 使用NVIDIA NeMo進行文本規范化和反向文本規范化
使用NVIDIA NeMo進行文本規范化和反向文本規范化

文本規范化( TN )將文本從書面形式轉換為口頭形式,是文本到語音( TTS )之前的一個重要預處理步驟。 TN 確保 TTS 可以處理所有輸入文本,而不會跳過未知符號。例如,“ 123 美元”轉換為“一百二十三美元”
反向文本規范化( ITN )是自動語音識別( ASR )后處理管道的一部分。 ITN 將 ASR 模型輸出轉換為書面形式,以提高文本可讀性。例如, ITN 模塊將 ASR 模型轉錄的“ 123 美元”替換為“ 123 美元。”
ITN 不僅提高了可讀性,還提高了下游任務(如神經機器翻譯或命名實體識別)的性能,因為這些任務在訓練期間使用書面文本。
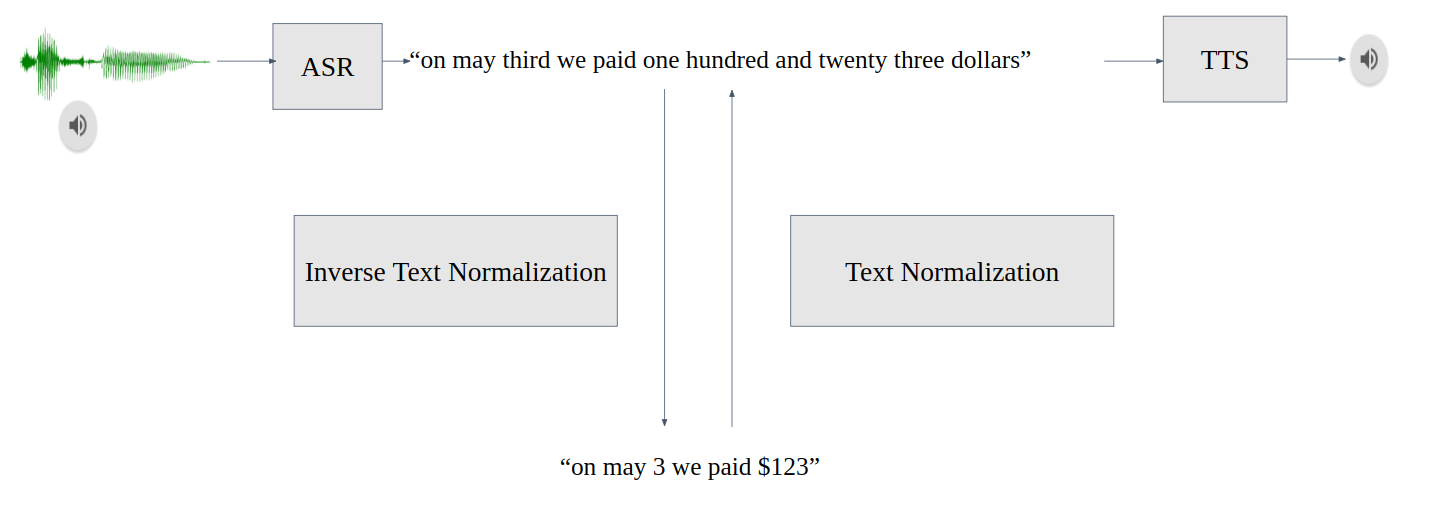
圖 1.會話 AI 管道中的 TN 和 ITN
TN 和 ITN 任務面臨幾個挑戰:
標記的數據稀缺且難以收集。
由于 TN 和 ITN 錯誤會級聯到后續模型,因此對不可恢復錯誤的容忍度較低。改變輸入語義的 TN 和 ITN 錯誤稱為不可恢復。
TN 和 ITN 系統支持多種 semiotic classes ,即口語形式不同于書面形式的單詞或標記,需要規范化。例如日期、小數、基數、度量等。
許多最先進的 TN systems in production 仍然使用 加權有限狀態傳感器 ( WFST )基于規則。 WFST 是 finite-state machines 的一種形式,用于繪制正則語言(或 regular expressions )之間的關系。對于這篇文章,它們可以由兩個主要屬性定義:
用于文本替換的已接受輸入和輸出表達式之間的映射
