") Transformer模型的具體應(yīng)用
Transformer模型的具體應(yīng)用

如果想在 AI 領(lǐng)域引領(lǐng)一輪新浪潮,就需要使用到 Transformer。
盡管名為 Transformer,但它們不是電視銀幕上的變形金剛,也不是電線桿上垃圾桶大小的變壓器。
在上一篇《什么是 Transformer 模型(一)》中,通過對 Transformer 模型進行的深入剖析,展開了一幅 AI 領(lǐng)域的創(chuàng)新畫卷,本篇文章將聚焦于該模型在現(xiàn)實世界各個領(lǐng)域中的具體應(yīng)用,以及這些應(yīng)用如何改變我們的生活和工作方式,展望其在未來人工智能發(fā)展中的潛在影響。
讓 Transformer 發(fā)揮作用
很快,Transformer 模型就被應(yīng)用于科學(xué)和醫(yī)療領(lǐng)域。
倫敦的 DeepMind 使用一種名為 AlphaFold2 的 Transformer 加深了對蛋白質(zhì)這一生命基礎(chǔ)要素的理解。最近《自然》期刊上的一篇文章對該 Transformer 進行了描述。這種 Transformer 能夠像處理文本字符串一樣處理氨基酸鏈,為描述蛋白質(zhì)的折疊方式打開了新的思路,這項研究可以加快藥物發(fā)現(xiàn)的速度。
阿斯利康和 NVIDIA 共同開發(fā)了一個專為藥物發(fā)現(xiàn)量身定制的 Transformer MegaMolBART。MegaMolBART 是該制藥公司 MolBART Transformer 的一個版本,使用 NVIDIA Megatron 在一個大型、無標(biāo)記的化合物數(shù)據(jù)庫上訓(xùn)練,以創(chuàng)建大規(guī)模 Transformer 模型。
閱讀分子和醫(yī)療記錄
阿斯利康分子 AI、發(fā)現(xiàn)科學(xué)和研發(fā)部門負(fù)責(zé)人 Ola Engkvist 在 2020 年宣布這項工作時表示:“正如 AI 語言模型可以學(xué)習(xí)句子中單詞之間的關(guān)系一樣,我們的目標(biāo)是使在分子結(jié)構(gòu)數(shù)據(jù)上訓(xùn)練而成的神經(jīng)網(wǎng)絡(luò)能夠?qū)W習(xí)現(xiàn)實世界分子中原子之間的關(guān)系。”
為了從大量臨床數(shù)據(jù)中提煉洞察,加快醫(yī)學(xué)研究的速度,佛羅里達大學(xué)學(xué)術(shù)健康中心與 NVIDIA 研究人員聯(lián)合創(chuàng)建了 GatorTron 這個 Transformer 模型。
Transformer 增長
在研究過程中,研究人員發(fā)現(xiàn)大型 Transformer 性能更好。
慕尼黑工業(yè)大學(xué) Rostlab 的研究人員推動著 AI 與生物學(xué)交叉領(lǐng)域的前沿研究,他們利用自然語言處理技術(shù)來了解蛋白質(zhì)。該團隊在 18 個月的時間里,從使用具有 9000 萬個參數(shù)的 RNN 升級到具有 5.67 億個參數(shù)的 Transformer 模型。
Rostlab 研究人員展示了在沒有標(biāo)記樣本的情況下訓(xùn)練的語言模型所捕捉到的蛋白質(zhì)序列信號
OpenAI 實驗室的生成式預(yù)訓(xùn)練 Transformer(GPT)證明了模型的規(guī)模越大越好。其最新版本 GPT-3 有 1750 億個參數(shù),而 GPT-2 只有 15 億個。
憑借更多的參數(shù),GPT-3 即使在沒有經(jīng)過專門訓(xùn)練的情況下,也能回答用戶的問詢。思科、IBM、Salesforce 等公司已經(jīng)在使用 GPT-3。
巨型 Transformer 的故事
