 一種簡單而有效的轉換方法來降低預測情感標簽的難度
一種簡單而有效的轉換方法來降低預測情感標簽的難度
01
研究動機
面向目標的多模態情感分類(TMSC)是方面級情感分析的一個新的子任務,旨在預測一對句子和圖片中提到的意見目標的情感極性。該任務背后的假設是圖片信息可以幫助文本內容識別意見目標的情感。圖1給出了兩個代表性的示例。我們可以看到僅僅根據非正式的簡短句子很難檢測出意見目標的情感,但與意見目標相關的視覺內容(即笑臉)可以清晰地反映其情感極性。
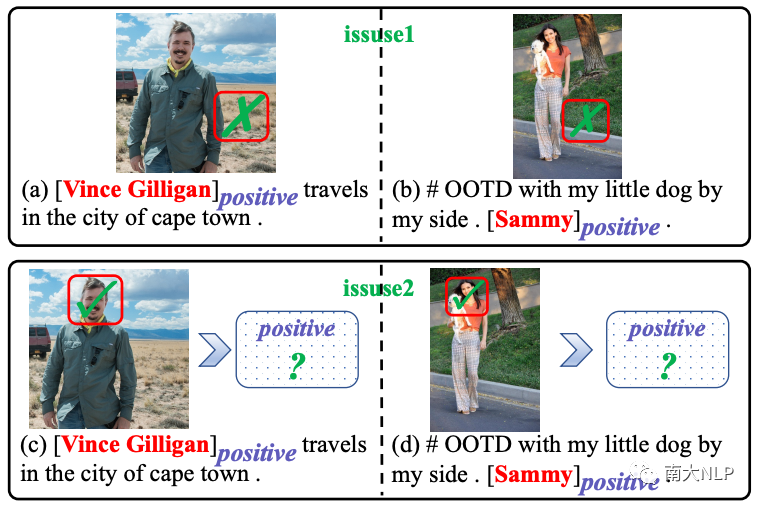
圖1:面向目標的多模態情感分類 (TMSC) 的兩個示例。意見目標及其相應的情感極性在句子中突出顯示。紅色邊框表示意見目標關注到的視覺線索。
從上面的示例中我們可以看出,對齊兩種模態的意見目標并捕獲有用的視覺情感特征在TMSC任務中起著至關重要的作用。鑒于其重要性,主流的工作采用了注意力機制來自動學習文本和圖片的對齊關系,然后將捕獲的意見目標的視覺表示聚合為證據來進行情感預測。
盡管取得了一些改進,但上述方法仍然存在兩個關鍵問題:
(1)由于文本和圖片中意見目標的粒度存在很大的差距,之前的這些方法很難對齊兩種模態。具體來說,圖片中出現的意見目標通常是指粗粒度的對象(例如,圖片中的man),而句子中的意見目標通常是細粒度的實體(例如,人名 “Vince Gilligan)。意見目標粒度的不一致導致視覺注意力有時無法捕捉到相應的視覺表征。
(2)即使捕獲到了,表達相同情緒的多樣化視覺表示也給情感預測帶來了很大的挑戰。以圖1(c)和圖1(d)為例,意見目標“Vince Gilligan”和“Sammy”分別關注了圖片中的粗粒度對象man和girl,從他們的面部表情我們可以看出他們都在微笑,但微笑的角度和幅度卻大不相同。視覺表示的多樣性不可避免地導致其稀疏性,這使得學習視覺表示和情感標簽之間的映射函數變得困難。
