") 視覺(jué)語(yǔ)言導(dǎo)航領(lǐng)域任務(wù)、方法和未來(lái)方向的綜述
視覺(jué)語(yǔ)言導(dǎo)航領(lǐng)域任務(wù)、方法和未來(lái)方向的綜述

視覺(jué)語(yǔ)言導(dǎo)航(VLN)是一個(gè)新興的研究領(lǐng)域,旨在構(gòu)建一種可以用自然語(yǔ)言與人類交流并在真實(shí)的3D環(huán)境中導(dǎo)航的具身代理,與計(jì)算機(jī)視覺(jué)、自然語(yǔ)言處理和機(jī)器人等研究領(lǐng)域緊密關(guān)聯(lián)。視覺(jué)語(yǔ)言導(dǎo)航任務(wù)要求構(gòu)建的具身代理能夠根據(jù)語(yǔ)言指令推理出導(dǎo)航路徑,然而,稀疏的語(yǔ)言指令數(shù)據(jù)集限制著導(dǎo)航模型的性能,研究者們又提出了一些能夠根據(jù)導(dǎo)航路徑輸出接近于人類標(biāo)注質(zhì)量的語(yǔ)言指令的模型。
本次DISC小編將分享ACL2022和CVPR2022的三篇論文,第一篇論文是一篇綜述,第二篇論文提出了一種監(jiān)督把控當(dāng)前導(dǎo)航進(jìn)程的方法,第三篇文章提出了一套根據(jù)導(dǎo)航路徑自動(dòng)生成描述這條路徑的語(yǔ)言指令的方法。
文章概覽
1.視覺(jué)語(yǔ)言導(dǎo)航:任務(wù)、方法和未來(lái)方向的綜述(Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions)
本文從任務(wù)、評(píng)價(jià)指標(biāo)、方法等方面回顧了當(dāng)前視覺(jué)語(yǔ)言導(dǎo)航研究的進(jìn)展,并介紹了當(dāng)前VLN研究的局限性和未來(lái)工作的機(jī)會(huì)。視覺(jué)語(yǔ)言導(dǎo)航有很多任務(wù)集,難度和任務(wù)設(shè)定各異,視覺(jué)語(yǔ)言導(dǎo)航也涉及許多機(jī)器學(xué)習(xí)相關(guān)的模型方法,本文對(duì)當(dāng)前的一些VLN數(shù)據(jù)集和經(jīng)典方法作了分類介紹。通過(guò)閱讀本文,可以對(duì)視覺(jué)語(yǔ)言導(dǎo)航領(lǐng)域有一個(gè)總體的了解。
2.一次一步:擁有里程碑的長(zhǎng)視界視覺(jué)語(yǔ)言導(dǎo)航(One Step at a Time: Long-Horizon Vision-and-Language Navigation with Milestones)
當(dāng)面對(duì)長(zhǎng)視界視覺(jué)語(yǔ)言導(dǎo)航任務(wù)時(shí),代理很容易忽視部分指令或者困在一個(gè)長(zhǎng)指令的中間部分。為了解決上述問(wèn)題,本文設(shè)計(jì)了一個(gè)模型無(wú)關(guān)的基于里程碑(milestone)的任務(wù)跟蹤器(milestone-based task tracker,M-TRACK)來(lái)指引代理并模擬其進(jìn)程。任務(wù)跟蹤器包含里程碑生成器(milestone builder)和里程碑檢查器(milestone tracker)。在ALFRED數(shù)據(jù)集上,本文的M-TRACK方法應(yīng)用在兩個(gè)經(jīng)典模型上分別提升了33%和52%的未知環(huán)境中成功率。
3.少即是多:從地標(biāo)生成對(duì)齊的語(yǔ)言指令(Less is More: Generating Grounded Navigation Instructions from Landmarks)
