") 基于全景分割的全場景圖生成任務(wù)
基于全景分割的全場景圖生成任務(wù)
【導(dǎo)讀】本文提出基于全景分割的全場景圖生成(panoptic scene graph generation,即PSG)任務(wù)。相比于傳統(tǒng)基于檢測框的場景圖生成,PSG任務(wù)要求全面地輸出圖像中的所有關(guān)系(包括物體與物體間關(guān)系,物體與背景間關(guān)系,背景與背景間關(guān)系),并用準確的分割塊來定位物體。PSG任務(wù)旨在推動計算機視覺模型對場景最全面的理解和感知,用全面的識別結(jié)果更好地支撐場景描述、視覺推理等下游任務(wù)。同時PSG數(shù)據(jù)集提供的關(guān)系標注和全景分割也為解決當前圖像生成領(lǐng)域?qū)﹃P(guān)系不敏感的問題創(chuàng)造了新的機遇。
現(xiàn)在已經(jīng)2022年了,但是當下大多數(shù)的計算機視覺任務(wù)卻仍然只關(guān)注于圖像感知。比如說,圖像分類任務(wù)只需要模型識別圖像中的物體物體類別。
雖然目標檢測,圖像分割等任務(wù)進一步要求找到物體的位置,然而,此類任務(wù)仍然不足以說明模型獲得了對場景全面深入的理解。
以下圖1為例,如果計算機視覺模型只檢測到圖片中的人、大象、柵欄、樹木等,我們通常不會認為模型已經(jīng)理解了圖片,而該模型也無法根據(jù)理解做出更高級的決策,例如發(fā)出「禁止投喂」的警告。
事實上,在智慧城市、自動駕駛、智能制造等許多現(xiàn)實世界的AI場景中,除了對場景中的目標進行定位外,我們通常還期待模型對圖像中各個主體之間的關(guān)系進行推理和預(yù)測。
例如,在自動駕駛應(yīng)用中,自動車需要分析路邊的行人是在推車還是在騎自行車。根據(jù)不同的情況,相應(yīng)的后續(xù)決策可能都會有所不同。而在智能工廠場景中,判斷操作員是否操作安全正確也需要監(jiān)控端的模型有理解主體之間關(guān)系的能力。
大多數(shù)現(xiàn)有的方法都是手動設(shè)置一些硬編碼的規(guī)則。這使得模型缺乏泛化性,難以適應(yīng)其他特定情況。
