") 大模型+多模態(tài)的3種實(shí)現(xiàn)方法
大模型+多模態(tài)的3種實(shí)現(xiàn)方法
我們知道,預(yù)訓(xùn)練LLM已經(jīng)取得了諸多驚人的成就, 然而其明顯的劣勢是不支持其他模態(tài)(包括圖像、語音、視頻模態(tài))的輸入和輸出,那么如何在預(yù)訓(xùn)練LLM的基礎(chǔ)上引入跨模態(tài)的信息,讓其變得更強(qiáng)大、更通用呢?本節(jié)將介紹“大模型+多模態(tài)”的3種實(shí)現(xiàn)方法。
01
以LLM為核心,調(diào)用其他多模態(tài)組件
2023年5月,微軟亞洲研究院(MSRA)聯(lián)合浙江大學(xué)發(fā)布了HuggingGPT框架,該框架能夠以LLM為核心,調(diào)用其他的多模態(tài)組件來合作完成復(fù)雜的AI任務(wù)(更多細(xì)節(jié)可參見Yongliang Shen等人發(fā)表的論文“HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace”)。HuggingGPT框架的原理示意圖如圖1所示。下面根據(jù)論文中提到的示例來一步一步地拆解 HuggingGPT框架的執(zhí)行過程。
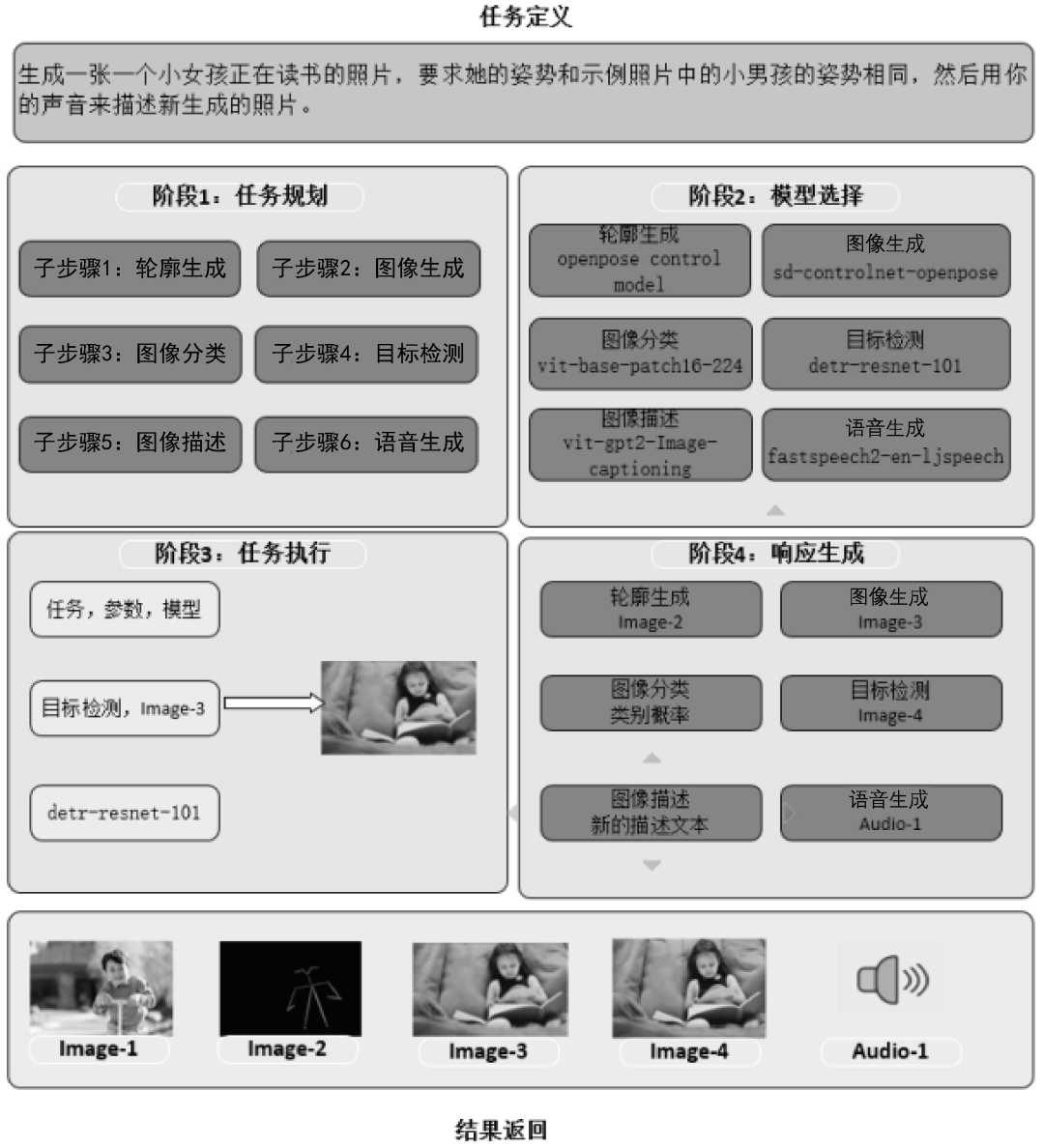
圖1
假如現(xiàn)在你要執(zhí)行這樣一個(gè)復(fù)雜的AI任務(wù):生成一張一個(gè)小女孩正在讀書的照片,要求她的姿勢和示例照片中的小男孩的姿勢相同,然后用你的聲音來描述新生成的照片。HuggingGPT框架把執(zhí)行這個(gè)復(fù)雜AI任務(wù)的過程分成了4個(gè)步驟。
(1)任務(wù)規(guī)劃(Task Planning)。使用LLM了解用戶的意圖,并將用戶的意圖拆分為詳細(xì)的執(zhí)行步驟。如圖5-10左上部分所示,將輸入指令拆分為6個(gè)子步驟。
子步驟1:根據(jù)小男孩的圖像Image-1,生成小男孩的姿勢輪廓Image-2。
子步驟 2:根據(jù)提示文本“小女孩正在讀書”及小男孩的姿勢輪廓Image-2生成小女孩的圖像Image-3。
子步驟3:根據(jù)小女孩的圖像Image-3,對圖像信息進(jìn)行分類。
子步驟4:根據(jù)小女孩的圖像Image-3,對圖像信息進(jìn)行目標(biāo)檢測,生成帶目標(biāo)框的圖像Image-4。
子步驟5:根據(jù)小女孩的圖像Image-3,對圖像信息進(jìn)行描述,生成描述文本,并在Image-4中完成目標(biāo)框和描述文本的配對。
子步驟6:根據(jù)描述文本生成語音Audio-1。