在這項工作中,我們提供了解決上述問題的新思路,即利用從圖片中提取的形容詞-名詞對 (ANPs) .(例如圖2(a)中的“nice clouds”, “bad car”, “happy man”, “clear sky”和“dry grass”)。對于第一個問題,我們觀察到ANPs中的名詞也是粗粒度的概念,因此一個很直觀的想法是將細粒度的意見目標(例如“Vince Gilligan”)映射到粗粒度名詞中(例如“man”)。
通過這種方式更容易彌合兩種模態的粒度差距并對齊文本和圖片。對于第二個問題,我們觀察到 ANPs 通常可以從表達相同情緒的不同視覺內容中提取到相同的形容詞,因此一個很直觀的想法是將多樣化的視覺表征(例如笑臉)映射到同一個形容詞(例如“happy”)。顯然,學習這些相同形容詞和情感標簽之間的映射函數更容易。
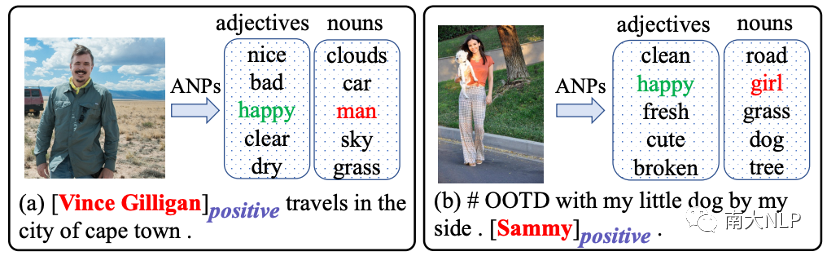
圖2:從每個圖片中提取前 5 個形容詞-名詞對 (ANPs)
為了使用 ANPs促進 TMSC 任務,我們提出了一個知識增強框架(簡稱KEF), 它主要包含兩個組件:視覺注意力增強器和情感預測增強器。前者首先使用我們設計的映射方法從 ANPs 中找到與意見目標最相關的名詞,然后用它來提高視覺注意力的有效性。后者的目的是建立形容詞和目標相關視覺表示之間的聯系,然后將其用作視覺表示的補充信息,以降低預測情感標簽的難度。
02
貢獻
1.據我們所知,我們是第一個提出利用從圖片中提取的形容詞-名詞對(ANPs)來幫助TMSC 任務對齊文本和圖片的工作;
2.我們提出了一種新穎的知識增強框架(KEF),它包含一個視覺注意力增強器來提高視覺注意力的有效性,以及一個情感預測增強器來降低情感預測的難度。
3.KEF 具有良好的兼容性,很容易組合或者擴展到現有的基于注意力的多模態模型。在這項工作中,我們將其應用于兩個最新的 TMSC 模型:SaliencyBERT[6]和 TomBERT[2]。兩個公開數據集的實驗結果證明了我們框架的有效性。
03
解決方案
圖 3 展示了 KEF 的整體架構,主要包含兩個組件:視覺注意力增強器和情感預測增強器。具體來說,我們首先基于TomBERT[2]和 SaliencyBERT模型抽象出一個通用的注意力架構。然后,在 ANPs 的幫助下,我們依次提出了視覺注意力增強器和情感預測增強器。前者旨在通過映射方法和重構損失來提高視覺注意力的有效性,后者引入了一種簡單而有效的轉換方法來降低預測情感標簽的難度。
