") 數(shù)據(jù)庫發(fā)展史2--數(shù)據(jù)倉庫
數(shù)據(jù)庫發(fā)展史2--數(shù)據(jù)倉庫

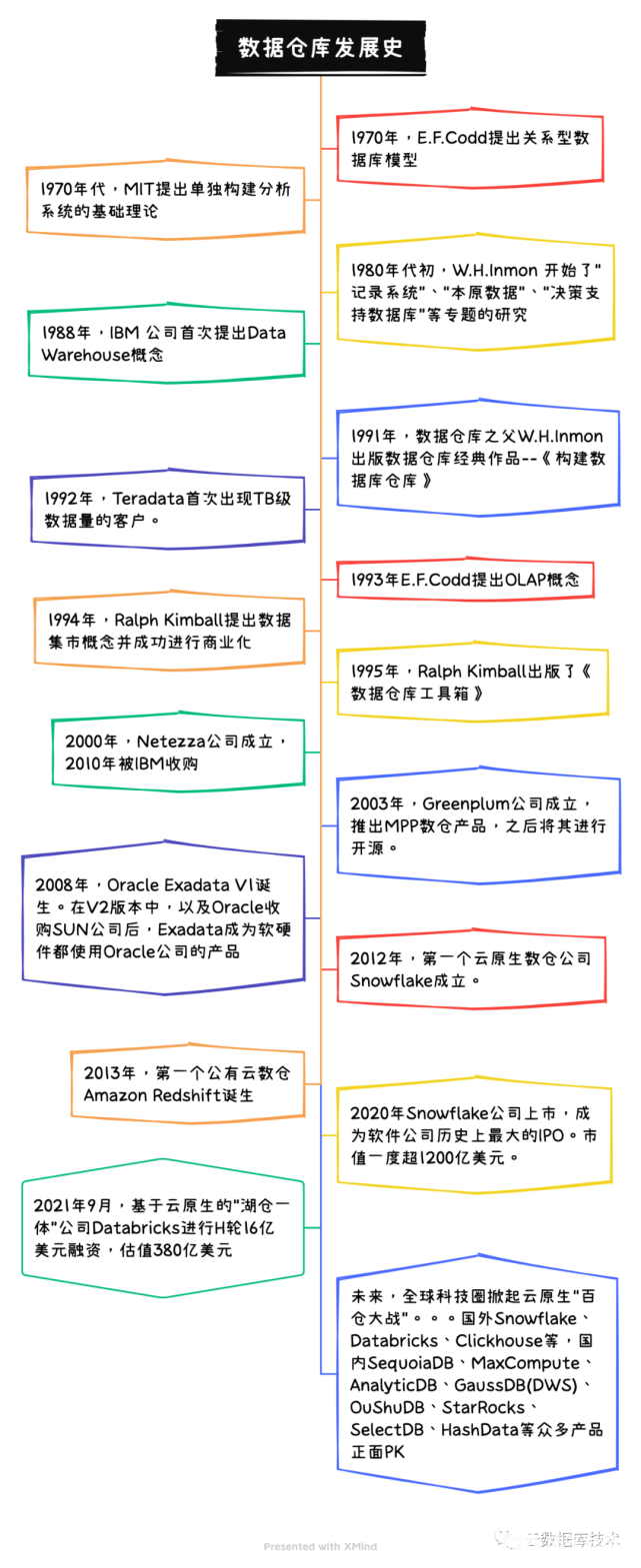
回顧數(shù)據(jù)倉庫的發(fā)展歷程,大致可以將其分為幾個階段:萌芽探索到全企業(yè)集成時代、企業(yè)數(shù)據(jù)集成時代、混亂時代--"數(shù)據(jù)倉庫之父"間的論戰(zhàn)、理論模型確認時代以及數(shù)據(jù)倉庫產(chǎn)品百家爭鳴時代。
數(shù)據(jù)倉庫理論發(fā)展歷程
上世紀70年代,IBM的E.F.Codd等人提出關(guān)系型數(shù)據(jù)庫后,MIT的研究員提出單獨構(gòu)建分析系統(tǒng)的基礎(chǔ)理論,新的理論試圖將業(yè)務(wù)處理系統(tǒng)和分析系統(tǒng)分開,即將業(yè)務(wù)處理和分析處理分為不同層次,針對各自的特點采取不同的架構(gòu)設(shè)計原則。他們認為這兩種信息處理的方式具有較大差別,應(yīng)使用不同的架構(gòu)和設(shè)計。但受限于當時的技術(shù)能力,這個研究僅僅停留在理論層面。
到了80年代初,W.H.Inmon 開始了“記錄系統(tǒng)”、“本原數(shù)據(jù)”、“決策支持數(shù)據(jù)庫”等專題的研究。幾乎同時,J. Martin在關(guān)于數(shù)據(jù)庫分類的研究中,專指一種他稱之為“第4類數(shù)據(jù)庫”的“由用戶驅(qū)動的計算環(huán)境”,為這種環(huán)境提供信息服務(wù)的是一種以“搜索和快速信息回收”為基本特征的數(shù)據(jù)庫。這個定義已經(jīng)和后來的數(shù)據(jù)倉庫十分類似。
1988年,IBM 公司的研究員創(chuàng)造性地提出了一個新的概念--數(shù)據(jù)倉庫(Data Warehouse)。到了1991年,數(shù)據(jù)倉庫之父W.H.Inmon出版數(shù)據(jù)倉庫經(jīng)典作品--《構(gòu)建數(shù)據(jù)庫倉庫》,標志著數(shù)據(jù)倉庫概念的確立。書中指出,DW是一個面向主題的、集成的、相對穩(wěn)定的、反映歷史變化的數(shù)據(jù)集合,并且是用于支持管理決策的數(shù)據(jù)集合。該書還提供了建立數(shù)據(jù)倉庫的指導意見和基本原則,憑借著這本書,W.H.Inmon被稱為數(shù)據(jù)倉庫之父。