本文研究了從360°室內(nèi)全景圖自動(dòng)生成導(dǎo)航指令。現(xiàn)存的語(yǔ)言指令生成器往往擁有較差的視覺(jué)對(duì)齊,這導(dǎo)致了生成指令的過(guò)程主要依賴于語(yǔ)言先驗(yàn)和虛幻的物體。本文提出的MARKY-MT5系統(tǒng)利用視線中的地標(biāo)來(lái)解決這個(gè)問(wèn)題,該系統(tǒng)包含地標(biāo)檢測(cè)器和指令生成器兩個(gè)部分。在R2R數(shù)據(jù)集上,人類尋路員根據(jù)人類標(biāo)注指令尋找導(dǎo)航路徑的成功率為75%,而根據(jù)MARKY-MT5生成的指令尋找導(dǎo)航路徑的成功率仍然有71%,且該指標(biāo)遠(yuǎn)高于根據(jù)其它生成器生成的指令尋找導(dǎo)航路徑的成功率。
動(dòng)機(jī)
近年來(lái),視覺(jué)語(yǔ)言導(dǎo)航領(lǐng)域飛速發(fā)展,越來(lái)越多的導(dǎo)航數(shù)據(jù)集涌現(xiàn),針對(duì)不同設(shè)定的任務(wù)數(shù)據(jù)集,研究者們也設(shè)計(jì)了許多評(píng)測(cè)指標(biāo),不同的研究社區(qū)也在VLN領(lǐng)域提出多種多樣的模型方法。本文希望對(duì)當(dāng)前現(xiàn)有的一些任務(wù)數(shù)據(jù)集和VLN方法進(jìn)行總結(jié)分類,為未來(lái)VLN研究方向提出一些建議,希望能夠?yàn)閂LN研究社區(qū)提供一個(gè)詳盡的參考。
任務(wù)和數(shù)據(jù)集
導(dǎo)航代理解釋自然語(yǔ)言指令的能力使得VLN有別于視覺(jué)導(dǎo)航。本文根據(jù)交流復(fù)雜度和任務(wù)目標(biāo)難度兩個(gè)維度來(lái)對(duì)現(xiàn)有的VLN數(shù)據(jù)集分類,如表1所示。
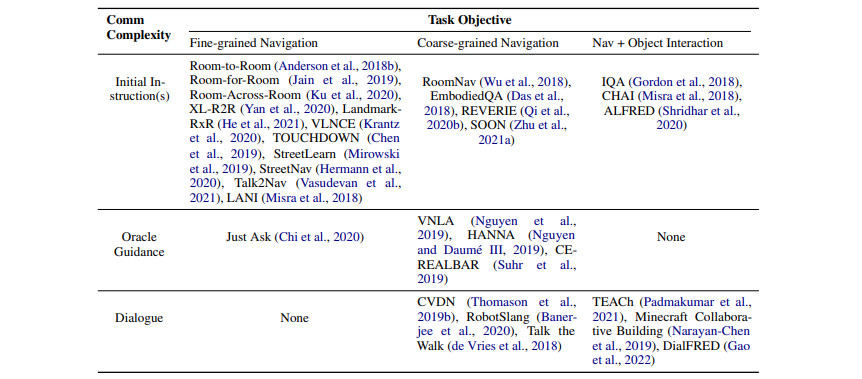
表1:根據(jù)交流復(fù)雜度和任務(wù)目標(biāo)劃分的視覺(jué)語(yǔ)言導(dǎo)航基準(zhǔn)。
交流復(fù)雜度定義了代理與oracle對(duì)話的級(jí)別,本文劃分了三個(gè)復(fù)雜程度遞增的級(jí)別:①代理只需要在導(dǎo)航開(kāi)始前理解一個(gè)初始指標(biāo);②代理在不確定時(shí)可以發(fā)送一個(gè)信號(hào)請(qǐng)求幫助,繼而根據(jù)oracle的指引完成任務(wù);③擁有對(duì)話能力的代理在導(dǎo)航期間可以通過(guò)自然語(yǔ)言的形式詢問(wèn)問(wèn)題并理解oracle的答復(fù)。
任務(wù)目標(biāo)定義代理如何根據(jù)來(lái)自oracle的初始指令實(shí)現(xiàn)其目標(biāo),本文劃分了三個(gè)難度遞增的級(jí)別:①細(xì)粒度導(dǎo)航,代理可以根據(jù)一條詳細(xì)的逐步的路徑描述來(lái)找到目標(biāo);②粗粒度導(dǎo)航,代理需要根據(jù)一條粗略的路徑描述來(lái)找到一個(gè)距離遙遠(yuǎn)的目標(biāo),代理可能需要得到oracle的一些幫助;③導(dǎo)航和物體交互,代理除了推理出一條行進(jìn)路徑,也需要操作環(huán)境中的物體。
評(píng)測(cè)指標(biāo)
