") 騰訊云TI平臺(tái)利用NVIDIA Triton推理服務(wù)器構(gòu)造不同AI應(yīng)用場(chǎng)景需求
騰訊云TI平臺(tái)利用NVIDIA Triton推理服務(wù)器構(gòu)造不同AI應(yīng)用場(chǎng)景需求

騰訊云 TI 平臺(tái) TI-ONE 利用 NVIDIA Triton 推理服務(wù)器構(gòu)造高性能推理服務(wù)部署平臺(tái),使用戶能夠非常便捷地部署包括 TNN 模型在內(nèi)的多種深度學(xué)習(xí)框架下獲得的 AI 模型,并且顯著提升推理服務(wù)的吞吐、提升 GPU 利用率。
騰訊云 TI 平臺(tái)(TencentCloud TI Platform)是基于騰訊先進(jìn) AI 能力和多年技術(shù)經(jīng)驗(yàn),面向開發(fā)者、政企提供的全棧式人工智能開發(fā)服務(wù)平臺(tái),致力于打通包含從數(shù)據(jù)獲取、數(shù)據(jù)處理、算法構(gòu)建、模型訓(xùn)練、模型評(píng)估、模型部署、到 AI 應(yīng)用開發(fā)的產(chǎn)業(yè) + AI 落地全流程鏈路,幫助用戶快速創(chuàng)建和部署 AI 應(yīng)用,管理全周期 AI 解決方案,從而助力政企單位加速數(shù)字化轉(zhuǎn)型并促進(jìn) AI 行業(yè)生態(tài)共建。騰訊云 TI 平臺(tái)系列產(chǎn)品支持公有云訪問、私有化部署以及專屬云部署。
TI-ONE 是騰訊云 TI 平臺(tái)的核心產(chǎn)品之一,可為 AI 工程師打造的一站式機(jī)器學(xué)習(xí)平臺(tái),為用戶提供從數(shù)據(jù)接入、模型訓(xùn)練、模型管理到模型服務(wù)的全流程開發(fā)支持。騰訊云 TI 平臺(tái) TI-ONE 支持多種訓(xùn)練方式和算法框架,滿足不同 AI 應(yīng)用場(chǎng)景的需求。
通常我們?cè)?AI 模型訓(xùn)練好之后,需要將其部署在云端形成 AI 服務(wù),供應(yīng)用的客戶端進(jìn)行調(diào)用。但如何高效地進(jìn)行推理服務(wù)的部署無疑是 AI 推理平臺(tái)需要面對(duì)的挑戰(zhàn)。
一方面,推理服務(wù)部署平臺(tái)需要支持多種不同深度學(xué)習(xí)框架訓(xùn)練出來的模型,以滿足不同客戶對(duì)于不同框架的偏好,甚至需要支持一些自定義的推理框架,如 TNN[1] 等。
另一方面,部署平臺(tái)需要盡可能提升推理服務(wù)的性能,包括提升吞吐、降低延時(shí),以及提升硬件資源利用率等,這就要求平臺(tái)對(duì)模型的部署和調(diào)度進(jìn)行高效的優(yōu)化。
