較大的能使得每個(gè)viewer被公平的選擇,并從訓(xùn)練中返回梯度,隨著訓(xùn)練的進(jìn)行,?將降低,訓(xùn)練更加穩(wěn)定。在推理中,構(gòu)建所有文檔嵌入的索引,然后利用近似最近鄰ANN檢索。 ?
剛開始時(shí),較大的能使得每個(gè)viewer被公平的選擇,并從訓(xùn)練中返回梯度,隨著訓(xùn)練的進(jìn)行,?將降低,訓(xùn)練更加穩(wěn)定。在推理中,構(gòu)建所有文檔嵌入的索引,然后利用近似最近鄰ANN檢索。 ?
實(shí)驗(yàn)
數(shù)據(jù)集
實(shí)驗(yàn)采用的數(shù)據(jù)集包括Natural Questions ,TriviaQA,SQuAD Open。數(shù)據(jù)集 Natural Questions:是一個(gè)流行的開放域檢索數(shù)據(jù)集,其中的問(wèn)題是真實(shí)的谷歌搜索查詢,答案是從維基百科中手動(dòng)標(biāo)注的。TriviaQA:包含了一系列瑣碎的問(wèn)題,其答案最初是從網(wǎng)上提取出來(lái)的。SQuADOpen:包含了來(lái)自閱讀理解數(shù)據(jù)集的問(wèn)題和答案,它已被廣泛應(yīng)用于開放域檢索研究。
實(shí)驗(yàn)結(jié)果
計(jì)算不同文檔對(duì)應(yīng)的查閱數(shù),在3個(gè)數(shù)據(jù)集上得到的平均值為2.7,1.5,1.2,這表明多視圖問(wèn)題是常見(jiàn)的。
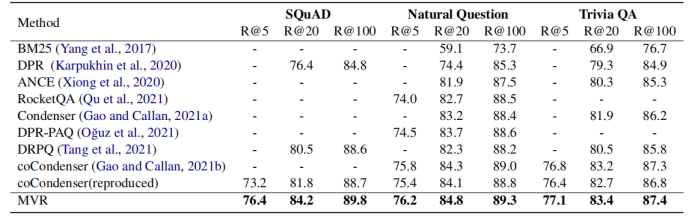
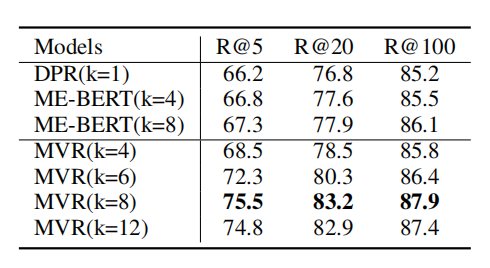
1-5 根據(jù)上表所示,MVR得到了最好的結(jié)果。MVR在SQuAD數(shù)據(jù)集上取得了最大的提升,這是因?yàn)樵摂?shù)據(jù)集單個(gè)文檔對(duì)應(yīng)更多的查詢。這說(shuō)明MVR比其他模型更能解決多視圖問(wèn)題。
1-6
1-7
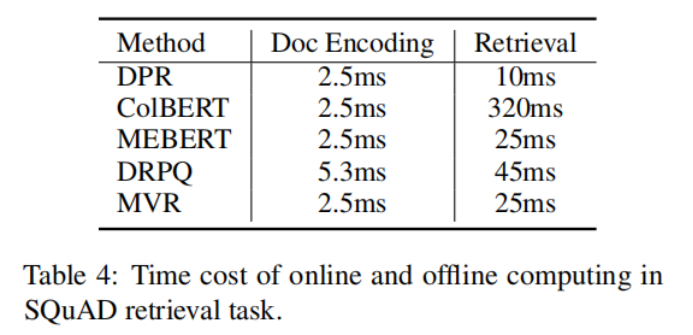
?1-8 上表說(shuō)明了,MVR與其他方法相比,需要的編碼時(shí)間和檢索時(shí)間較小。
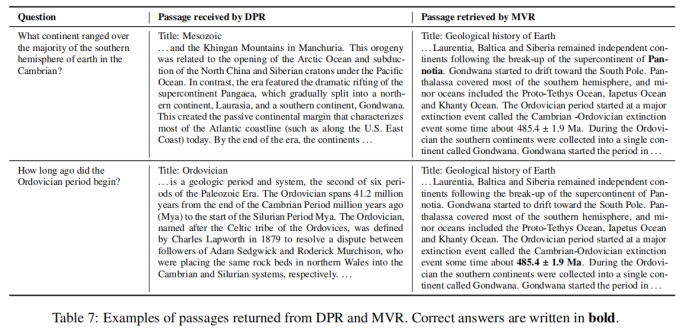
1-9 上表對(duì)DPR和MVR的檢索結(jié)果進(jìn)行了比較,結(jié)果表明MVR能夠捕獲更加細(xì)粒度的語(yǔ)義信息,返回正確的答案。
2

2-1
動(dòng)機(jī)