面向目標(biāo)的指標(biāo)主要關(guān)注代理和目標(biāo)的接近程度。其中最自然的指標(biāo)是成功率(Success Rate),它衡量代理成功完成任務(wù)的頻率,距離目標(biāo)一定范圍內(nèi)即算成功。目標(biāo)進(jìn)程(Goal Progress)衡量距離目標(biāo)剩余距離的減少。路徑長(zhǎng)度(Path Length)衡量導(dǎo)航路徑的總長(zhǎng)度。最短路徑距離(Shortest-Path Distance)衡量代理的最終位置與目標(biāo)之間的平均距離。路徑加權(quán)成功率(Success weighted by Path Length)同時(shí)考慮成功率和路徑長(zhǎng)度,因?yàn)檫^(guò)長(zhǎng)路徑的成功導(dǎo)航是不被期望的。Oracle導(dǎo)航誤差(Oracle Navigation Error)衡量路徑上最接近目標(biāo)的點(diǎn)到目標(biāo)的距離。Oracle成功率(Oracle Success Rate)衡量路徑上最接近目標(biāo)的點(diǎn)到目標(biāo)的距離是否在一個(gè)閾值內(nèi)。
路徑精確度的指標(biāo)評(píng)估一個(gè)代理在多大程度上遵循期望的路徑。有些任務(wù)要求代理不僅要找到目標(biāo)位置,還要遵循特定的路徑。精確性的衡量的是專家演示中的動(dòng)作序列與智能體軌跡中的動(dòng)作序列之間的匹配程度。長(zhǎng)度分?jǐn)?shù)加權(quán)的覆蓋(Coverage weighted by LS)由路徑覆蓋(Path Coverage)和長(zhǎng)度分?jǐn)?shù)(Length Score)相乘得到,其衡量代理路徑和參考路徑的接近程度。歸一化動(dòng)態(tài)時(shí)間規(guī)整(Normalized Dynamic Time Warping)懲罰偏離參考路徑的偏差,以計(jì)算兩條路徑之間的匹配。歸一化動(dòng)態(tài)時(shí)間規(guī)則加權(quán)的成功(Success weighted by normalized Dynamic Time Warping)則進(jìn)一步將nDTW限制為僅成功的片段,以同時(shí)衡量成功和精確度。
VLN方法
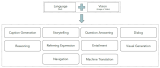
如圖1所示,本文將現(xiàn)存的VLN方法大致分類為表示學(xué)習(xí)、動(dòng)作決策學(xué)習(xí)、數(shù)據(jù)中心學(xué)習(xí)、提前探索等。表示學(xué)習(xí)主要幫助代理理解多模態(tài)的輸入(視覺(jué)、語(yǔ)言、動(dòng)作)及其之間的關(guān)系。由于導(dǎo)航依賴?yán)鄯e的動(dòng)作序列,動(dòng)作決策學(xué)習(xí)可以幫助代理做出更好的決策。另外,VLN任務(wù)的數(shù)據(jù)集仍然不夠大,收集VLN訓(xùn)練數(shù)據(jù)是昂貴且耗時(shí)的。因此,數(shù)據(jù)中心方法利用現(xiàn)有數(shù)據(jù)集,創(chuàng)造更多盡可能高質(zhì)量的訓(xùn)練數(shù)據(jù),提升模型表現(xiàn)。提前探索可以幫助代理適應(yīng)事先未見(jiàn)過(guò)的環(huán)境,提升代理泛化能力,降低代理在已知環(huán)境和未知環(huán)境中的表現(xiàn)差距。
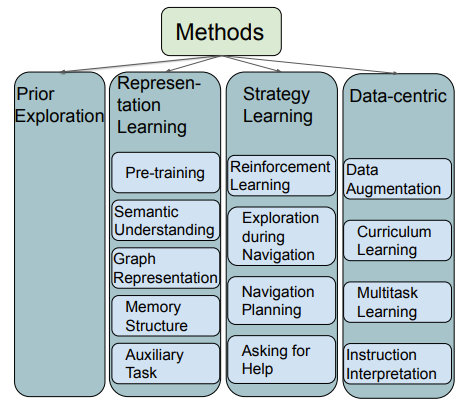
圖1:VLN方法分類。各方法間可能有交集。
表示學(xué)習(xí)
視覺(jué)語(yǔ)言預(yù)訓(xùn)練模型可以提供好的文本和視覺(jué)聯(lián)合表示,使得代理更好地兼顧理解語(yǔ)言指令和環(huán)境觀察。研究者也探索專屬于VLN領(lǐng)域的預(yù)訓(xùn)練,采用VLN領(lǐng)域特定的大規(guī)模預(yù)訓(xùn)練數(shù)據(jù)和針對(duì)VLN任務(wù)設(shè)計(jì)的特定預(yù)訓(xùn)練任務(wù),如PREVALENT、Airbert等。
