 一種360°全景定制的Transformer框架
一種360°全景定制的Transformer框架
導讀
現有的基于CNN 的全景深度估計方法側重于消除全景失真,由于CNN中固定的接收場,無法有效地感知全景結構。本文提出了一種360°全景定制的Transformer框架,可以很容易地遷移到全景視覺其他dense prediction任務上,比如全景圖像語義分割,無需改變任何網絡結構便能取得SOTA性能。

論文鏈接:
https://arxiv.org/pdf/2203.09283.pdf
代碼鏈接:
https://github.com/zhijieshen-bjtu/PanoFormer
文案:申志杰,廖康
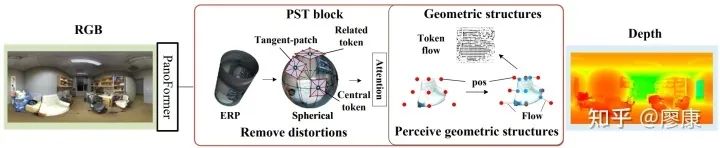
PanoFormer簡介圖
1. 研究背景及動機
單目全景深度估計(monocular omnidirectional depth estimation, MODE)是三維場景理解中的一個子領域,其任務設定為給定一張360°全景RGB圖像,通過網絡建模推理得到對應的360°深度圖,相較于立體視覺而言具有更好的便利性。
MODE使用更為常見的等距柱狀投影(ERP)全景圖作為輸入。這與正常的2D perspective圖像存在較大差異:ERP全景圖的360°視角增益是以畸變為代價,因此導致整幅圖像存在規律性的扭曲(畸變程度由圖片水平軸線向垂直邊逐漸增大)。受限于CNN有限的感受野和固定的采樣位置,這種畸變特性使得MODE具有獨立于傳統單目深度估計任務之外的挑戰性。
當然,此前的一些工作提出基于CUBE和ERP投影的雙分支融合結構來增強網絡對于大畸變區域的特征提取和建模能力,但需要注意的是,CUBE格式的全景圖在投影過程中會有25%像素的丟失,這直接導致CUBE分支深度圖的模糊。如此兩個分支的有限結果決定了其性能上限。為了解決像素損失這一問題,后續有工作提出基于旋轉CUBE設計雙分支結構,一定程度上緩和了這一矛盾。
隨著Transformer網絡框架的興起,其獨特的long-range建模能力為解決大畸變問題提供了一個新的思路。但“拿來主義”真能行得通嗎?
2. 應用挑戰
首先,我們回顧一下傳統的視覺Transformer在處理圖像時的步驟并分析一下其在ERP圖像上的應用挑戰:
劃分patch
在以ERP格式作為輸入的前提下會有兩種劃分patch的方法:(1)直接等間距劃分patch;(2)將球面全景圖投影成重疊的perspective視口自然地作為patch。首先,直接劃分patch的方法會顯著破壞大畸變區域的結構,而perspective視口可以將跨度非常大的物體投影回一個patch。這樣對比來看似乎后者更有趣且合理。
Patch->Embedding->Token
視覺Transformer中做位置嵌入是通過線性層壓縮特征維度實現的,那這種特征維度的壓縮對于深度估計這一類像素級回歸任務來說會不會造成信息的丟失,從而導致性能的下降?
位置嵌入
此前的一些工作指出,在視覺領域位置嵌入能夠貢獻的力量似乎并沒有很大,且比較雞肋,很多工作甚至直接摒棄了位置嵌入模塊,他們認為網絡中所引入的卷積結構會暗含位置信息。但考慮步驟1,如果我們采用perspective視口patch的劃分方式,其真實的空間位置已經發生了改變,因此一個合適的位置嵌入策略在MODE中是迫切需要的。那么如何設計一個合理的位置嵌入方式呢?
Self-attention
自注意力模塊通過壓縮后的特征生成q, k, v依次查詢計算全局注意力,如果我們的embedding設計成像素級,將會帶來很大的計算復雜度,如何解決?
為了解決這些問題我們提出了一種360°全景定制的Transformer框架。
3. 方法
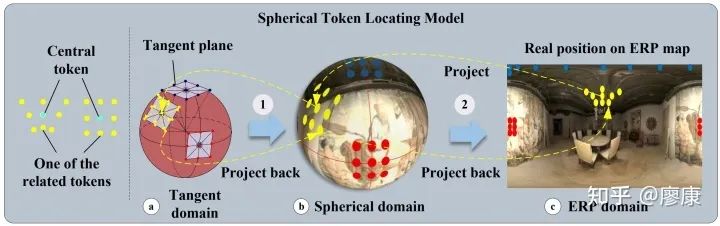
Spherical Token Locating Model (STLM)
劃分patch
