") 多尺度多方法組合的網(wǎng)約車需求預(yù)測方法研究
多尺度多方法組合的網(wǎng)約車需求預(yù)測方法研究
作者:丁夏蕾,郭秀才,程勇
引 言
為了滿足各種乘客的出行需求,隨著互聯(lián)網(wǎng)的發(fā)展,滴滴打車等在線打車平臺應(yīng)運(yùn)而生,這些服務(wù)使得乘客的出行需求向更靈活的公共交通工具發(fā)展,例如出租車、共享汽車和自行車。至關(guān)重要的是,移動隨需應(yīng)變系統(tǒng)可以進(jìn)一步開發(fā),以預(yù)測全市范圍內(nèi)的乘客出行需求(即載客和空載頻率),這將大大有助于定制有效的車輛分配和調(diào)度策略,以實(shí)現(xiàn)需求和資源平衡。值得一提的是,如果車輛分布與乘客需求分布不匹配,容易造成交通擁堵、資源浪費(fèi)等問題,更重要的是會降低客戶滿意度。
已存在的預(yù)測網(wǎng)約車需求的方法主要包括三類:基于統(tǒng)計(jì)分析的預(yù)測方法(如整合移動平均自回歸模型)、機(jī)器學(xué)習(xí)方法(如隨機(jī)森林)和深度學(xué)習(xí)方法(如長短期記憶神經(jīng)網(wǎng)絡(luò))。文獻(xiàn)[1]使用梯度提升回歸樹對網(wǎng)約出租車需求進(jìn)行預(yù)測。文獻(xiàn)[2]對傳統(tǒng)的梯度提升算法進(jìn)行優(yōu)化進(jìn)而預(yù)測網(wǎng)約車需求。文獻(xiàn)[3]使用隱馬爾科夫預(yù)測短時(shí)交通狀況。文獻(xiàn)[4]使用灰狼優(yōu)化算法對LSTM優(yōu)化。文獻(xiàn)[5]使用歷史數(shù)據(jù)并結(jié)合天氣、POI等構(gòu)建多特征 LSTM 模型。文獻(xiàn)[6]提出一種基于多層卷積神經(jīng)網(wǎng)絡(luò)的城市交通流量模型,并使用殘差網(wǎng)絡(luò)防止模型過擬合。文獻(xiàn)[7]使用基于卷積和卷積LSTM的編碼器?解碼器框架捕獲時(shí)空特征,通過引入一個(gè)多層次注意力模型,包括全局注意力和時(shí)間注意力挖掘潛在的城市交通流動性規(guī)律的影響并捕獲相關(guān)的時(shí)間依賴性。文獻(xiàn)[8]提出一種出發(fā)地?目的地交通需求預(yù)測模型,使用卷積神經(jīng)網(wǎng)絡(luò)和LSTM捕獲空間特征和時(shí)間特征。文獻(xiàn)[9]使用長短期記憶神經(jīng)網(wǎng)絡(luò)預(yù)測共享單車短時(shí)需求量。文獻(xiàn)[10]使用量子行為粒子群算法優(yōu)化徑向基神經(jīng)網(wǎng)絡(luò),進(jìn)而對網(wǎng)約車需求量進(jìn)行預(yù)測。文獻(xiàn)[11]利用短時(shí)交通流組合模型預(yù)測。文獻(xiàn)[12]使用改進(jìn)型貝葉斯組合模型預(yù)測短時(shí)交通流量。文獻(xiàn)[13]使用傳統(tǒng)時(shí)間序列預(yù)測方法ARMA和卡爾曼濾波預(yù)測短時(shí)交通流量。