最后,對(duì)于由前后處理、AI 模型等多個(gè)模塊組成的工作流,例如一些 AI 工作管線中除了深度學(xué)習(xí)模型之外還包含前后處理模塊,推理服務(wù)部署平臺(tái)也需要對(duì)各個(gè)模塊進(jìn)行有條不紊且高效的串聯(lián)。以上這些需求,都需要對(duì)推理服務(wù)部署平臺(tái)進(jìn)行精心的設(shè)計(jì)和實(shí)現(xiàn)。
針對(duì)以上挑戰(zhàn),騰訊云 TI-ONE 充分利用 NVIDIA Triton 推理服務(wù)器構(gòu)建高性能的推理部署解決方案,為多個(gè)行業(yè)場(chǎng)景的推理工作負(fù)載提升效率。
騰訊云將 Triton 集成進(jìn) TI-ONE 的推理部署服務(wù)中。行業(yè)客戶僅需將需要推理的模型上傳至 TI-ONE 平臺(tái)上,并選擇使用 Triton 作為推理后端框架,TI-ONE 便能自動(dòng)地在 Kubernetes 集群上自動(dòng)拉起 Triton 容器。在容器內(nèi),Triton 服務(wù)器將會(huì)啟動(dòng),并根據(jù)客戶選定的配置參數(shù),自動(dòng)地加載用戶上載的模型,以模型實(shí)例的方式管理起來,并對(duì)外提供推理服務(wù)請(qǐng)求的接口。
Triton 支持絕大部分主流深度學(xué)習(xí)框架的推理,包括 TensorRT, TensorFlow, PyTorch, ONNX Runtime 等。除此之外,Triton 還支持?jǐn)U展自定義的推理框架 Backend。TNN 是騰訊自研的開源高性能、輕量級(jí)神經(jīng)網(wǎng)絡(luò)推理框架,被廣泛應(yīng)用于騰訊云行業(yè)解決方案的推理場(chǎng)景中。騰訊云遵循 Triton Backend API [2],實(shí)現(xiàn)了 Triton TNN Backend,使得 TNN 模型能夠直接被 Triton 推理服務(wù)器加載、管理以及執(zhí)行推理。
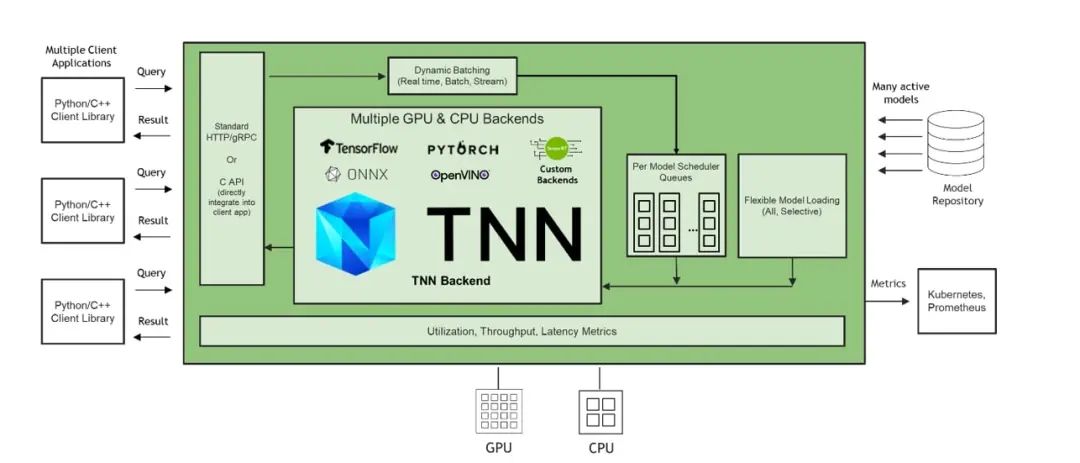
圖1. 加入 TNN Backend 的 Triton 推理服務(wù)器架構(gòu)示意圖
為了提升推理服務(wù)的性能、提升硬件資源利用率,騰訊云 TI-ONE 利用了 Triton 提供的 Dynamic Batching 功能。在部署推理服務(wù)時(shí),用戶可選擇開啟該功能,Triton 則會(huì)自動(dòng)地將到達(dá)服務(wù)端的零散推理請(qǐng)求(通常 batch size 較小)聚合成大的 batch,輸入對(duì)應(yīng)的模型實(shí)例中進(jìn)行推理。如此,GPU 在執(zhí)行更大 batch size 的推理時(shí)能達(dá)到更高的利用率,從而提升服務(wù)的吞吐。