 MLPerf世界紀錄技術分享:優化卷積合并算法提升Resnet50推理性能
MLPerf世界紀錄技術分享:優化卷積合并算法提升Resnet50推理性能
MLPerf是一套衡量機器學習系統性能的權威標準,將在標準目標下訓練或推理機器學習模型的時間,作為一套系統性能的測量標準。MLPerf推理任務包括圖像識別(ResNet50)、醫學影像分割(3D-UNet)、目標物體檢測(SSD-ResNet34)、語音識別(RNN-T)、自然語言理解(BERT)以及智能推薦(DLRM)。在MLPerf V2.0推理競賽中,浪潮AI服務器基于ImageNet數據集在離線場景中運行Resnet50,達到了449,856 samples/s的計算性能,位居世界第一。
本文將介紹浪潮在MLPerf推理競賽中使用的卷積合并計算算法。
Resnet是殘差網絡(Residual Network)的縮寫,該系列網絡廣泛用于目標分類等領域以及作為計算機視覺任務主干經典神經網絡的一部分,典型的網絡有Resnet50、Resnet101等。在Resnet神經網絡中,主要計算算子是卷積計算層。Resnet50神經網絡具有4組殘差結構,這4組殘差結構包含48個卷積算子,通過設計卷積算子的計算算法,提高卷積算子的計算性能,可以減少Resnet50推理過程中的延遲。基于最新GPU單卡的性能測試顯示,在BatchSize=2048的情況下,優化后的卷積合并優化算法相比原算法可帶來14.6%的性能提升。
MLPerf Resnet50推理流程
在MLPerf V2.0推理測試中,Resnet50模型需要在ImageNet2012測試集上達到FP32精度(76.46%)的99%以上。數據中心賽道設置了離線(Offline)與在線(Server)兩種模式,其中離線模式會產生一次推理時間大于10分鐘的samples請求,可直接反映機器和算法的推理性能。
Resnet50推理流程如下。首先在ImageNet2012測試集中讀取數據,并進行數據預處理,隨后數據會加載到TensorRT中進行實際的推理測試。測試分為兩方面,一是測試模型的精度;二是產生一次推理請求,TensorRT會將請求中的圖片全部推理完成得到總時間,根據計算時間得到每秒推理的樣本數量,即為最終的成績。
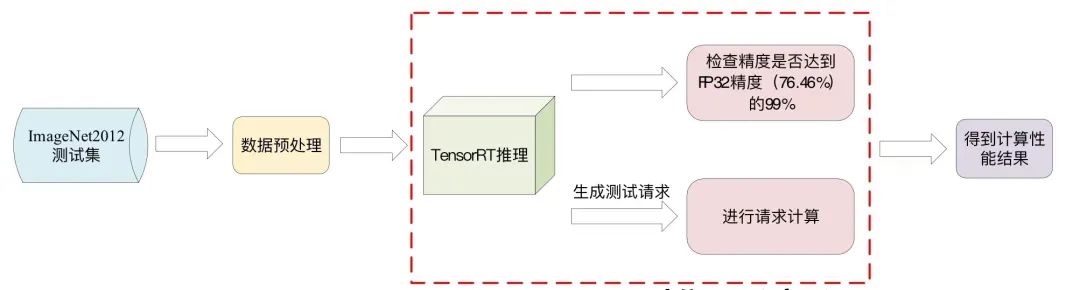
圖1 MLPerf Resnet50推理流程▲
卷積合并計算算法
▏2.1 算法優化思路
在GPU上運行Resnet50圖像推理模型時,需要將每一個算子(卷積、池化、全連接等)放在GPU的Kernel中進行算子計算,由于GPU上運行Kernel時共享內存以及寄存器的資源有限,不可能將所有的計算過程數據放到Kernel中,而GPU的全局內存一般都很大,所以會將比較大的過程數據放在全局內存中。在進行推理時,根據Kernel的計算將數據按需從全局內存讀取到Kernel中進行計算,每個算子在計算時會不可避免地產生Kernel與全局內存的數據交換,由于全局內存的讀寫訪問延遲較大,會使算子計算性能下降。