雖然目前對于網(wǎng)約車需求預(yù)測在預(yù)測方法和預(yù)測精度上有了很大提高,但由于網(wǎng)約車訂單數(shù)據(jù)通常具有多維特征,如時(shí)間特征(例如每天中的不同時(shí)刻、周內(nèi)周末)、空間特征、天氣影響等,由于每個(gè)單一的時(shí)間序列預(yù)測模型都有自身的特點(diǎn),同時(shí)又不可避免地具有應(yīng)用局限性,反映數(shù)據(jù)信息也存在一定差異,使用單一模型進(jìn)行預(yù)測難免會丟失部分?jǐn)?shù)據(jù)信息[13],要準(zhǔn)確預(yù)測網(wǎng)約車需求是非常有挑戰(zhàn)性的。使用多個(gè)預(yù)測模型相結(jié)合的組合預(yù)測模型,可以彌補(bǔ)單個(gè)模型的缺點(diǎn),同時(shí)使用多模型組合預(yù)測也逐步成為研究發(fā)展的趨勢。本文使用歷史平均、ARIMA、LSTM三種模型對時(shí)間序列建模,分別挖掘時(shí)間序列數(shù)據(jù)的周期性規(guī)律、差分變化規(guī)律和其他復(fù)雜規(guī)律,從不同角度挖掘數(shù)據(jù)信息,然后用GWO(灰狼算法)對幾種單一模型權(quán)重進(jìn)行尋優(yōu),最后對未來時(shí)間段的網(wǎng)約車需求進(jìn)行預(yù)測。
1、相關(guān)研究
1.1 灰狼算法
灰狼優(yōu)化算法是文獻(xiàn)[14?15]在2014年提出的一種群智能優(yōu)化算法。該算法是受到灰狼捕食獵物活動的啟發(fā)而開發(fā)的一種優(yōu)化搜索方法,與其他優(yōu)化算法相比,灰狼優(yōu)化算法具有較強(qiáng)的收斂性能、參數(shù)少、易實(shí)現(xiàn)等特點(diǎn),近年來受到了學(xué)者的廣泛關(guān)注,它己被成功地應(yīng)用到了車間調(diào)度、參數(shù)優(yōu)化、圖像分類等領(lǐng)域中。灰狼算法的核心思想是通過模仿灰狼的社會等級制度,將捕食任務(wù)分配給不同等級的灰狼群體,以完成包圍、追捕和攻擊,從而實(shí)現(xiàn)全局最優(yōu)的過程。
1.2 LSTM
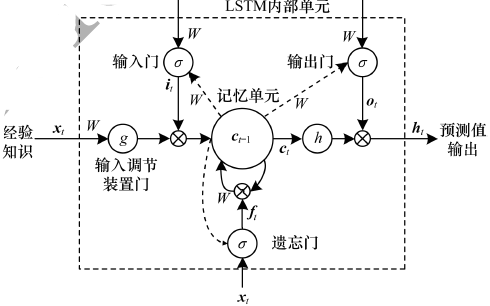
一般的循環(huán)神經(jīng)網(wǎng)絡(luò),如RNN通常會因?yàn)闀r(shí)間相隔較遠(yuǎn)之間的依賴問題難以學(xué)習(xí),LSTM 通過對輸入信息進(jìn)行門控處理,很好地解決了時(shí)間序列數(shù)據(jù)長期依賴問題。LSTM 的 cell單元結(jié)構(gòu)如圖1所示。
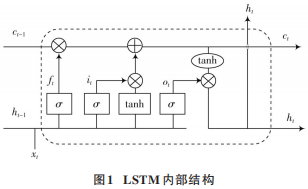
LSTM模型內(nèi)部使用輸入門it、忘記門ft、輸出門ot對信息進(jìn)行相應(yīng)的處理。其中:ht-1表示模型上一次輸出的結(jié)果;xt表示模型當(dāng)前輸入的信息。對于單元狀態(tài)中的每個(gè)數(shù)字 ct-1,用1代表完全保留ct-1,而用0代表完全拋棄ct-1 。tanh是雙曲正切激活函數(shù),σ (?)是Sigmoid激活函數(shù)。
1.3 ARIMA
差分整合移動平均自回歸模型(AutoregressiveIntegrated Moving Average Model,ARIMA)是一種傳統(tǒng)的、在時(shí)間序列預(yù)測問題中經(jīng)常被使用的模型,對于平穩(wěn)數(shù)據(jù)能夠很好的預(yù)測。ARIMA包括三部分:自回歸項(xiàng) 、積分項(xiàng) 、移動平均項(xiàng) ,用符號 可以將其表示為ARIMA(p,d,q),其中,p代表原始數(shù)據(jù)本身的滯后數(shù),d是積分次數(shù),表示原始數(shù)據(jù)經(jīng)過d次積分可以變?yōu)榉€(wěn)定數(shù)據(jù),q表示預(yù)測誤差的滯后數(shù)。ARIMA(p, d, q)模型用公式可以表示為:
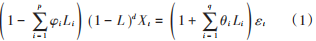
式中L是滯后算子。
1.4 隨機(jī)森林
隨機(jī)森林(Random Forest,RF)是以決策樹為基學(xué)習(xí)器的一種集成學(xué)習(xí)方法,與 Bagging(裝袋算法)不同的是,RF 引入了隨機(jī)屬性選擇,具體來說,RF 在選擇劃分屬性時(shí),首先在當(dāng)前節(jié)點(diǎn)的屬性集合中隨機(jī)選擇k個(gè),然后再從這k個(gè)屬性中選擇最優(yōu)屬性進(jìn)行劃分,這樣做增強(qiáng)了模型的泛化能力。
2、網(wǎng)約車影響因素分析及特征提取
首先對影響網(wǎng)約車需求的相關(guān)因素進(jìn)行分析并可視化,然后使用隨機(jī)森林回歸算法分別對網(wǎng)約車日需求量和網(wǎng)約車小時(shí)需求量建模,從而對影響網(wǎng)約車需求的相關(guān)因素進(jìn)行排名,進(jìn)而選擇重要的影響因素,為后面的網(wǎng)約車需求預(yù)測做準(zhǔn)備。
2.1 網(wǎng)約車影響因素分析
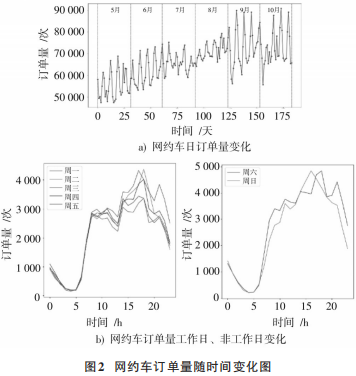
網(wǎng)約車需求通常受時(shí)間(不同時(shí)刻、周內(nèi)周末等)、空間、天氣(溫度、天氣狀況等)等多種因素影響,通過對獲取到的海口市2017年5—10月網(wǎng)約車訂單數(shù)據(jù)進(jìn)行統(tǒng)計(jì)分析,進(jìn)而分析不同因素對網(wǎng)約車需求的影響。
海口市5—10月網(wǎng)約車日訂單量變化圖如圖2a)所示,從圖中可以看出,隨著時(shí)間的推移網(wǎng)約車需求量也在逐步增加,同時(shí)可以看出,網(wǎng)約車需求量具有周期性特征。網(wǎng)約車訂單量工作日、非工作日變化圖如圖2b),圖2c)所示,圖中展示的是5月8日—12日(周一至周五)及5月13日—14日(周六、周天)一周的網(wǎng)約車訂單量。從圖中可以看出,工作日和非工作日的網(wǎng)約車訂單需求模式有很大不同,工作日需求量有3個(gè)峰值(早9點(diǎn)、下午14點(diǎn)、晚上18點(diǎn)),反映了人們一天當(dāng)中的通勤模式,而非工作日沒有工作日那么明顯的需求峰值。
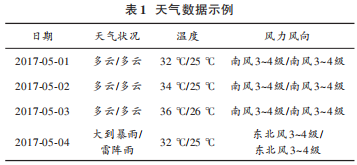
從天氣預(yù)報(bào)網(wǎng)爬取到的天氣數(shù)據(jù)示例如表 1所示。天氣狀況劃分為5種類型,分別為多云、雷陣雨、中雨、大雨、暴雨,其中 6 個(gè)月中天氣狀況以雷陣雨和多云為主。對于天氣數(shù)據(jù)中的風(fēng)力風(fēng)向,考慮其每一條數(shù)據(jù)幾乎無差異,所以考慮不將其作為有效特征。
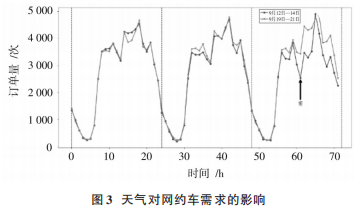
通過關(guān)聯(lián)天氣狀況數(shù)據(jù)與網(wǎng)約車訂單數(shù)據(jù),分析天氣狀況對網(wǎng)約車需求量的影響。天氣對網(wǎng)約車需求的影響如圖3所示,圖中展示的是9月12日—14 日和9月19日—21日的網(wǎng)約車需求量小時(shí)變化圖,兩個(gè)時(shí)間段均是周二至周四,兩個(gè)時(shí)間段除了9 月14日下雨,其余時(shí)間均是多云。可以發(fā)現(xiàn),9月14日網(wǎng)約車需求明顯少于同期水平,說明天氣狀況是影響網(wǎng)約車需求的一個(gè)重要因素,尤其是下雨天網(wǎng)約車訂單量會減少。
