") YOLOv5使用教程詳解(單卡,多卡,多機訓練)
YOLOv5使用教程詳解(單卡,多卡,多機訓練)
前言
代碼倉庫地址:https://github.com/Oneflow-Inc/one-yolov5歡迎star one-yolov5項目 獲取 最新的動態(tài)。如果你有問題,歡迎在倉庫給我們提出寶貴的意見。 如果對你有幫助,歡迎來給我Star呀~
聲明:Model Train(以coco數(shù)據(jù)集為例) 。本文涉及到了大量的超鏈接,但是在微信文章里面外鏈接會被吃掉,所以歡迎大家到這里查看本篇文章的完整版本:https://start.oneflow.org/oneflow-yolo-doc/tutorials/03_chapter/quick_start.html
項目結構預覽
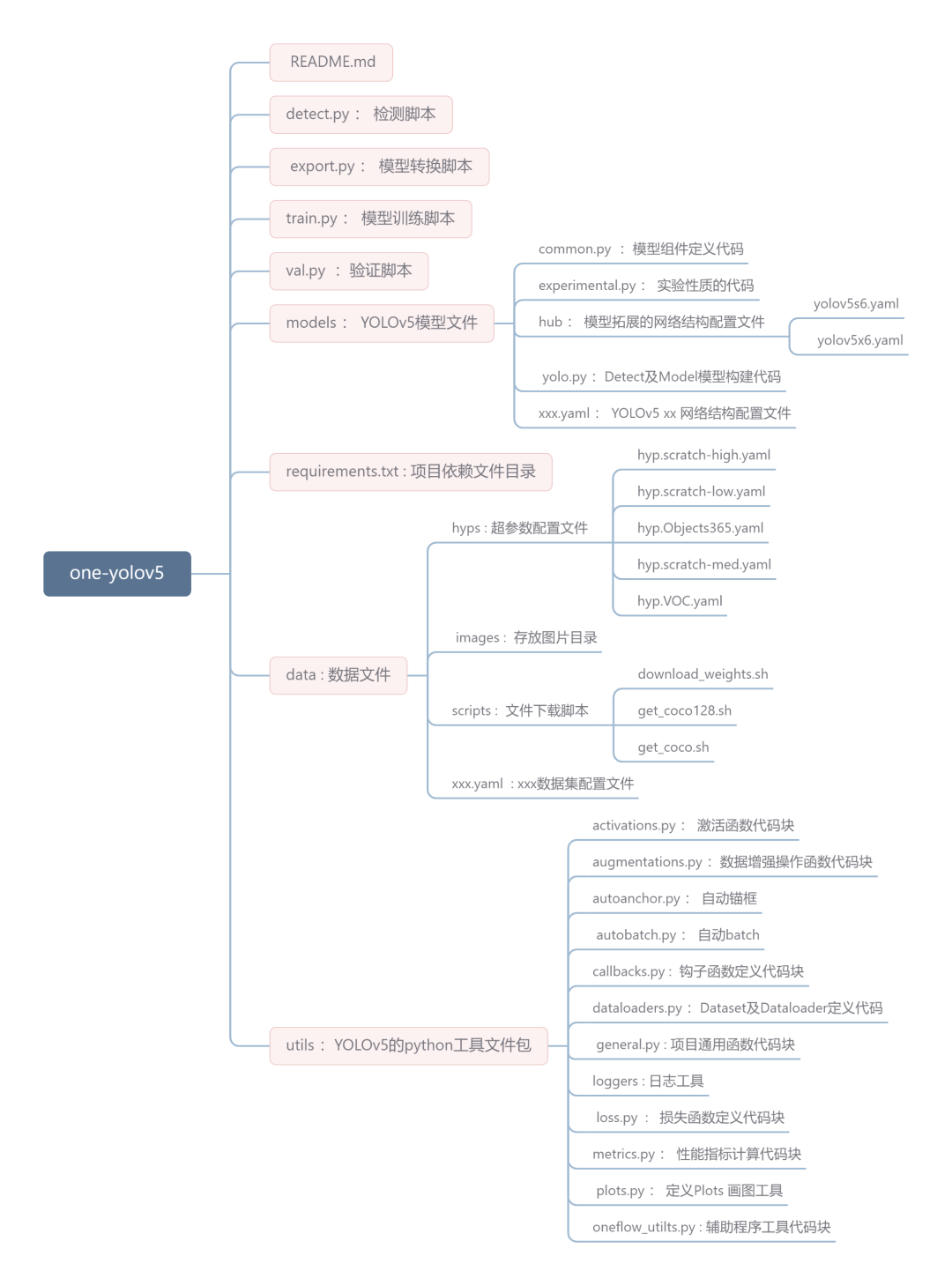 image
image安裝
gitclonehttps://github.com/Oneflow-Inc/one-yolov5#clone
cdone-yolov5
pipinstall-rrequirements.txt#install
訓練
兩種訓練方式
- 帶權重訓練
$pythonpath/to/train.py--datacoco.yaml--weightsyolov5s--img640
- 不帶權重訓練
$pythonpath/to/train.py--datacoco.yaml--weights''--cfgyolov5s.yaml--img640
單GPU訓練
$pythontrain.py--datacoco.yaml--weightsyolov5s--device0
多GPU訓練
$python-moneflow.distributed.launch--nproc_per_node2train.py--batch64--datacoco.yaml--weightsyolov5s--device0,1
注意:
-
--nproc_per_node 指定要使用多少GPU。舉個例子:在上面 多GPU訓練指令中它是2。
-
--batch 是總批量大小。它將平均分配給每個GPU。在上面的示例中,每GPU是64/2=32。
-
--cfg : 指定一個包含所有評估參數(shù)的配置文件。
-
上面的代碼默認使用GPU 0…(N-1)。使用特定的GPU?可以通過簡單在 --device 后跟指定GPU來實現(xiàn)。「案例」,在下面的代碼中,我們將使用GPU 2,3。
$python-moneflow.distributed.launch--nproc_per_node2train.py--batch64--datacoco.yaml--cfgyolov5s.yaml--weights''--device2,3
恢復訓練
如果你的訓練進程中斷了,你可以這樣恢復先前的訓練進程。
#多卡訓練.
python-moneflow.distributed.launch--nproc_per_node2train.py--resume
你也可以通過 --resume 參數(shù)指定要恢復的模型路徑
#記得把/path/to/your/checkpoint/path替換為你要恢復訓練的模型權重路徑
--resume/path/to/your/checkpoint/path
使用SyncBatchNorm
SyncBatchNorm可以提高多gpu訓練的準確性,但會顯著降低訓練速度。它僅適用于多GPU DistributedDataParallel 訓練。
建議最好在每個GPU上的樣本數(shù)量較小(樣本數(shù)量<=8)時使用。
要使用SyncBatchNorm,只需將添加 --sync-bn 參數(shù)選項,具體「案例」如下:
$python-moneflow.distributed.launch--nproc_per_node2train.py--batch64--datacoco.yaml--cfgyolov5s.yaml--weights''--sync-bn
評估
下面的命令是在COCO val2017數(shù)據(jù)集上以640像素的圖像大小測試 yolov5x 模型。yolov5x是可用小模型中最大且最精確的,其它可用選項是 yolov5n ,yolov5m,yolov5s,yolov5l ,以及他們的 P6 對應項比如 yolov5s6 ,或者你自定義的模型,即 runs/exp/weights/best 。有關可用模型的更多信息,請參閱我們的README-TABLE
