") Sapphire Rapids加速器::AMX、DLB、DSA、IAA和AMX
Sapphire Rapids加速器::AMX、DLB、DSA、IAA和AMX

英特爾的年度創(chuàng)新活動(dòng)最近在圣何塞舉行,該公司希望重新獲得在過(guò)去幾年中慢慢失去的大量技術(shù)動(dòng)力。雖然英特爾一直在努力發(fā)布新產(chǎn)品,但進(jìn)度的延遲和無(wú)法向親臨現(xiàn)場(chǎng)的觀眾展示他們的產(chǎn)品,使該公司及其產(chǎn)品失去了一些光澤。因此,對(duì)于在這次自疫情爆發(fā)以來(lái)舉辦的最大的現(xiàn)場(chǎng)技術(shù)活動(dòng),該公司正在盡可能多地展示其產(chǎn)品,以說(shuō)服媒體、合作伙伴和客戶相信其CEO Pat Gelsinger的努力已經(jīng)使該公司回到了正軌。
在英特爾過(guò)去幾年的奮斗中,沒(méi)有比他們的Sapphire Rapids服務(wù)器/工作站CPU更好的產(chǎn)品了。作為Intel真正的下一代產(chǎn)品,它帶來(lái)了從PCIe 5、DDR5到CXL的一切,以及一系列硬件加速卡,對(duì)于Sapphire Rapids的延遲,真的沒(méi)有什么可寫的。
但Sapphire Rapids即將到來(lái)。英特爾終于能夠看到這些開發(fā)工作隧道盡頭的光亮了。距離2023年第一季度的全面上市只有一個(gè)多季度,英特爾終于可以向更多人展示Sapphire Rapids了。或者從更務(wù)實(shí)的角度來(lái)看,英特爾現(xiàn)在需要在Sapphire Rapids的發(fā)布之前開始認(rèn)真推廣它。
在今年的展會(huì)上,英特爾邀請(qǐng)媒體成員觀看預(yù)生產(chǎn)的Sapphire Rapids芯片的現(xiàn)場(chǎng)演示。演示的目的,除了讓媒體能夠說(shuō) "我們看到了它;它真的存在!"之外,也是為了開始展示Sapphire Rapids的一個(gè)更獨(dú)特的功能:其專用加速器塊的集合。
除了為CPU的處理器核心提供急需的更新外,Sapphire Rapids還為幾個(gè)常見(jiàn)的CPU關(guān)鍵服務(wù)器/工作站工作負(fù)載添加了專用加速器塊。簡(jiǎn)單地說(shuō),這個(gè)想法是,固定功能芯片可以用一小部分功率完成任務(wù),甚至比CPU核心更好,而且只需增加一小部分芯片尺寸。隨著超大規(guī)模企業(yè)和其他服務(wù)器運(yùn)營(yíng)商在計(jì)算密度和能源效率方面尋求重大改進(jìn),像這樣的特定領(lǐng)域加速器是英特爾向其客戶提供這種優(yōu)勢(shì)的一個(gè)好方法。而且,競(jìng)爭(zhēng)對(duì)手AMD預(yù)計(jì)不會(huì)有類似的加速器模塊,這對(duì)他們也沒(méi)有什么影響。
01Sapphire Rapids芯片
在我們進(jìn)一步討論之前,我們先來(lái)看看Sapphire Rapids芯片的情況。

為了進(jìn)行演示(以及提供給最終的評(píng)測(cè)者使用),英特爾使用預(yù)生產(chǎn)的芯片組裝了一些雙插口Sapphire Rapids系統(tǒng)。為了便于拍照,他們打開了一個(gè)系統(tǒng)并取出了CPU。