由于傳統(tǒng)的關(guān)系型數(shù)據(jù)庫已無法滿足構(gòu)建數(shù)據(jù)倉庫的需求,在1993年Codd提出了多維數(shù)據(jù)庫和多維分析的概念,即OLAP(On-Line Analysis Processing聯(lián)機分析處理)。當時Codd認為OLTP(On- Line Transaction Processing 聯(lián)機事務(wù)處理)已不能滿足終端用戶對數(shù)據(jù)庫查詢的需要,SQL對大數(shù)據(jù)庫進行的簡單查詢也不能滿足用戶分析的需求。用戶的決策分析需要對關(guān)系數(shù)據(jù)庫進行大量計算才能得到結(jié)果,而查詢的結(jié)果并不能滿足決策者提出的需要。因此提出了多維數(shù)據(jù)庫和多維分析的概念,即OLAP。
1995年,Ralph Kimball出版了《數(shù)據(jù)倉庫工具箱》,數(shù)據(jù)倉庫行業(yè)進入少林和武當之爭。Inmon主張建立數(shù)據(jù)倉庫時采用自上而下方式,以關(guān)系型數(shù)據(jù)庫的第3范式進行數(shù)據(jù)倉庫模型設(shè)計,而Kimball則是主張自下而上的方式,力推數(shù)據(jù)集市(Data Market)建設(shè)。兩位數(shù)據(jù)倉庫領(lǐng)域的大咖為此吵得不可開交,他們的粉絲也紛紛站隊,這種爭吵直到Inmon推出新的BI架構(gòu)CIF,把Kimball的數(shù)據(jù)集市包括了進來才算平息。
早期MPP時代的數(shù)倉
IBM DB2和Teradata是早期數(shù)倉理論的實踐者,也是市場領(lǐng)導者。其中Teradata是MPP數(shù)倉最成功的商業(yè)產(chǎn)品,幾乎是行業(yè)的天花板。誕生于1970年代末的Teradata公司,名稱來源于Tera Bytes,TB數(shù)據(jù)的存儲也展示了哪個年代創(chuàng)業(yè)者的雄心壯志。終于在1992年第一個TB 級的數(shù)據(jù)庫在華爾街出現(xiàn)。1999年,客戶擁有130TB的數(shù)據(jù)分布于176個節(jié)點。短短7年時間,Teradata客戶的數(shù)據(jù)規(guī)模翻了176倍。
但進入新千年后,數(shù)據(jù)庫巨頭間的競爭進入白熱化階段,以O(shè)racle Exadata為代表的一體機很快嶄露頭角。之后在Postgres基礎(chǔ)上演變而來的Greenplum構(gòu)建了開源的MPP架構(gòu)數(shù)倉,也在市場中有很高的影響力。但真正讓數(shù)倉煥然一新的是云計算時代的云原生數(shù)倉Snowflake。
一體機時代的數(shù)倉
新千年后,數(shù)倉進入一體機的快速發(fā)展時代,典型代表是Netezza、SAP HANA和Oracle Exadata。Netezza率先推出,后來被IBM收購。而Oracle Exadata為代表的一體機依然是今天Oracle公司的核心業(yè)務(wù)。2008年,Exadata V1誕生,由Oracle提供軟件惠普提供硬件,這一代產(chǎn)品僅支持數(shù)據(jù)倉庫和商務(wù)智能等OLAP工作。到了2009年9月,Exadata V2發(fā)布,采用了SUN的(此后MySQL也屬于了Oracle),次年Oracle完成了SUN的收購。在V2版本中,Exadata存儲節(jié)點中首次采用了Flash卡,從而可以同時支持OLAP和OLTP類型的負載。有了高性能產(chǎn)品的同時也有了極其昂貴的價格。