直接圖遍歷的路徑加權
如果存在歧義,則選擇權重總和最小的路徑。在圖 2 中,“二十三”被轉換為“ 23 ”而不是“ 203 ”

圖 2.輸入“二十三”的 WFST 格子
目前, NVIDIA NeMo 為 TN 和 ITN 系統提供以下選項:
Context-independent WFST-based TN and ITN grammars
Context-aware WFST-based grammars + neural LM for TN
Audio-based TN for speech datasets creation
Neural TN and ITN
基于 WFST 的語法(系統 1 、 2 和 3 )
NeMo 文本處理包是一個 Python 框架,它依賴于 Python 包 Pynini 來編寫和編譯規范化語法。有關最新支持的語言的更多信息,請參閱 Language Support Matrix 。有關如何擴展或添加語言語法的更多信息,請參閱 語法定制 。
Pynini 是一個構建在 OpenFst 之上的工具包,它支持將語法導出到 OpenFST Archive File (FAR) 中(圖 3 )。 FAR 文件可以在基于 Sparrowhawk 的 C ++生產框架中使用。
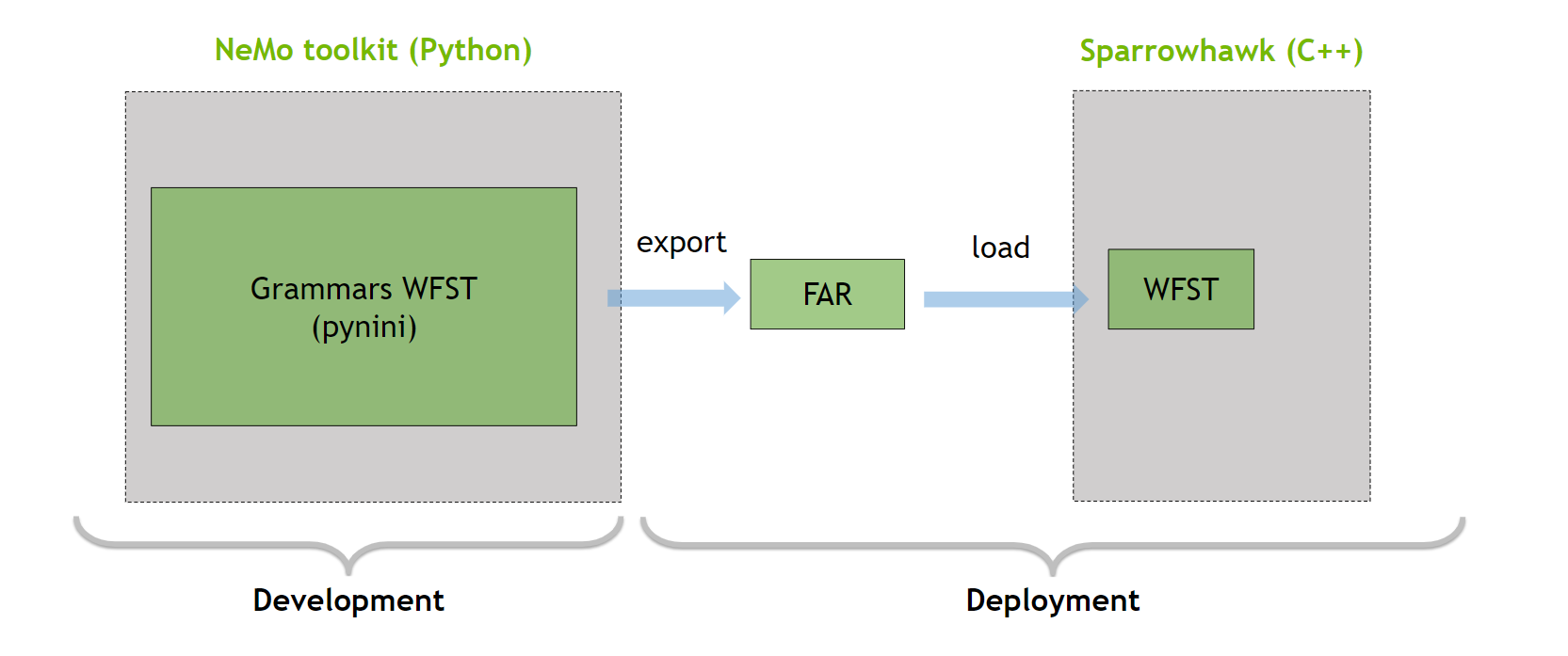
圖 3. NeMo 反向文本規范化開發和部署示意圖
我們最初版本的 TN / ITN 系統# 1 沒有考慮上下文,因為這會使規則更加復雜,這需要廣泛的語言知識,并降低延遲。如果輸入不明確,例如,與“ 1 / 4 個杯子”相比,“火車在 1 / 4 上出發”中的“ 1 / 4 ”,則系統# 1 會在不考慮上下文的情況下確定地選擇歸一化。