對于每個算子的Kernel計算,會產生兩部分的全局內存訪問,一部分是最開始的全局內存讀取,另一部分是Kernel計算完成后的全局內存寫回。為了降低全局內存訪問帶來的性能影響,有如下兩種辦法:
一是采用算子合并的方式。默認的程序會將每個算子都放在單獨的Kernel中進行計算,每個算子都會產生全局內存讀和寫兩次訪問。如果將兩個算子放在一個Kernel中進行計算,對于連續的兩個卷積計算,可以減少第一個卷積算子的寫回以及第二個算子的讀取;對于卷積與Shortcut的合并,可以減少一次全局內存的寫回操作,通過減少全局內存的訪問可以提高程序的計算性能;
二是根據GPU不同架構的計算特性對Kernel的內部計算進行合理的優化設計。當不可避免地需要對全局內存進行訪問時,做到全局內存進行連續線程的融合讀取,充分利用向量化讀取等加速對全局內存的訪問,同時優化計算流程,通過Double buffer用計算來隱藏內存的訪問延遲,對于需求較晚的全局內存數據,也可以通過GPU的新特性-全局內存的異步復制來隱藏數據讀取過程。
本文主要針對MLPerf推理中Resnet50卷積神經網絡的第二組殘差結構中的部分算子進行計算合并,在充分考慮GPU計算特性前提下,進行合理的算法設計,提高Resnet50卷積神經網絡的性能。
▏2.2 Resnet50合并計算算法
在Resnet50神經網絡中,第二組殘差結構有Res3.1、Res3.2、Res3.3、Res3.4,共四部分的卷積計算,其中Res3.2、Res3.3、Res3.4三部分計算結構一樣,如下圖所示:
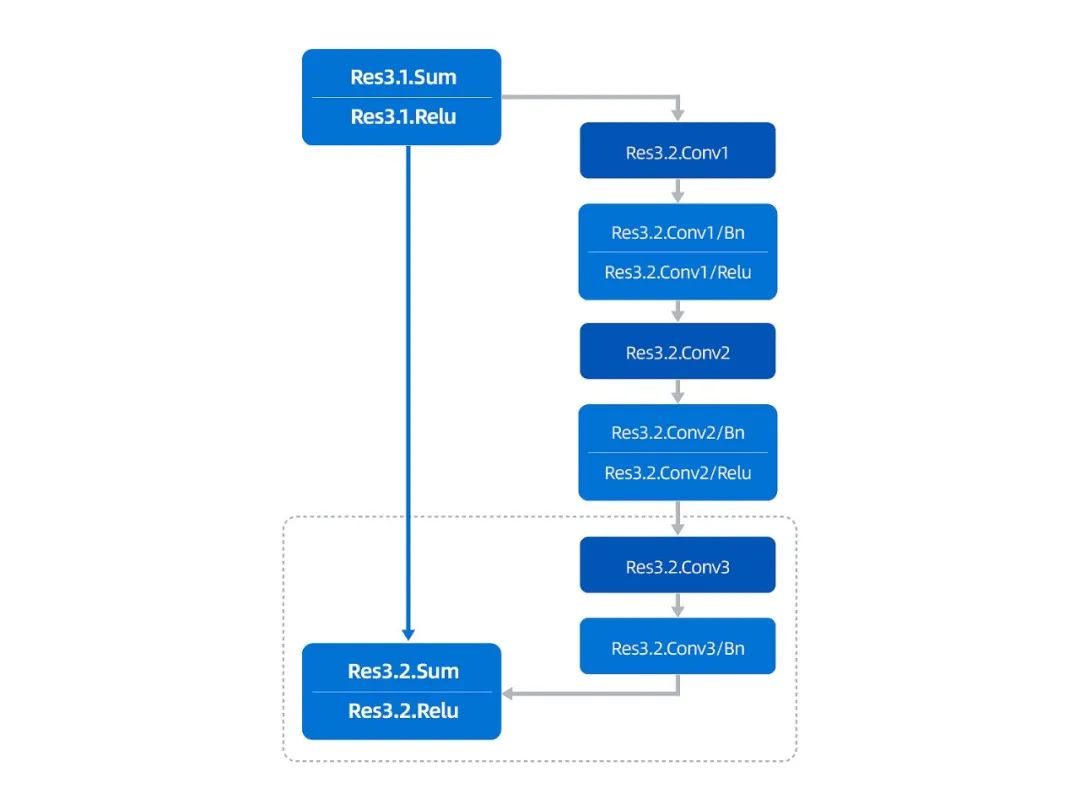
圖2 Resnet50中第二組殘差結構Res3.2示意圖▲
可以看到,Res3.1的輸出(input)作為Res3.2部分的輸入,輸入后會有兩部分分支,在右部分的分支中,會先后計算Conv1,Conv2,Conv3三個卷積,其中Conv1,Conv2兩個卷積后面都包含Bn和Relu過程,Conv3后面會有Bn的計算過程;在右邊分支計算完成后,會與input進行Shortcut操作,主要進行的是與輸入數據Sum和Relu操作,兩部分結果經過Shortcut操作后會得到Res3.2的輸出完成這部分的計算。
本文介紹的合并算法對圖2虛線框中的計算進行合并,主要是對Conv3以及Shortcut的過程進行合并,包含Conv3+Bn+Sum+Relu過程。
卷積合并算法在GPU加速卡上的實現