(2)模型選擇(Model Selection)。根據(jù)步驟(1)中拆分的不同子步驟,從Hugging Face平臺(tái)(一個(gè)包含多個(gè)模型的開源平臺(tái))中選取最合適的模型。對于子步驟1中的輪廓生成任務(wù),選取OpenCV的openpose control模型;對于子步驟2中的圖像生成任務(wù),選取sd-controlnet-openpose模型;對于子步驟3中的圖像分類任務(wù),選取谷歌的vit-base-patch16-224模型;對于子步驟4中的目標(biāo)檢測任務(wù),選取Facebook的detr-resnet-101模型;對于子步驟5中的圖像描述任務(wù),選取nlpconnect開源項(xiàng)目的vit-gpt2-Image-captioning模型;對于子步驟6中的語音生成任務(wù),選取Facebook的fastspeech2-en- ljspeech模型。
(3)任務(wù)執(zhí)行(Task Execution)。調(diào)用步驟(2)中選定的各個(gè)模型依次執(zhí)行,并將執(zhí)行的結(jié)果返回給LLM。
(4)響應(yīng)生成(Response Generation)。使用LLM對步驟(3)中各個(gè)模型返回的結(jié)果進(jìn)行整合,得到最終的結(jié)果并進(jìn)行輸出。
HuggingGPT框架能夠以LLM為核心,并智能調(diào)用其他多模態(tài)組件來處理復(fù)雜的AI任務(wù),原理簡單,使用方便,可擴(kuò)展性強(qiáng)。另外,其執(zhí)行效率和穩(wěn)定性在未來有待進(jìn)一步加強(qiáng)。
02
基于多模態(tài)對齊數(shù)據(jù)訓(xùn)練多模態(tài)大模型
這種方法是直接利用多模態(tài)的對齊數(shù)據(jù)來訓(xùn)練多模態(tài)大模型,《多模態(tài)大模型:技術(shù)原理與實(shí)戰(zhàn)》一書5.3節(jié)中介紹了諸多模型,例如VideoBERT、CLIP、CoCa、CoDi等都是基于這種思路實(shí)現(xiàn)的。
這種方法的核心理念是分別構(gòu)建多個(gè)單模態(tài)編碼器,得到各自的特征向量,然后基于類Transformer對各個(gè)模態(tài)的特征進(jìn)行交互和融合,實(shí)現(xiàn)在多模態(tài)的語義空間對齊。
由此訓(xùn)練得到的多模態(tài)大模型具備很強(qiáng)的泛化能力和小樣本、零樣本推理能力,這得益于大規(guī)模的多模態(tài)對齊的預(yù)訓(xùn)練語料。與此同時(shí),由于訓(xùn)練參數(shù)量較大,往往需要較多的訓(xùn)練資源和較長的訓(xùn)練時(shí)長。
03
以LLM為底座模型,訓(xùn)練跨模態(tài)編碼器