著名的Conor O'Mahony(DB2的市場經(jīng)理)羅列了使用一臺全機架系統(tǒng)(full-rack)Exdata V2所需的費用列表:
$1,150,000 硬件價格
$1,680,000 存儲服務(wù)器的軟件價格
$369,600 存儲服務(wù)器軟件支持和維護費用(以22%計)
$1,520,000 Oracle企業(yè)版軟件價格($47.5k*8 servers*8 cores*0.5 Intel core factor)
$736,000 Oracle RAC軟件價格($23k*8 servers*8 cores*0.5 Intel core factor)
$368,000 Oracle分區(qū)特性價格 ($11.5k*8 servers*8 cores*0.5 Intel core factor)
$368,000 Oracle高級壓縮(Advanced Compression) ($11.5k*8 servers*8 cores*0.5 Intel core factor)
$160,000 Oracle企業(yè)管理器診斷包(推薦安裝)
$160,000 Oracle企業(yè)管理器調(diào)優(yōu)包(推薦安裝)
$728,640 以上除去存儲服務(wù)器軟件的第一年軟件維護支持價格(以22%計)
Oracle Exadata 一體機
如此昂貴的價格,對于一般企業(yè)顯然無法接受。人們相信全新一代的數(shù)倉技術(shù)一定會在一個萬眾囑目的情況下出現(xiàn),像蓋世英雄身披金甲圣衣,腳踏七彩祥云而來。
云計算時代的數(shù)倉
隨著移動互聯(lián)網(wǎng)、物聯(lián)網(wǎng)的蓬勃發(fā)展,率先掀起數(shù)據(jù)庫革命的是Google公司,他的三篇論文開啟了大數(shù)據(jù)時代,之后言數(shù)倉、大數(shù)據(jù)必稱Hadoop。但它的弊病也頗為明顯,昂貴、不方便使用、難維護等問題始終無法很好的解決。直到計算機行業(yè)七彩祥云--云計算出現(xiàn),為整個行業(yè)和人類生活帶來巨大變化。而此時的數(shù)據(jù)倉庫在變更的前夜顯得異常安靜,古語言:三年不鳴一鳴驚人,Snowflake 就是三年不飛一飛沖天的云計算時代云原生數(shù)倉產(chǎn)品。
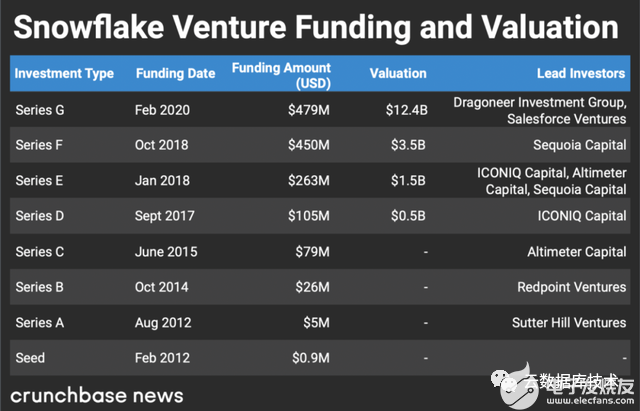