2.2 特征提取及特征選擇
特征選擇可以精簡掉無用的特征,以降低最終模型的復(fù)雜性,它的最終目的是得到一個(gè)簡約模型,在不降低預(yù)測準(zhǔn)確率或?qū)︻A(yù)測準(zhǔn)確率影響不大的情況下提高計(jì)算速度。為了得到這樣的模型,有些特征選擇技術(shù)需要訓(xùn)練不止一個(gè)待選模型。目前主流的特征選擇技術(shù)可以分為以下三類:
1)過濾式
過濾式方法中的一種典型方法是變量排序法,該方法獨(dú)立于后續(xù)的建模方法。過濾式方法的關(guān)鍵就是找到一種能度量特征重要性的方法,比如Pearson相關(guān)系數(shù)、信息論理論中的互信息等。
2)包裹式包裹式方法的核心思想在于,給定了某種模型及預(yù)測效果評價(jià)的方法,然后針對特征空間中的不同子集,計(jì)算每個(gè)子集的預(yù)測效果,效果最好的即作為最終被挑選出來的特征子集。包裹式的特點(diǎn)是計(jì)算量大。
3)嵌入式嵌入式方法將特征選擇融合在模型訓(xùn)練的過程中,比如決策樹在分枝的過程中,就是使用嵌入式特征選擇方法,其內(nèi)在還是根據(jù)某個(gè)度量指標(biāo)對特征進(jìn)行排序。
本文使用嵌入式方法中的隨機(jī)森林算法進(jìn)行特征選擇,隨機(jī)森林是一種非常流行的特征選擇方法,該方法易于使用,一般不需要特征工程、調(diào)參等繁瑣的步驟。
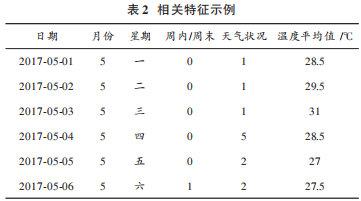
對于 2.1節(jié)中分析可視化的網(wǎng)約車影響因素包含月份、周內(nèi)周末、星期幾、小時(shí)、天氣狀況、溫度,對這些影響因素進(jìn)行特征編碼。對于月份、星期幾這幾個(gè)因素直接使用對應(yīng)數(shù)字構(gòu)成特征,將周內(nèi)編碼為0,周末編碼為1,對于5種類型的天氣狀況分別將其編碼為0~5。表2為相關(guān)特征示例。
由于爬取到的天氣數(shù)據(jù)較為粗糙,溫度只有一天當(dāng)中的最高溫度和最低溫度,所以分別采用隨機(jī)森林算法對日訂單量的影響因素特征和小時(shí)訂單量的影響因素特征進(jìn)行排名。
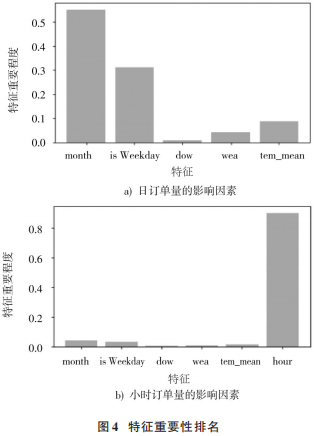
使用隨機(jī)森林算法對特征進(jìn)行排名,參數(shù)全部使用默認(rèn)參數(shù),其中基學(xué)習(xí)器數(shù)量為10個(gè),max_features為auto,對每日訂單量的影響因素做特征排名。相關(guān)特征包括:月 份(month)、是否工作日(is Weekday)、周幾(dow)、天氣狀況(wea)、溫度平均值(tem_mean)。實(shí)驗(yàn)結(jié)果圖 4a)所示。
用相同的方法對每小時(shí)訂單量的影響因素做特征排名。提取的特征包括:月份(month)、是否工作日(isWeekday)、周幾(dow)、天氣狀況(wea)、溫 度 平 均 值(tem_mean)、小時(shí)(hour)。實(shí)驗(yàn)結(jié)果如圖4b)所示。
從上面兩個(gè)實(shí)驗(yàn)結(jié)果可以看出:影響網(wǎng)約車需求最重要的特征是小時(shí)(即一天中的不同時(shí)刻),在小時(shí)訂單量特征重要性實(shí)驗(yàn)中達(dá)到0.9;其次是月份,訂單量特征重要性實(shí)驗(yàn)中達(dá)到0.56;最不重要的特征是周幾,在兩個(gè)實(shí)驗(yàn)中特征重要性排名均最低,可以認(rèn)為周幾是不重要的特征,所以將周幾這一特征剔除。其他特征,如是否工作日、天氣狀況、溫度平均值予以保留。