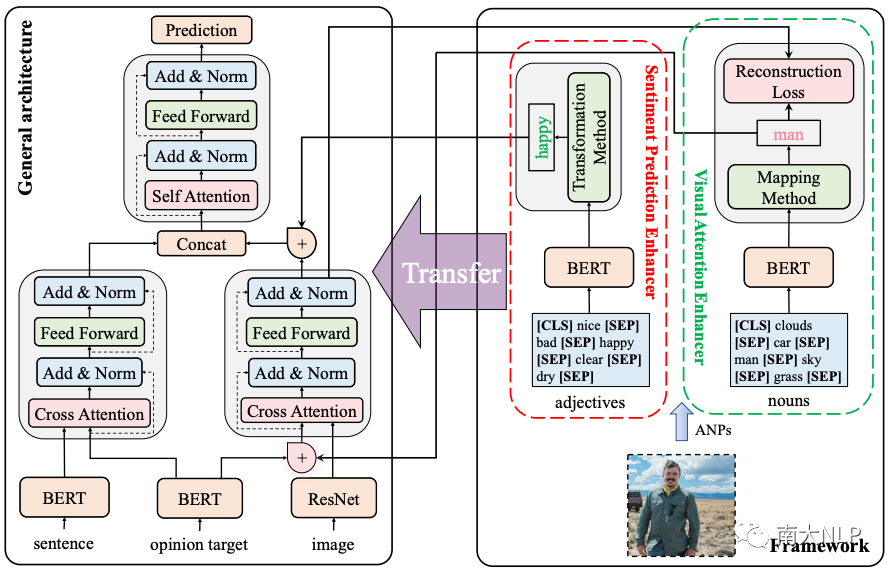
圖3:知識增強框架(KEF)的整體架構
3.1 視覺注意力增強器
問題
如前所述,圖片中出現的意見目標是一個粗粒度的概念,而句子中提到的意見目標是一個細粒度的概念,意見目標粒度的不一致導致了視覺注意力有時無法捕獲到相應的視覺表示。
基本的直覺
顯然,從圖片中提取出來的名詞也是粗粒度的概念,所以一個直觀的想法是將細粒度的意見目標映射到粗粒度的名詞上,然后將它作為橋梁來捕獲粗粒度的視覺特征.。但是,從圖片中提取的大部分名詞都是與意見目標無關的,因此我們不能直接使用它們。
映射方法(Mapping Method.)
為了應對上述挑戰,我們首先通過計算嵌入空間中名詞表示和目標表示之間的語義相似度來衡量目標-名詞相關性的強度:
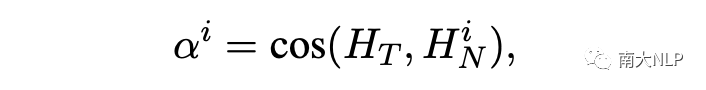
根據最大相似度得分,我們可以找到與意見目標最相關的名詞:
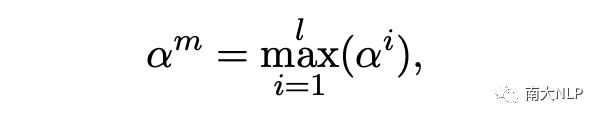
接下來,我們將它們聚合在一起作為意見目標的補充信息以捕獲相應的視覺表示:
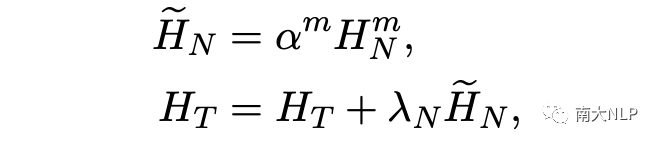
重構損失(Reconstruction Loss.)
為了確保視覺注意力能夠更準確地捕獲到與意見目標相關的視覺特征,我們還設計了一種重構損失來最小化目標相關名詞表示和目標相關視覺表示之間的差異:
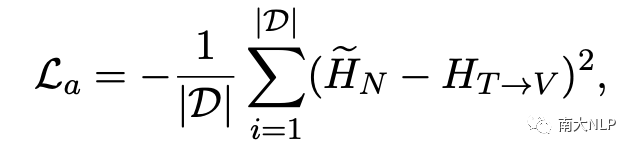
3.2 情感預測增強器
問題
即使視覺特征被捕獲到了,但是表達相同情緒的視覺表征之間仍然存在顯著差異,這給學習視覺表征和情感標簽之間的映射函數帶來了挑戰。
基本的直覺
考慮到 ANPs 通常可以從表達相同情緒的不同視覺表征中提取相同的形容詞,因此一個直觀的想法是將多樣化的視覺表征映射到同一個形容詞。然而,與視覺表示最相關的形容詞是未知的,我們需要明確地找到它。
轉換方法(Transformation Method.)
