") 使用NVIDIA數(shù)學(xué)庫加速GPU應(yīng)用程序
使用NVIDIA數(shù)學(xué)庫加速GPU應(yīng)用程序
加速 GPU 應(yīng)用程序的主要方法有三種:編譯器指令、編程語言和預(yù)編程庫。編譯器指令,例如 OpenACC a 允許您順利地將代碼移植到 GPU 以使用基于指令的編程模型進行加速。雖然它易于使用,但在某些情況下可能無法提供最佳性能。
編程語言,例如 CUDA C 和 C ++ 在加速應(yīng)用程序時為您提供更大的靈活性,但用戶也有責(zé)任編寫代碼,利用新的硬件功能在最新的硬件上實現(xiàn)最佳性能。這就是預(yù)編程庫填補空白的地方。
除了增強代碼的可重用性外,還可以使用 NVIDIA 數(shù)學(xué)庫 優(yōu)化以充分利用 GPU 硬件,獲得最大的性能增益。如果您正在尋找一種簡單的方法來加速應(yīng)用程序,請繼續(xù)閱讀,了解如何使用庫來提高應(yīng)用程序的性能。
NVIDIA 數(shù)學(xué)庫,作為 CUDA 工具包 和 高性能計算( HPC )軟件開發(fā)工具包( SDK ) ,提供各種計算密集型應(yīng)用程序中遇到的函數(shù)的高質(zhì)量實現(xiàn)。這些應(yīng)用包括機器學(xué)習(xí)、深度學(xué)習(xí)、分子動力學(xué)、計算流體動力學(xué)( CFD )、計算化學(xué)、醫(yī)學(xué)成像和地震勘探等領(lǐng)域。
這些庫旨在取代常見的 CPU 庫,如 OpenBLAS 、 LAPACK 和 Intel MKL ,并加速上的應(yīng)用程序 NVIDIA GPU 代碼更改最少。為了展示這個過程,我們創(chuàng)建了一個雙精度通用矩陣乘法( DGEMM )功能的示例,以比較 cuBLAS 與 OpenBLAS 的性能。
下面的代碼示例演示了 OpenBLAS DGEMM 調(diào)用的使用。
// Init Data
…
// Execute GEMM
cblas_dgemm(CblasColMajor, CblasNoTrans, CblasTrans, m, n, k, alpha, A.data(), lda, B.data(), ldb, beta, C.data(), ldc);
下面的代碼示例 2 顯示了 cuBLAS dgemm 調(diào)用。
// Init Data
…
// Data movement to GPU
…
// Execute GEMM
cublasDgemm(cublasH, CUBLAS_OP_N, CUBLAS_OP_T, m, n, k, &alpha, d_A, lda, d_B, ldb, &beta, d_C, ldc));
如上面的示例所示,您可以簡單地添加 OpenBLAS CPU 代碼并用 cuBLAS API 函數(shù)替換。 請參閱 cuBLAS 和 OpenBLAS 示例的完整代碼 該 cuBLAS 示例在 NVIDIA ( R ) V100 張量核 GPU 上運行,速度提高了近 20 倍。下圖顯示了運行這些示例時的加速比和規(guī)格。
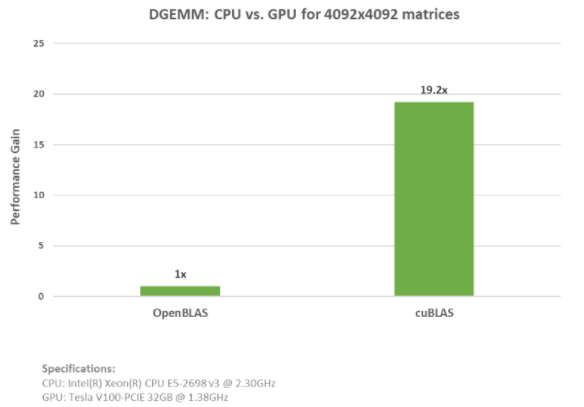
圖 1.在 GPU 上用 cuBLAS API 函數(shù)替換 OpenBLAS CPU 代碼,在 CPU 和 GPU 上, DGEMM 計算的速度提高了 19.2 倍,其中 a 、 B 和 C 矩陣是 4K x 4K 矩陣。
有趣的事實:這些庫在更高級別的 Python API 中調(diào)用,例如 cuPy , cuDNN 和 RAPIDS ,因此,如果您有這些方面的經(jīng)驗,那么您已經(jīng)在使用這些 NVIDIA 數(shù)學(xué)庫。
這篇文章的其余部分涵蓋了所有可用的數(shù)學(xué)庫。
與純 CPU 替代方案相比,提供了更好的性能