該系統擴展了系統# 1 ,并在規范化期間合并了上下文。在上下文不明確的情況下,系統輸出多個規范化選項,使用預處理語言模型使用 Masked Language Model Scoring 重新搜索(圖 4 )。
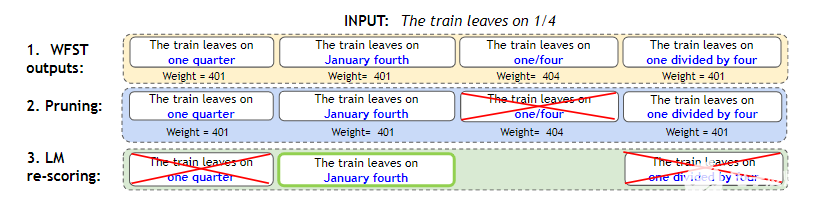
圖 4.WFST + LM 淺熔管線
WFST 生成所有可能的標準化表格,并為每個選項分配權重。
修剪權重高于閾值“ 401.2 ”的標準化選項。在本例中,我們刪除了“ 1 / 4 ”。它的權重更高,因為它沒有完全歸一化。
LM 重新排序在其余選項中選擇了最佳選項。
這種方法類似于 ASR 的淺層融合,并結合了基于規則和神經系統的優點。 WFST 仍然限制了不可恢復的錯誤,而神經語言模型在不需要大量規則或難以獲取數據的情況下解決了上下文模糊性。有關詳細信息,請參閱 Text normalization 。
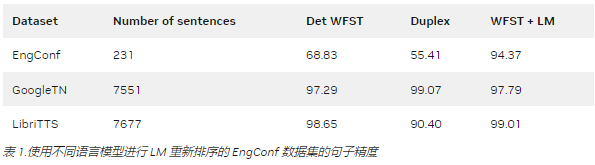
表 1 比較了 WFST + LM 方法在句子準確性方面與之前的系統# 1 ( DetWFST )和三個數據集上的純神經系統( Duplex )。在本文后面,我們將提供有關系統# 4 的更多詳細信息。
總的來說, WFST + LM 模型是最有效的,特別是在 EngConf 上,這是一個具有模糊示例的自收集數據集。
圖 5 顯示了這三種方法對錯誤的敏感性。雖然神經方法受不可恢復錯誤(如幻覺或遺漏)的影響最大,但 WFST + LM 受這些錯誤和類歧義的影響最小。
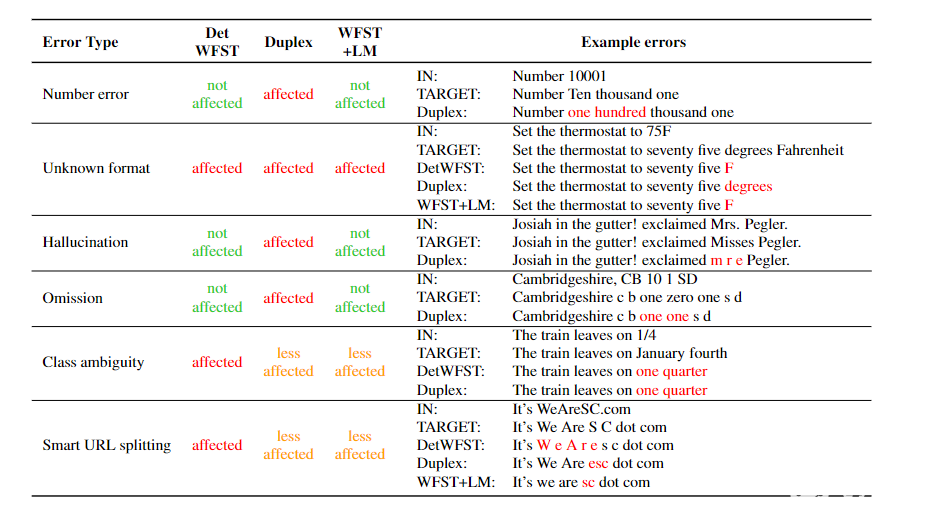