場景圖生成任務(wù)(scene graph generation,或SGG)就旨在解決如上的問題。在對目標物體進行分類和定位的要求之上,SGG任務(wù)還需要模型預(yù)測對象之間的關(guān)系(見圖 2)。

圖2:場景圖生成
傳統(tǒng)場景圖生成任務(wù)的數(shù)據(jù)集通常具有對象的邊界框標注,并標注邊界框之間的關(guān)系。但是,這種設(shè)置有幾個固有的缺陷:
(1)邊界框無法準確定位物體:如圖2所示,邊界框在標注人時不可避免地會包含人周圍的物體;
(2)背景無法標注:如圖2所示,大象身后的樹木用bounding box標注,幾乎覆蓋了整個圖像,所以涉及到背景的關(guān)系無法準確標注,這也使得場景圖無法完全覆蓋圖像,無法達到全面的場景理解。
因此,作者提出全場景圖生成(PSG)任務(wù),攜同一個精細標注的大規(guī)模PSG數(shù)據(jù)集。

圖3:全場景圖生成
如圖 3 所示,該任務(wù)利用全景分割來全面準確地定位對象和背景,從而解決場景圖生成任務(wù)的固有缺點,從而推動該領(lǐng)域朝著全面和深入的場景理解邁進。
論文信息

Paper link: https://arxiv.org/abs/2207.11247
Project Page: https://psgdataset.org/
OpenPSG Codebase: https://github.com/Jingkang50/OpenPSG
Competition Link: https://www.cvmart.net/race/10349/base
ECCV’22 SenseHuman Workshop Link: https://sense-human.github.io/
HuggingFace Demo Link: https://huggingface.co/spaces/ECCV2022/PSG
作者提出的PSG數(shù)據(jù)集包含近五萬張coco的圖片,并基于coco已有的全景分割標注,標注了分割塊之間的關(guān)系。