有許多 NVIDIA 數(shù)學(xué)庫可以利用,從 GPU 加速的 BLAS 實現(xiàn)到隨機數(shù)生成。請看下面的 NVIDIA 數(shù)學(xué)庫概述,了解如何開始輕松提高應(yīng)用程序的性能。
用 cuBLAS 加速基本線性代數(shù)子程序
廣義矩陣乘法是人工智能和科學(xué)計算中最常用的基本線性代數(shù)子程序之一。 GEMM 還構(gòu)成了深度學(xué)習(xí)框架的基礎(chǔ)模塊。要了解有關(guān)在深度學(xué)習(xí)框架中使用 GEMM 的更多信息,請參閱 為什么 GEMM 是深度學(xué)習(xí)的核心 。
這個 cuBLAS 是 BLAS 的一種實現(xiàn),它利用 GPU 功能實現(xiàn)了極大的速度提升。它包括用于執(zhí)行向量和矩陣運算的例程,例如點積(級別 1 )、向量加法(級別 2 )和矩陣乘法(級別 3 )。
此外,如果您想并行化矩陣乘法, cuBLAS 支持多功能批量 GEMM ,可用于張量計算、機器學(xué)習(xí)和 LAPACK 。有關(guān)提高機器學(xué)習(xí)和張量收縮效率的更多詳細信息,請參閱 CPU 和 GPU 上具有擴展 BLAS 核的張量收縮 。
古巴文字
如果問題太大,無法安裝在 GPU 上,或者您的應(yīng)用程序需要單節(jié)點、多 GPU 支持, 古巴文字 是一個很好的選擇。 cuBLASXt 允許混合 CPU- GPU 計算,并支持執(zhí)行矩陣到矩陣操作的 BLAS 級別 3 操作,例如執(zhí)行厄米秩更新的herk。
cuBLASLt
cuBLASLt 是一個覆蓋 GEMM 的輕量級庫。 cuBLASLt 使用融合內(nèi)核來加速應(yīng)用程序,將兩個或多個內(nèi)核“組合”為單個內(nèi)核,從而允許重用數(shù)據(jù)并減少數(shù)據(jù)移動。 cuBLASLt 還允許用戶設(shè)置尾聲的后處理選項(應(yīng)用偏置,然后重新魯變換或?qū)斎刖仃噾?yīng)用偏置梯度)。
Cubrasmg : CUDA 數(shù)學(xué)庫早期訪問程序
對于大規(guī)模問題,請查看 Cubrasmg 以獲得最先進的多 GPU 、多節(jié)點矩陣乘法支持。它目前是 CUDA 數(shù)學(xué)庫早期訪問程序的一部分。 申請訪問權(quán)限。
用 cuSPARSE 處理稀疏矩陣
稀疏矩陣、密集矩陣乘法( SpMM )是機器學(xué)習(xí)、深度學(xué)習(xí)、 CFD 和地震勘探以及經(jīng)濟、圖形和數(shù)據(jù)分析中許多復(fù)雜算法的基礎(chǔ)。有效處理稀疏矩陣對于許多科學(xué)模擬至關(guān)重要。
神經(jīng)網(wǎng)絡(luò)規(guī)模的不斷擴大以及由此產(chǎn)生的成本和資源的增加導(dǎo)致了稀疏化的需要。稀疏性在深度學(xué)習(xí)訓(xùn)練和推理中都得到了普及,以優(yōu)化資源的使用。有關(guān)這一思想流派的更多信息以及對庫(如 cuSPARSE )的需求,請參閱 深度神經(jīng)網(wǎng)絡(luò)稀疏性的未來 。
cuSPARSE 提供一組用于處理稀疏矩陣的基本線性代數(shù)子程序,這些子程序可用于構(gòu)建 GPU 加速求解器。庫例程有四類:
級別 1 在稀疏向量和密集向量之間運行,例如兩個向量之間的點積。
級別 2 在稀疏矩陣和密集向量(例如矩陣向量積)之間運行。
第 3 級在稀疏矩陣和一組密集向量(例如矩陣乘積)之間運行。
級別 4 允許不同矩陣格式之間的轉(zhuǎn)換和壓縮稀疏行( CSR )矩陣的壓縮。
cusPARSELt 公司
對于具有計算能力的 cuSPARSE 庫的輕量級版本,可以執(zhí)行稀疏矩陣密集矩陣乘法以及用于修剪和壓縮矩陣的輔助函數(shù),請嘗試 cusPARSELt 。要更好地了解 CUSPASSELT 庫,請參閱 使用 CUSPASSELT 利用 NVIDIA 安培結(jié)構(gòu)稀疏性。