2012年,在Oracle公司工作十多年的2位程序員決心在云上建立一個數(shù)據(jù)倉庫,于是誕生了Snowflake公司。它誕生的第一天,就有云計算的特點:存儲與計算分離、按量付費、云中立。作為第一個基于云原生的數(shù)據(jù)倉庫,Snowflake 敏銳的抓住從本地到上云的時代趨勢,充分利用公有云強大基礎(chǔ)設(shè)施能力,讓用戶更加輕松實現(xiàn)跨云平臺、跨區(qū)域的方式移動數(shù)據(jù)。這種基于云原生、云中立、跨多云平臺的云原生數(shù)據(jù)服務(wù),為客戶提供巨大數(shù)據(jù)價值的同時,極大降低了客戶使用、維護、價格成本。
Snowflake產(chǎn)品上的成功同時也取得資本市場的巨大成功。2020年9月16日,在紐交所成功IPO,股神巴菲特斥幾億美元入股,交易首日股價翻倍市值達到704億美元,成為史上規(guī)模最大的軟件IPO,之后市值一度最高突破1200億美元,儼然成為資本市場的寵兒。
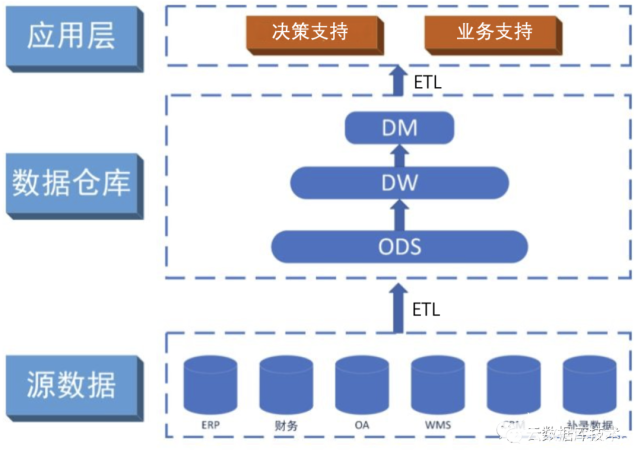
數(shù)據(jù)倉庫和數(shù)據(jù)庫關(guān)系
廣義的數(shù)據(jù)倉庫并不是一項技術(shù),也不是一個產(chǎn)品,而是一種數(shù)據(jù)處理過程。數(shù)據(jù)倉庫的數(shù)據(jù)來源有多種,業(yè)務(wù)系統(tǒng)、日志、互聯(lián)網(wǎng)、系統(tǒng)運行參數(shù)等等,這些數(shù)據(jù)可以在數(shù)據(jù)倉庫中進行匯合,然后通過統(tǒng)一的建模,加工成服務(wù)與數(shù)據(jù)分析的數(shù)據(jù)模型,最終輔助企業(yè)分析決策。
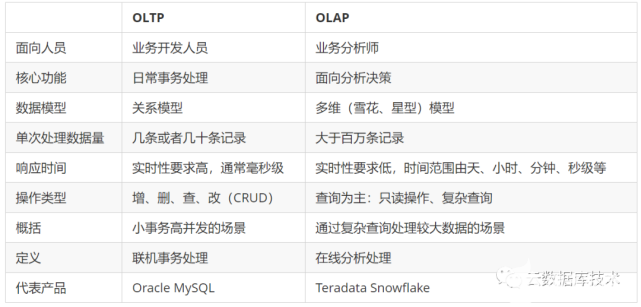
那如何構(gòu)建數(shù)據(jù)倉庫呢?常見的是使用OLAP數(shù)據(jù)庫(如近年流行Clickhouse)存儲數(shù)據(jù),通過數(shù)據(jù)建模、ETL、數(shù)據(jù)可視化等一系列操作,這一過程被稱為構(gòu)建數(shù)據(jù)倉庫。由于數(shù)據(jù)倉庫基于OLAP產(chǎn)品,是做在線分析處理,這是與數(shù)據(jù)庫的本質(zhì)區(qū)別。另外,既然是數(shù)據(jù)倉庫就要加工數(shù)據(jù),加工數(shù)據(jù)會耗時間,所以加工數(shù)據(jù)在實際的應(yīng)用中又分為批處理和實時處理。而傳統(tǒng)的數(shù)據(jù)庫是為了解決事務(wù)存在的,他們的區(qū)別如下。
總結(jié)和展望
數(shù)據(jù)倉庫是80~90年代提出的概念,互聯(lián)網(wǎng)企業(yè)為了解決更大數(shù)據(jù)量的管理問題,掀起了大數(shù)據(jù)技術(shù)新浪潮,大數(shù)據(jù)已經(jīng)跳出了數(shù)倉定義領(lǐng)域,未來再專題闡述。