作者精細地定義了56種關(guān)系,包括了位置關(guān)系(over,in front of,等),常見的物體間關(guān)系(hanging from等),常見的生物動作(walking on,standing on,等),人類行為(cooking等),交通場景中的關(guān)系(driving,riding等),運動場景中的關(guān)系(kicking等),以及背景間關(guān)系(enclosing等)。
作者要求標注員能用更準確的動詞表達就絕不用更模糊的表達,并且盡可能全地標注圖中的關(guān)系。

PSG模型效果展示
任務(wù)優(yōu)勢
作者通過下圖的例子再次理解全場景圖生成(PSG)任務(wù)的優(yōu)勢:
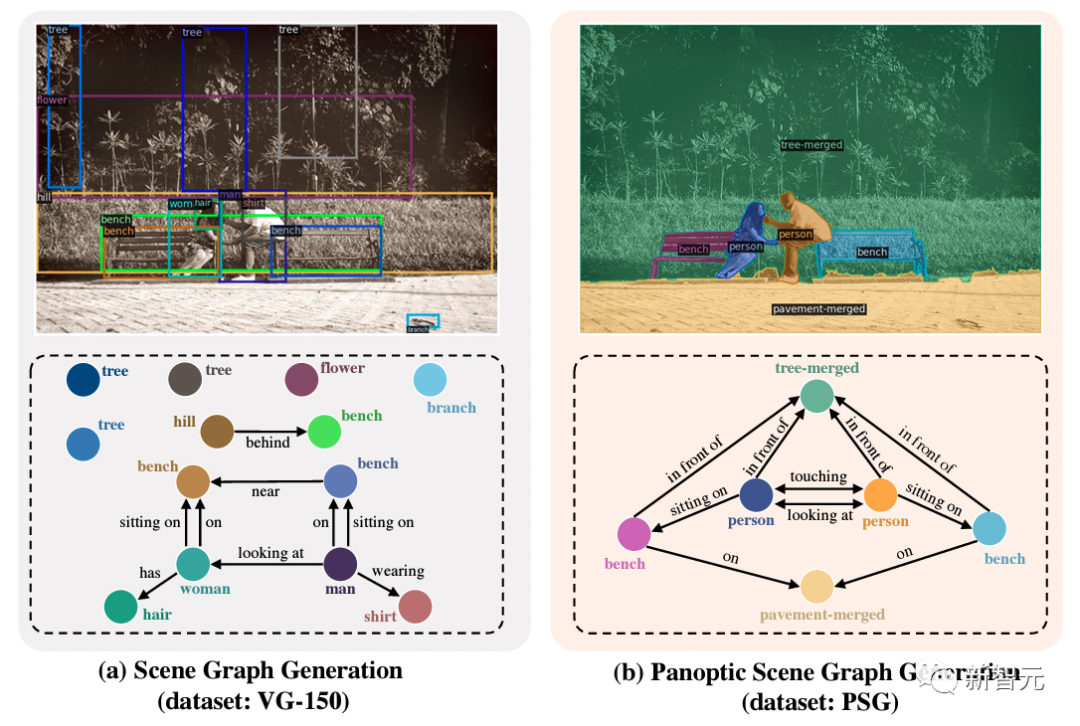
左圖來自于SGG任務(wù)的傳統(tǒng)數(shù)據(jù)集Visual Genome (VG-150)。可以看到基于檢測框的標注通常不準確,而檢測框覆蓋的像素也不能準確定位物體,尤其是椅子,樹木之類的背景。同時,基于檢測框的關(guān)系標注通常會傾向于的標注一些無聊的關(guān)系,如「人有頭」,「人穿著衣服」。
相比之下,右圖中提出的 PSG 任務(wù)提供了更全面(包括前景和背景的互動)、更清晰(合適的物體粒度)和更準確(像素級準確)的場景圖表示,以推動場景理解領(lǐng)域的發(fā)展。
兩大類PSG模型
為了支撐提出的PSG任務(wù),作者搭建了一個開源代碼平臺OpenPSG,其中實現(xiàn)了四個雙階段的方法和兩個單階段的方法,方便大家開發(fā)、使用、分析。
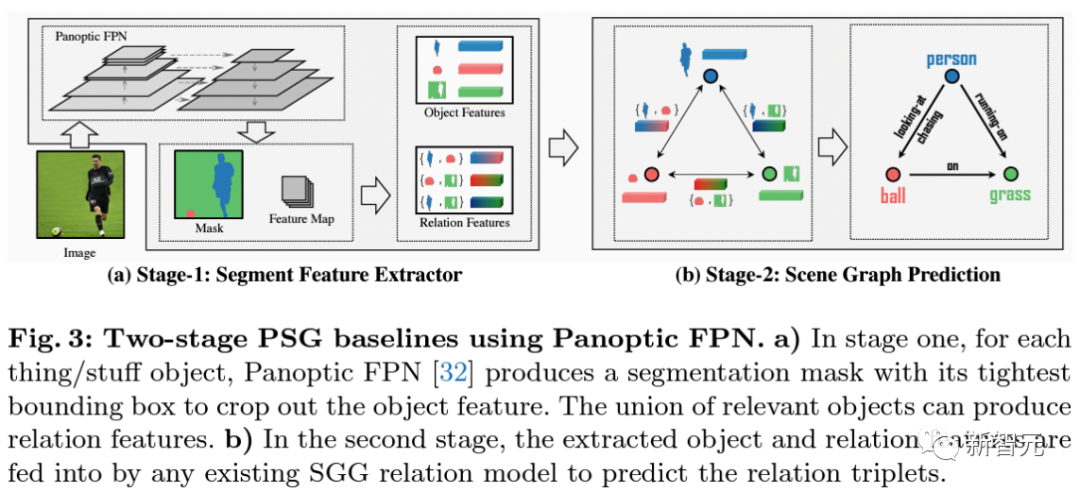
雙階段的方法利用Panoptic-FPN在第一階段中對圖像進行全景分割。
接下來作者提取全景分割得到的物體的特征以及每一對物體融合的關(guān)系特征,送至下一階段的關(guān)系預(yù)測階段。框架已集成復(fù)現(xiàn)了傳統(tǒng)場景圖生成的經(jīng)典方法IMP,VCTree,Motifs,和GPSNet。