$pythonval.py--weightsyolov5x--datacoco.yaml--img640
推理
首先,下載一個訓練好的模型權重文件,或選擇你自己訓練的模型;
然后,通過 detect.py文件進行推理。
pythonpath/to/detect.py--weightsyolov5s--source0#webcam
img.jpg#image
vid.mp4#video
path/#directory
path/*.jpg#glob
'https://youtu.be/Zgi9g1ksQHc'#YouTube
'rtsp://example.com/media.mp4'#RTSP,RTMP,HTTPstream
訓練結果
本地日志
默認情況下,所有結果都記錄為runs/train,并為每個新訓練創(chuàng)建一個新的訓練結果目錄,如runs/train/exp2、runs/train/exp3等。查看訓練和測試JPG以查看 mosaics, labels, predictions and augmentation 效果。注意:Mosaic Dataloader 用于訓練(如下所示),這是Ultralytics發(fā)表的新概念,首次出現(xiàn)在YOLOv4中。
train_batch0.jpg 顯示 batch 為 0 的 (mosaics and labels):
 img
imgval_batch0_labels.jpg 展示測試 batch 為 0 的labels:
 img
img
val_batch0_pred.jpg 展示測試 batch 為 0 predictions(預測):
訓練訓損失和性能的指標有記錄到Tensorboard和自定義結果中results.csv日志文件,訓練訓完成后作為結果繪制 results.png如下。在這里,我們展示了在COCO128上訓練的YOLOV5結果
- 從零開始訓練 (藍色)。
- 加載預訓練權重 --weights yolov5s (橙色)。
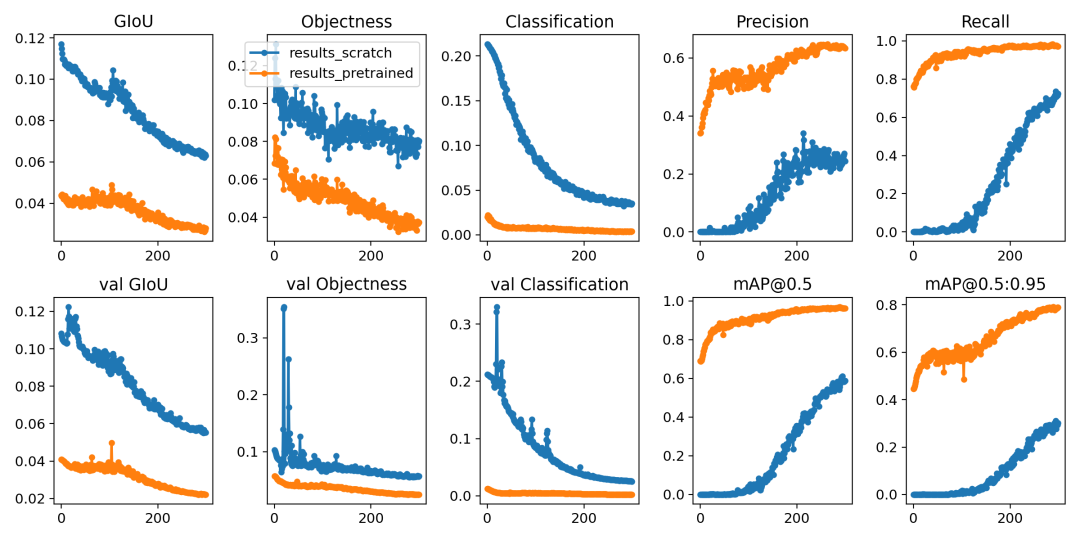 img
img具體的指標分析詳見文章《模型精確度評估》
訓練技巧
聲明:大多數(shù)情況下,只要數(shù)據(jù)集足夠大且標記良好,就可以在不改變模型或訓練設置的情況下獲得良好的結果。如果一開始你沒有得到好的結果,你可以采取一些步驟來改進,但我們始終建議用戶在考慮任何更改之前先使用所有默認設置進行一次訓練。這有助于建立評估基準和發(fā)現(xiàn)需要改進的地方 。
模型選擇
類似于YOLOv5x和YOLOv5x6的大型模型在幾乎所有情況下都會產生更好的結果,但參數(shù)更多,需要更多的CUDA內存進行訓練,運行速度較慢。
對于移動部署,我們推薦YOLOv5s/m,對于云部署,我們建議YOLOV5l/x。
有關所有模型的完整比較,請參閱詳細表
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-FotYkHQk-1668949640644)( https://user-images.githubusercontent.com/35585791/201064824-f97c82d5-6bba-4421-86d9-194e47842e35.png)]
- 從預先訓練的權重開始訓練。建議用于中小型數(shù)據(jù)集(即VOC、VisDrone、GlobalWheat)。將模型的名稱傳遞給--weights參數(shù)。模型自動從latest YOLOv5 releasse 下載 。
pythontrain.py--datacustom.yaml--weightsyolov5s
yolov5m
yolov5l
yolov5x
custom_pretrained#自定義的網絡結構文件
-
從頭開始訓練的話,推薦用大的數(shù)據(jù)集(即 COCO、Objects365、OIv6 )在
--cfg選項后傳遞你感興趣的網絡結構文件參數(shù) 以及空的--weights ''參數(shù):
pythontrain.py--datacustom.yaml--weights''--cfgyolov5s.yaml