本文的動(dòng)機(jī)與上文基本相同。一個(gè)段落可能能夠回答多個(gè)問(wèn)題,這在對(duì)比學(xué)習(xí)框架中會(huì)導(dǎo)致嚴(yán)重的問(wèn)題,文中將其稱之為Contrastive Conflicts。這主要包括兩個(gè)方面(1)相似性的轉(zhuǎn)移,由于一個(gè)段落可能是多個(gè)問(wèn)題的答案,當(dāng)最大化對(duì)應(yīng)段落和問(wèn)題的相似性時(shí),會(huì)同時(shí)讓問(wèn)題之間更為相似,但是這些問(wèn)題在語(yǔ)義上不同。(2)在大批量上的多重標(biāo)簽。在大批量處理時(shí),可能出現(xiàn)使得同一個(gè)段落為正的多個(gè)問(wèn)題,在當(dāng)前采用的技術(shù)中,該段落將被同時(shí)作為這些問(wèn)題的正樣本和負(fù)樣本,這在邏輯上是不合理的。由于一對(duì)多問(wèn)題是Contrastive Conflicts的直接原因,文章提出了將密集的段落表示分解為句子級(jí)的段落表示的方法,將其稱之為Dense Contextual Sentence Representation (DCSR)。
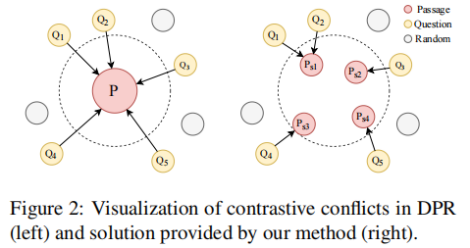
2-2
模型
Encoder采用bert結(jié)構(gòu)。
由于上下文信息在段落檢索中也很重要,因此簡(jiǎn)單地將段落分解成句子并獨(dú)立編碼是不可行的。在輸入文章的句子之間插入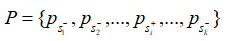 不包含答案的段落,將其表示為:
不包含答案的段落,將其表示為: 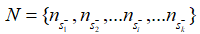 其中的+-代表句子中是否含有答案。文章使用BM25來(lái)檢索每個(gè)問(wèn)題的負(fù)段落。文章將包含答案的句子視為正樣本(),并從BM25得到的負(fù)段落中隨機(jī)抽取1個(gè)句子作為負(fù)樣本。此外在包含答案的段落中隨機(jī)抽取1個(gè)句子作為另一個(gè)負(fù)樣本。 檢索: 對(duì)于檢索,使用FAISS來(lái)計(jì)算問(wèn)題和所有段落句子之間的分?jǐn)?shù)。由于一個(gè)段落在索引中含有多個(gè)鍵,則檢索返回100*k(k是每篇文章的平均句子數(shù)量)個(gè)句子。之后,針對(duì)這些句子的分?jǐn)?shù),對(duì)它們執(zhí)行softmax,從而將分?jǐn)?shù)轉(zhuǎn)化為概率。如果一篇passage中含有多個(gè)句子,,這些句子對(duì)應(yīng)的概率為,則該篇passage為query答案的概率為:
其中的+-代表句子中是否含有答案。文章使用BM25來(lái)檢索每個(gè)問(wèn)題的負(fù)段落。文章將包含答案的句子視為正樣本(),并從BM25得到的負(fù)段落中隨機(jī)抽取1個(gè)句子作為負(fù)樣本。此外在包含答案的段落中隨機(jī)抽取1個(gè)句子作為另一個(gè)負(fù)樣本。 檢索: 對(duì)于檢索,使用FAISS來(lái)計(jì)算問(wèn)題和所有段落句子之間的分?jǐn)?shù)。由于一個(gè)段落在索引中含有多個(gè)鍵,則檢索返回100*k(k是每篇文章的平均句子數(shù)量)個(gè)句子。之后,針對(duì)這些句子的分?jǐn)?shù),對(duì)它們執(zhí)行softmax,從而將分?jǐn)?shù)轉(zhuǎn)化為概率。如果一篇passage中含有多個(gè)句子,,這些句子對(duì)應(yīng)的概率為,則該篇passage為query答案的概率為:
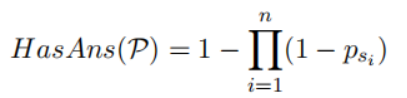
根據(jù)計(jì)算得到文章的概率,返回概率最高的top100 passage。
實(shí)驗(yàn)
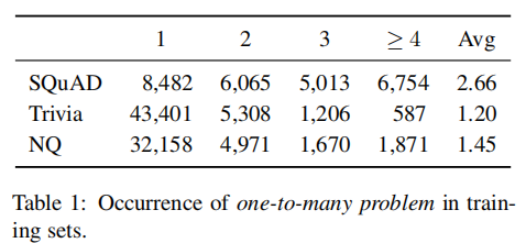
實(shí)驗(yàn)在SQuAD, TriviaQA,Natural Questions數(shù)據(jù)集上進(jìn)行。下表統(tǒng)計(jì)了數(shù)據(jù)集中段落對(duì)應(yīng)的問(wèn)題數(shù)量。在SQuAD上的平均值最大,該數(shù)據(jù)集上Contrastive Conflicts的情況最嚴(yán)重,這與DPR在SQuAD上表現(xiàn)最差的事實(shí)相符。
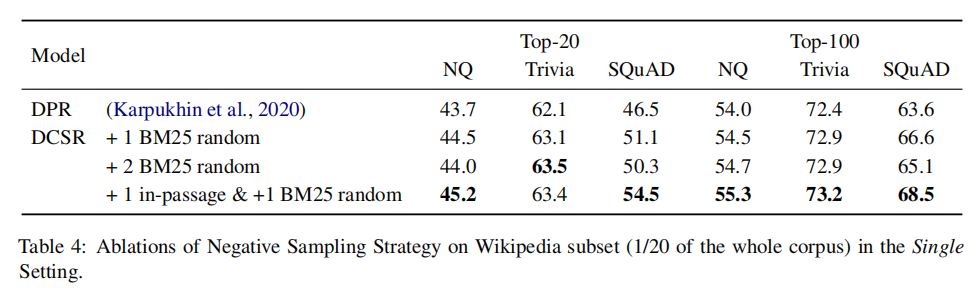
2-4 對(duì)于模型而言,DCSR采用了和DPR相同的模型結(jié)構(gòu),沒(méi)有引入額外的參數(shù)。在訓(xùn)練時(shí),采用的負(fù)樣本由隨機(jī)抽樣產(chǎn)生。因此DCSR帶來(lái)的額外時(shí)間負(fù)擔(dān)僅由抽樣引起,這可以忽略不計(jì)。
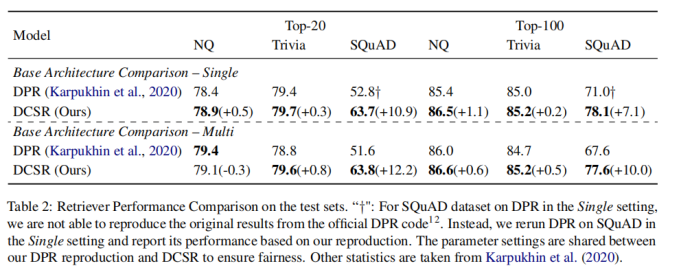
2-5 對(duì)在單數(shù)據(jù)集上的訓(xùn)練結(jié)果而言,上表顯示DCSR取得了明顯優(yōu)于DPR的結(jié)果,特別是在SQuAD這樣的受Contrastive Conflicts影響最嚴(yán)重的數(shù)據(jù)集上,對(duì)于受Contrastive Conflicts影響較小的數(shù)據(jù)集,也有較小的性能提升。對(duì)于在多數(shù)據(jù)集上的訓(xùn)練結(jié)果而言,DPR較DCSR指標(biāo)下降的幅度更大,這表明DCSR還捕獲了不同領(lǐng)域之間數(shù)據(jù)集的普遍性。
2-6
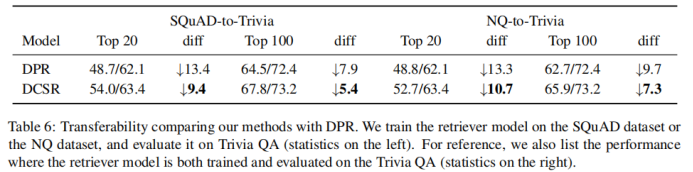