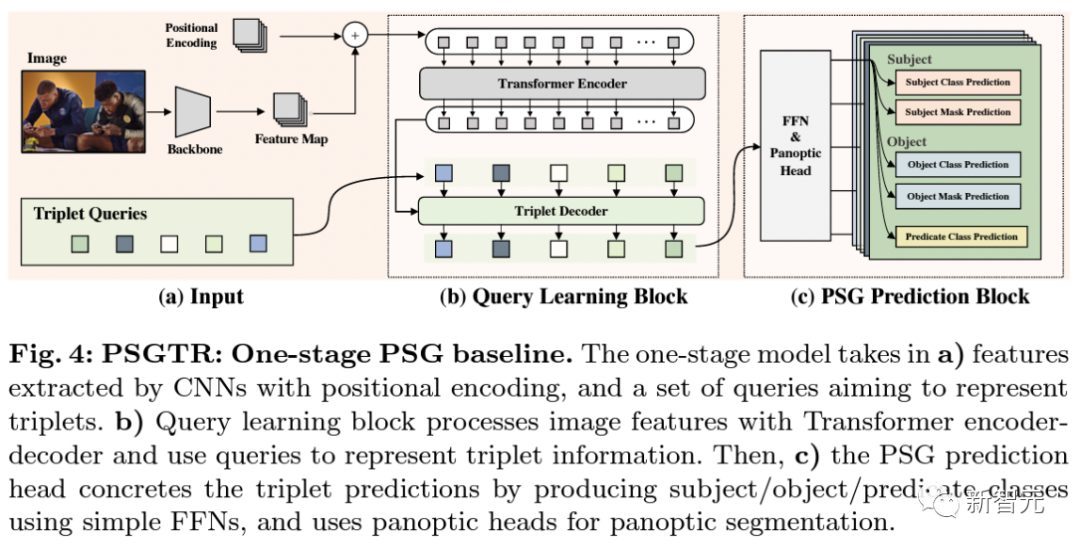
PSGFormer是基于雙decoder DETR的單階段方法。
模型首先在a)中通過卷積神經(jīng)網(wǎng)絡(luò)backbone提取圖片特征并加以位置編碼信息作為編碼器的輸入,同時初始化一組用以表示三元組的queries。
與DETR類似地, 在b)中模型將編碼器的輸出作為key和value與表示三元組的queries一同輸入解碼器進行cross-attention操作。
隨后模型在c)中將解碼完成的每個query分別輸入主謂賓三元組對應(yīng)的預(yù)測模塊,最后得到對應(yīng)的三元組預(yù)測結(jié)果。
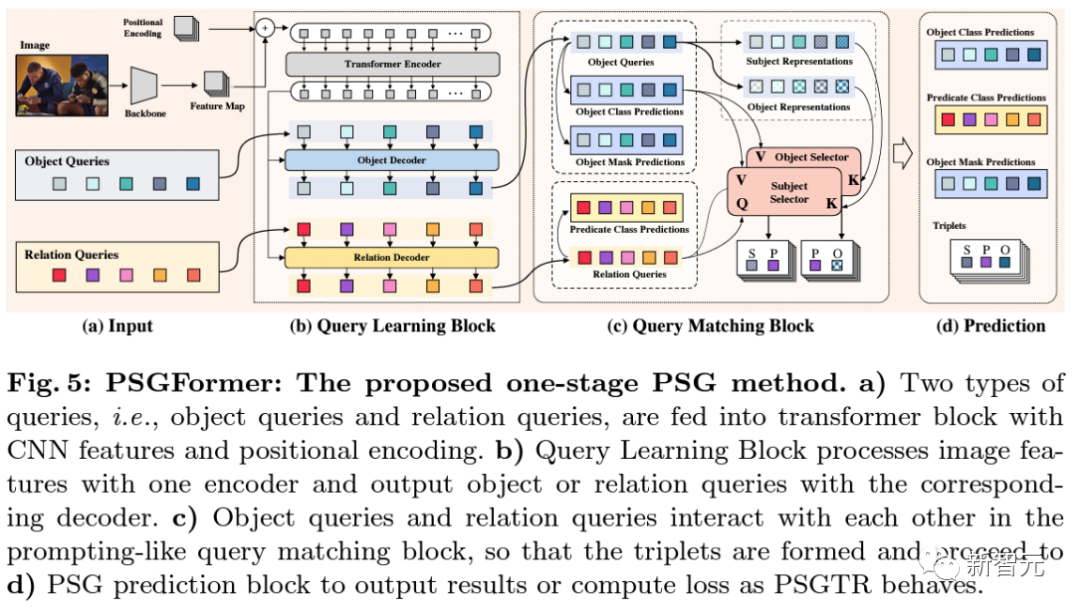
PSGFormer基于雙decode的DETR的單階段方法。
模型在a) 通過CNN提取圖片特征,加以位置編碼信息輸入編碼器,同時初始化了兩組queries分別代表物體和關(guān)系。
接著在b)步驟里,模型基于編碼器編碼的圖片信息,分別在物體解碼器和關(guān)系編碼器中通過cross-attention解碼學習物體query和關(guān)系query。
當兩類query均學習完畢后,在c)中通過映射后匹配,得到成對的三元組query。
最后在d)中通過預(yù)測頭分別完成關(guān)于物體query和關(guān)系query的預(yù)測,并根據(jù)c)中的匹配結(jié)果得到最終的三元組預(yù)測結(jié)果。
PSGTR與PSGFormer都是在DETR的基礎(chǔ)上進行擴展和改進的模型,不同的地方在于PSGTR用一組query對于三元組直接建模而PSGFormer則通過兩組query分別對物體和關(guān)系建模,兩種方法各有利弊,具體可參考論文中實驗結(jié)果。
結(jié)論分享