語(yǔ)義理解可以獲取VLN任務(wù)中重要特征的知識(shí),同時(shí)高層語(yǔ)義表示也能提升代理在未知環(huán)境中的表現(xiàn)。語(yǔ)義理解包括模態(tài)內(nèi)和模態(tài)間的語(yǔ)義理解。
圖表示可以抽取獲得語(yǔ)言指令和環(huán)境觀察中的結(jié)構(gòu)化知識(shí),這為導(dǎo)航提供了顯式的語(yǔ)義關(guān)系。圖可以編碼文本和視覺(jué)之間的關(guān)系,記錄導(dǎo)航過(guò)程中的位置信息等。
記憶結(jié)構(gòu)可以幫助代理高效地利用逐漸累積的導(dǎo)航歷史信息。有些方法利用記憶單元,如LSTM、循環(huán)的信息狀態(tài)等;有些方法建立一個(gè)獨(dú)立的記憶模型來(lái)存儲(chǔ)相關(guān)信息。
輔助任務(wù)在不需要額外標(biāo)簽的情況下幫助代理更好地理解環(huán)境和其自身所處的狀態(tài),這往往需要引進(jìn)額外的損失函數(shù)。一般的輔助任務(wù)有解釋其先前的動(dòng)作、預(yù)測(cè)未來(lái)決策的信息、預(yù)測(cè)當(dāng)前任務(wù)的完成狀態(tài)和視覺(jué)文本的匹配程度等。
動(dòng)作決策學(xué)習(xí)
VLN是一個(gè)動(dòng)作序列決策問(wèn)題并且可以被建模成一個(gè)馬爾科夫決策過(guò)程。所以強(qiáng)化學(xué)習(xí)方法可以使代理學(xué)得更好的策略。一個(gè)應(yīng)用強(qiáng)化學(xué)習(xí)的難點(diǎn)在于很難知道一個(gè)動(dòng)作對(duì)最終任務(wù)完成的貢獻(xiàn)程度,因此無(wú)法決定獎(jiǎng)勵(lì)或懲罰。對(duì)此,人們提出了RCM模型和利用指令和關(guān)鍵地標(biāo)之間的局部對(duì)齊作為獎(jiǎng)勵(lì)等方法。
邊導(dǎo)航邊探索可以使代理對(duì)狀態(tài)空間有一個(gè)更好的了解。探索和開(kāi)發(fā)之間存在一個(gè)權(quán)衡,隨著更多的探索,代理以更長(zhǎng)的路徑和更長(zhǎng)的導(dǎo)航時(shí)間為代價(jià)獲得了更好的表現(xiàn),因此代理需要決定探索的時(shí)間和深度。
導(dǎo)航規(guī)劃會(huì)帶來(lái)更好的行動(dòng)策略,從視覺(jué)角度來(lái)看,預(yù)測(cè)路徑點(diǎn)、下一個(gè)狀態(tài)和獎(jiǎng)勵(lì)、生成未來(lái)的觀察結(jié)果和整合鄰居視圖都已經(jīng)被證明是有效的。
代理在不確定下一個(gè)動(dòng)作時(shí)可以詢問(wèn)幫助,可以利用動(dòng)作概率分布或者獨(dú)立訓(xùn)練的模型來(lái)決定是否詢問(wèn),詢問(wèn)方式可以是發(fā)送一個(gè)信號(hào)或者使用自然語(yǔ)言。
數(shù)據(jù)中心學(xué)習(xí)
VLN領(lǐng)域的數(shù)據(jù)增強(qiáng)主要包含路徑指令對(duì)增強(qiáng)和環(huán)境增強(qiáng)。擴(kuò)增的路徑指令對(duì)可以直接作為額外的訓(xùn)練樣本。生成更多的環(huán)境數(shù)據(jù)不僅幫助擴(kuò)增路徑樣本,還可以避免在已知環(huán)境中的過(guò)擬合問(wèn)題,生成額外環(huán)境數(shù)據(jù)一般采用隨機(jī)遮蓋不同視點(diǎn)的相同視覺(jué)特征。
課程學(xué)習(xí)的大致思想是在訓(xùn)練過(guò)程中逐漸增大任務(wù)的難度,即先用低難度的樣本訓(xùn)練代理。
多任務(wù)學(xué)習(xí)引入不同的VLN任務(wù)進(jìn)行訓(xùn)練,促進(jìn)跨任務(wù)知識(shí)轉(zhuǎn)移。