隨著2020年云原生數(shù)倉Snowflake上市并取得巨大的成功,大家開始趨向把數(shù)據(jù)倉庫、大數(shù)據(jù)、數(shù)據(jù)湖、云存儲的技術(shù)全面融合,全世界掀起了云原生數(shù)據(jù)倉庫和湖倉一體的熱潮,國際上Databricks、Clickhouse已經(jīng)正面PK,國內(nèi)有SequoiaDB、MaxCompute,AnalyticDB,GaussDB(DWS),OuShuDB、StarRocks、SelectDB、HashData等不下數(shù)十款產(chǎn)品,還有很多類似HTAP新品在路上,未來必將迎來百倉大戰(zhàn)的腥風血雨。
數(shù)據(jù)倉庫發(fā)展史
審核編輯 黃昊宇
-
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3921瀏覽量
66131
發(fā)布評論請先 登錄
數(shù)據(jù)庫數(shù)據(jù)恢復—MongoDB數(shù)據(jù)庫文件丟失的數(shù)據(jù)恢復案例
數(shù)據(jù)庫數(shù)據(jù)恢復—SQL Server數(shù)據(jù)庫被加密如何恢復數(shù)據(jù)?

數(shù)據(jù)庫數(shù)據(jù)恢復——MongoDB數(shù)據(jù)庫文件拷貝后服務(wù)無法啟動的數(shù)據(jù)恢復
數(shù)據(jù)庫數(shù)據(jù)恢復—SQL Server附加數(shù)據(jù)庫提示“錯誤 823”的數(shù)據(jù)恢復案例
MySQL數(shù)據(jù)庫的安裝
云數(shù)據(jù)庫是哪種數(shù)據(jù)庫類型?
數(shù)據(jù)庫數(shù)據(jù)恢復—Mysql數(shù)據(jù)庫表記錄丟失的數(shù)據(jù)恢復流程

數(shù)據(jù)庫數(shù)據(jù)恢復—MYSQL數(shù)據(jù)庫ibdata1文件損壞的數(shù)據(jù)恢復案例
數(shù)據(jù)庫數(shù)據(jù)恢復—通過拼接數(shù)據(jù)庫碎片恢復SQLserver數(shù)據(jù)庫

Oracle數(shù)據(jù)恢復—異常斷電后Oracle數(shù)據(jù)庫啟庫報錯的數(shù)據(jù)恢復案例
架構(gòu)師日記-從數(shù)據(jù)庫發(fā)展歷程到數(shù)據(jù)結(jié)構(gòu)設(shè)計探析

數(shù)據(jù)庫數(shù)據(jù)恢復—Oracle數(shù)據(jù)庫文件system01.dbf損壞的數(shù)據(jù)恢復案例
數(shù)據(jù)庫數(shù)據(jù)恢復—SQL Server數(shù)據(jù)庫出現(xiàn)823錯誤的數(shù)據(jù)恢復案例

Oracle數(shù)據(jù)恢復—Oracle數(shù)據(jù)庫delete刪除的數(shù)據(jù)恢復方法
恒訊科技分析:sql數(shù)據(jù)庫怎么用?
- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論