大部分在SGG任務(wù)上有效的方法在PSG任務(wù)上依舊有效。然而有一些利用較強的數(shù)據(jù)集統(tǒng)計先驗,或主謂賓中謂語方向先驗的方法可能沒那么奏效。這可能是由于PSG數(shù)據(jù)集相較于傳統(tǒng)VG數(shù)據(jù)集的bias沒有那么嚴重,并且對謂語動詞的定義更加清晰可學。因此,作者希望后續(xù)的方法關(guān)注視覺信息的提取和對圖片本身的理解。統(tǒng)計先驗可能在刷數(shù)據(jù)集上有效,但不本質(zhì)。
相比于雙階段模型,單階段模型目前能達到更好的效果。這可能得益于單階段模型有關(guān)于關(guān)系的監(jiān)督信號可以直接傳遞到feature map端,使得關(guān)系信號參與了更多的模型學習,有利于對關(guān)系的捕捉。但是由于本文只提出了若干基線模型,并沒有針對單階段或雙階段模型進行調(diào)優(yōu),因此目前還不能說單階段模型一定強于雙階段模型。這還希望參賽選手繼續(xù)探索。
相比于傳統(tǒng)的SGG任務(wù),PSG任務(wù)基于全景分割圖進行關(guān)系配對,要求對于每個關(guān)系中主賓物體的id 進行確認。相比于雙階段直接預(yù)測全景分割圖完成物體id 的劃分,單階段模型需要通過一系列后處理完成這一步驟。若基于現(xiàn)有單階段模型進一步改進升級,如何在單階段模型中更有效的完成物體id的確認,生成更好的全景分割圖,仍是一個值得探索的話題。
最后,歡迎大家試用HuggingFace:
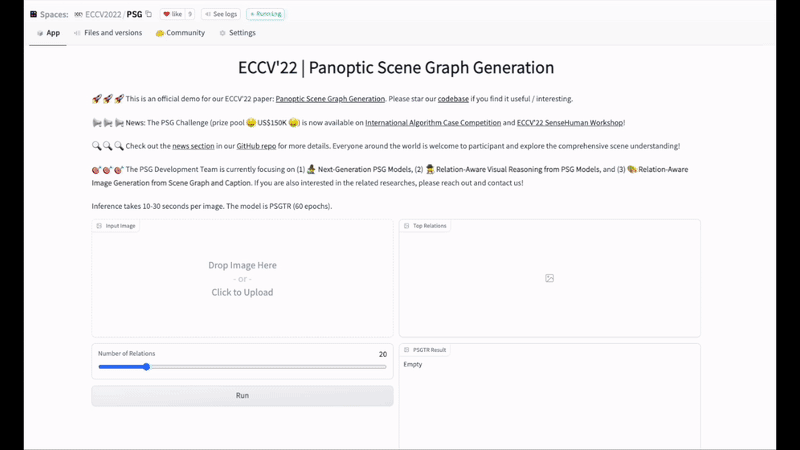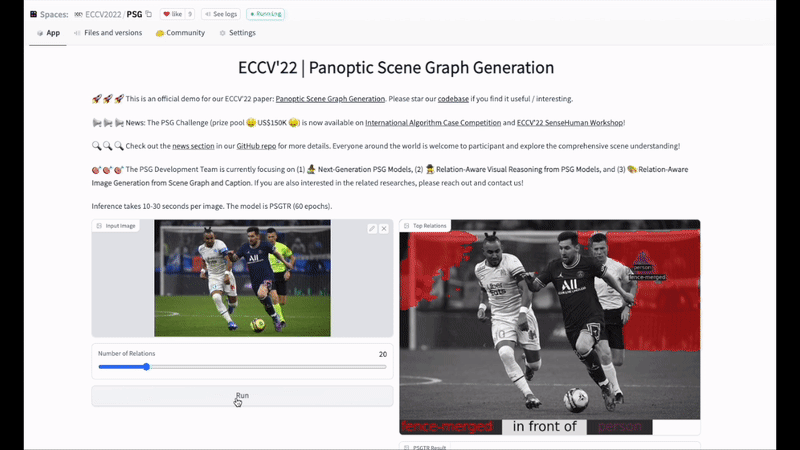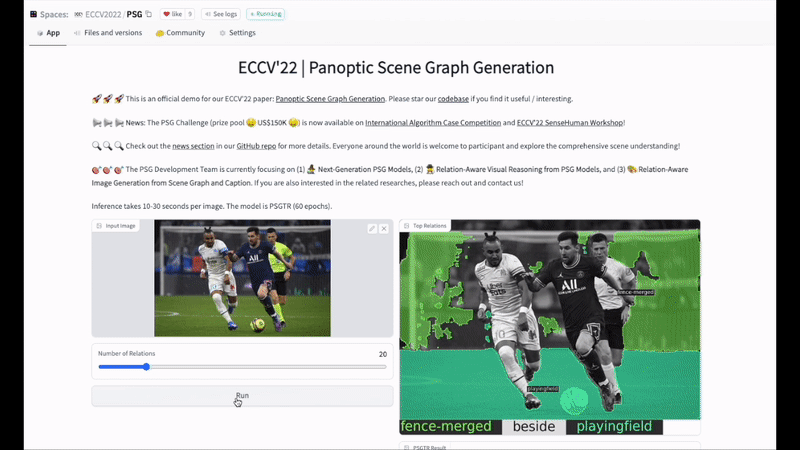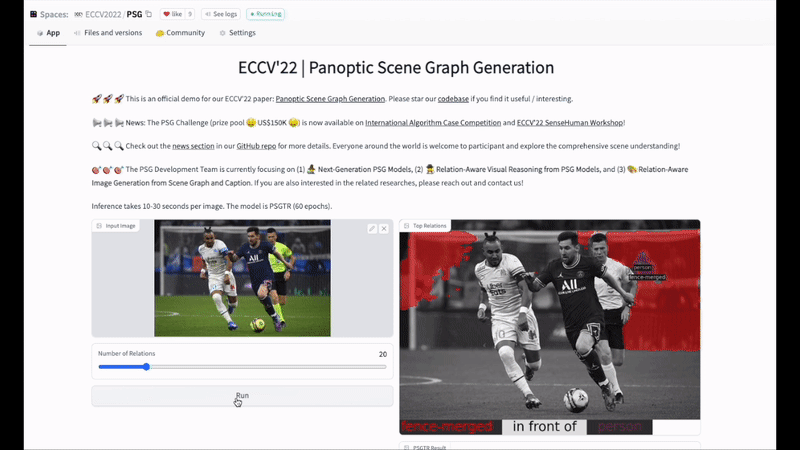
Demo:https://huggingface.co/spaces/ECCV2022/PSG
關(guān)于圖像生成的展望
最近大火的基于文字輸入的生成模型(如DALL-E2) 著實令人驚嘆,但是也有研究表明,這些生成模型可能只是把文本中的幾個實體粘合在一起,甚至都沒有理解文本中表述的空間關(guān)系。
如下圖,雖然輸入的是「杯子在勺子上」,生成的圖片仍然都是「勺子在杯子里」。