NVIDIA 和微軟在 2022 年 11 月發(fā)布了擁有 5300 億個參數(shù)的 Megatron-Turing 自然語言生成模型(MT-NLG)。與它一起發(fā)布的框架 NVIDIA NeMo Megatron 旨在讓任何企業(yè)都能創(chuàng)建自己的十億或萬億參數(shù) Transformer,為自定義聊天機器人、個人助手以及其他能理解語言的 AI 應(yīng)用提供助力。
MT-NLG 首次公開亮相是作為 Toy Jensen(TJ)虛擬形象的大腦,幫助 TJ 在 NVIDIA 2021 年 11 月的 GTC 上發(fā)表了一部分主題演講。
負(fù)責(zé) NVIDIA 團隊訓(xùn)練該模型的 Mostofa Patwary 表示:“當(dāng)我們看到 TJ 回答問題時,他作為我們的首席執(zhí)行官展示我們的工作成果,那一刻真是令人振奮。”
創(chuàng)建這樣的模型并非易事。MT-NLG 使用數(shù)千億個數(shù)據(jù)元素訓(xùn)練而成,整個過程需要數(shù)千顆 GPU 運行數(shù)周時間。
Patwary 表示:“訓(xùn)練大型 Transformer 模型既昂貴又耗時,如果前一兩次沒有成功,項目就可能被取消。”
萬億參數(shù) Transformer
如今,許多 AI 工程師正在研究萬億參數(shù) Transformer 及其應(yīng)用。
Patwary 表示:“我們一直在研究這些大模型如何提供更好的應(yīng)用。我們還在研究它們會在哪些方面失敗,這樣就能創(chuàng)建出更好、更大的模型。”
為了提供這些模型所需的算力,NVIDIA 的加速器內(nèi)置了一個 Transformer 引擎并支持新的 FP8 格式,既加快了訓(xùn)練速度,又保持了準(zhǔn)確性。
黃仁勛在 GTC 2022 上表示,通過這些及其他方面的進步,“Transformer 模型的訓(xùn)練時間可以從數(shù)周縮短到數(shù)天。”
TJ 在 GTC 2022 上表示:“Megatron 能幫助我回答黃仁勛拋給我的所有難題。”
MoE 對于 Transformer 的意義更大
谷歌研究人員 2021 年介紹的 Switch Transformer 是首批萬億參數(shù)模型之一。該模型利用 AI 稀疏性、復(fù)雜的混合專家(MoE)架構(gòu)等先進技術(shù)提高了語言處理性能并使預(yù)訓(xùn)練速度加快了最多 7 倍。
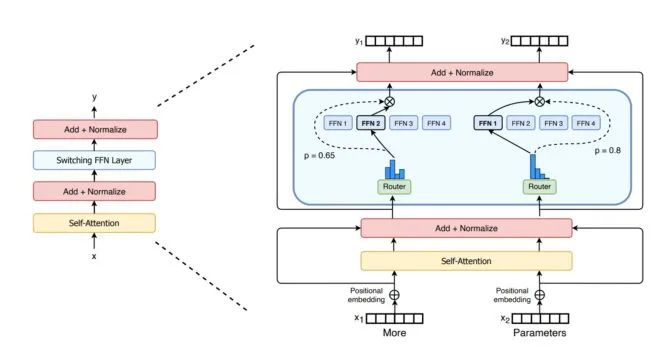
首個擁有多達一萬億個參數(shù)模型 Switch Transformer 的編碼器
微軟 Azure 則與 NVIDIA 合作,在其翻譯服務(wù)中使用了 MoE Transformer。
解決 Transformer 所面臨的挑戰(zhàn)
如今,一些研究人員的目標(biāo)是開發(fā)出性能與那些最大的模型相同、但參數(shù)更少并且更簡單的 Transformer。
Cohere 的 Gomez 以 DeepMind 的 Retro 模型為例:“我看到基于檢索的模型將大有可為并實現(xiàn)彎道超車,對此我感到非常興奮。”
基于檢索的模型通過向數(shù)據(jù)庫提交查詢來進行學(xué)習(xí)。他表示:“這很酷,因為你可以對放到知識庫中的內(nèi)容進行選擇。”
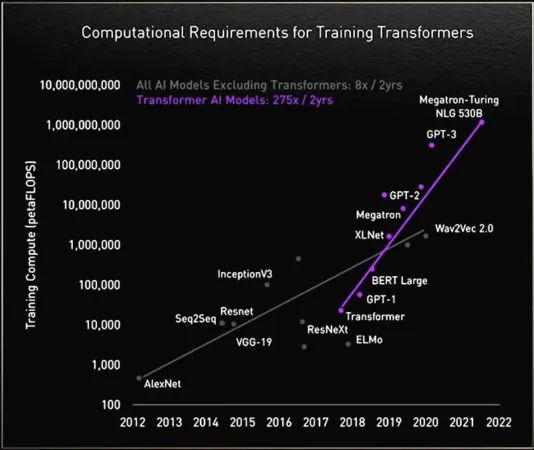
在追求更高性能的過程中,Transformer 模型的規(guī)模也在不斷擴大
Vaswani 現(xiàn)在是一家隱形 AI 初創(chuàng)公司的聯(lián)合創(chuàng)始人,他表示最終目標(biāo)是“讓這些模型像人類一樣,在現(xiàn)實世界中使用極少的數(shù)據(jù)就能從上下文中學(xué)習(xí)。”
他想象未來的模型可以在前期進行更多計算,從而減少對數(shù)據(jù)的需求,使用戶能夠更好地提供反饋。