對(duì)一條語(yǔ)言指令進(jìn)行多次不同的指令解釋可以使代理更好地理解其目標(biāo)。
提前探索
提前探索方法允許代理去觀察和適應(yīng)未知環(huán)境,從而縮小已知和未知環(huán)境中的表現(xiàn)差距。一些經(jīng)典方法有利用測(cè)試環(huán)境來(lái)取樣和擴(kuò)增路徑樣本來(lái)適應(yīng)未知環(huán)境、利用圖結(jié)構(gòu)來(lái)提前建立未知環(huán)境的信息概況等。
未來(lái)方向
鑒于現(xiàn)在的任務(wù)設(shè)定在環(huán)境中都只有一個(gè)代理,未來(lái)可以關(guān)注多代理協(xié)作的視覺(jué)語(yǔ)言導(dǎo)航任務(wù);其次,希望未來(lái)的任務(wù)研究更貼合現(xiàn)實(shí)情況,比如環(huán)境中可能會(huì)有人類在改變環(huán)境的狀態(tài),而不是只有導(dǎo)航代理的存在;另外,希望視覺(jué)語(yǔ)言導(dǎo)航任務(wù)的研究能關(guān)注到數(shù)據(jù)隱私和道德的問(wèn)題;最后,由于當(dāng)前的訓(xùn)練數(shù)據(jù)集基本來(lái)自于歐美國(guó)家,訓(xùn)練多文化的代理也是重要的。

動(dòng)機(jī)
近些年,許多VLN模型取得了巨大的成功,尤其是在短視界(short-horizon)問(wèn)題上。但當(dāng)面對(duì)到擁有很長(zhǎng)動(dòng)作序列的長(zhǎng)視界(long-horizon)問(wèn)題時(shí),許多模型的表現(xiàn)仍然讓人不夠滿意。具體來(lái)說(shuō),本文作者觀察到在一些實(shí)驗(yàn)中,代理會(huì)跳過(guò)部分子任務(wù)不做或者在一個(gè)已完成的子任務(wù)內(nèi)原地徘徊而無(wú)法去執(zhí)行下一個(gè)子任務(wù),這些都說(shuō)明代理在處理長(zhǎng)序列任務(wù)時(shí),缺乏對(duì)其所處進(jìn)程的認(rèn)識(shí)。本文嘗試構(gòu)建里程碑(milestone)來(lái)模擬任務(wù)進(jìn)程進(jìn)度,設(shè)計(jì)了任務(wù)跟蹤器M-TRACK。
M-TRACK方法
本文設(shè)計(jì)任務(wù)跟蹤器(M-TRACK),它在子任務(wù)中跟蹤任務(wù)進(jìn)度,只有代理達(dá)到一個(gè)子任務(wù)的里程碑時(shí)才能進(jìn)入下一個(gè)子任務(wù)。M-TRACK包含里程碑生成器(milestone builder)和里程碑檢查器(milestone checker)。里程碑生成器將指令劃分為導(dǎo)航(Navigation)里程碑和交互(Interaction)里程碑,代理需要一步步完成這些里程碑。里程碑檢查器系統(tǒng)地檢查代理在當(dāng)前里程碑中的進(jìn)度,并確定何時(shí)繼續(xù)到下一個(gè)里程碑。
下圖展示了一個(gè)ALFRED任務(wù),其由一個(gè)整體目標(biāo)和六個(gè)子任務(wù)組成。每張圖中的藍(lán)色/紅色文本框就是該方法從各子任務(wù)中抽取出的導(dǎo)航/交互里程碑。一個(gè)代理在處理下一個(gè)子任務(wù)之前需要達(dá)到當(dāng)前所處子任務(wù)的里程碑條件。

圖2:M-TRACK方法的示意。
對(duì)于長(zhǎng)視界(long-horizon)VLN任務(wù),代理往往需要按照一個(gè)特定的順序完成多個(gè)子任務(wù)從而完成一個(gè)完整任務(wù)。更具體地,完整任務(wù)的語(yǔ)言指令中的每一句指令可以視作一個(gè)子任務(wù)的語(yǔ)言指令。