圖 5.上下文無關的 WFST 、 Duplex 和 WFST + LM 系統的錯誤模式
基于音頻的 TN (系統 3 )
在創建新的語音數據集時,文本規范化也很有用。例如,“六二七”和“六二十七”都是“ 627 ”的有效規范化選項。但是,您必須選擇最能反映相應音頻中實際內容的選項。基于音頻的文本規范化提供了此類功能(圖 6 )。
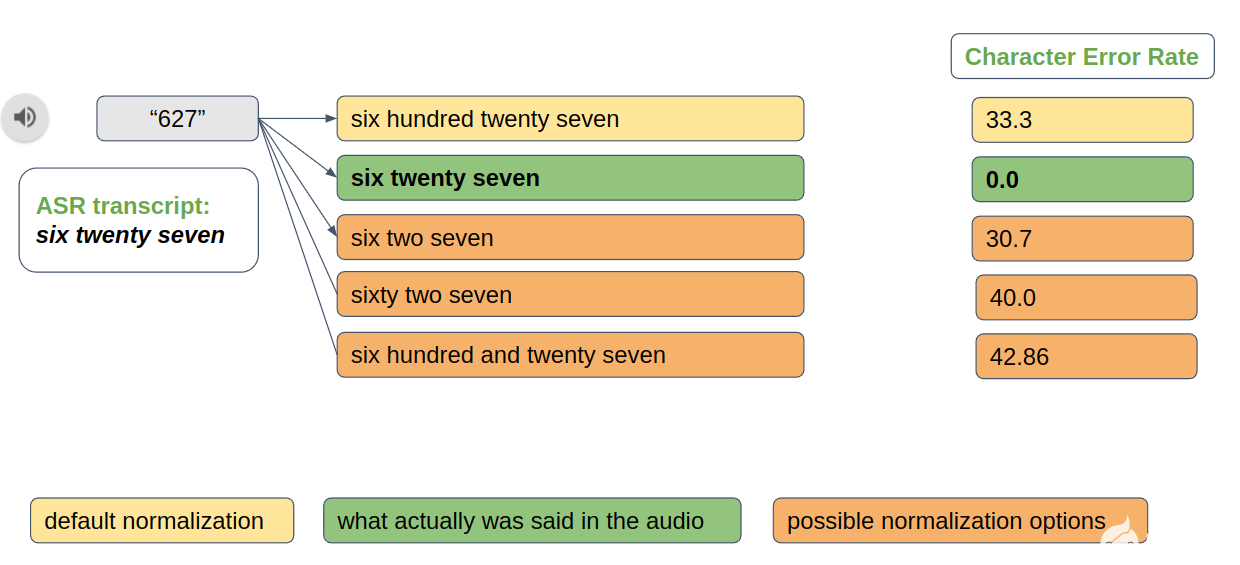
圖 6.基于音頻的標準化分辨率示例
神經 TN 和 ITN 模型(系統 4 )
與基于規則的系統相比,神經系統的一個顯著優勢是,如果存在新語言的訓練數據,那么它們很容易擴展。基于規則的系統需要花費大量精力來創建,并且由于組合爆發,可能會在某些輸入上工作緩慢。
作為 WFST 解決方案的替代方案, NeMo 為 TN / ITN 提供了 seq2seq Duplex 模型,為 ITN 提供了基于標記器的神經模型。
雙重 TN 和 ITN
Duplex TN and ITN 是一個基于神經的系統,可以同時進行 TN 和 ITN 。在較高的層次上,該系統由兩個組件組成:
DuplexTaggerModel: 基于 transformer 的標記器,用于識別輸入中的符號跨度(例如,關于時間、日期或貨幣金額的跨度)。
DuplexDecoderModel :基于變壓器的 seq2seq 模型,用于將符號跨度解碼為適當的形式(例如, TN 的口語形式和 ITN 的書面形式)。
術語“雙工”指的是這樣一個事實,即該系統可以訓練為同時執行 TN 和 ITN 。但是,您也可以專門針對其中一項任務對系統進行培訓。
圖特莫斯塔格
雙工模型是一種順序到順序模型。不幸的是,這種神經模型容易產生幻覺,從而導致無法恢復的錯誤。
