 AI/ML應用和處理器的架構探索
AI/ML應用和處理器的架構探索
人工智能應用的架構探索很復雜,涉及多項研究。首先,我們可以針對單個問題,例如內存訪問,也可以查看整個處理器或系統。
行業背景
人工智能 (AI) 應用考慮了計算、存儲、內存、管道、通信接口、軟件和控制。此外,人工智能應用程序處理可以分布在處理器內的多核、PCIe 主干上的多個處理器板、分布在以太網中的計算機、高性能計算機或數據中心的系統。此外,AI處理器還具有巨大的內存大小要求,訪問時間限制,跨模擬和數字的分布以及硬件 - 軟件分區。
問題
人工智能應用的架構探索很復雜,涉及多項研究。首先,我們可以針對單個問題,例如內存訪問,也可以查看整個處理器或系統。大多數設計都是從內存訪問開始的。有很多選擇 - SRAM 與 DRAM、本地與分布式存儲、內存計算以及緩存反向傳播系數與丟棄。
第二個評估扇區是總線或網絡拓撲。虛擬原型可以具有用于處理器內部的片上網絡、TileLink 或 AMBA AXI 總線、用于連接多處理器板和機箱的 PCIe 或以太網,以及用于訪問數據中心的 Wifi/5G/Internet 路由器。
使用虛擬原型的第三個研究是計算。這可以建模為處理器內核、多處理器、加速器、FPGA、多重累加和模擬處理。最后部分是傳感器、網絡、數學運算、DMA、自定義邏輯、仲裁器、調度程序和控制函數的接口。
此外,人工智能處理器和系統的架構探索具有挑戰性,因為它在硬件的全部功能上應用了數據密集型任務圖。
模型構建