里程碑生成器(milestone builder)使用命名實(shí)體識(shí)別技術(shù)為每一個(gè)子任務(wù)從其語(yǔ)言指令中提取出里程碑作為指導(dǎo)。里程碑由一個(gè)形如的元組表示。舉個(gè)例子,對(duì)于指令"Turn to the left and face the toilet",里程碑生成器將輸出標(biāo)簽,而對(duì)于指令"Pick the soap up from the back of the toilet",里程碑生成器將輸出標(biāo)簽。如果一個(gè)子任務(wù)擁有多個(gè)要求交互的物體,生成器輸出的標(biāo)簽需要包含所有。本文采用BERT-CRF模型實(shí)現(xiàn)里程碑生成器,并用ALFRED模擬器的元數(shù)據(jù)組成訓(xùn)練數(shù)據(jù)。
里程碑檢查器(milestone checker)確認(rèn)代理是否達(dá)到一個(gè)里程碑。一個(gè)導(dǎo)航里程碑的達(dá)成條件是目標(biāo)物體在視野內(nèi)且代理可以觸碰到,一個(gè)交互里程碑的達(dá)成條件是目標(biāo)物體在代理可以觸碰到的視野內(nèi)并且代理完成了與該目標(biāo)物體的交互。
另外,M-TRACK方法在代理執(zhí)行預(yù)測(cè)動(dòng)作前,主動(dòng)應(yīng)用里程碑檢查器進(jìn)行檢查。這可以避免代理與一個(gè)錯(cuò)誤的物體交互后進(jìn)行額外的糾正錯(cuò)誤步驟。
如圖3所示,里程碑檢查器在每一步動(dòng)作執(zhí)行完畢后檢查當(dāng)前里程碑是否達(dá)成,一旦達(dá)成則向代理輸入下一個(gè)子任務(wù)的語(yǔ)言指令;同時(shí),檢查器在交互動(dòng)作執(zhí)行之前,確認(rèn)交互物體目標(biāo)是否為交互里程碑中涉及的物體目標(biāo),若不是則不執(zhí)行動(dòng)作并挑選下一個(gè)概率最高的動(dòng)作執(zhí)行。
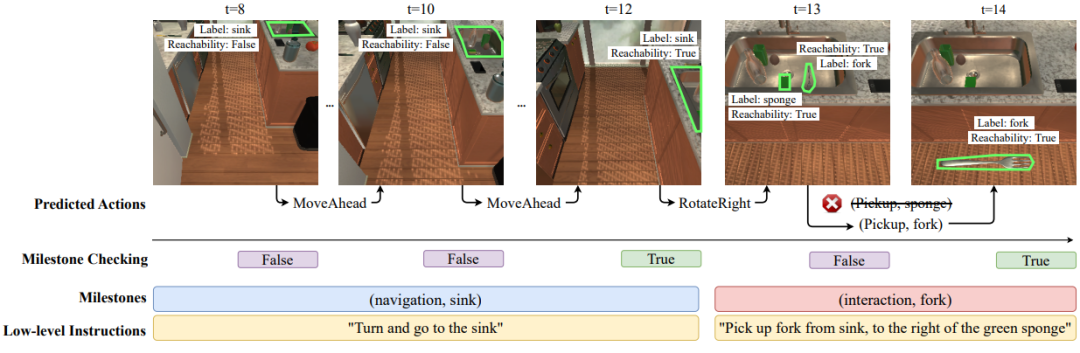
圖3:里程碑檢查過(guò)程的示意圖。
值得一提的是,M-TRACK方法只需要用到語(yǔ)言指令、視覺(jué)輸入和代理動(dòng)作,因此該方法是與模型無(wú)關(guān)的,即可以應(yīng)用到任何VLN模型上。
實(shí)驗(yàn)結(jié)果
本文在ALFRED數(shù)據(jù)集上驗(yàn)證M-TRACK方法。ALFRED數(shù)據(jù)集收集了8055條完成家務(wù)任務(wù)的專家路徑,其帶有25743條標(biāo)注的語(yǔ)言指令。驗(yàn)證集和測(cè)試集會(huì)被進(jìn)一步劃分為1)在訓(xùn)練過(guò)程中能看到的環(huán)境Seen和2)新的環(huán)境Unseen。
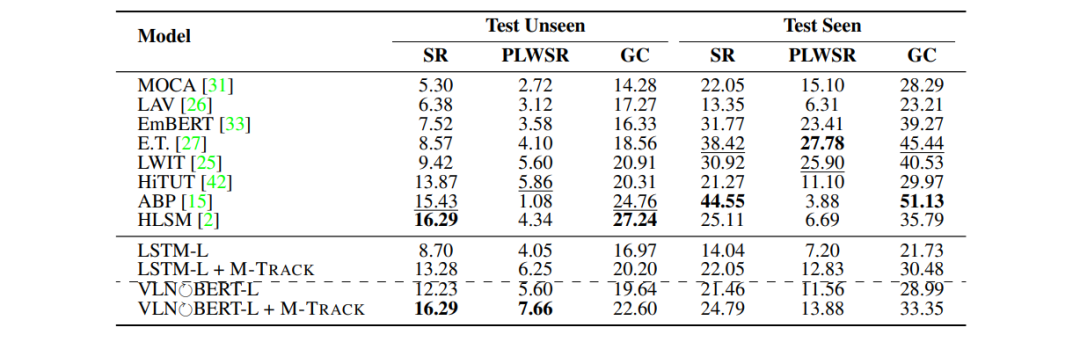
表2:ALFRED測(cè)試集上的表現(xiàn)。
如表2所示,M-TRACK方法分別應(yīng)用在LSTM模型和VLN-BERT模型上后,均顯著提高了兩模型的各指標(biāo)表現(xiàn),使得兩模型的性能優(yōu)于其它大多數(shù)模型。另外,使用M-TRACK方法的VLN-BERT模型在Unseen環(huán)境中的SR和PLWSR指標(biāo)上達(dá)到了最好表現(xiàn)。

動(dòng)機(jī)