Thutmose Tagger 模型將 ITN 視為一項標記任務,并緩解了幻覺問題(圖 7 和 8 )。 Thutmose 是一個單通道令牌分類器模型,它為每個輸入令牌分配一個替換片段,或將其標記為刪除或復制而不做更改。
NeMo 提供了一種基于 ITN 示例粒度對齊的數據集準備方法。該模型在谷歌文本規范化數據集上進行訓練,并在英語和俄語測試集上實現了最先進的句子準確性。
表 2 和表 3 總結了兩個指標的評估結果:
Sentence accuracy :將每個預測與參考的多個可能變體相匹配的自動度量。所有錯誤分為兩組:數字錯誤和其他錯誤。當至少有一個數字與最接近的參考變量不同時,會發生數字錯誤。其他錯誤意味著預測中存在非數字錯誤,例如標點符號或字母不匹配。
Word error rate ( WER ): ASR 中常用的自動度量。
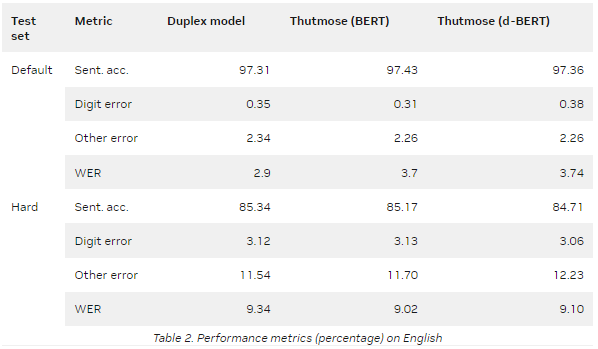
d- BERT 代表蒸餾 BERT 。
默認值是默認的 Google 文本規范化測試集。
Hard 是一個測試集,每個符號類至少有 1000 個樣本。
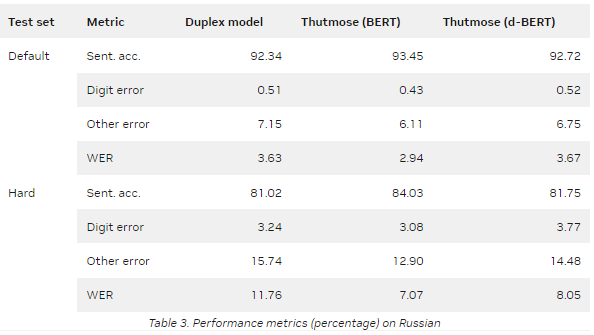
標簽和輸入詞之間的一對一對應提高了模型預測的可解釋性,簡化了調試,并支持后期處理更正。該模型比序列到序列模型更簡單,更容易在生產設置中進行優化。
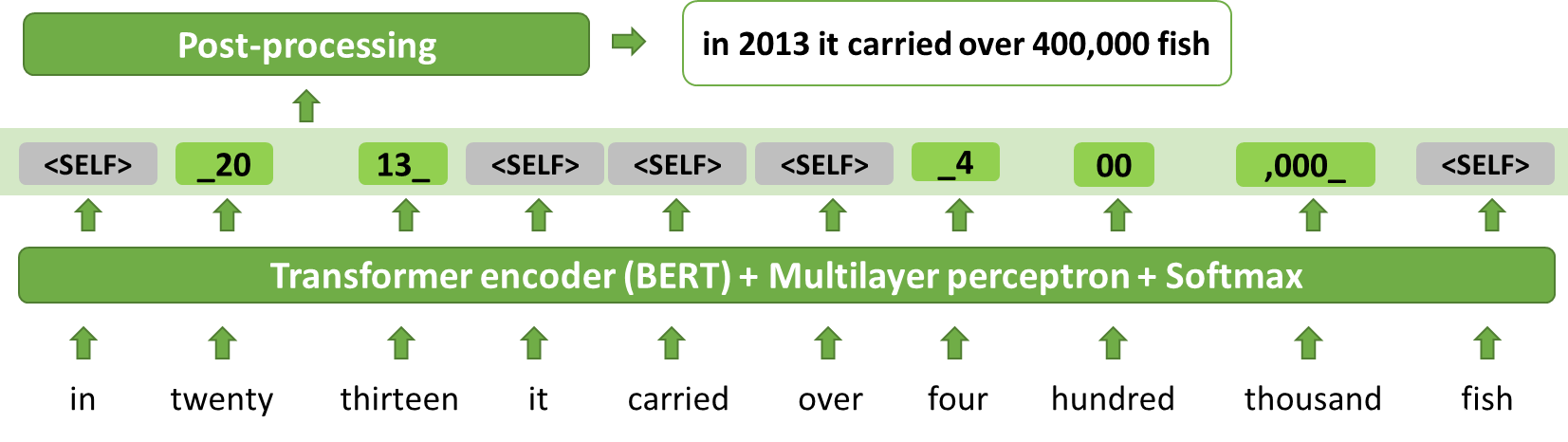
圖 7.ITN 作為標記:推理示例
輸入單詞的序列由基于 BERT 的標記分類器處理,給出輸出標記序列。簡單的確定性后處理提供最終輸出。

圖 8.錯誤示例:(左) Thutmose tagger ,(右) Duplex 模型