2-7 比較模型的可轉(zhuǎn)移性。將DPR和DCSR在一個(gè)數(shù)據(jù)集上訓(xùn)練好后,遷移到另外一個(gè)數(shù)據(jù)集上做評(píng)估。可以發(fā)現(xiàn),DCSR比DPR指標(biāo)下降的幅度更小,模型的可轉(zhuǎn)移性更好。
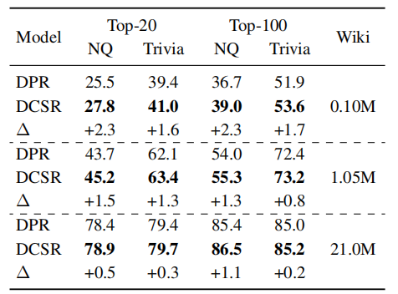
2-8 在不同大小的數(shù)據(jù)集上訓(xùn)練模型,發(fā)現(xiàn)DCSR與DPR相比,在任何大小的數(shù)據(jù)集上都表現(xiàn)得更好。與更大的數(shù)據(jù)集相比,在小的數(shù)據(jù)集上DCSR改進(jìn)更顯著。
3

3-1
動(dòng)機(jī)
高質(zhì)量的短語(yǔ)表示對(duì)于在文檔中尋找主題和相關(guān)術(shù)語(yǔ)至關(guān)重要。現(xiàn)有的短語(yǔ)表示學(xué)習(xí)方法要么簡(jiǎn)單地以無(wú)上下文的方式組合單詞,要么依賴于廣泛的注釋來(lái)感知上下文。文中提出了UCTopic(an Unsupervised Contrastive learning framework for phrase representations and TOPIC mining),用于感知上下文的短語(yǔ)表示和主題挖掘。UCTopic訓(xùn)練的關(guān)鍵是正負(fù)樣本對(duì)的構(gòu)建。文章提出了聚類輔助對(duì)比學(xué)習(xí)(CCL),它通過(guò)從聚類中選擇負(fù)樣本來(lái)減少噪聲,并進(jìn)一步改進(jìn)了關(guān)于主題的短語(yǔ)表示。
模型
編碼器結(jié)構(gòu)
UCTopic的編碼器采用LUKE (Language Understanding with Knowledge-based Embeddings)。
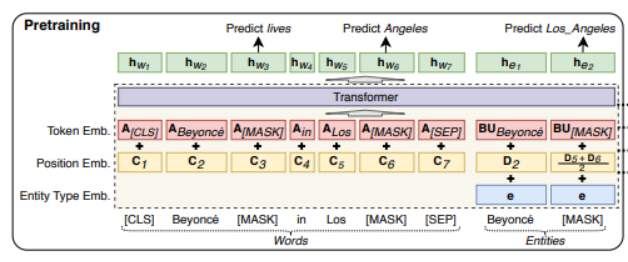
3-2 Luke采用transformer結(jié)構(gòu)。它將文檔中的單詞和實(shí)體都作為輸入token,并為每個(gè)token計(jì)算presentation。形式上,給定一個(gè)由m個(gè)詞和n個(gè)實(shí)體組成的序列,為其計(jì)算,其中, 其中。Luke的輸入由三部分組成。Input embedding=position embedding+token embedding+entity type embedding (1)token embedding (2) position embedding 出現(xiàn)在序列中第i位的單詞和實(shí)體分別用和表示。如果一個(gè)實(shí)體包含多個(gè)單詞,則將相應(yīng)位置的embedding進(jìn)行平均來(lái)計(jì)算position embedding。(3)Entity type embedding 表示token是否一個(gè)實(shí)體。