3、組合預(yù)測模型
3.1 相關(guān)定義及問題描述
定義1(網(wǎng)約車需求):對于網(wǎng)約車訂單數(shù)據(jù),每個(gè)訂單中包括( ppick , pdrop , tpick , tdrop )等信息,表示用戶在時(shí)間為tpick、位置為ppick 點(diǎn)上車,在時(shí)間為 tdrop、位置為pdrop點(diǎn)下車,用τ表示訂單集合,用Gλ={gii∈[1,n]}表示所有區(qū)域集合(本文按照行政區(qū)域劃分)。對于任一點(diǎn)p(xp,yp),如果p在區(qū)域gi中,記作p∈gi,給出時(shí)間段[st,et],對所有訂單數(shù)據(jù)實(shí)行等時(shí)段同區(qū)域需求量聚合,可以計(jì)算出上車需求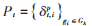 ,其滿足
,其滿足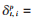 {|T∈τ|?|Tppick∈gi∧Ttpick∈[st,et]},其中δpt,i表示在時(shí) 間間隔[st,et]從區(qū)域gi出發(fā)的需求量。
{|T∈τ|?|Tppick∈gi∧Ttpick∈[st,et]},其中δpt,i表示在時(shí) 間間隔[st,et]從區(qū)域gi出發(fā)的需求量。
問題描述:網(wǎng)約車需求可以表示為時(shí)間序列Xt,目標(biāo)是給出網(wǎng)約車歷史需求數(shù)據(jù){Xti=t-n+1,?,t|}來預(yù)測未來需求量Xt-1,其中n表示序列長度。
3.2 組合預(yù)測模型構(gòu)建
本文提出一種組合預(yù)測模型,模型融合了歷史平均、ARIMA和LSTM三種方法的優(yōu)勢,以灰狼算法搜索最優(yōu)加權(quán)組合預(yù)測模型。組合預(yù)測結(jié)構(gòu)圖如圖5所示。
首先通過使用歷史平均、ARIMA、LSTM三種模型對時(shí)間序列建模,分別挖掘時(shí)間序列數(shù)據(jù)的周期性規(guī)律、差分變化規(guī)律和其他復(fù)雜規(guī)律;然后用灰狼算法對三種模型進(jìn)行組合,計(jì)算最優(yōu)組合參數(shù);最后對未來時(shí)間段的網(wǎng)約車需求進(jìn)行預(yù)測。根據(jù)最優(yōu)化理論,將損失函數(shù)定義為預(yù)測誤差平方和最小,計(jì)算式為:
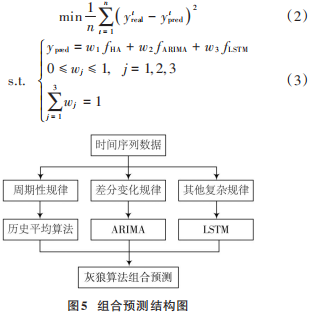
式(2)要求適應(yīng)度函數(shù)(均方誤差)最小,式(3)為約束條件。式中:yrteal是t時(shí)刻真實(shí)值;ytpred是t時(shí)刻預(yù)測值;,fHA,fARIMA,fLSTM分別是三種方法的預(yù)測值;w1,w2,w3為對應(yīng)的權(quán)重。使用灰狼算法搜索權(quán)重wj的最優(yōu)解,操作步驟如下:
步驟1(初始化模型參數(shù)):設(shè)定狼群規(guī)模N,最大迭代次數(shù) imax,組合的模型數(shù)量 m = 3,適應(yīng)度函數(shù)取 RMSE(均方誤差),產(chǎn)生N個(gè)m維[0,1]區(qū)間上的隨機(jī)數(shù)向量。對每一個(gè)向量執(zhí)行 wni∑i =1mwni,即對三個(gè)模型權(quán)重做歸一化處理,使其權(quán)重和為1。初始化α,β,δ狼的適應(yīng)度值α_score,β_score,δ_score為inf(inf表示無窮大),初始化α,β,δ狼的位置向量Xα,Xβ,Xδ為[inf,inf,inf]。