在這一點(diǎn)上,除了它的工作原理外,我們對(duì)芯片沒(méi)有什么可說(shuō)的。由于它仍然是預(yù)生產(chǎn)產(chǎn)品,英特爾沒(méi)有披露時(shí)鐘速度或型號(hào),也沒(méi)有透露非最終芯片的勘誤表。但我們所知道的是,這些芯片有60個(gè)CPU內(nèi)核在運(yùn)行,還有演示的加速器塊。
Sapphire Rapids加速器::AMX、DLB、DSA、IAA和AMX
不算Sapphire Rapids CPU核心上的AVX-512單元,服務(wù)器CPU將在每個(gè)CPU塊中配備4個(gè)專用加速器。
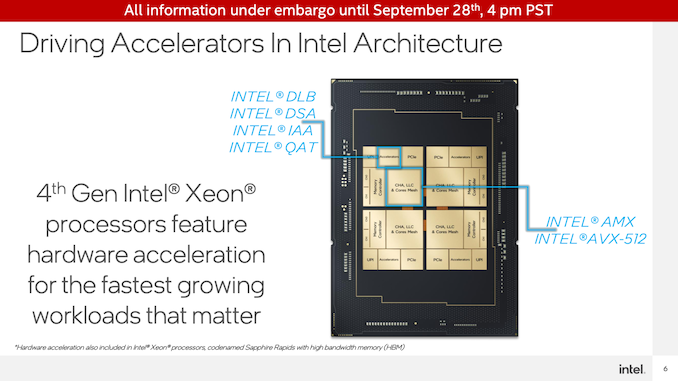
這些加速器是英特爾動(dòng)態(tài)負(fù)載平衡器(DLB)、英特爾數(shù)據(jù)流加速器(DSA)、英特爾內(nèi)存分析加速器(IAA)和英特爾快速輔助技術(shù)(QAT)。所有這些都作為專用設(shè)備掛在芯片網(wǎng)格上,本質(zhì)上是作為PCIe加速器,已經(jīng)集成到CPU芯片本身。這意味著加速器不消耗CPU核心資源(內(nèi)存和I/O是另一回事),但這也意味著可用的加速器核心數(shù)量不會(huì)隨著CPU核心數(shù)量的增加而直接增加。
在這些加速器中,除了QAT,其他都是英特爾的新產(chǎn)品。QAT是個(gè)例外,因?yàn)樵摷夹g(shù)的上一代是在用于第三代至強(qiáng)(Ice Lake-SP)處理器的PCH(芯片組)中實(shí)現(xiàn)的,而從Sapphire Rapids開始,它被集成到CPU芯片本身。因此,雖然英特爾實(shí)施特定領(lǐng)域的加速器并不是一個(gè)新現(xiàn)象,但該公司在Sapphire Rapids的想法上是全力以赴的。