實際上,在映射方法中,我們發現名詞表示與目標感知視覺表示最相關。由于形容詞是名詞的修飾語,因此與該名詞對應的形容詞也與目標感知視覺表示最相關。最后,我們將其用作視覺表示的補充信息,以降低情感預測的難度: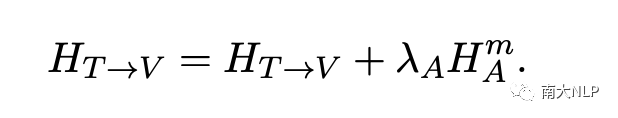
04
實驗
我們在兩個公開的數據集Twitter2015和Twitter2017上進行了實驗,并且使用準確率(Accuracy)和Macro-F1分數作為評估指標。KEF包含兩個即插即用的組件,可以輕松組合或擴展到現有的基于注意力的方法。為了更好地驗證KEF的有效性,我們選擇了兩個最近的基于BERT的多模態模型作為我們工作的基礎,即TomBERT和Saliencybert。
換句話說,我們將KEF集成到TomBERT和Saliencybert中,得到最終模型KEF-TomBERT和KEF-Saliencybert。從表1可以看出,KEF-Saliencybert和KEF-TomBERT在TWITTER-15和TWITTER-17數據集上均取得了具有競爭力的結果。
具體來說,與TomBERT相比,KEF-TomBERT在Macro-F1和Accuracy分別獲得了大約2.0%和1.5%的改進。相比之下,KEF-Saliencybert的表現平均優于Saliencybert1.5%和1.7%。這些結果表明我們的框架具有良好的兼容性。此外,在大多數情況下,KEF-TomBERT的表現優于KEFSaliencybert,這表明我們的框架對TomBERT更有效。
表1:主實驗結果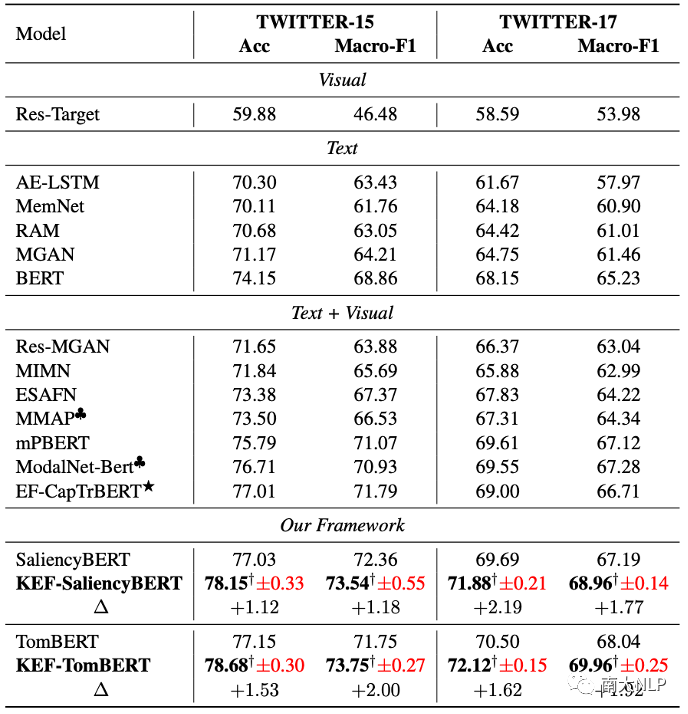
在不失一般性的情況下,我們選擇 KEF-TomBERT 模型進行消融實驗,以研究 KEF 中單個模塊對模型整體效果的影響。視覺注意力增強器簡稱VAE,-情感預測增強器簡稱SPE。根據表2報告的結果,我們可以觀察到以下幾點:
表2:消融實驗結果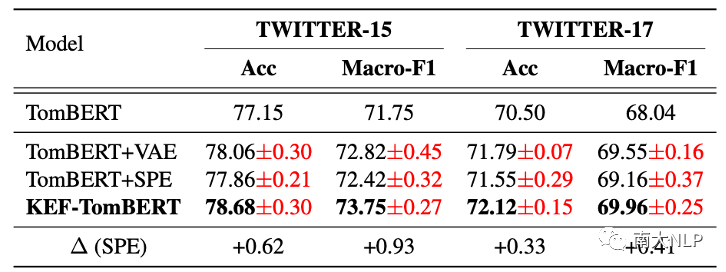
1. 與基礎模型 TomBERT 相比,TomBERT+VAE 和TomBERT+SPE在兩個數據集上均取得了具有競爭力的表現,這驗證了利用形容詞-名詞對提高視覺注意力能力和情感預測能力的合理性;