正巧,PSG數(shù)據(jù)集標注了基于mask的scene graph關(guān)系。
作者可以利用scene graph和全景分割mask作為訓練對,得到一個text2mask的模型,在基于mask生成更細致的圖片。
因此,PSG數(shù)據(jù)集有可能也為注重關(guān)系的圖像生成提供了潛在的解決方案。
審核編輯 :李倩
-
計算機視覺
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46621 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25321 -
智能制造
+關(guān)注
關(guān)注
48文章
5855瀏覽量
77556
原文標題:南洋理工提出全場景圖生成PSG任務(wù),像素級定位物體,還得預(yù)測56種關(guān)系
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
圓滿收官!科士達全場景光儲生態(tài)點燃全球追光者盛宴

芯資訊|廣州唯創(chuàng)電子語音識別芯片:全場景覆蓋與長效品質(zhì)

DuxCam G2S全景相機,提供360°全景測繪解決方案
敏捷合成器的技術(shù)原理和應(yīng)用場景
畫面分割器怎么調(diào)試
億緯鋰能全場景鋰電池方案,加速萬物互聯(lián)
惠普AI PC全場景AI解決方案重磅發(fā)布, AI一步到位,智能觸手可及

專注充電充滿想象,羅馬仕全球品牌升級打造全場景用電體驗生態(tài)

專注充電充滿想象,羅馬仕全球品牌升級打造全場景用電體驗生態(tài)

圖像語義分割的實用性是什么
圖像分割和語義分割的區(qū)別與聯(lián)系
圖像分割與目標檢測的區(qū)別是什么
機器學習中的數(shù)據(jù)分割方法
圖像分割與語義分割中的CNN模型綜述
機器人視覺技術(shù)中常見的圖像分割方法
- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論