且用戶可在 TI-ONE 平臺(tái)中設(shè)置將多個(gè)請(qǐng)求組合成 batch 的等待時(shí)長(zhǎng),以便在延時(shí)和吞吐之間權(quán)衡。不僅如此,TI-ONE 還利用 Triton 的 Concurrent Model Execution 功能,在每張 NVIDIA GPU 上同時(shí)部署相同或不同模型的多個(gè)模型實(shí)例,使得在單個(gè)模型較為輕量的情況下,通過多個(gè)模型實(shí)例的并行執(zhí)行來充分利用 GPU 的計(jì)算資源,在提升 GPU 利用率的同時(shí)獲得更高的吞吐。
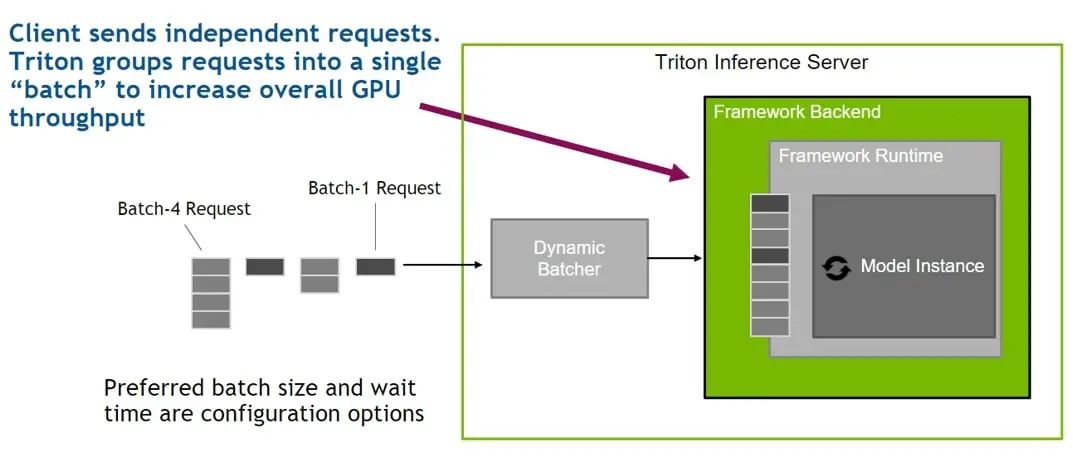
圖2. Triton Dynamic Batching 機(jī)制示意圖
最后,針對(duì)需要部署由多個(gè)模塊組合的 AI 工作管線的應(yīng)用場(chǎng)景,TI-ONE 正與 NVIDIA 一起積極探索如何利用 Triton Ensemble Model 以及 Triton Python Backend,將前后處理模塊與 AI 模型有序地串聯(lián)在一起。其中,Triton Python Backend 能夠直接將現(xiàn)有的 Python 前后處理代碼封裝為可在 Triton 上部署的模塊;Triton Ensemble Model 是一種特殊的調(diào)度器,可通過配置文件定義多個(gè)模塊之間的連接關(guān)系,并自動(dòng)地將推理請(qǐng)求在定義好的工作管線上進(jìn)行有條不紊的調(diào)度。
目前,騰訊云 TI 平臺(tái) TI-ONE 利用 NVIDIA Triton 已為多種不同的行業(yè)解決方案提供了高性能的推理服務(wù),包括工業(yè)質(zhì)檢、自動(dòng)駕駛等業(yè)務(wù)場(chǎng)景,涉及到的圖像分類、對(duì)象檢測(cè)、以及實(shí)例分割等 AI 任務(wù)。
通過 Triton 提供的多框架支持以及擴(kuò)展的 TNN Backend,無論用戶使用何種框架訓(xùn)練 AI 模型,都能在 TI-ONE 上部署其推理服務(wù),給了算法工程師更大的選擇自由度,節(jié)省了模型轉(zhuǎn)換的開銷。利用 Triton 的 Dynamic Batching 機(jī)制和 Concurrent Model Execution 功能, TI-ONE 在某一目標(biāo)檢測(cè)場(chǎng)景部署 FasterRCNN ResNet50-FPN 模型,相比于使用 Tornado 部署框架在 NVIDIA T4 Tensor Core GPU 上最高可獲得 31.6% 的吞吐提升,如下圖所示:
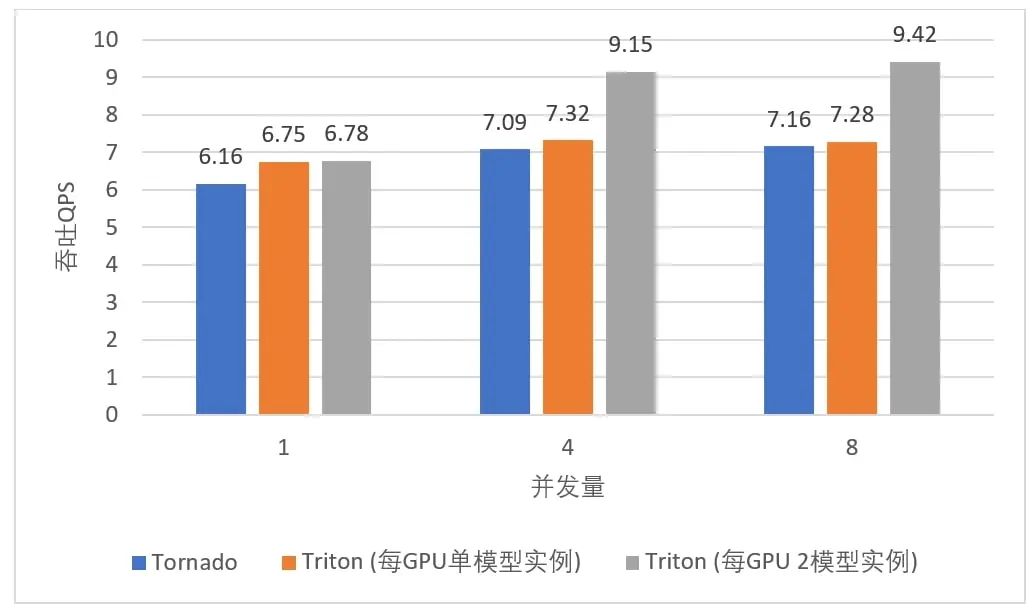
圖 3. TI-ONE 中不同推理服務(wù)框架部署目標(biāo)檢測(cè)模型時(shí)所實(shí)現(xiàn)的服務(wù)吞吐量對(duì)比
2022 騰訊云
此圖片依據(jù)由騰訊云提供數(shù)據(jù)所制作
在另一圖像分類業(yè)務(wù)中,TI-ONE 利用 Triton 的 Dynamic Batching 機(jī)制部署包含前后處理及模型推理的工作管線,結(jié)合 TNN 對(duì)推理的加速,在 1/2 T4 Tensor Core GPU 上,相比于 Python 實(shí)現(xiàn)的 HTTP Server 獲得最高 2.6 倍延時(shí)縮減及最高 2.5 倍吞吐的提升,如下表所示:
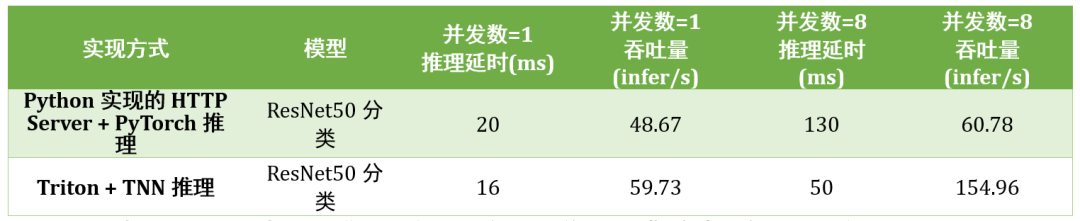
表 1. TI-ONE 中不同推理服務(wù)框架部署圖像分類模型時(shí)所實(shí)現(xiàn)的服務(wù)性能對(duì)比
2022 騰訊云
此表格依據(jù)由騰訊云提供數(shù)據(jù)所制作
未來,騰訊云 TI 平臺(tái)將與 NVIDIA 團(tuán)隊(duì)繼續(xù)合作,探索利用 Triton 對(duì)復(fù)雜工作管線進(jìn)行推理服務(wù)部署的解決方案,進(jìn)一步為各個(gè)行業(yè)的 AI 推理場(chǎng)景提供更高效率、更低成本的推理平臺(tái)。
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5292瀏覽量
106151 -
服務(wù)器
+關(guān)注
關(guān)注
13文章
9767瀏覽量
87713 -
AI
+關(guān)注
關(guān)注
88文章
34909瀏覽量
277887 -
騰訊云
+關(guān)注
關(guān)注
0文章
221瀏覽量
17075
原文標(biāo)題:NVIDIA Triton 助力騰訊云 TI-ONE 平臺(tái)為行業(yè)解決方案提供高性能 AI 推理部署服務(wù)
文章出處:【微信號(hào):NVIDIA-Enterprise,微信公眾號(hào):NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
AI 推理服務(wù)器都有什么?2025年服務(wù)器品牌排行TOP10與選購技巧

英偉達(dá)GTC25亮點(diǎn):NVIDIA Dynamo開源庫加速并擴(kuò)展AI推理模型
AI云服務(wù)平臺(tái)可以干什么

使用NVIDIA推理平臺(tái)提高AI推理性能






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論