yolov5m.yaml
yolov5l.yaml
yolov5x.yaml
訓練配置
在修改任何內容之前,首先使用默認設置進行訓練,以建立性能基線。訓練參數(shù)的完整列表,能夠在train.py文件中發(fā)現(xiàn)。
-
Epochs : 默認訓練300個epochs。如果早期過擬合,則可以減少訓練。如果在300個周期后未發(fā)生過擬合,則可以訓練更長,比如600、1200個epochs。
-
Image size: COCO以 --img 640,的分辨率進行訓練,但由于數(shù)據(jù)集中有大量的小對象,它可以從更高分辨率(如--img 1280)的訓練中訓練。如果有許多小對象,則自定義數(shù)據(jù)集將從更高分辨率的訓練中獲益。最好的推斷結果是在相同的--img 處獲得的 ,即如果在-img 1280處進行訓練,也應該在--img 1280處進行測試和檢測。
-
Batch Size: 使用更大的 --batch-size 。能夠有效緩解小樣本數(shù)產生的batchnorm統(tǒng)計的錯誤。
-
Hyperparameters:默認超參數(shù)在hyp.scratch-low.yaml文件中。我們建議你在考慮修改任何超參數(shù)之前,先使用默認超參數(shù)進行訓練。一般來說,增加增強超參數(shù)將減少和延遲過度擬合,允許更長的訓練和得到更高mAP值。減少損耗分量增益超參數(shù),如hyp['obj'],將有助于減少這些特定損耗分量中的過度擬合。有關優(yōu)化這些超參數(shù)的自動化方法,請參閱我們的 《超參數(shù)演化教程》。
-
...更多訓練的超參數(shù)配置請查看本文的附錄。
拓展
使用多機訓練
這僅適用于多GPU分布式數(shù)據(jù)并行訓練。
在訓練之前,確保所有機器上的文件都相同,數(shù)據(jù)集、代碼庫等。之后,確保機器可以相互通信。
你必須選擇一臺主機器(其他機器將與之對話)。記下它的地址(master_addr)并選擇一個端口(master-port)。對于下面的示例,將使用master_addr=192.168.1.1和master_ port=1234。
要使用它,可以執(zhí)行以下指令:
#Onmastermachine0
$python-moneflow.distributed.launch--nproc_per_nodeG--nnodesN--node_rank0--master_addr"192.168.1.1"--master_port1234train.py--batch64--datacoco.yaml--cfgyolov5s.yaml--weights''
#OnmachineR
$python-moneflow.distributed.launch--nproc_per_nodeG--nnodesN--node_rankR--master_addr"192.168.1.1"--master_port1234train.py--batch64--datacoco.yaml--cfgyolov5s.yaml--weights''
其中G是每臺機器的GPU數(shù)量,N是機器數(shù)量,R是從0到(N-1)的機器數(shù)量。
假設我有兩臺機器,每臺機器有兩個GPU,對于上面的情況,G=2,N=2,R=1。
在連接所有N臺機器之前,訓練不會開始。輸出將僅顯示在主機上!
注意
- oneflow目前不支持windows平臺
- --batch 必須是GPU數(shù)量的倍數(shù)。
- GPU 0 將比其他GPU占用略多的內存,因為它維護EMA并負責檢查點等。
- 如果你得到 RuntimeError: Address already in use ,可能是因為你一次正在運行多個訓練程序。要解決這個問題,只需通過添加--master_port來使用不同的端口號,如下所示
$python-moneflow.distributed.launch--master_port1234--nproc_per_node2...
配置代碼
#prepare
t=https://github.com/Oneflow-Inc/one-yolov5:latest&&sudodockerpull$t&&sudodockerrun-it--ipc=host--gpusall-v"$(pwd)"/coco:/usr/src/coco$t