2. 將SPE集成到TomBERT+VAE后,KEF-TomBERT實現了state-of-the-art的性能,這證明了SPE可以通過形容詞-名詞對提高情感預測能力;
3. VAE 比 SPE 更有效,這是合理的因為注意力機制的有效性是情感預測的核心因素。因此,它對我們的框架貢獻更大;
4. 如圖 4 所示,我們可以看到 KEF-TomBERT 學習到的多模態表示明顯比 TomBERT+VAE 學習的更可分離,這表明SPE確實可以降低情感預測的難度。
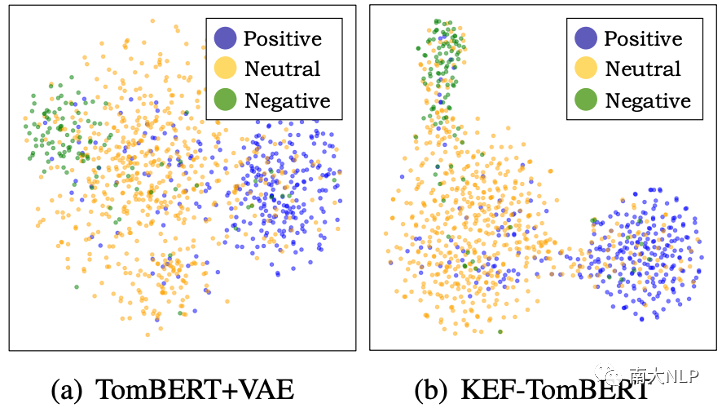
圖4:TomBERT+VAE 和 KEF-TomBERT 的多模態表示的可視化
為了驗證 ANPs 對 KEF-TomBERT 模型的影響,我們從每張圖片中提取前 1、3、5 和 7 個 ANPs進行了實驗,結果如圖 5 所示。顯然,隨著 ANPs 數量的增加,KEF-TomBERT 的性能變得更好。而且當 ANPs 的數量等于 5 時,KEF-TomBERT 的效果最好。
但是,一旦 ANP 的數量大于 5,性能就不會繼續增加,甚至開始下降。這背后的原因可能是:每個句子最多包含5個意見目標,所以當ANPs的數量大于意見目標的最大數量時會帶來一些噪音。
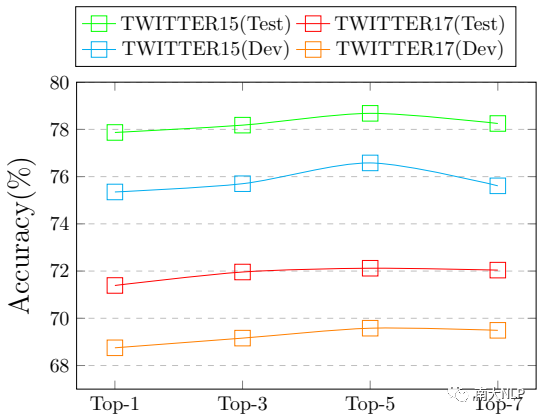
圖5:不同數量 ANPs 對KEF-TomBERT的影響
05
案例分析
為了更好地理解視覺注意力增強器 (VAE) 和情感預測增強器 (SPE) 的優勢,我們從 Twitter 數據集中隨機選擇一些樣本進行案例研究。
視覺注意力增強器的影響
如圖 6(a) 所示,基礎模型 TomBERT 錯誤地預測了意見目標“Korkie”的情感。這是合理的因為我們發現 TomBERT關注了與意見目標無關的視覺線索(由黃色邊界框突出顯示)。在將 VAE 集成到 TomBERT 之后,TomBERT+VAE將細粒度的意見目標“Korkie”映射到 ANPs 中的粗粒度名詞“man”。在名詞“man”的幫助下,TomBERT+VAE 成功地捕捉到了目標相關的視覺線索(由紅色邊界框突出顯示),從而給出了正確的預測。