Res3.2的計算參數主要如下:
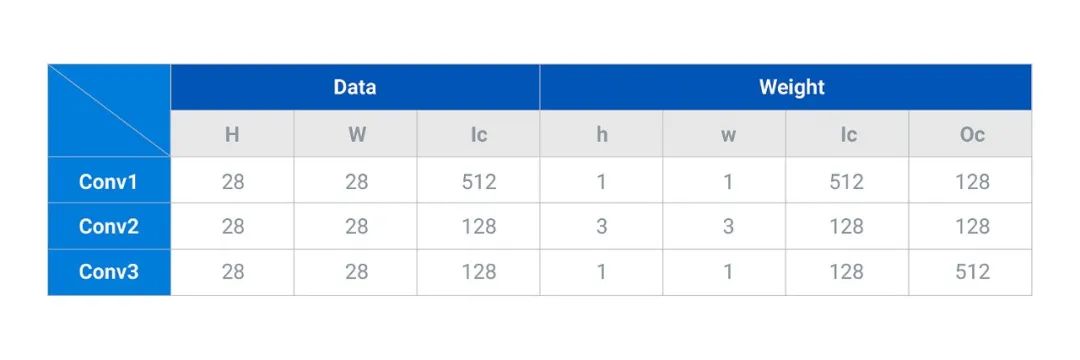
通過上表可以看到,Conv3輸入Data的H*W為28*28,輸入通道Ic為128,輸入的權重Weight的h*w為1*1,輸入通道Ic為128,輸出通道Oc為512;Shortcut的輸入同Conv1,其中H*W為28*28,輸入通道Ic為512;兩部分計算合并之后的輸出Output的H*W為28*28,通道Oc為512。
▏ 3.1 關于data、weight、output的layout變換
本文采用的計算數據類型為int8,因此下文介紹的所有內容都是基于int8開展的優化。
算法對data以及weight進行了提前處理以適應GPU的計算特性,主要處理如下:
對于data,原始layout為[B, H, W, Ic]=[B, 28, 28, 128],算法將Ic=128以32為單位進行拆分為4組,形成[B, 4, H, W, Ic/32]=[B, 4(I1), 28, 28, 32(I2)]的layout,這樣做的目的是32個int8可以組成16B共128位數據的聯合向量化讀寫,提高GPU中全局內存的通信速度。
對于weight,由于h*w=1*1,因此本文后續不再表示h*w,默認的weight的layout為[Ic, Oc]=[128, 512],算法將Ic以32為單位進行拆分為4組,將4放在左數第二維,將32放在左數第四維,這樣做的目的也是為了程序在訪問全局內存時做到16B共128位數據的聯合向量化讀寫;算法將Oc以128為單位進行拆分為4組,將4放在左數第一維,將128放在左數第三維,這樣做的目的是將Oc拆成了4組放在了不同的block中進行計算,這樣在每個block進行計算的時候可以順序的由全局內存加載weight,不會產生數據內存位置的跳躍,這部分會在后面block的劃分中進行介紹,這樣就形成[O1, I1, O2, I2] =[4, 4, 128, 32]的weight的layout。
對于output,原始layout為[B, H, W, Oc]=[B, 28, 28, 512],這部分數據類似于輸入data,將Oc以32為單位進行拆分為16組,形成layout為[B, 16, H, W, Oc/32]=[B, 16(O1), 28, 28, 32(O2)]。
▏ 3.2 關于Grid以及Block的并行劃分
對于Grid的劃分,首先是x維度,由上文可知,對于Conv3的Oc為512,本文將Oc劃分為4組放到Grid.x維度,每組計算的Oc為128;對于y維度,將H*W=28*28=784分為49組放到Grid.y維度,每組計算的HW為16;對于z維度,將B分為B/4組放到Grid.z維度,每組計算B的數量是4。這樣經過劃分,Grid的數量為[Grid.x, Grid.y, Grid.z]=[4, 49, B/4],即共有4*49*B/4組計算同時并行進行。GPU上SM數量有108個,當B≥4時,一個kernel共需要啟動大于4*49*4/4=196個Block,完全滿足Grid維度并行度的要求。
