") 介紹3種實(shí)現(xiàn)Nested-Loop Join算法的方法
介紹3種實(shí)現(xiàn)Nested-Loop Join算法的方法
在MySQL的實(shí)現(xiàn)中,Nested-Loop Join有3種實(shí)現(xiàn)的算法:
- Simple Nested-Loop Join:
簡(jiǎn)單嵌套循環(huán)連接 - Block Nested-Loop Join:
緩存塊嵌套循環(huán)連接 - Index Nested-Loop Join:
索引嵌套循環(huán)連接
一、原理篇
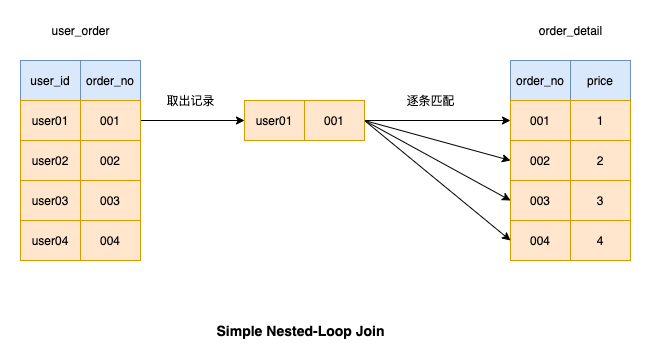
1、Simple Nested-Loop Join
比如:
SELECT *
FROM user u
LEFT JOIN class c ON u.id = c.user_id
我們來看一下當(dāng)進(jìn)行 join 操作時(shí),mysql是如何工作的:

當(dāng)我們進(jìn)行l(wèi)eft join連接操作時(shí),左邊的表是 「驅(qū)動(dòng)表」 ,右邊的表是**「被驅(qū)動(dòng)表」**
特點(diǎn):
Simple Nested-Loop Join 簡(jiǎn)單粗暴容易理解,就是通過雙層循環(huán)比較數(shù)據(jù)來獲得結(jié)果,但是這種算法顯然太過于粗魯,如果每個(gè)表有1萬條數(shù)據(jù),那么對(duì)數(shù)據(jù)比較的次數(shù)=1萬 * 1萬 =1億次,很顯然這種查詢效率會(huì)非常慢。
「這個(gè)全是磁盤掃描!」
?因?yàn)槊看螐尿?qū)動(dòng)表取數(shù)據(jù)比較耗時(shí),所以MySQL即使在沒有索引命中的情況下也并沒有采用這種算法來進(jìn)行連接操作,而是下面這種!
?
2、Block Nested-Loop Join
同樣以上面的sql為例,我們看下mysql是如何工作的
SELECT *
FROM user u
LEFT JOIN class c ON u.id = c.user_id

因?yàn)槊看螐?code>驅(qū)動(dòng)表取一條數(shù)據(jù)都是磁盤掃描所有比較耗時(shí)。
這里就做了優(yōu)化就是 「每次從驅(qū)動(dòng)表取一批數(shù)據(jù)放到內(nèi)存中,然后對(duì)這一批數(shù)據(jù)進(jìn)行匹配操作」 。
這批數(shù)據(jù)匹配完畢,再?gòu)尿?qū)動(dòng)表中取一批數(shù)據(jù)放到內(nèi)存中,直到驅(qū)動(dòng)表的數(shù)據(jù)全都匹配完畢。
這塊內(nèi)存在MySQL中有一個(gè)專有的名詞,叫做 join buffer,我們可以執(zhí)行如下語句查看 join buffer 的大小
show variables like '%join_buffer%'