訓(xùn)練數(shù)據(jù)稀疏一直是視覺(jué)語(yǔ)言導(dǎo)航領(lǐng)域的一個(gè)問(wèn)題,研究自動(dòng)生成高質(zhì)量的語(yǔ)言指令的模型方法十分重要。自動(dòng)生成語(yǔ)言指令的一個(gè)經(jīng)典模型是Speaker-Follower模型,但其表現(xiàn)仍然不夠令人滿意。本文觀察到人類標(biāo)注員在寫語(yǔ)言指令時(shí)僅參考了一小部分他們看到的物體,這使得學(xué)習(xí)視覺(jué)輸入和文本輸出之間的精確映射變得更加困難。換一句話說(shuō),輸入中涉及過(guò)多的視覺(jué)信息可能反而導(dǎo)致更差的性能,因?yàn)槟P蜁?huì)學(xué)到很多虛假的相關(guān)性。另外,本文還注意到地標(biāo)說(shuō)明是語(yǔ)言指令中的重要組成部分。綜上,本文提出了一套僅利用地標(biāo)和動(dòng)作序列等較少信息就生成語(yǔ)言指令的流程方法。
制作地標(biāo)數(shù)據(jù)集
MARKY-MT5第一階段識(shí)別視覺(jué)地標(biāo)作為第二階段指令生成器的輸入,這需要一個(gè)地標(biāo)識(shí)別器,而地標(biāo)識(shí)別器的訓(xùn)練需要制作地標(biāo)數(shù)據(jù)集,如圖4所示。

圖4:從RxR數(shù)據(jù)集制作的地標(biāo)數(shù)據(jù)集。
第一步是從語(yǔ)言指令中抽取地標(biāo)詞組,如圖5所示。第二步是將地標(biāo)詞組匹配到對(duì)應(yīng)的視覺(jué)圖像,對(duì)于一條語(yǔ)言指令為了匹配地標(biāo)詞組和圖像序列,建模矩陣,其中表示詞組和圖像的匹配度。
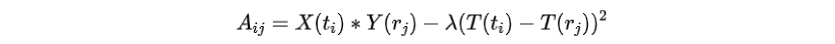
其中計(jì)算MURAL文本表征,計(jì)算MURAL圖像表征,返回時(shí)間戳。第三步是將圖像中的地標(biāo)居中,以更好地與地標(biāo)詞組對(duì)齊。

圖5:地標(biāo)數(shù)據(jù)集制作過(guò)程。
地標(biāo)檢測(cè)
本文采用CenterNet模型作為地標(biāo)檢測(cè)器,輸入形式為360°全景圖的序列,同時(shí)每個(gè)全景圖上標(biāo)注了入口和出口方向,如圖6所示,輸出即為檢測(cè)出的系列地標(biāo)。
在訓(xùn)練時(shí),使用之前從RxR數(shù)據(jù)集制作的地標(biāo)數(shù)據(jù)集。在推理時(shí),聚集每一個(gè)視點(diǎn)全景圖的分?jǐn)?shù)最高的3個(gè)地標(biāo),最終返回T個(gè)分?jǐn)?shù)最高的地標(biāo),T為路徑長(zhǎng)度。
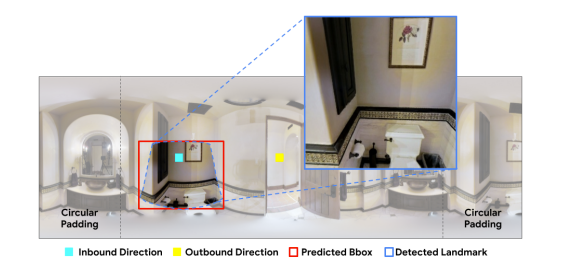
圖6:地標(biāo)檢測(cè)器的全景輸入形式。
指令生成
本文通過(guò)將選定地標(biāo)的視覺(jué)表示插入到一個(gè)模板式的英文文本序列中,以描述每個(gè)地標(biāo)的方向和穿越路線所需的動(dòng)作,從而形成模型的輸入。如圖7所示,對(duì)于每張有檢測(cè)出地標(biāo)的視點(diǎn)全景圖,用地標(biāo)方向和當(dāng)前視點(diǎn)采用的前進(jìn)方向,配合地標(biāo)和當(dāng)前視點(diǎn)的出口視圖,交織成一句語(yǔ)言指令,以此類推,直至描述完所有符合要求的視點(diǎn)全景圖。
本文采用的指令生成模型基于mT5模型,這是T5模型的多語(yǔ)言變體。
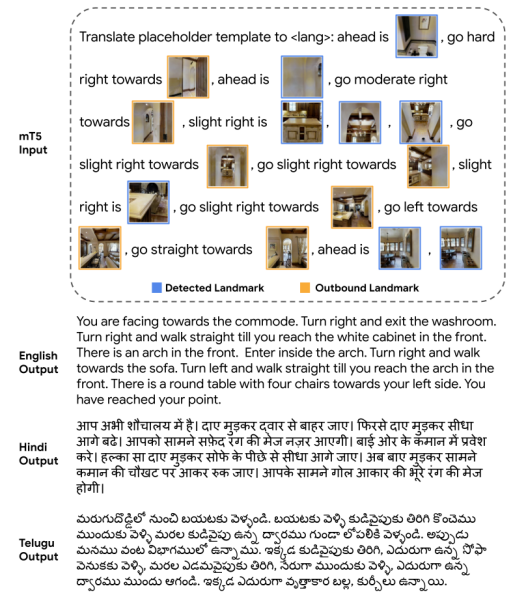
圖7:輸入模板和指令生成器的多語(yǔ)言輸出。
實(shí)驗(yàn)結(jié)果
MARKY-MT5模型在RxR數(shù)據(jù)集上訓(xùn)練,分別在RxR和R2R數(shù)據(jù)集上評(píng)測(cè)。評(píng)測(cè)方法是讓人類去分別根據(jù)人類標(biāo)注和模型生成的語(yǔ)言指令,在虛擬環(huán)境中操作完成導(dǎo)航,完成導(dǎo)航的成功率越高,說(shuō)明語(yǔ)言指令的質(zhì)量越高。