步驟2(單一模型預(yù)測):分別利用三種單一模型預(yù)測時(shí)間序列數(shù)據(jù),調(diào)整單一模型參數(shù)至最佳狀態(tài),得到每個(gè)模型的預(yù)測結(jié)果。
步驟3(社會等級分層):把N個(gè)狼群分別代入組合模型中,求出N個(gè)ypred,計(jì)算適應(yīng)度,將狼群中適應(yīng)度最好的3個(gè)適應(yīng)度值分別賦給α_score,β_score,δ_score,同時(shí)將最好的位置向量分別賦給Xα,Xβ,Xδ。
步驟4(包圍獵物和狩獵):灰狼搜索獵物時(shí)會逐漸接近獵物并包圍它,搜索過程主要靠α,β,δ狼指引,根據(jù)當(dāng)前種群中適應(yīng)度最好的三只灰狼α,β,δ 的位置信息Xα,Xβ,Xδ更新其他狼的位置,公式如式(4)~式(10)所示:
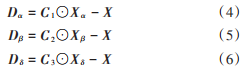
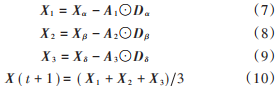
式中:Xα,Xβ,Xδ分別表示當(dāng)前種群中α,β,δ 的位置向量;Dα,Dβ,Dδ是位置更新后的位置向量;Ai,Ci是協(xié)同系數(shù)向量;X 是當(dāng)前灰狼的位置向量;X (t+1)是更新后的灰狼位置向量。
步驟5:再次執(zhí)行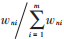 做歸一化處理。
做歸一化處理。
步驟6:如果迭代結(jié)果趨于穩(wěn)定或達(dá)到最大迭代次數(shù),則停止迭代,輸出 Xα 并可視化迭代過程;否則,重復(fù)步驟3~步驟 5。
4、實(shí)驗(yàn)分析
4.1 實(shí)驗(yàn)數(shù)據(jù)及預(yù)處理
實(shí)驗(yàn)使用的數(shù)據(jù)分為兩部分:海口市網(wǎng)約車訂單數(shù)據(jù)和海口市行政區(qū)域劃分?jǐn)?shù)據(jù)。海口市網(wǎng)約車訂單數(shù)據(jù)中包含了海口市183天的網(wǎng)約車訂單數(shù)據(jù),其中包括約1400萬條用戶乘車訂單記錄,每條記錄的主要信息包括用戶上下車時(shí)間、用戶上下車位置(經(jīng)緯度),具體信息如表3所示。滴滴出行數(shù)據(jù)起點(diǎn)Google Earth 分布圖如圖6所示。

在進(jìn)行實(shí)驗(yàn)之前,先設(shè)置實(shí)驗(yàn)參數(shù),時(shí)間粒度取1 h,并以時(shí)間粒度為時(shí)間間隔,將時(shí)間軸劃分成多個(gè)時(shí)間段,并統(tǒng)計(jì)每個(gè)時(shí)間段內(nèi)各區(qū)域的上車訂單數(shù)量作為網(wǎng)約車需求量。實(shí)驗(yàn)使用最后7天(168 h)作為測試集,其他數(shù)據(jù)作為訓(xùn)練集。實(shí)驗(yàn)運(yùn)行環(huán)境為:Intel Xeon E5?2620CPU,2.4 GHz,內(nèi)存 32 GB,操作系統(tǒng)為Windows7,所有實(shí)驗(yàn)均用集成開發(fā)環(huán)境 Anaconda(Python 3.7)完成 ,主要用到的第三包括Keras、TensorFlow、statsmodels等。