這種方法的特色是以預(yù)訓(xùn)練好的LLM為底座模型,凍結(jié)LLM的大部分參數(shù)來訓(xùn)練跨模態(tài)編碼器,既能夠有效地利用LLM強(qiáng)大的自然語言理解和推理能力,又能完成復(fù)雜的多模態(tài)任務(wù)。這種訓(xùn)練方法還有一個(gè)顯而易見的好處,在訓(xùn)練過程中對LLM的大部分參數(shù)進(jìn)行了凍結(jié),導(dǎo)致模型可訓(xùn)練的參數(shù)量遠(yuǎn)遠(yuǎn)小于真正的多模態(tài)大模型,因此其訓(xùn)練時(shí)長較短,對訓(xùn)練資源的要求也不高。下面以多模態(tài)大模型LLaVA為例介紹這種方法的主要構(gòu)建流程。
2023年4月,威斯康星大學(xué)麥迪遜分校等機(jī)構(gòu)聯(lián)合發(fā)布了多模態(tài)大模型LLaVA。LLaVA模型在視覺問答、圖像描述、物體識(shí)別、多輪對話等任務(wù)中表現(xiàn)得極其出色,一方面具有強(qiáng)大的自然語言理解和自然語言推理能力,能夠準(zhǔn)確地理解用戶輸入的指令和意圖,支持以多輪對話的方式與用戶進(jìn)行交流,另一方面能夠很好地理解輸入圖像的語義信息,準(zhǔn)確地完成圖像描述、視覺問答、物體識(shí)別等多模態(tài)任務(wù)。LLaVA模型的原理示意圖如圖2所示。
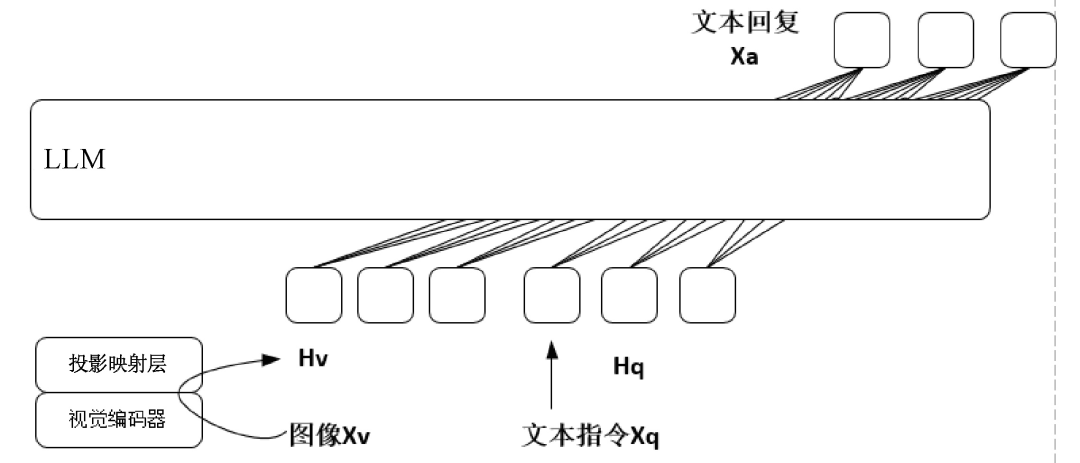
圖2
在訓(xùn)練數(shù)據(jù)上,LLaVA模型使用了高質(zhì)量的多模態(tài)指令數(shù)據(jù)集,并且這些數(shù)據(jù)都是通過GPT-4生成的。這個(gè)指令數(shù)據(jù)集包含基于圖像的對話數(shù)據(jù)、詳細(xì)描述數(shù)據(jù)和復(fù)雜推理數(shù)據(jù),共15萬條,數(shù)據(jù)的質(zhì)量和多樣性較高。LLaVA模型將多模態(tài)指令數(shù)據(jù)集應(yīng)用到了多模態(tài)任務(wù)上,這是指令微調(diào)擴(kuò)展到多模態(tài)領(lǐng)域的第一次嘗試。
在模型架構(gòu)上,LLaVA模型使用Vicuna模型作為文本編碼器,使用CLIP模型作為圖像編碼器。
第一個(gè)階段,基于59.5萬條CC3M文本-圖像對齊數(shù)據(jù),訓(xùn)練跨模態(tài)編碼器,以便將文本特征和圖像特征進(jìn)行語義對齊。這里的跨模態(tài)編碼器其實(shí)是一個(gè)簡單的投影映射層,在訓(xùn)練時(shí)凍結(jié)LLM的參數(shù),僅僅對投影映射層的參數(shù)進(jìn)行更新。