Entity-aware Self-attention
因?yàn)閘uke處理兩種類型的標(biāo)記,所以在計(jì)算注意力分?jǐn)?shù)的時(shí)候考慮token的類型。
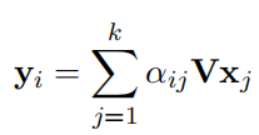
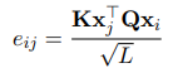
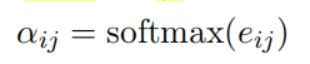
UCTopic
與預(yù)測(cè)實(shí)體的LUKE不同,UCTopic是通過(guò)短語(yǔ)上下文的對(duì)比學(xué)習(xí)訓(xùn)練的。因此,來(lái)自UCTopic的短語(yǔ)表示具有上下文感知能力,并且對(duì)不同的領(lǐng)域非常健壯。
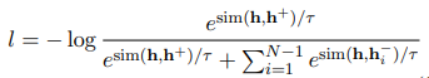
UCTopic采用對(duì)比學(xué)習(xí)的框架進(jìn)行無(wú)監(jiān)督學(xué)習(xí)。文中提出了關(guān)于短語(yǔ)語(yǔ)義的兩個(gè)假設(shè)來(lái)獲得正負(fù)樣本對(duì):1.短語(yǔ)語(yǔ)義由它的上下文決定。mask所提到的短語(yǔ)會(huì)迫使模型從上下文中學(xué)習(xí)表示,從而防止過(guò)擬合和表示崩潰 2.相同的短語(yǔ)有相同的語(yǔ)義
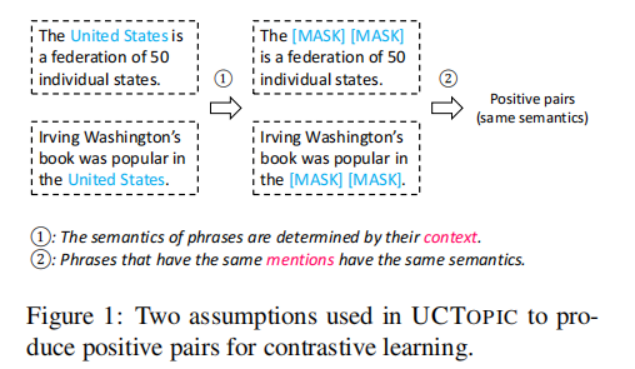
3-4
假設(shè)一個(gè)文檔內(nèi)有3個(gè)主題,假設(shè)批量大小是32,因此一個(gè)批量?jī)?nèi)會(huì)有一些樣本來(lái)自同一個(gè)主題,但是在之前的處理方法中這些樣本都被處理成負(fù)樣本,這會(huì)導(dǎo)致性能下降。為了根據(jù)主題優(yōu)化短語(yǔ)表示,減小噪聲。文章提出了聚類輔助對(duì)比學(xué)習(xí)(CCL),其基本思想是利用pre-trained representation和聚類的先驗(yàn)知識(shí)來(lái)減少負(fù)樣本中存在的噪聲。具體來(lái)說(shuō),對(duì)預(yù)訓(xùn)練的短語(yǔ)表示使用聚類算法。每一類的質(zhì)心被認(rèn)為是短語(yǔ)的主題表示。在計(jì)算了短語(yǔ)和質(zhì)心之間的余弦距離后,選擇接近質(zhì)心的t%實(shí)例,并為它們分配偽標(biāo)簽。短語(yǔ)自身的偽標(biāo)簽由包含該短語(yǔ)的實(shí)例的投票決定。假設(shè)一個(gè)主題集C,其中包含偽標(biāo)簽和短語(yǔ)。對(duì)于主題,構(gòu)造正樣本。隨機(jī)選擇來(lái)自其他主題的短語(yǔ)作為訓(xùn)練的負(fù)樣本。微調(diào)時(shí)訓(xùn)練的損失函數(shù)如下:
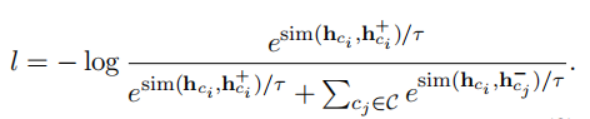
為了推斷短語(yǔ)實(shí)例x的主題y,計(jì)算短語(yǔ)表示h和主題表示之間的距離,與短語(yǔ)x最近的主題被認(rèn)為是短語(yǔ)屬于的主題。
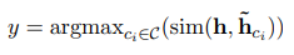
UCTopic的Pre-training與Finetuning示意圖如下:
3-5
實(shí)驗(yàn)
訓(xùn)練語(yǔ)料庫(kù)使用Wikipedia,并將其中帶有超鏈接的文本作為短語(yǔ)。經(jīng)過(guò)處理后,預(yù)訓(xùn)練數(shù)據(jù)集有1160萬(wàn)個(gè)句子和1.088億個(gè)訓(xùn)練實(shí)例。預(yù)訓(xùn)練采用兩個(gè)損失函數(shù):一個(gè)是masked language model loss,另一個(gè)是前面的對(duì)比學(xué)習(xí)損失。
實(shí)體聚類
3-6
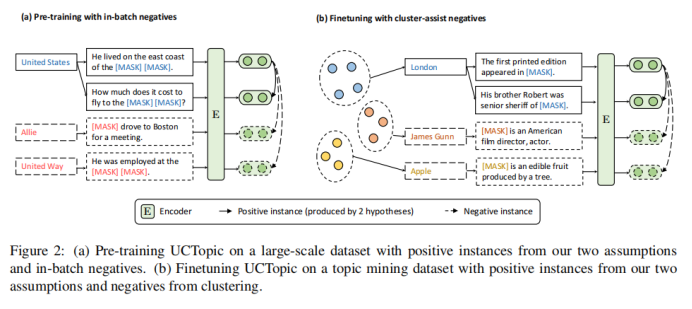
與其他的微調(diào)方法相比,CCL微調(diào)可以通過(guò)捕獲特定于數(shù)據(jù)的特征來(lái)進(jìn)一步改進(jìn)預(yù)先訓(xùn)練好的短語(yǔ)表示。
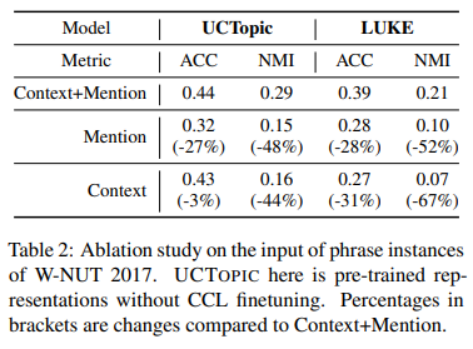
3-7
主題詞挖掘
通過(guò)計(jì)算輪廓系數(shù)來(lái)獲得每個(gè)數(shù)據(jù)集的主題數(shù)量。
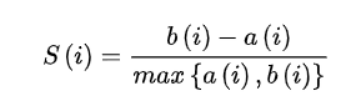
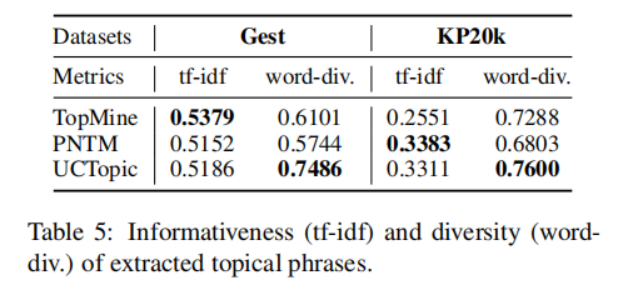
3-8 是第i個(gè)點(diǎn)到與i相同聚類中其他點(diǎn)的平均距離,是第i個(gè)點(diǎn)到下一個(gè)最近簇中的點(diǎn)的平均距離。具體來(lái)說(shuō),從數(shù)據(jù)集中隨機(jī)抽取10K個(gè)短語(yǔ),并對(duì)預(yù)訓(xùn)練過(guò)的短語(yǔ)應(yīng)用K-means聚類。計(jì)算不同主題數(shù)量的輪廓系數(shù)得分;得分最大的數(shù)字將被用作數(shù)據(jù)集中的主題數(shù)量。之后利用CCL對(duì)數(shù)據(jù)集進(jìn)行微調(diào)。主題短語(yǔ)評(píng)估:(1)主題分離:通過(guò)短語(yǔ)入侵任務(wù)來(lái)評(píng)估,具體來(lái)說(shuō),是從一系列短語(yǔ)中發(fā)掘與其他短語(yǔ)所屬主題不同的短語(yǔ)。