使用割傳感器加速張量應(yīng)用
這個 cuTENSOR 庫 是一個張量線性代數(shù)庫實現(xiàn)。張量是機器學(xué)習(xí)應(yīng)用的核心,是推導(dǎo)應(yīng)用問題控制方程的重要數(shù)學(xué)工具。 cuTENSOR 提供了直接張量收縮、張量約化和元素級張量運算的例程。 cuTENSOR 用于提高深度學(xué)習(xí)訓(xùn)練和推理、計算機視覺、量子化學(xué)和計算物理應(yīng)用中的性能。
切割傳感器
如果您仍然想要 cuTENSOR 功能,但支持可以在單個節(jié)點中跨多 GPU 分布的大張量,例如 DGX A100 , 切割傳感器 是圖書館的首選。它提供了廣泛的混合精度支持,其主要計算例程包括直接張量收縮、張量約化和元素級張量運算。
使用 cuSOLVER 的 GPU 加速 LAPACK 功能
這個 庫索爾弗庫 是一個用于基于 cuBLAS 和 cuSPARSE 庫的線性代數(shù)函數(shù)的高級軟件包。 cuSOLVER 提供了類似 LAPACK 的功能,例如矩陣分解、密集矩陣的三角形求解例程、稀疏最小二乘解算器和特征值解算器。
cuSOLVER 有三個獨立的組件:
cuSolverDN 用于密集矩陣分解。
cuSolverSP 提供了一組基于稀疏 QR 分解的稀疏例程。
cuSolverRF 是一個稀疏重分解包,用于求解具有共享稀疏模式的矩陣序列。
cusOLVERMg 公司
對于 GPU 加速的 ScaLAPACK 特性,考慮對稱特征求解器、 1-D 列塊循環(huán)布局支持以及對 cuSOLVER 特性的單節(jié)點多 GPU 支持 cusOLVERMg 。
庫索爾文普
求解大型線性方程組需要多節(jié)點、多 GPU 支持。以其上下分解和 Cholesky 分解特性而聞名, 庫索爾文普 是一個很好的解決方案。
用 cuRAND 大規(guī)模生成隨機數(shù)
這個 cuRAND 庫 重點介紹通過主機( CPU ) API 或設(shè)備( GPU ) API 上的偽隨機或準隨機數(shù)生成器生成隨機數(shù)。主機 API 可以純粹在主機上生成隨機數(shù)并將其存儲在主機內(nèi)存中,也可以在主機上調(diào)用庫的設(shè)備上生成隨機數(shù),但隨機數(shù)生成發(fā)生在設(shè)備上并存儲在全局內(nèi)存中。
設(shè)備 API 定義了用于設(shè)置隨機數(shù)生成器狀態(tài)和生成隨機數(shù)序列的函數(shù),用戶內(nèi)核可以立即使用這些函數(shù),而無需對全局內(nèi)存進行讀寫。一些基于物理的問題表明需要大規(guī)模隨機數(shù)生成。
蒙特卡洛模擬是 GPU 上隨機數(shù)生成器的一種用例。 在 CUDA Fortran 中開發(fā)基于 GPU 的蒙特卡洛并行偽隨機神經(jīng)網(wǎng)絡(luò) 重點介紹了 cuRAND 在大規(guī)模生成隨機數(shù)中的應(yīng)用。
使用 cuFFT 計算快速傅立葉變換
cuFFT CUDA 快速傅立葉變換( FFT )庫為在 NVIDIA GPU 上計算 FFT 提供了一個簡單的接口。 FFT 是一種分治算法,用于有效計算復(fù)數(shù)或?qū)嵵禂?shù)據(jù)集的離散傅立葉變換。它是計算物理和一般信號處理中應(yīng)用最廣泛的數(shù)值算法之一。
cuFFT 可用于廣泛的應(yīng)用,包括醫(yī)學(xué)成像和流體動力學(xué)。 光聲顯微鏡定量血流成像的并行計算 說明了 cuFFT 在基于物理的應(yīng)用程序中的使用。具有現(xiàn)有 FFTW 應(yīng)用程序的用戶應(yīng)該使用 cuFFTW 輕松地將代碼移植到 NVIDIA GPU 上,只需很少的努力。 cuFFTW 庫提供了 FFTW3 API ,以便于移植現(xiàn)有的 FFTW 應(yīng)用程序。