實(shí)驗(yàn)采用五種評價(jià)標(biāo)準(zhǔn):MSE(均方誤差)、RMSE(均方根誤差)、MAE(平均絕對誤差)、MAPE(平均絕對百分比誤差)、MSPE(均方百分比誤差)。五種評價(jià)標(biāo)準(zhǔn)計(jì)算如下:
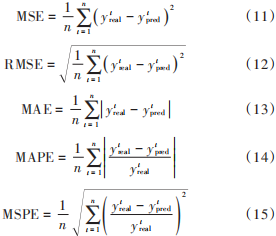
式中:yrteal為t時(shí)間段的真實(shí)值;ytpred為相應(yīng)的預(yù)測值。
4.2 單種模型仿真驗(yàn)證
歷史平均法:歷史平均法使用歷史上相同時(shí)刻的平均值作為未來網(wǎng)約車預(yù)測值,比如要預(yù)測星期一 12:00—13:00 的交通量,那么就將歷史上星期一12:00—13:00的交通量做平均后作為預(yù)測值。
LSTM:在2.2節(jié)中最后提取的特征包括月份(month)、是否工作日(is Weekday)、周幾(dow)、天氣狀況(wea)、溫度平均值(tem_mean),使用這5個(gè)外部特征和前5個(gè)歷史時(shí)刻網(wǎng)約車需求量共10個(gè)特征一同構(gòu)成多元單步LSTM的輸入向量。使用多元單步 LSTM 模型進(jìn)行網(wǎng)約車需求預(yù)測分為三步:首先對原始數(shù)據(jù)做縮放處理,使所有數(shù)據(jù)在同一量綱下,并對縮放后的序列數(shù)據(jù)使用滑動時(shí)間窗法分割數(shù)據(jù),構(gòu)建 feature?target對,將問題轉(zhuǎn)化為監(jiān)督學(xué)習(xí)問題;然后搭建多元單步LSTM模型;最后對未來網(wǎng)約車需求進(jìn)行預(yù)測。本文設(shè)置輸入數(shù)據(jù)時(shí)間步取10,輸出時(shí)間步取1(即 10 個(gè)預(yù)測1個(gè)),模型采用三層LSTM,每層隱含層神經(jīng)元個(gè)數(shù)取50個(gè),批處理大小 batch_size 取32,使用 Early Stopping 機(jī)制防止模型過擬合并能獲得最好的泛化性能。使用 Adam 優(yōu)化器優(yōu)化模型參數(shù)。
ARIMA:為了搜索ARIMA的最優(yōu)參數(shù),本文使用AIC(赤池信息準(zhǔn)則)評價(jià)標(biāo)準(zhǔn)評估模型優(yōu)劣,AIC越低,模型性能越好,AIC越高,模型性能越差。同時(shí),為了提高預(yù)測準(zhǔn)確性、減少迭代次數(shù),從集合{1,2,4,6,8}中選擇p和q,從集合{0,1,2}中選擇參數(shù) d。通過實(shí)驗(yàn)得到最優(yōu)參數(shù)為ARIMA(4,1,2)。
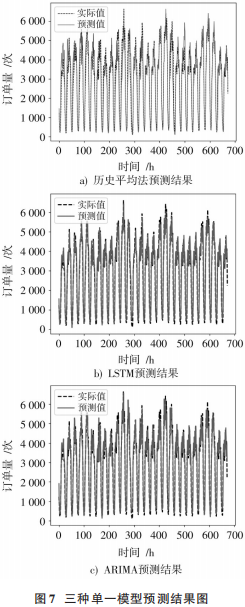
三種單一模型的預(yù)測結(jié)果如圖7所示。從實(shí)驗(yàn)結(jié)果可以看出,三種獨(dú)立方法均可以在一定程度上反映海口市網(wǎng)約車需求的變化趨勢。歷史平均算法能在很大程度上反映周期性規(guī)律,在低需求量時(shí)段能很好的預(yù)測,但對需求量高峰時(shí)段不能很好的預(yù)測。歷史平均算法、LSTM 算法在低需求量時(shí)段能很好的預(yù)測,而且在需求量高峰時(shí)段 ,LSTM算法要好于歷史平均算法 。ARIMA模型在低需求量時(shí)段預(yù)測不如歷史平均和LSTM,但在需求量高峰時(shí)段要好于以上兩種方法,這主要是因?yàn)锳RIMA能較好地處理序列數(shù)據(jù)的差分變化,捕獲數(shù)據(jù)的差分變化規(guī)律。