如前所述,我們劃分patch可以盡可能地通過投影的方式劃分patch而不是直接在ERP圖上劃分。投影我們選擇CUBE格式的perspective視口。那么問題是,我們如何選擇CUBE patch的切點?以及如何確定patch的大小?不考慮計算復雜度,我們可以將每個像素點都作為一次切點,這樣信息會盡可能地全部保留。至于大小,我們在前面討論了CUBE投影的弊端之一是像素丟失,在這里我們還要討論一種弊端:對于CUBE投影面,理想情況下僅有CUBE的中心點(即切點)不存在畸變,除此之外,其他位置會呈現出由切點向四周逐漸增大的畸變趨勢。考慮一種極端的情況,當CUBE的大小收縮到極致,即每個CUBE面僅由中心切點及其周圍的八個點組成,CUBE面近似貼近球面,畸變影響降至最小。我們將此時的CUBE面稱為Tangent patch。
Embedding
從盡可能提高性能的角度出發,我們可以通過等價映射將每個像素點映射成一個Token。區別于傳統Transformer中將每個Patch嵌入為每個Token,我們直接將每個Tangent Patch上的采樣點當作Token。直觀的理解,我們的patch和token都是手工劃分的,patch在我們的網絡中多為一種抽象的概念,我們直接的操作對象是Token(采樣點),即每個切點及其周圍的八個點。
位置嵌入
Tangent Patch是相對于球面而言,為了定義其空間位置屬性,我們將手工劃分的patch反投影到ERP圖上。注意在球面全景圖上每個patch由切點及其周圍的八個投影點組成,而在ERP圖上這種空間對應關系發生了改變,由于畸變的存在,他們在ERP上幾乎不再相鄰。這種位置投影對應關系恰恰提供了我們Transformer里面所需要的位置嵌入。
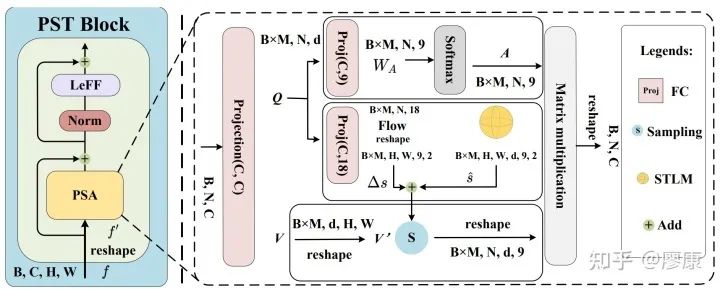
Panoramic Structure-guided Transformer (PST) block
計算注意力
首先如果我們像傳統Transformer那樣計算注意力,其計算開銷非常大,但得益于我們patch劃分方式和位置嵌入策略,我們似乎找到了其最相關的位置對應關系,即切點token及與其最相關的8個token。那么我們可以僅僅通過計算切點token(或中心token)與這8個token的注意力即可。但問題如果這樣做,我們會犯了一個非常大的錯誤,即把token的位置鎖死了,使得我們的網絡架構喪失了傳統Transformer固有的靈活性。為了解決這一問題,我們提出了token flow的概念,即通過學習一個偏移來彌補其結構上靈活性的喪失。意外之喜是,這種流式的概念可以使網絡更好地建模全景結構這一重要的深度線索。
最后,我們基于設計的PST block構建最終的PanoFormer網絡框架:
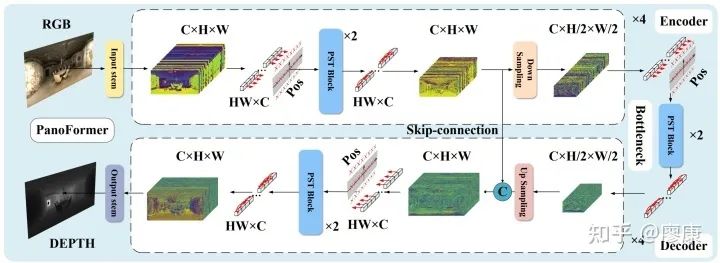
PanoFormer網絡架構圖
4. 新指標
為了突出模型對于大畸變區域的建模能力,我們通過選取6個CUBE投影面的上下兩個面來設計Pole-RMSE指標。(注意此指標的應用的一個前提條件是全景相機水平放置,目前的流行的數據集大都遵循這一假設。)
考慮到ERP全景圖的特性,左右可以實現無縫拼接,我們提出LRCE指標來反映模型的長距離建模能力。
詳細計算過程請參考論文。
5. 實驗結果
我們在四個主流的MODE數據集上對我們的模型進行了評估,結果顯示我們的模型取得了更有競爭力的結果。但由于Stanford2D3D以及Matterport3D數據集的固有缺陷導致我們沒有辦法在這兩個數據集上評測我們的新指標(P-RMSE),因此我們在這兩個數據集上只報道了MRE和MAE的指標性能,這兩個指標的計算參照SliceNet(CVPR'21)所開源的代碼執行。此外,關于數據集的一些討論詳情見gihub代碼鏈接。
值得一提的是,PanoFormer可以很容易地遷移到全景視覺其他dense prediction任務上,比如全景圖像語義分割,無需改變任何網絡結構便能取得SOTA性能。
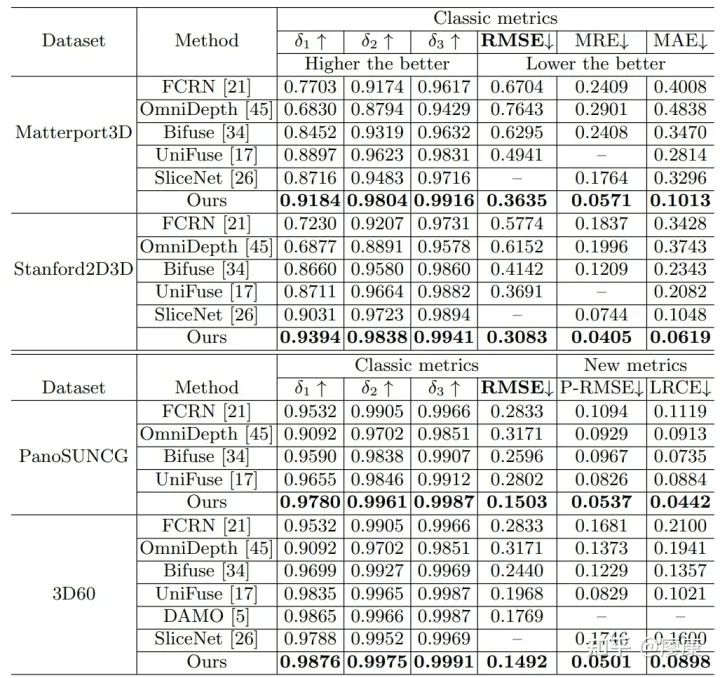
客觀指標
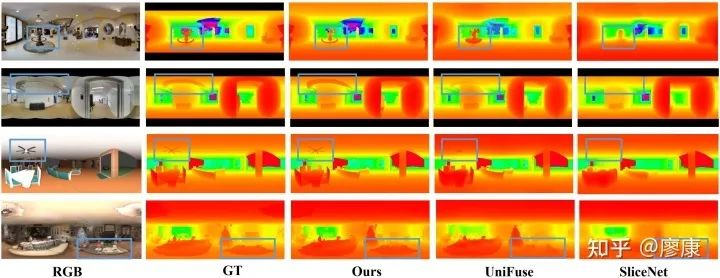
主觀對比