“我們的目標(biāo)是創(chuàng)建能夠在日常生活中幫助人們的模型。”
安全、負(fù)責(zé)任的模型
其他研究人員正在研究如何在模型放大錯誤或有害語言時消除偏見或有害性,例如斯坦福大學(xué)專門創(chuàng)建了基礎(chǔ)模型研究中心探究這些問題。
NVIDIA 研究科學(xué)家 Shrimai Prabhumoye 是業(yè)內(nèi)眾多研究這一領(lǐng)域的人士之一。他表示:“這些都是在安全部署模型前需要解決的重要問題。”
“如今,大多數(shù)模型需要的是特定的單詞或短語。但在現(xiàn)實生活中,這些內(nèi)容可能會以十分微妙的方式呈現(xiàn),因此我們必須考慮整個上下文。”
Gomez 表示:“這也是 Cohere 最關(guān)心的問題。如果這些模型會傷害到人,就不會有人使用它們,所以創(chuàng)建最安全、最負(fù)責(zé)任的模型是最基本的要求。”
展望未來
在 Vaswani 的想象中,未來能夠自我學(xué)習(xí)、由注意力驅(qū)動的 Transformer 最有可能成為 AI 的“殺手锏”。
他表示:“我們現(xiàn)在有機會實現(xiàn)人們在創(chuàng)造‘通用人工智能’一詞時提到的一些目標(biāo),我覺得這給我們帶來了巨大的啟發(fā)。”
“在當(dāng)前這個時代,神經(jīng)網(wǎng)絡(luò)等各種簡單的方法正在賦予我們大量新的能力。”
小結(jié)
本文通過對 Transformer 模型的應(yīng)用案例進行了梳理,并對其未來的發(fā)展方向進行了預(yù)測。從生物醫(yī)藥到科學(xué)研究,該模型不僅在技術(shù)上取得了突破,更在實際應(yīng)用中展現(xiàn)了其深遠的影響力和廣闊的前景。本文系列內(nèi)容到此已經(jīng)對 Transformer 模型如何擴展我們對于機器學(xué)習(xí)和 AI 的想象進行了深入介紹。隨著技術(shù)的不斷進步,Transformer 模型將在 AI 的新時代中扮演著更加關(guān)鍵的角色,推動各行各業(yè)的創(chuàng)新與變革。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5283瀏覽量
106090 -
AI
+關(guān)注
關(guān)注
88文章
34813瀏覽量
277298 -
模型
+關(guān)注
關(guān)注
1文章
3506瀏覽量
50225 -
Transformer
+關(guān)注
關(guān)注
0文章
151瀏覽量
6469
原文標(biāo)題:什么是 Transformer 模型(二)
文章出處:【微信號:NVIDIA_China,微信公眾號:NVIDIA英偉達】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
Transformer架構(gòu)中編碼器的工作流程

Transformer架構(gòu)概述

如何使用MATLAB構(gòu)建Transformer模型

transformer專用ASIC芯片Sohu說明

【「大模型啟示錄」閱讀體驗】如何在客服領(lǐng)域應(yīng)用大模型
自動駕駛中一直說的BEV+Transformer到底是個啥?

【《大語言模型應(yīng)用指南》閱讀體驗】+ 基礎(chǔ)知識學(xué)習(xí)
Transformer能代替圖神經(jīng)網(wǎng)絡(luò)嗎
Transformer語言模型簡介與實現(xiàn)過程
llm模型有哪些格式
llm模型和chatGPT的區(qū)別
Transformer模型在語音識別和語音生成中的應(yīng)用優(yōu)勢
使用PyTorch搭建Transformer模型
Transformer 能代替圖神經(jīng)網(wǎng)絡(luò)嗎?






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論