所有這些專用加速塊都是為了卸載一組特定的高吞吐量工作負(fù)載而設(shè)計(jì)的。例如,DSA可以加速數(shù)據(jù)復(fù)制和簡(jiǎn)單計(jì)算,例如計(jì)算CRC32。同時(shí),QAT是一個(gè)加密加速塊,也是一個(gè)數(shù)據(jù)壓縮/解壓縮塊。IAA也是類似的,即時(shí)數(shù)據(jù)壓縮和解壓縮,允許大型數(shù)據(jù)庫(kù)(即大數(shù)據(jù))以壓縮形式保存在內(nèi)存中。最后,DLB是加速服務(wù)器之間負(fù)載平衡的一個(gè)塊。
最后,還有Advanced Matrix Extension(AMX),它是Intel之前宣布的矩陣數(shù)學(xué)執(zhí)行塊。與張量核和其他類型的矩陣加速器類似,這些是高效執(zhí)行矩陣數(shù)學(xué)的超高密度塊。與其他加速器類型不同,AMX不是專用加速器,而是CPU內(nèi)核的一部分,每個(gè)內(nèi)核都有一個(gè)塊。
AMX是Intel在深度學(xué)習(xí)市場(chǎng)上的重頭戲,通過(guò)使用更密集的數(shù)據(jù)結(jié)構(gòu),它超越了目前使用AVX-512所能達(dá)到的吞吐量。雖然Intel將擁有超越這一點(diǎn)的GPU,但對(duì)于Sapphire Rapids,Intel希望解決需要人工智能推理的客戶群體,這些推理發(fā)生在非常靠近CPU內(nèi)核的位置,而不是在一個(gè)靈活性較低、更專用的加速器中。
02實(shí)例演示
在活動(dòng)上的演示中,Intel派出了測(cè)試團(tuán)隊(duì),設(shè)置并展示了一系列利用新加速器的真實(shí)情況演示,并可以對(duì)其性能進(jìn)行基準(zhǔn)測(cè)試。為此,英特爾希望展示其在自己的Sapphire Rapids硬件上與非加速(CPU)操作相比的優(yōu)勢(shì),即為什么應(yīng)該在這些類型的工作負(fù)載中使用其加速器,并展示與在主要競(jìng)爭(zhēng)對(duì)手AMD的EPYC(米蘭)CPU上執(zhí)行相同工作負(fù)載相比的性能優(yōu)勢(shì)。
當(dāng)然,英特爾已經(jīng)在內(nèi)部運(yùn)行這些數(shù)據(jù)。因此,這些演示的目的除了揭示這些性能數(shù)據(jù)外,還在于展示這些數(shù)據(jù)是真實(shí)的,以及它們是如何獲得這些數(shù)據(jù)的。毫無(wú)疑問(wèn),這是英特爾想要邁出的最好的一步。但它是用真正的芯片和真正的服務(wù)器來(lái)實(shí)現(xiàn)的,工作負(fù)載(對(duì)我來(lái)說(shuō))似乎是測(cè)試的合理任務(wù)。
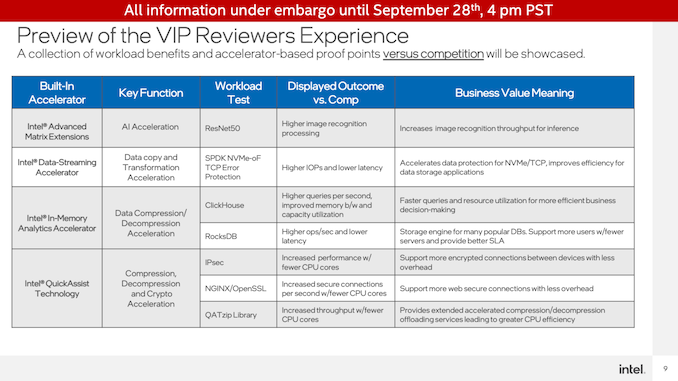
QuickAssist技術(shù)演示
首先是QuickAssist Technology(QAT)加速器的演示。Intel從NGINX工作負(fù)載開始,測(cè)量OpenSSL加密性能。
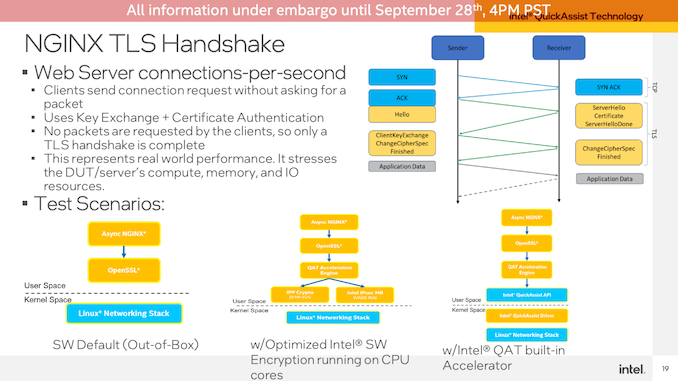
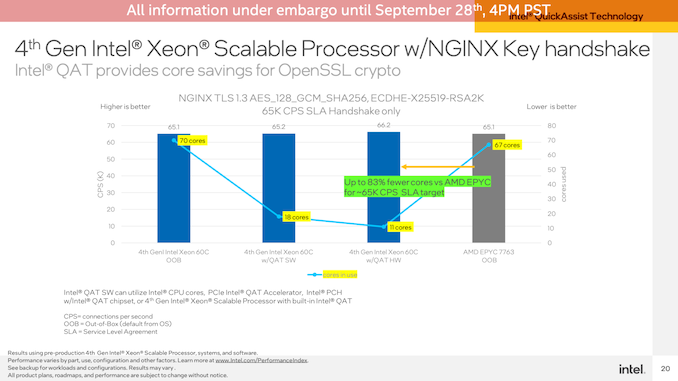
為了達(dá)到大致相同的性能,Intel能夠在其Sapphire Rapids服務(wù)器上實(shí)現(xiàn)大約每秒66K的連接,僅使用QAT加速器和120(2x60)個(gè)CPU內(nèi)核中的11個(gè)來(lái)處理演示的非加速位。相比之下,在Sapphire Rapids上無(wú)需任何QAT加速即可實(shí)現(xiàn)相同的吞吐量需要67個(gè)內(nèi)核,而在雙插槽EPYC 7763服務(wù)器上則需要67個(gè)核心。


第二個(gè)QAT演示是在相同硬件上測(cè)量壓縮/解壓縮性能。正如我們對(duì)專用加速器塊的期望一樣,這個(gè)基準(zhǔn)測(cè)試非常失敗。QAT硬件加速器超過(guò)了CPU,甚至在使用Intel高度優(yōu)化的ISA-L庫(kù)時(shí)超過(guò)了CPU。與此同時(shí),這幾乎是一項(xiàng)完全卸載的任務(wù),因此它消耗了4個(gè)CPU內(nèi)核的時(shí)間,而軟件工作負(fù)載中的所有120/128個(gè)CPU內(nèi)核都是如此。