在Mirabilis,我們使用VisualSim進行AI應用程序的架構探索。VisualSim 的用戶在圖形離散事件仿真平臺中非常快速地組裝虛擬原型,該平臺具有大型 AI 硬件和軟件建模組件庫。該原型可用于進行時序、吞吐量、功耗和服務質量權衡。提供超過20個AI處理器和嵌入式系統模板,以加速新AI應用程序的開發。
為 AI 系統中的權衡生成的報告包括響應時間、吞吐量、緩沖區占用、平均功耗、能耗和資源效率。
ADAS模型構建
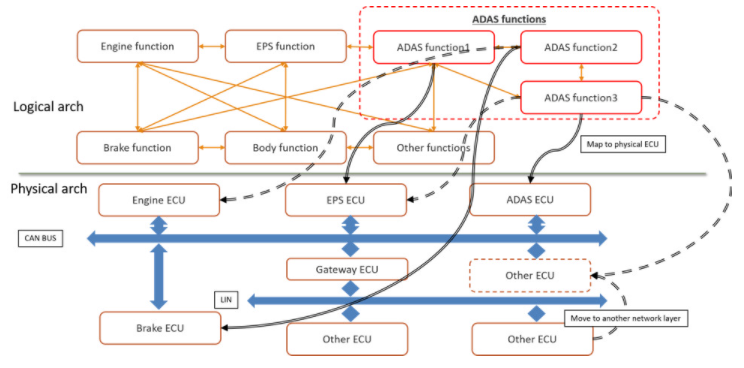
首先,讓我們考慮自動駕駛(ADAS)應用程序,這是圖1中的一種AI部署形式。ADAS應用程序與計算機或電子控制單元(ECU)和網絡上的許多應用程序共存。ADAS任務還依賴于現有系統的傳感器和執行器才能正常運行。
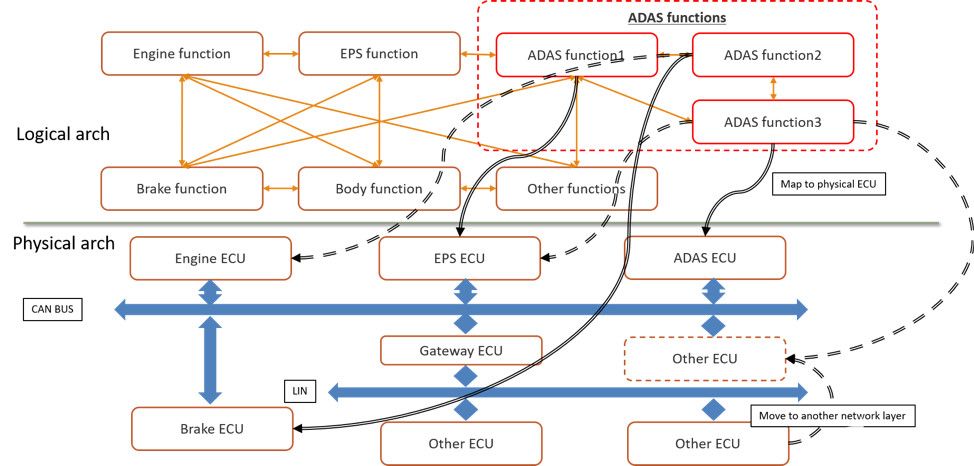
圖1.汽車設計中 AI 應用的邏輯到物理架構
早期架構權衡可以測試和評估假設,以快速識別瓶頸,并優化規范以滿足時序、吞吐量、功耗和功能要求。在圖 1 中,您將看到架構模型需要硬件、網絡、應用任務、傳感器、衰減器和流量激勵來了解整個系統的運行情況。圖 2 顯示了映射到物理架構的此 ADAS 邏輯架構的實現。
架構模型的一個很好的功能是能夠分離設計的所有部分,以便可以研究單個操作的性能。在圖 2 中,您會注意到單獨列出了現有任務、帶有 ECU 的網絡、傳感器生成和 ADAS 邏輯任務組織。ADAS任務圖中的每個功能都映射到ECU。
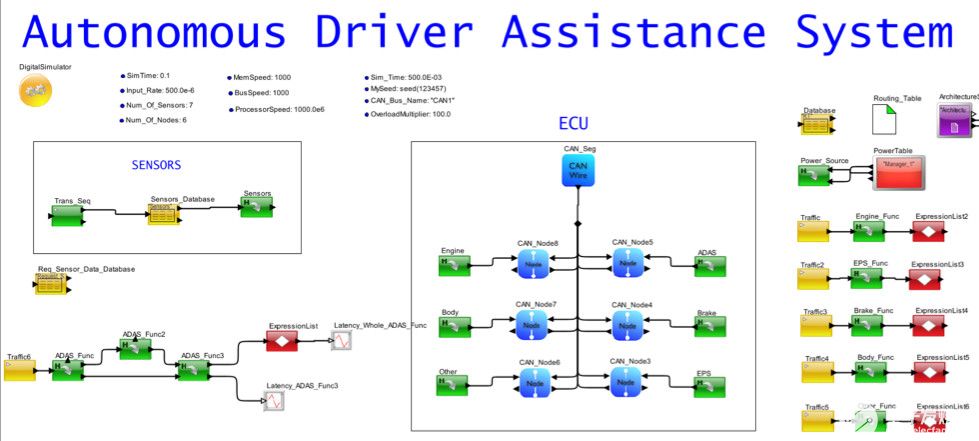
圖2.將ADAS映射到ECU網絡的汽車系統的系統模型