cuFFTXt
要在單個節(jié)點中跨 GPU 分布 FFT 計算,請檢查 cuFFTXt 。該庫包括幫助用戶在多個 GPU 上操作數(shù)據(jù)和跟蹤數(shù)據(jù)順序的功能,從而可以以最有效的方式處理數(shù)據(jù)。
cuFFTMp
不僅在單個系統(tǒng)中有多 GPU 支持, cuFFTMp 提供跨多個節(jié)點的多 GPU 支持。該庫可用于任何 MPI 應(yīng)用程序,因為它獨立于 MPI 實現(xiàn)的質(zhì)量。它使用 NVSHMEM 這是一個基于 OpenSHMEM 標準的通信庫,專為 NVIDIA GPU 設(shè)計。
cuFFTDx
要通過避免不必要的全局內(nèi)存訪問并允許 FFT 內(nèi)核與其他操作融合來提高性能,請查看 cuFFT 設(shè)備擴展( cuFFTDx ) 作為數(shù)學(xué)庫設(shè)備擴展的一部分,它允許應(yīng)用程序在用戶內(nèi)核內(nèi)計算 FFT 。
使用 CUDA 數(shù)學(xué) API 優(yōu)化標準數(shù)學(xué)函數(shù)
CUDA 數(shù)學(xué) API 是為每種 NVIDIA GPU 架構(gòu)優(yōu)化的標準數(shù)學(xué)函數(shù)的集合。所有 CUDA 庫都依賴于 CUDA 數(shù)學(xué)庫。 CUDA 數(shù)學(xué) API 支持所有 C99 標準浮點和雙精度數(shù)學(xué)函數(shù)、浮點、雙精度和全舍入模式,以及不同的函數(shù),如三角函數(shù)和指數(shù)函數(shù)(cospi、sincos)和其他逆誤差函數(shù)(erfinv、erfcinv)。
使用帶彎刀的 C ++模板自定義代碼
矩陣乘法是許多科學(xué)計算的基礎(chǔ)。這些乘法在深度學(xué)習(xí)算法的有效實現(xiàn)中尤為重要。與庫布拉斯類似, CUDA Templates for Linear Algebra Subroutines (CUTLASS) 包含一組線性代數(shù)例程,用于執(zhí)行有效的計算和縮放。
它結(jié)合了分層分解和數(shù)據(jù)移動的策略,類似于用于實現(xiàn) cuBLAS 和 cuDNN 的策略。然而,與 cuBLAS 不同的是,彎刀越來越模塊化和可重新配置。它將 GEMM 的運動部分分解為基本組件或塊,作為 C ++模板類可用,從而為您定制算法提供了靈活性。
該軟件是流水線的,以隱藏延遲并最大限度地提高數(shù)據(jù)重用。無沖突地訪問共享內(nèi)存,以最大限度地提高數(shù)據(jù)吞吐量,消除內(nèi)存占用,并完全按照您想要的方式設(shè)計應(yīng)用程序。要了解有關(guān)使用 Cutslass 提高應(yīng)用程序性能的更多信息,請參閱 CUDA C 中的快速線性代數(shù)++ 。
使用 AmgX 計算微分方程
AmgX 提供 GPU 加速的 AMG (代數(shù)多重網(wǎng)格)庫,在分布式節(jié)點上的單個 GPU 或多 GPU 上受支持。它允許用戶創(chuàng)建復(fù)雜的嵌套解算器、平滑器和預(yù)條件器。該庫使用不同的平滑器(如塊 Jacobi 、 Gauss-Seidel 和稠密 LU )實現(xiàn)了經(jīng)典和基于聚合的代數(shù)多重網(wǎng)格方法。
該庫還包含預(yù)條件 Krylov 子空間迭代方法,如 PCG 和 BICGStab 。 AmgX 為模擬的計算密集型線性求解器部分提供高達 10 倍的加速度,非常適合隱式非結(jié)構(gòu)方法。