情感預測增強器的影響
如圖 6(b) 和6(c) 所示,雖然 TomBERT+VAE 準確地捕捉到了意見目標的相應視覺表征(即笑臉),但微笑表情的多樣化增加了情感預測的難度,因此 TomBERT +VAE 錯誤地預測了圖 6(c) 中“Sammy”的情感。在將 SPE 集成到 TomBERT+VAE 之后,KEFTomBERT 將不同的笑臉映射到同一個形容詞“happy”。顯然,KEF-TomBERT 更容易學習這些“happy”和情感標簽“positive”之間的映射函數,從而做出正確的預測。
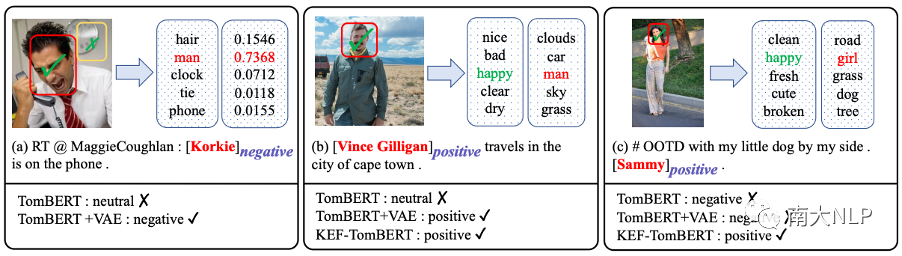
圖6:案例分析
06
總結
在本文中,我們為 TMSC 任務提出了一種新穎的知識增強框架 (KEF)。具體來說,在 ANPs 的幫助下,我們設計了兩個新穎的知識增強器,視覺注意力增強器和情感預測增強器,以提高 TMSC 任務的視覺注意力能力和情感預測能力。大量實驗的結果表明,我們的框架與其它最先進的方法相比具有更好的性能。進一步的分析也驗證了我們框架的優越性。
在未來,我們希望將我們的想法應用于其他多模態任務,因為從圖片中提取的形容詞-名詞對很容易擴展到其他多模態任務,例如多模態實體鏈接、多模態機器理解和多模態對話生成。
審核編輯:劉清
-
增強器
+關注
關注
1文章
48瀏覽量
8465 -
ANP
+關注
關注
0文章
5瀏覽量
6420
原文標題:COLING2022 | 南大提出:面向目標的多模態情感分類的知識增強框架
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用ad9467-250來采集低頻信號,請問有什么方法來提高sfdr嗎?
如何使用NTAG213單擊一次即可執行多項作?
一種永磁電機用轉子組件制作方法
用ADS1258做了一塊采集卡,請問有比較簡單的測試方法來測試我的采集卡的性能和精度嗎?
實用干貨:降低電流紋波的有效妙招
一種降低VIO/VSLAM系統漂移的新方法
如何有效提高BUCK電路占空比的方法
一種使用LDO簡單電源電路解決方案
基于LSTM神經網絡的情感分析方法
一種簡單高效配置FPGA的方法





 工商網監
工商網監
評論