內(nèi)存分析加速器演示
第二個(gè)演示是內(nèi)存分析加速器。盡管名稱如此,它實(shí)際上并沒(méi)有加速任務(wù)的實(shí)際分析部分。相反,它是一個(gè)壓縮/解壓縮加速器,準(zhǔn)備用于數(shù)據(jù)庫(kù),以便可以在內(nèi)存中操作它們,而無(wú)需大量的CPU性能成本。
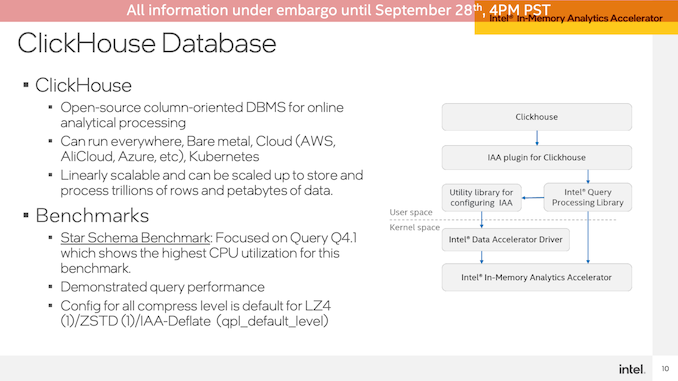
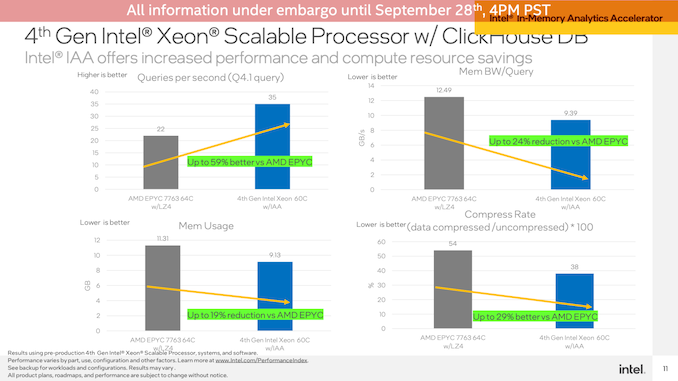
在ClickHouse DB上運(yùn)行演示,該場(chǎng)景演示了Sapphire Rapids系統(tǒng)與AMD EPYC系統(tǒng)相比,每秒查詢數(shù)達(dá)到59%的性能優(yōu)勢(shì)(Intel沒(méi)有運(yùn)行僅限軟件的Intel設(shè)置),并且總體上減少了內(nèi)存帶寬使用量和內(nèi)存使用量。
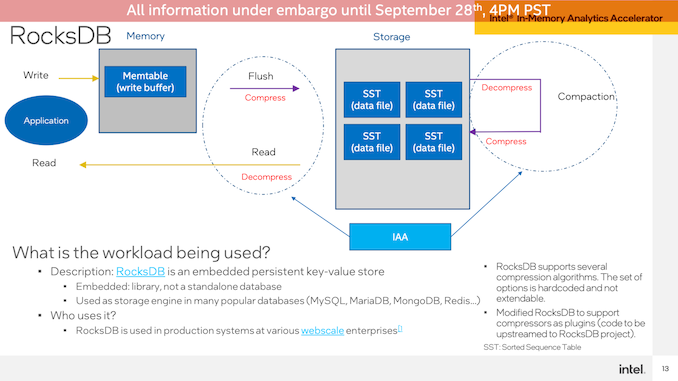
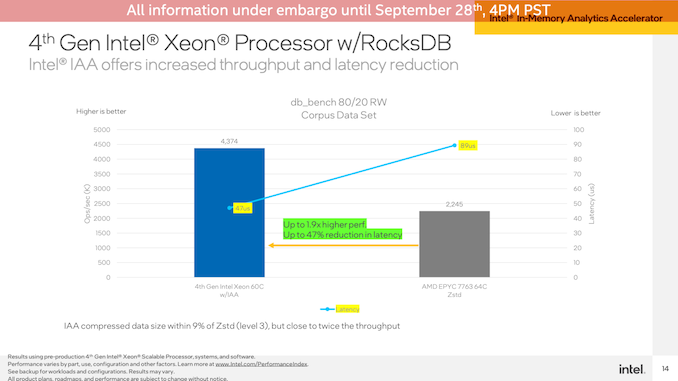
第二次IAA演示是在RocksDB上進(jìn)行的,使用相同的Intel和AMD系統(tǒng)。Intel再次展示了IAA加速SPR系統(tǒng),其性能提高了1.9倍,延遲幾乎降低了一半。