結論
文本規范化和反向文本規范化對于會話系統至關重要,并極大地影響用戶體驗。本文結合 WFST 和預處理語言模型的優點,介紹了一種處理 TN 任務的新方法,以及一種處理 ITN 任務的基于神經標記的新方法。
關于作者
Yang Zhang 是英偉達人工智能應用集團的一名深度學習軟件工程師。她目前的重點是自然語言處理、對話管理和文本(去規范化)。在過去,她一直致力于大型 ASR 模型和語言模型預培訓的可擴展培訓。她在卡內基梅隆大學獲得機器學習碩士學位,在德國卡爾斯魯厄理工學院獲得計算機科學學士學位。
Evelina Bakhturina 是 Nvidia 的一個深學習應用科學家,專注于自然語言處理任務和英偉達 NeMo 框架。她畢業于紐約大學,獲得數據科學碩士學位
Alexandra Antonova 是 NVIDIA Conversational AI 團隊( NeMo )的高級研究科學家,致力于 ASR 模型。她在莫斯科國立大學學習理論和應用語言學,在莫斯科物理技術學院深造。在加入 NVIDIA 之前,她曾在幾家俄羅斯科技公司工作。在空閑時間,她喜歡讀書。
審核編輯:郭婷
-
傳感器
+關注
關注
2566文章
53008瀏覽量
767581 -
NVIDIA
+關注
關注
14文章
5309瀏覽量
106433
發布評論請先 登錄
飛書開源“RTV”富文本組件 重塑鴻蒙應用富文本渲染體驗
Allegro Skill工藝輔助之導入疊層模板
鐳神智能深度參與兩項激光雷達國家標準制定 引領行業規范化發展新征程

眾合云科林枚參編的人力資源AI領域團體標準正式發布,助推行業數字化人才能力規范化建設

共建標準,共享未來:狄耐克積極參與腦機產業規范化建設
把樹莓派打造成識別文本的“神器”!