對于Block中的劃分,GPU中一個SM的warp schedule為4個,因此一個block中線程數量至少大于或等于128,為了實現更好的并行度,算法選擇一個Block中設置8個warp共256個線程。
▏ 3.3 關于Block內部計算層次劃分
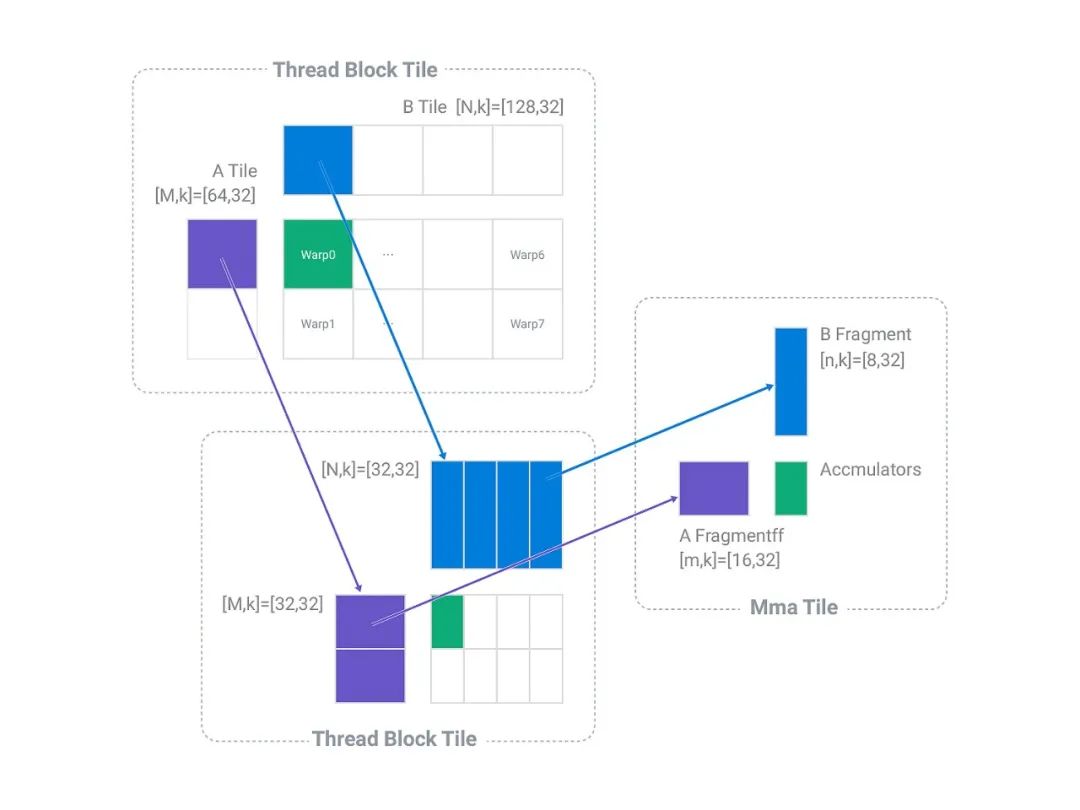
圖3 Block內部計算層析劃分▲
由上文可知,一個Block中劃分的Output的計算shape為[B, H*W, Oc]=[4, 16, 128],由于在1*1卷積計算中B維度與HW維度具有同等地位,因此將BHW合并為一個維度,此時本文用M表示BHW維度,即M=BHW=4*16=64,用N表示Oc維度,即N=Oc=128,此時一個Block中的計算維度變為[M,N]=[64, 128]。
由前述data的layout的變換可知形成[B, 4, H, W, Ic/32]=[B, 4, 28, 28, 32]的layout,由于Grid.y以及Grid.x對B維度以及HW維度進行了劃分,此時一個Block中data的輸入數據為[B, I1, HW, I2]=[4, 4, 16, 32],用上段所述BHW合并為1維用M表示,即M=B*HW=4*16=64,K表示I1*I2維度,即K=I1*I2=128,則此時一個Block中data的計算維度變為[M, K]=[64, 128]。
由前述weight的layout的變換可知,weight的layout為[O1, I1, O2, I2]=[4, 4, 128, 32],由于對Oc按照32為單位劃分4組在Grid.x維度,因此每個Block中計算的Oc為128,此時一個Block中的weight的計算數據為[I1, O2, I2] =[4, 128, 32],用N表示O2維度,即N=O2=128,用K表示I1*I2維度,即K=I1*I2=128,則此時一個Block中weight的計算維度變為[N, K]=[128, 128]。
一個Block中實際要進行的計算就變為一個矩陣乘data[M, K]點乘weight[N, K]等于output[M, N],即[64, 128]﹒[128,128]=[64, 128],共4*49*B/4個Block并行完成所有整個卷積合并的計算,其中data的實際維度為[B, I1, HW, I2]=[4, 4, 16, 32],weight的實際維度為[I1, O, I2]=[4, 128, 32]。