高級(jí)矩陣擴(kuò)展演示
Intel設(shè)置的最后一個(gè)演示站配置為顯示Advanced Matrix Extensions(AMX)和Data Streaming Accelerator(DSA)。
從AMX開始,Intel使用TensorFlow和ResNet50神經(jīng)網(wǎng)絡(luò)運(yùn)行圖像分類基準(zhǔn)測(cè)試。該測(cè)試在CPU上使用了非加速的FP32操作,AVX-512在Sapphire Rapids上加速了INT8,最后AMX也在Sappphire Rapid上加速了INT8。
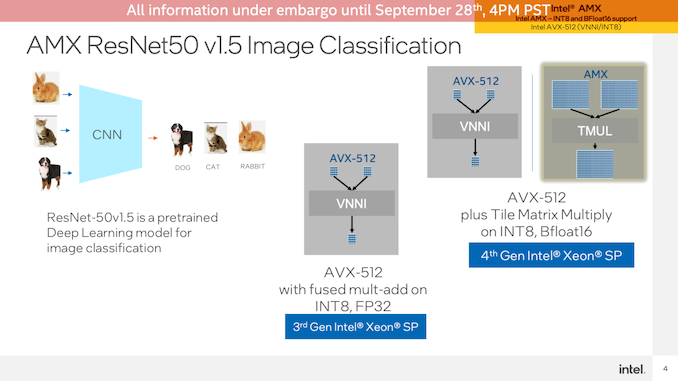