另外,Join Buffer緩存的對(duì)象是什么,這個(gè)問題相當(dāng)關(guān)鍵和重要。
?Join Buffer存儲(chǔ)的并不是驅(qū)動(dòng)表的整行記錄,具體指所有參與查詢的列都會(huì)保存到Join Buffer,而不是只有Join的列。
?
比如下面sql
SELECT a.col3
FROM a JOIN b ON a.col1 = b.col2
WHERE a.col2 > 0 AND b.col2 = 0
上述SQL語句的驅(qū)動(dòng)表是a,被驅(qū)動(dòng)表是b,那么存放在Join Buffer中的列是所有參與查詢的列,在這里就是(a.col1,a.col2,a.col3)。
也就是說查詢的字段越少,Join Buffer可以存的記錄也就越多!
變量join_buffer_size的默認(rèn)值是256K,顯然對(duì)于稍復(fù)雜的SQL是不夠用的。好在這個(gè)是會(huì)話級(jí)別的變量,可以在執(zhí)行前進(jìn)行擴(kuò)展。
建議在會(huì)話級(jí)別進(jìn)行設(shè)置,而不是全局設(shè)置,因?yàn)楹茈y給一個(gè)通用值去衡量。另外,這個(gè)內(nèi)存是會(huì)話級(jí)別分配的,如果設(shè)置不好容易導(dǎo)致因無法分配內(nèi)存而導(dǎo)致的宕機(jī)問題。
-- 調(diào)整到1M
set session join_buffer_size = 1024 * 1024 * 1024;
-- 再執(zhí)行查詢
SELECT a.col3
FROM a JOIN b ON a.col1 = b.col2
WHERE a.col2 > 0 AND b.col2 = 0
3、Index Nested-Loop Join
當(dāng)我們了解**「Block Nested-Loop Join」** 算法,我們發(fā)現(xiàn)雖然可以將驅(qū)動(dòng)表的數(shù)據(jù)放入 「Join Buffer」 中,但是緩存中的每條記錄都要和被驅(qū)動(dòng)表的所有記錄都匹配一遍,也會(huì)非常耗時(shí),所以我們應(yīng)該如何提高被驅(qū)動(dòng)表匹配的效率呢?
其實(shí)很簡(jiǎn)單 就是給被驅(qū)動(dòng)表連接的列加上索引,這樣匹配的過程就非常快,如圖所示