(2)短語(yǔ)連貫性:要求注釋者評(píng)估一個(gè)主題中的前50個(gè)短語(yǔ)是否有連貫性。(3)短語(yǔ)信息量和多樣性。高信息量的短語(yǔ)不是語(yǔ)料庫(kù)中常見(jiàn)的短語(yǔ)。使用tf-idf來(lái)評(píng)估一個(gè)短語(yǔ)的信息量。短語(yǔ)的多樣性通過(guò)計(jì)算出現(xiàn)的詞的種類與出現(xiàn)詞的數(shù)量的比值來(lái)評(píng)估。UCtopic的多樣性最強(qiáng),說(shuō)明了UCtopic的短語(yǔ)表示具有上下文感知能力。
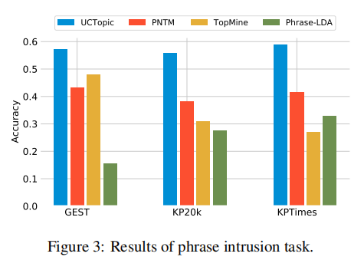
3-9
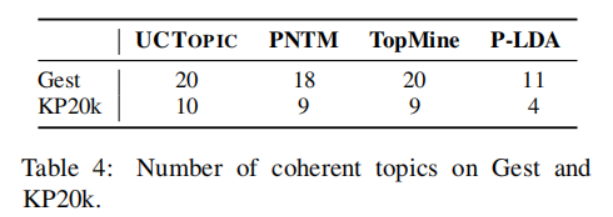
3-10
3-11
審核編輯 :李倩
-
編碼器
+關(guān)注
關(guān)注
45文章
3808瀏覽量
138100 -
模型
+關(guān)注
關(guān)注
1文章
3521瀏覽量
50441 -
檢索
+關(guān)注
關(guān)注
0文章
27瀏覽量
13295
原文標(biāo)題:ACL2022 | 對(duì)比學(xué)習(xí)在開放域段落檢索和主題挖掘中的應(yīng)用
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
FPGA在機(jī)器學(xué)習(xí)中的具體應(yīng)用
【「零基礎(chǔ)開發(fā)AI Agent」閱讀體驗(yàn)】+Agent的案例解讀
昱能科技“AI領(lǐng)航,光儲(chǔ)新程”主題開放日成功舉辦!

三一挖掘機(jī)一鍵啟動(dòng)開關(guān)易壞的原因及更換注意事項(xiàng)
Samtec受邀參與Keysight開放實(shí)驗(yàn)室日主題日活動(dòng)
混合域示波器的原理和應(yīng)用
zeta在機(jī)器學(xué)習(xí)中的應(yīng)用 zeta的優(yōu)缺點(diǎn)分析
cmp在機(jī)器學(xué)習(xí)中的作用 如何使用cmp進(jìn)行數(shù)據(jù)對(duì)比
谷歌發(fā)布“深度研究”AI工具,利用Gemini模型進(jìn)行網(wǎng)絡(luò)信息檢索
快速理解工業(yè)交換機(jī)中的沖突域與廣播域
GPU在深度學(xué)習(xí)中的應(yīng)用 GPUs在圖形設(shè)計(jì)中的作用
NPU在深度學(xué)習(xí)中的應(yīng)用
eda在機(jī)器學(xué)習(xí)中的應(yīng)用
軟件系統(tǒng)的數(shù)據(jù)檢索設(shè)計(jì)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論