這是加速器的又一次爆炸。由于CPU內(nèi)核上的AMX塊,Sapphire Rapids系統(tǒng)在batch size為1的AVX-512 VNNI模式下的性能提高了2倍,而在bach size為16的情況下,性能提高了兩倍以上。當(dāng)然,與EPYC CPU相比,這種情況看起來(lái)更適合Intel,因?yàn)楫?dāng)前Milan處理器不提供AVX-512VNNI。這里的總體性能提升不如從純CPU升級(jí)到AVX-512,但AVX-512s本身已經(jīng)部分成為矩陣加速塊(除其他外)。
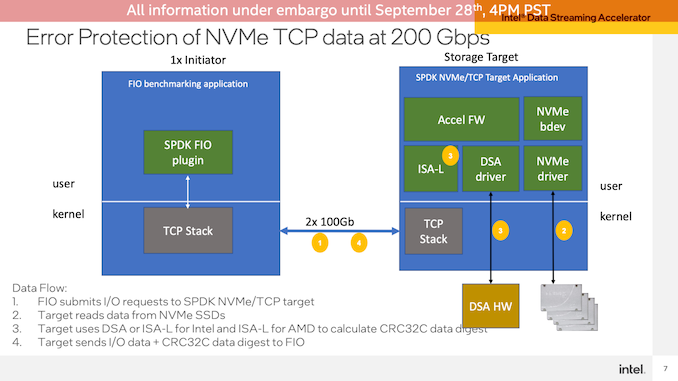
數(shù)據(jù)流加速器演示
最后,Intel演示了數(shù)據(jù)流加速器(DSA)塊,該塊將在Sapphire Rapids上展示專用的加速器塊。在這個(gè)測(cè)試中,Intel使用FIO設(shè)置了一個(gè)網(wǎng)絡(luò)傳輸演示,讓客戶端從Sapphire Rapids服務(wù)器讀取數(shù)據(jù)。這里使用DSA來(lái)卸載用于TCP數(shù)據(jù)包的CRC32計(jì)算,這一操作在Intel測(cè)試的非常高的數(shù)據(jù)速率(2x100GbE連接)下,CPU需求迅速增加。
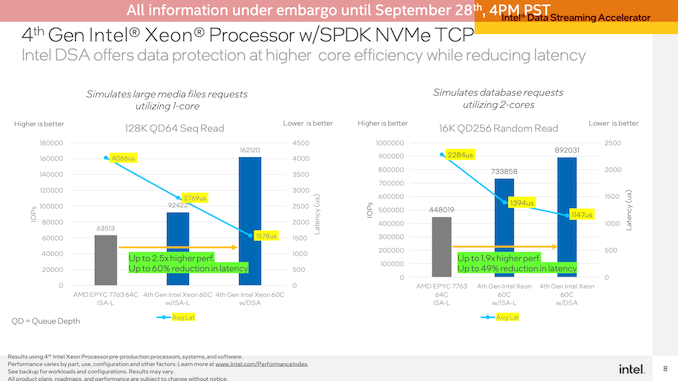
這里使用單個(gè)CPU內(nèi)核來(lái)展示效率(因?yàn)閹讉€(gè)CPU內(nèi)核就足以使鏈路飽和),與在相同工作負(fù)載上僅使用Intel優(yōu)化的ISA-L庫(kù)相比,DSA塊允許Sapphire Rapids在128K QD64順序讀取上提供76%的IOPS。EPYC系統(tǒng)的領(lǐng)先優(yōu)勢(shì)甚至更大,DSA的延遲遠(yuǎn)低于2000 us。
使用較小的16K QD256隨機(jī)讀取,在2個(gè)CPU內(nèi)核上運(yùn)行,也進(jìn)行了類似的測(cè)試。DSA的性能優(yōu)勢(shì)在這里沒(méi)有那么大——與Sapphire Rapids上的優(yōu)化軟件相比,只有22%——但與EPYC相比,它的優(yōu)勢(shì)更大,延遲更低。
這就是:在Intel的第4代Xeon(Sapphire Rapids)CPU上首次發(fā)布專用加速塊(和AMX)的新聞演示。我們看到了它,它確實(shí)存在,它是Sapphire Rapids計(jì)劃從明年開始為客戶帶來(lái)的一切的冰山一角。
鑒于特定于領(lǐng)域的加速器的性質(zhì)和目的,我覺(jué)得這里沒(méi)有什么應(yīng)該讓普通技術(shù)讀者感到驚訝的。DSA的存在正是為了加速專用工作負(fù)載,特別是那些CPU和/或能源密集型工作負(fù)載,這就是Intel在這里所做的。隨著服務(wù)器市場(chǎng)的競(jìng)爭(zhēng)預(yù)計(jì)將成為CPU總體性能的一個(gè)熱點(diǎn),這些加速塊是Intel為其Xeon處理器增加更多價(jià)值的一種方式,并且在AMD和其他推出更多CPU內(nèi)核的競(jìng)爭(zhēng)對(duì)手中脫穎而出。
預(yù)計(jì)在未來(lái)幾個(gè)月內(nèi),隨著英特爾最終將推出下一代服務(wù)器CPU,Sapphire Rapids將有更多的應(yīng)用。
審核編輯 :李倩
-
英特爾
+關(guān)注
關(guān)注
61文章
10192瀏覽量
174619 -
cpu
+關(guān)注
關(guān)注
68文章
11074瀏覽量
216932 -
加速器
+關(guān)注
關(guān)注
2文章
827瀏覽量
39095
原文標(biāo)題:英特爾Sapphire Rapids硬件加速器的作用大揭秘
文章出處:【微信號(hào):算力基建,微信公眾號(hào):算力基建】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
高壓放大器在粒子加速器研究中的應(yīng)用

粒子加速器?——?科技前沿的核心裝置

基于雙向塊浮點(diǎn)量化的大語(yǔ)言模型高效加速器設(shè)計(jì)
第三期 “亞馬遜云科技創(chuàng)業(yè)加速器” 正式啟動(dòng)
小型加速器中子源監(jiān)測(cè)系統(tǒng)解決方案

Sapphire Rapids與OpenVINO?工具套件是否兼容?
EE-436:使用ADSP-SC59x/2159x高性能FIR/IIR加速器


RAPIDS cuDF將pandas提速近150倍

IBM將在云平臺(tái)部署AMD加速器
磁調(diào)制式電流傳感器在粒子加速器中的應(yīng)用
具有邊沿速率加速器的TXB和TXS電壓電平轉(zhuǎn)換器的注意事項(xiàng)
數(shù)據(jù)中心應(yīng)用中適用于Intel Xeon Sapphire Rapids可擴(kuò)展處理器的負(fù)載點(diǎn)解決方案
利用邊沿速率加速器和自動(dòng)感應(yīng)電平轉(zhuǎn)換器
數(shù)據(jù)中心應(yīng)用中適用于Intel? Xeon? Sapphire Rapids可擴(kuò)展處理器的負(fù)載點(diǎn)解決方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論