pipinstall--preoneflow-fhttps://staging.oneflow.info/branch/master/cu112
cd..&&rm-rfapp&&gitclonehttps://github.com/Oneflow-Inc/one-yolov5-bmasterapp&&cdapp
cpdata/coco.yamldata/coco_profile.yaml
#profile
pythontrain.py--batch-size16--datacoco_profile.yaml--weightsyolov5l--epochs1--device0
python-moneflow.distributed.launch--nproc_per_node2train.py--batch-size32--datacoco_profile.yaml--weightsyolov5l--epochs1--device0,1
python-moneflow.distributed.launch--nproc_per_node4train.py--batch-size64--datacoco_profile.yaml--weightsyolov5l--epochs1--device0,1,2,3
python-moneflow.distributed.launch--nproc_per_node8train.py--batch-size128--datacoco_profile.yaml--weightsyolov5l--epochs1--device0,1,2,3,4,5,6,7
附件
表3.1
表3.1 : train.py參數(shù)解析表
| 參數(shù) | help | 幫助 |
|---|---|---|
| --weight | initial weights path | 加載的權重文件路徑 |
| --cfg | model.yaml path | 模型配置文件,網絡結構 路徑 |
| --data | dataset.yaml path | 數(shù)據(jù)集配置文件,數(shù)據(jù)集路徑 |
| --hyp | hyperparameters path | 超參數(shù)文件 路徑 |
| --epochs | Total training rounds | 訓練總輪次 |
| --batch-size | total batch size for all GPUs, -1 for autobatch | 一次訓練所選取的樣本數(shù) |
| --imgsz | train, val image size (pixels) | 輸入圖片分辨率大小 |
| --rect | rectangular training | 是否采用矩形訓練,默認False |
| --resume | resume most recent training | 接著打斷訓練上次的結果接著訓練 |
| --nosave | only save final checkpoint | 只保存最終的模型,默認False |
| --noautoanchor | disable AutoAnchor | 不自動調整anchor,默認False |
| --noplots | save no plot files | 不保存打印文件,默認False |
| --evolve | evolve hyperparameters for x generations | 是否進行超參數(shù)進化,默認False |
| --bucket | gsutil bucket | 谷歌云盤bucket,一般不會用到 |
| --cache | --cache images in "ram" (default) or "disk" | 是否提前緩存圖片到內存,以加快訓練速度,默認False |
| --device | cuda device, i.e. 0 or 0,1,2,3 or cpu | 訓練的設備,cpu;0(表示一個gpu設備cuda:0);0,1,2,3(多個gpu設備) |
| --multi-scale | vary img-size +/- 50%% | 是否進行多尺度訓練,默認False |