全景語義分割客觀指標
6. 局限性
關于更高分辨率的擴展計算復雜度可能是我們工作的一個待提升的點。這可以通過在encoder階段增加下采樣層,在decoder階段增加插值操作得到緩解。此外,如果仔細觀察可以發現attention計算部分存在比較多重復計算的情況,這可能是優化我們網絡的一個方向。
希望我們的工作可以為該領域帶來啟發。
審核編輯 :李倩
-
框架
+關注
關注
0文章
403瀏覽量
17564 -
數據集
+關注
關注
4文章
1211瀏覽量
24890 -
Transformer
+關注
關注
0文章
146瀏覽量
6080
原文標題:首個360°全景定制的單目深度估計Transformer-PanoFormer(ECCV 2022)
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
探索 RK3576 方案:卓越性能與靈活框架,誠邀開發定制合作!
一種面向飛行試驗的數據融合框架


自動駕駛中一直說的BEV+Transformer到底是個啥?

360度全景觀看顯示神器定制球形LED異形創意顯示屏面世。

全景聲解碼器

基于TDA處理器的360度全景實現YUV422輸出的方案

Transformer能代替圖神經網絡嗎
使用PyTorch搭建Transformer模型
YXC差分可編程振蕩器,頻點200MHz,LVDS輸出,應用于360°全景環視

引領安防發展,EPSON晶振助力全景攝像頭

一種高效的KV緩存壓縮框架--GEAR

介紹一種OpenAtom OpenHarmony輕量系統適配方案






 工商網監
工商網監
評論