第二個(gè)階段,基于15萬條多模態(tài)指令數(shù)據(jù),對多模態(tài)大模型進(jìn)行端到端的指令微調(diào),具體針對視覺問答和多模態(tài)推理任務(wù)進(jìn)行模型訓(xùn)練。值得注意的是,LLaVA模型在訓(xùn)練的第二個(gè)階段會(huì)對LLM和投影映射層的參數(shù)都進(jìn)行相應(yīng)的更新,仍然存在一定的時(shí)間開銷和訓(xùn)練資源依賴,這也是后續(xù)研究工作的一個(gè)重要方向。
2023年5月2日,LLaVA官方發(fā)布了輕量級的LLaVA Lightning模型(可以翻譯為輕量級的LLaVA模型),使用8個(gè)RTX A100型號(hào)的顯卡,3小時(shí)即可完成訓(xùn)練,總訓(xùn)練成本僅為40美元。
審核編輯:劉清
-
編碼器
+關(guān)注
關(guān)注
45文章
3784瀏覽量
137446 -
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
15978 -
大模型
+關(guān)注
關(guān)注
2文章
3062瀏覽量
3909 -
LLM
+關(guān)注
關(guān)注
1文章
322瀏覽量
727
原文標(biāo)題:大模型+多模態(tài)的3種實(shí)現(xiàn)方法|文末贈(zèng)書
文章出處:【微信號(hào):AI前線,微信公眾號(hào):AI前線】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
商湯日日新SenseNova融合模態(tài)大模型 國內(nèi)首家獲得最高評級的大模型
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態(tài)大模型

海康威視發(fā)布多模態(tài)大模型AI融合巡檢超腦
移遠(yuǎn)通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗(yàn)

移遠(yuǎn)通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗(yàn)

海康威視發(fā)布多模態(tài)大模型文搜存儲(chǔ)系列產(chǎn)品

商湯日日新多模態(tài)大模型權(quán)威評測第一
一文理解多模態(tài)大語言模型——下

利用OpenVINO部署Qwen2多模態(tài)模型
云知聲山海多模態(tài)大模型UniGPT-mMed登頂MMMU測評榜首

Meta發(fā)布多模態(tài)LLAMA 3.2人工智能模型
PerfXCloud 重大更新 端側(cè)多模態(tài)模型 MiniCPM-Llama3-V 2.5 閃亮上架






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論