經過前面的劃分,一個Thread Block層次實際計算量為[64, 128]﹒[128,128]=[64, 128]。
為了加速int8矩陣乘的計算,程序采用了CUDA中mma進行加速計算,其中mma的計算形狀為[m ,n ,k]=[16, 8, 32],為了配合共享內存,寄存器以及mma形狀的匹配,程序將內積方向的K維度128拆分為2組64進行計算,每組64進一步拆分為2組32(k)進行計算,這樣最基礎的Thread Block層次進行的計算就變為圖3中左上角虛線框中所示的[M, k]﹒[N, k]=[M ,N]即[64, 32]﹒[128, 32]=[64 ,128],由于一個Block中設置warp的數量為8,8個warp會對Thread Block中的計算任務進行劃分,每個warp計算任務為[32, 32]﹒[32, 32]=[32, 32]的矩陣乘,經過內積方向的4次32的循環,在warp level便可以將內積方向K=128完全計算得[M, N]=[32, 32]的計算結果,則8個warp合并可得[M, N]=[64, 128]的計算結果。
如上文所述,程序將內積方向的K維度128拆分為2組64進行計算,每組64進一步拆分為2組32(k)進行計算。這么做的目的是將data以及weight的全局內存加載變成了Double buffer模式,即首先將第一組的數據由全局內存加載到共享內存,然后在利用第一組的數據進行計算前,便提交第二組數據由全局內存加載到共享內存的過程,這樣可以利用第一組數據的計算過程時間來隱藏第二組數據的全局內存加載到共享內存的過程的時間,整體流程示意圖如下:
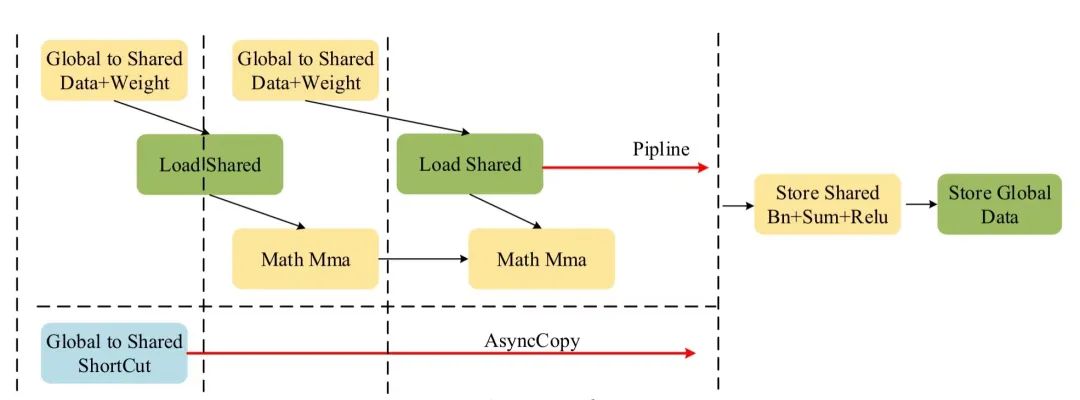
圖4 程序整體流程圖▲
如前所述,每個warp計算任務為[32, 32]﹒[32, 32]=[32, 32]的矩陣乘,因此在warp的計算層次配合[m ,n ,k]=[16, 8, 32]的形狀,需要進行row=2,col=4,共row*col=8次mma的計算才可以得到warp 層次的計算結果,在計算時配合ldmatrix的使用可以進一步提高程序的計算性能。
對于Mma層次的計算,根據mma的形狀,單次計算為[m , k]﹒[n, k]=[16, 32]﹒[8, 32]=[16, 8]。
▏ 3.4 Shoutcut的合并計算