| --single-cls | train multi-class data as single-class | 數(shù)據(jù)集是否只有一個類別,默認False |
| --optimizer | optimizer | 優(yōu)化器 |
| --sync-bn | use SyncBatchNorm, only available in DDP mode | 是否使用跨卡同步BN,在DDP模式使用 |
| --workers | max dataloader workers (per RANK in DDP mode) | dataloader的最大worker數(shù)量 |
| --project | save to project path | 保存到項目結果地址 |
| --name | save to project/name/ | 保存到項目結果/名稱 |
| --exist-ok | existing project/name ok, do not increment | 現(xiàn)有項目/名稱確定,不遞增,默認False |
| --quad | quad dataloader | 四元數(shù)據(jù)加載器 開啟之后在尺寸大于640的圖像上識別效果更好,但是有可能會使在640尺寸的圖片上效果更差 |
| --cos-lr | cosine LR scheduler | 是否采用退火余弦學習率,默認False |
| --label-smoothing | Label smoothing epsilon | 標簽平滑 |
| --patience | EarlyStopping patience (epochs without improvement) | 早停機制,默認False |
| --freez | Freeze layers: backbone=10, first3=0 1 2 | 凍結層數(shù),默認不凍結 |
| --save-period | Save checkpoint every x epochs (disabled if < 1) | 用于記錄訓練日志信息,int 型,默認 -1 |
| --seed | Global training seed | 隨機數(shù)種子設置 |
| --local_rank | Automatic DDP Multi-GPU argument, do not modify | 自動單機多卡訓練 一般不改動 |
Reference
- https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
- https://docs.ultralytics.com/quick-start/
審核編輯 :李倩
-
gpu
+關注
關注
28文章
4916瀏覽量
130744 -
數(shù)據(jù)集
+關注
關注
4文章
1223瀏覽量
25305
原文標題:《YOLOv5全面解析教程》六,YOLOv5使用教程詳解(單卡,多卡,多機訓練)
文章出處:【微信號:GiantPandaCV,微信公眾號:GiantPandaCV】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
在K230上部署yolov5時 出現(xiàn)the array is too big的原因?
RV1126 yolov8訓練部署教程
請問如何在imx8mplus上部署和運行YOLOv5訓練的模型?
YOLOv5類中rgb888p_size這個參數(shù)要與模型推理和訓練的尺寸一致嗎?一致會達到更好的效果?
yolov5轉onnx在cubeAI進行部署,部署失敗的原因?
【米爾RK3576開發(fā)板評測】+項目名稱YOLOV5目標檢測
【ELF 2學習板試用】ELF2開發(fā)板(飛凌嵌入式)部署yolov5s的自定義模型
在RK3568教學實驗箱上實現(xiàn)基于YOLOV5的算法物體識別案例詳解
在樹莓派上部署YOLOv5進行動物目標檢測的完整流程
RK3588 技術分享 | 在Android系統(tǒng)中使用NPU實現(xiàn)Yolov5分類檢測
RK3588 技術分享 | 在Android系統(tǒng)中使用NPU實現(xiàn)Yolov5分類檢測-迅為電子






 工商網監(jiān)
工商網監(jiān)
評論