上面圖中就是先匹配索引看有沒有命中的數(shù)據(jù),有命中數(shù)據(jù)再回表查詢這條記錄,獲取其它所需要的數(shù)據(jù),但列的數(shù)據(jù)在索引中都能獲取那都不需要回表查詢,效率更高!
二、SQL示例
1、新增表和填充數(shù)據(jù)
-- 表1 a字段加索引 b字段沒加
CREATE TABLE `t1` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主鍵',
`a` int DEFAULT NULL COMMENT '字段a',
`b` int DEFAULT NULL COMMENT '字段b',
PRIMARY KEY (`id`),
KEY `idx_a` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- 表2
create table t2 like t1;
-- t1插入10000條數(shù)據(jù) t2插入100條數(shù)據(jù)
drop procedure if exists insert_data;
delimiter ;;
create procedure insert_data()
begin
declare i int;
set i = 1;
while ( i <= 10000 ) do
insert into t1(a,b) values(i,i);
set i = i + 1;
end while;
set i = 1;
while ( i <= 100) do
insert into t2(a,b) values(i,i);
set i = i + 1;
end while;
end;;
delimiter ;
call insert_data();
2、Block Nested-Loop Join算法示例
-- b字段沒有索引
explain select t2.* from t1 inner join t2 on t1.b= t2.b;
-- 執(zhí)行結(jié)果
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------------------------------------------+
| 1 | SIMPLE | t2 | NULL | ALL | NULL | NULL | NULL | NULL | 100 | 100.00 | NULL |
| 1 | SIMPLE | t1 | NULL | ALL | NULL | NULL | NULL | NULL | 10337 | 10.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+-------+----------+----------------------------------------------------+
從執(zhí)行計(jì)劃我們可以得出一些結(jié)論:
驅(qū)動(dòng)表是t2,被驅(qū)動(dòng)表是t1。所以使用 inner join 時(shí),排在前面的表并不一定就是驅(qū)動(dòng)表。- Extra 中 的 「Using join buffer (Block Nested Loop)」 說明該關(guān)聯(lián)查詢使用的是 BNLJ 算法。
上面的sql大致流程是:
- 將 t2 的所有數(shù)據(jù)放入到
join_buffer中 - 將 join_buffer 中的每一條數(shù)據(jù),跟表t1中所有數(shù)據(jù)進(jìn)行比較
- 返回滿足join 條件的數(shù)據(jù)
3、Index Nested-Loop Join 算法
-- a字段有索引
EXPLAIN select * from t1 inner join t2 on t1.a= t2.a;
-- 執(zhí)行結(jié)果
+----+-------------+-------+------------+------+---------------+-------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+-------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | t2 | NULL | ALL | idx_a | NULL | NULL | NULL | 100 | 100.00 | Using where |
| 1 | SIMPLE | t1 | NULL | ref | idx_a | idx_a | 5 | mall_order.t2.a | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+-------+---------+-----------------+------+----------+-------------+
從執(zhí)行計(jì)劃我們可以得出一些結(jié)論:
- 我們可以看出 t1的type不在是all而是ref,說明不在是全表掃描,而是走了idx_a的索引。
- 這里并沒有出現(xiàn) 「Using join buffer (Block Nested Loop)」 ,說明走的是Index Nested-Loop Join。
上面的sql大致流程是:
- 從表 t2 中讀取一行數(shù)據(jù)
- 從第 1 步的數(shù)據(jù)中,取出關(guān)聯(lián)字段 a,到表 t1 idx_a 索引中查找;
- 從idx_a 索引上找到滿足條件的數(shù)據(jù),如果查詢數(shù)據(jù)在索引樹都能找到,那就可以直接返回,否則回表查詢剩余字段屬性再返回。
- 返回滿足join 條件的數(shù)據(jù)
我們發(fā)現(xiàn)這里效率最大的提升在于,t1表中rows=1,也就是說因?yàn)閕dx_a 索引的存在,不需要把t1每條數(shù)據(jù)都遍歷一遍,而是通過索引1次掃描可以認(rèn)為最終只掃描 t1 表一行完整數(shù)據(jù)。
三、join優(yōu)化總結(jié)
根據(jù)上面的知識(shí)點(diǎn)我們可以總結(jié)以下有關(guān)join優(yōu)化經(jīng)驗(yàn):
在關(guān)聯(lián)查詢的時(shí)候,盡量在被驅(qū)動(dòng)表的關(guān)聯(lián)字段上加索引,讓MySQL做join操作時(shí)盡量選擇INLJ算法。
2)小表做驅(qū)動(dòng)表!
當(dāng)使用left join時(shí),左表是驅(qū)動(dòng)表,右表是被驅(qū)動(dòng)表,當(dāng)使用right join時(shí),右表是驅(qū)動(dòng)表,左表是被驅(qū)動(dòng)表,當(dāng)使用join時(shí),mysql會(huì)選擇數(shù)據(jù)量比較小的表作為驅(qū)動(dòng)表,大表作為被驅(qū)動(dòng)表,如果說我們?cè)?join的時(shí)候 明確知道哪張表是小表的時(shí)候,可以用 「straight_join」 寫法固定連接驅(qū)動(dòng)方式,省去mysql優(yōu)化器自己判斷的時(shí)間。
「對(duì)于小表定義的明確」 :
在決定哪個(gè)表做驅(qū)動(dòng)表的時(shí)候,應(yīng)該是兩個(gè)表按照各自的條件過濾,過濾完成之后,計(jì)算參與 join 的各個(gè)字段的總數(shù)據(jù)量,數(shù)據(jù)量小的那個(gè)表,就是“小表”,應(yīng)該作為驅(qū)動(dòng)表。
3)在適當(dāng)?shù)那闆r下增大 join buffer 的大小,當(dāng)然這個(gè)最好是在會(huì)話級(jí)別的增大,而不是全局級(jí)別。
4)不要用 * 作為查詢列表,只返回需要的列!
這樣做的好處可以讓在相同大小的join buffer可以存更多的數(shù)據(jù),也可以在存在索引的情況下盡可能避免回表查詢數(shù)據(jù)。
審核編輯:劉清
-
MySQL
+關(guān)注
關(guān)注
1文章
849瀏覽量
27659
發(fā)布評(píng)論請(qǐng)先 登錄
FFT 算法的一種 FPGA 實(shí)現(xiàn)
DSP的實(shí)現(xiàn)方法
兩種典型的ADRC算法介紹
Apriori算法的一種優(yōu)化方法
3DES算法的FPGA高速實(shí)現(xiàn)
Viterbi譯碼器回溯算法實(shí)現(xiàn)

3種像素歷遍方法的比較和實(shí)現(xiàn)_Delphi教程
Join在Spark中是如何組織運(yùn)行的
SQL子查詢優(yōu)化是怎么回事

LOOP指令——匯編語言學(xué)習(xí)筆記3

如何優(yōu)化MySQL中的join語句
一文終結(jié)SQL子查詢優(yōu)化
大模型+多模態(tài)的3種實(shí)現(xiàn)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論