經過以上計算,每個Block程序會得到Conv3的[M, N]=[64, 128]的計算結果,由于程序對Bn+Sum+Relu進行了合并,因此需要對Res3.1輸出的原始數據進行加載。根據Grid[x , y, z]的劃分,可以相應的得到Shortcut的數據偏移,為了隱藏這部分數據在全局內存加載到共享內存時通信延遲,程序利用了GPU異步復制(pipeline_memcpy_async)的新特性,在程序的最開始便提交了這部分數據的加載,這樣可以最大程度上利用計算的時間同時進行數據的加載以隱藏Shortcut的通信延遲,如圖4所示。完成數據的加載后,會以warp為單位對每一個計算結果進行Bn+Sum+Relu的操作,最后將數據由寄存器寫回共享內存,再寫回全局內存完成整個卷積合并算法的計算。
性能提升效果
根據上文介紹的卷積合并優化算法,在TensorRT中增加了關于卷積合并算法的plugin以替代原始算法,在最新GPU單卡進行Conv3+Bn+Sum+Relu性能測試,在BatchSize=2048的情況下,原算法的性能為123TOPS,經過優化后的卷積合并優化算法性能為141TOPS,算子相比較原算法可以帶來14.6%的性能提升。通過合并Res3.2、Res3.3、Res3.4三部分Conv3+Bn+Sum+Relu算子合并,可將Resnet50推理性能提升1%-2%。同樣該算法合并思路可以用到其他殘差結構中,通過合理的算法設計帶來整體的程序性能提升。
在MLPerf V2.0推理競賽中,浪潮通過軟件與硬件優化,基于ImageNet數據集Resnet50模型,在Offline場景中達到了449,856 samples/s的計算性能,位居世界第一。
審核編輯:湯梓紅
-
浪潮
+關注
關注
1文章
474瀏覽量
24566 -
resnet
+關注
關注
0文章
13瀏覽量
3298 -
MLPerf
+關注
關注
0文章
36瀏覽量
796
原文標題:MLPerf世界紀錄技術分享:優化卷積合并算法提升Resnet50推理性能
文章出處:【微信號:浪潮AIHPC,微信公眾號:浪潮AIHPC】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
NVIDIA擴大AI推理性能領先優勢,首次在Arm服務器上取得佳績

NVIDIA打破AI推理性能記錄
Eshow網絡直播平臺與世界吉尼斯世界紀錄
軟硬件協同優化,平頭哥玄鐵斬獲MLPerf四項第一
Arm Neoverse V1的AWS Graviton3在深度學習推理工作負載方面的作用
求助,為什么將不同的權重應用于模型會影響推理性能?
如何提高YOLOv4模型的推理性能?
【KV260視覺入門套件試用體驗】四、學習過程梳理&DPU鏡像&Resnet50

NVIDIA發布最新Orin芯片提升邊緣AI標桿
MLPerf是邊緣AI推理的新行業基準
深度解析MLPerf競賽Resnet50訓練單機最佳性能
基于改進ResNet50網絡的自動駕駛場景天氣識別算法


基于RV1126開發板的resnet50訓練部署教程






 工商網監
工商網監
評論