表3:人類尋路員在R2R未知驗(yàn)證集上的表現(xiàn)。

表4:人類尋路員在RxR未知驗(yàn)證集上的表現(xiàn)。
綜上, 可以發(fā)現(xiàn)在較簡(jiǎn)單的R2R數(shù)據(jù)集上,MARKY-MT5系統(tǒng)的表現(xiàn)十分接近于人類標(biāo)注的語(yǔ)言指令,同時(shí)又遠(yuǎn)高于其它系統(tǒng)模型生成的語(yǔ)言指令質(zhì)量。而在較復(fù)雜的RxR數(shù)據(jù)集上,MARKY-MT5模型和人類標(biāo)注的語(yǔ)言指令質(zhì)量存在一定的差距。
總結(jié)
本次 Fudan DISC 小編分享的三篇論文從不同的角度研究了視覺(jué)語(yǔ)言導(dǎo)航領(lǐng)域。第一篇工作主要是綜述前人的工作,希望對(duì)視覺(jué)語(yǔ)言導(dǎo)航的目前進(jìn)展做出一個(gè)歸納整理,無(wú)論是對(duì)剛?cè)腴T的人,還是對(duì)在這個(gè)領(lǐng)域略有心得的人,都是一個(gè)不錯(cuò)的參考啟發(fā)資料。第二篇工作主要是意識(shí)到了導(dǎo)航代理在把握任務(wù)進(jìn)程方面的難處,并提出了一種可行的進(jìn)程監(jiān)督方式。第三篇工作在語(yǔ)言指令生成方面做出了突破性進(jìn)展,通過(guò)精簡(jiǎn)視覺(jué)輸入的信息,僅利用關(guān)鍵性地標(biāo)和方向動(dòng)作來(lái)生成語(yǔ)言指令,實(shí)驗(yàn)結(jié)果達(dá)到了SOTA結(jié)果。
-
導(dǎo)航
+關(guān)注
關(guān)注
7文章
555瀏覽量
43190 -
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
9文章
1709瀏覽量
46791 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
292瀏覽量
13658
原文標(biāo)題:ACL & CVPR 2022 | 逐步語(yǔ)言指導(dǎo)和導(dǎo)航指令生成最新進(jìn)展
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
一種在視覺(jué)語(yǔ)言導(dǎo)航任務(wù)中提出的新方法,來(lái)探索未知環(huán)境
【大語(yǔ)言模型:原理與工程實(shí)踐】核心技術(shù)綜述
基于方向引導(dǎo)優(yōu)化的主動(dòng)視覺(jué)導(dǎo)航參量計(jì)算方法
橋接視覺(jué)與語(yǔ)言的研究綜述
自然語(yǔ)言處理是人工智能領(lǐng)域中的一個(gè)重要方向
視覺(jué)問(wèn)答與對(duì)話任務(wù)研究綜述

基于視覺(jué)/慣導(dǎo)的無(wú)人機(jī)組合導(dǎo)航算法綜述
ACL2021的跨視覺(jué)語(yǔ)言模態(tài)論文之跨視覺(jué)語(yǔ)言模態(tài)任務(wù)與方法
利用視覺(jué)+語(yǔ)言數(shù)據(jù)增強(qiáng)視覺(jué)特征
多維度剖析視覺(jué)-語(yǔ)言訓(xùn)練的技術(shù)路線
小樣本學(xué)習(xí)領(lǐng)域的未來(lái)發(fā)展方向

ICCV 2023 | 面向視覺(jué)-語(yǔ)言導(dǎo)航的實(shí)體-標(biāo)志物對(duì)齊自適應(yīng)預(yù)訓(xùn)練方法

基于視覺(jué)語(yǔ)言模型的導(dǎo)航框架VLMnav
Aux-Think打破視覺(jué)語(yǔ)言導(dǎo)航任務(wù)的常規(guī)推理范式





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論