AmgX 是專門為 CFD 應(yīng)用開發(fā)的,可用于能源、物理和核安全等領(lǐng)域。 AmgX 庫的一個實際示例是求解小規(guī)模到大規(guī)模計算問題的泊松方程。
這個 飛蛇模擬示例 顯示了在 GPU 上使用 AmgX 包裝器加速 CFD 代碼時所花費的時間和成本的減少。與一個 12 核 CPU 節(jié)點相比,一個 K20 GPU 節(jié)點上有 300 萬個網(wǎng)格點,速度提高了 21 倍。
開始使用 NVIDIA 數(shù)學(xué)庫
cuBLAS 、 cuRAND 、 cuFFT 、 cuSPARSE 、 cuSOLVER 和 CUDA 數(shù)學(xué)庫都包含在 HPC SDK NVIDIA 和 CUDA 工具包
數(shù)學(xué)庫設(shè)備擴展( cuFFTDx )在 MathDx 20.22
cuTENSOR , cusPARSELt 和 MathDx 可以在上找到 開發(fā)區(qū)
AmgX 和 CUTLASS 在 GitHub 上可用
Cubrasmg 目前是 CUDA 數(shù)學(xué)庫早期訪問程序
關(guān)于作者
Aastha Jhunjhunwala 在獲得卡內(nèi)基梅隆大學(xué)化學(xué)工程碩士學(xué)位后,于 2021 年作為新大學(xué)畢業(yè)生輪換計劃的一部分加入 NVIDIA。她的背景是分子動力學(xué)和機器學(xué)習(xí)。作為 NVIDIA 的解決方案架構(gòu)師,她參與了醫(yī)療保健領(lǐng)域的 HPC 和 DL 工作流。她熱衷于人工智能在計算化學(xué)和藥物發(fā)現(xiàn)中的應(yīng)用。
Gabrielle Talavera 是 NVIDIA 的解決方案架構(gòu)師。她畢業(yè)于內(nèi)華達大學(xué)里諾分校,獲得計算機科學(xué)學(xué)士學(xué)位,并于 2021 年通過新大學(xué)畢業(yè)生輪崗計劃加入 NVIDIA,專注于軟件開發(fā)、網(wǎng)絡(luò)和 HPC。她喜歡向其他人介紹 NVIDIA 必須提供的技術(shù),并幫助客戶加速他們的應(yīng)用程序。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5246瀏覽量
105774 -
gpu
+關(guān)注
關(guān)注
28文章
4912瀏覽量
130661
發(fā)布評論請先 登錄
NVIDIA CUDA深度神經(jīng)網(wǎng)絡(luò)庫實現(xiàn)高性能GPU加速
《CST Studio Suite 2024 GPU加速計算指南》
NVIDIA火熱招聘GPU高性能計算架構(gòu)師
NVIDIA-SMI:監(jiān)控GPU的絕佳起點
GPU加速XenApp/Windows 2016/Office/IE性能會提高嗎
近600個應(yīng)用程序通過NVIDIA GPU實現(xiàn)了提速
VMware和Nvidia將聯(lián)手加速企業(yè)人工智能應(yīng)用程序的開發(fā)
全新NVIDIA Omniverse應(yīng)用程序及連接器介紹
NVIDIA CUDA Toolkit用于創(chuàng)建高性能GPU加速應(yīng)用程序
使用NVIDIA TensorRT部署實時深度學(xué)習(xí)應(yīng)用程序
如何使用NVIDIA Docker部署GPU服務(wù)器應(yīng)用程序
NVIDIA GPU助力加速先進對話式AI技術(shù)

NVIDIA cuBLAS庫加速BLAS的GPU設(shè)計實現(xiàn)
使用 NVIDIA DOCA 2.2 加速數(shù)據(jù)中心工作負載和 AI 應(yīng)用程序





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論