4.3 組合預(yù)測模型仿真驗(yàn)證
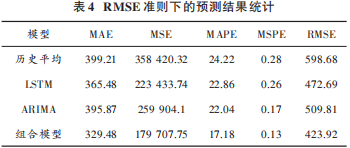
為了驗(yàn)證本文所提出組合模型的優(yōu)越性 ,使用RMSE(均方根誤差)為適應(yīng)度函數(shù)對三種模型進(jìn)行組合,結(jié)果如表4所示。可以看出,在單一模型中,LSTM模型在不同評價(jià)標(biāo)準(zhǔn)下結(jié)果均優(yōu)于歷史平均方法和ARIMA方法,同時(shí),相比于單一模型,組合預(yù)測模型在五種不同誤差尺度下均好于三種單一模型,在網(wǎng)約車需求預(yù)測問題上具有更好的預(yù)測精度。
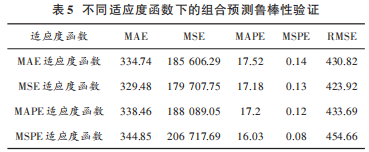
為了驗(yàn)證模型的魯棒性,在不同的適應(yīng)度函數(shù)下進(jìn)行實(shí)驗(yàn),結(jié)果如表5所示。結(jié)果顯示,在不同適應(yīng)度函數(shù)下,組合模型在不同評價(jià)標(biāo)準(zhǔn)下的誤差均優(yōu)于單一模型,驗(yàn)證了模型的魯棒性。
5、結(jié) 論
本文通過將歷史平均、ARIMA、LSTM三種時(shí)間序列預(yù)測方法用灰狼算法進(jìn)行加權(quán)組合,分別挖掘時(shí)間序列數(shù)據(jù)的周期性規(guī)律、差分變化規(guī)律和其他復(fù)雜規(guī)律,然后用灰狼算法對三種模型進(jìn)行組合尋優(yōu),計(jì)算最優(yōu)參數(shù),最后對海口市網(wǎng)約車需求量進(jìn)行預(yù)測。通過在真實(shí)數(shù)據(jù)集上驗(yàn)證組合模型的有效性并與其他單一模型進(jìn)行比較。實(shí)驗(yàn)結(jié)果表明,采用組合模型能夠準(zhǔn)確地預(yù)測網(wǎng)約車需求且優(yōu)于其他單一模型,這對于網(wǎng)約車公司預(yù)先調(diào)配車量來滿足網(wǎng)約車用戶需求和提高用戶體驗(yàn)具有重要意義。
審核編輯:郭婷
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25311 -
決策樹
+關(guān)注
關(guān)注
3文章
96瀏覽量
13787
原文標(biāo)題:論文速覽 | 多尺度多方法組合的網(wǎng)約車需求預(yù)測方法研究
文章出處:【微信號:現(xiàn)代電子技術(shù),微信公眾號:現(xiàn)代電子技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
網(wǎng)約車新政出臺后的幾天,看看約車平臺、出租車租賃公司和司機(jī)們的故事!
基于多新息隨機(jī)梯度算法的網(wǎng)側(cè)變流器參數(shù)辨識方法研究
基于大數(shù)據(jù)的多尺度系統(tǒng)軟測量方法及其應(yīng)用_楊彬
一種多尺度多視點(diǎn)特性視圖生成方法的研究和應(yīng)用_謝冰
基于多斷面的區(qū)間預(yù)測方法
多尺度數(shù)據(jù)挖掘方法
加權(quán)系數(shù)的短期風(fēng)電功率組合預(yù)測方法
基于LSTM模型的多時(shí)間尺度融合預(yù)測方法
結(jié)合多尺度邊緣保持分解與PCNN的圖像融合方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論