NVIDIA NeMo Guardrails引入三項全新NIM微服務
如何使用自然語言處理分析文本數據
科華數據參編《西藏金融數據中心建設規范》近日發布


圖紙模板中的文本變量
如何在文本字段中使用上標、下標及變量

如何使用 Llama 3 進行文本生成
Dell PowerScale數據湖助力醫研一體化建設
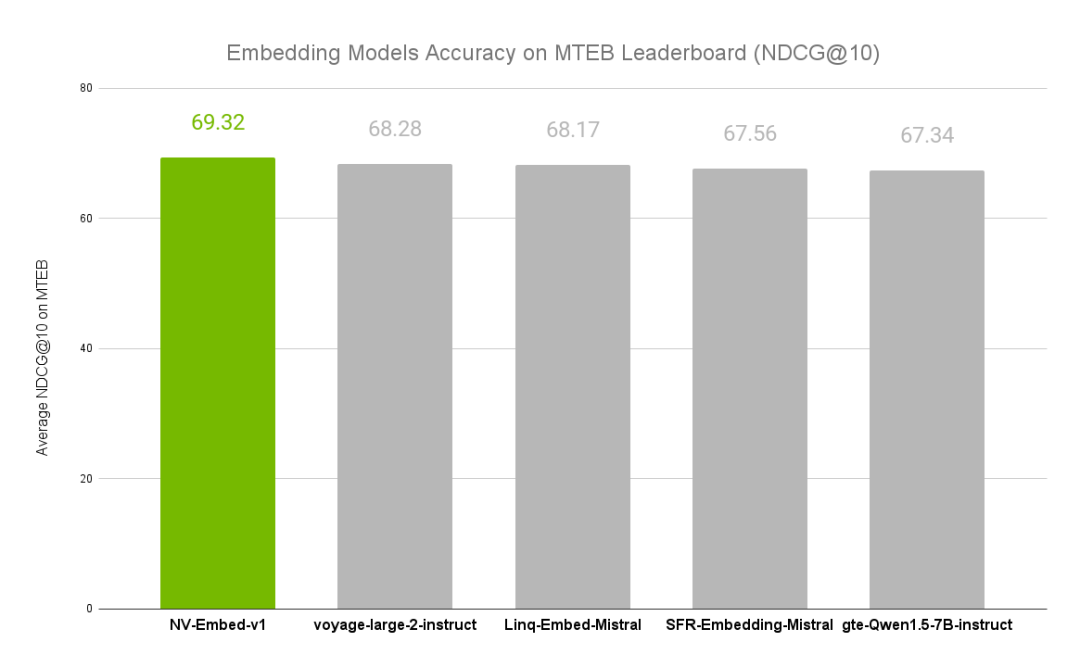
NVIDIA文本嵌入模型NV-Embed的精度基準





 工商網監
工商網監
評論