自動輔助系統分析
仿真圖2中的ADAS模型時,您可以獲得各種報告。圖3顯示了完成ADAS任務的延遲以及電池為此任務散發的相關熱量。其他感興趣的圖可以是測量的功率、網絡吞吐量、電池消耗、CPU 利用率和緩沖區占用。
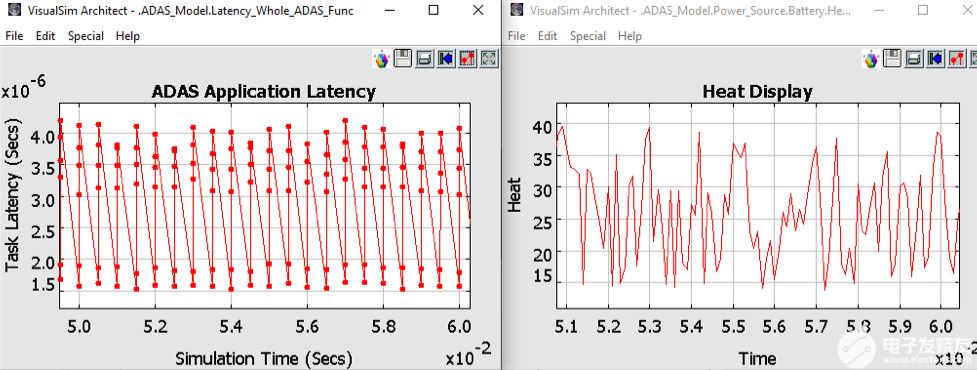
圖3.來自 ADAS 架構模型的分析報告
處理器模型構建
AI 處理器和系統的設計人員對應用程序類型、訓練與推理、成本點、功耗和大小限制進行實驗。例如,設計人員可以將子網絡分配給流水線階段,權衡深度神經網絡 (DNN) 與傳統機器學習算法,測量 GPU、TPU、AI 處理器、FPGA 和傳統處理器上的算法性能,評估在芯片上融合計算和內存的優勢,計算類似于人腦功能的模擬技術的功耗影響,以及構建具有針對單個應用的部分功能集的 SoC。
從PowerPoint到新AI處理器的第一個原型的時間表非常短,第一個生產樣品不能有任何瓶頸或錯誤。因此,建模成為強制性的。
圖 4 顯示了 Google 張量處理器的內部視圖。框圖已轉換為圖 5 中的架構模型。處理器通過 PCIe 接口接收來自主機的請求。MM、TG2、TG3 和 TG4 是來自獨立主機的不同請求流。權重存儲在片外 DDR3 中,并調用到權重 FIFO 中。到達的請求在統一本地緩沖區中存儲和更新,并發送到矩陣動車單元進行處理。通過 AI 管道處理請求后,它將返回到統一緩沖區以響應主機。
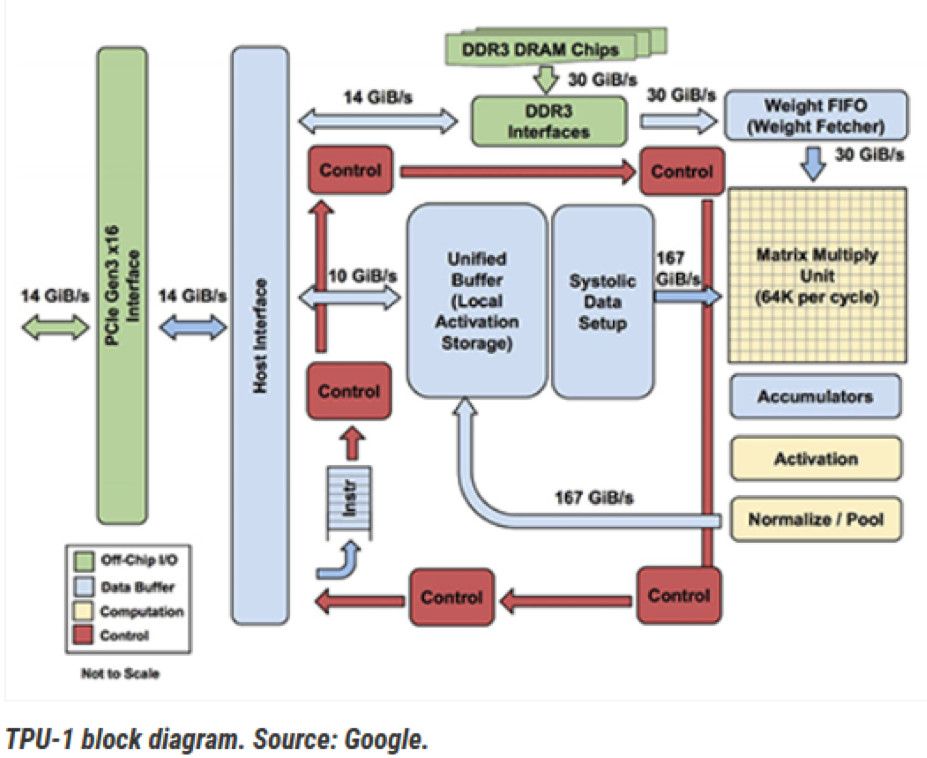
圖4.來自谷歌的 TPU-1
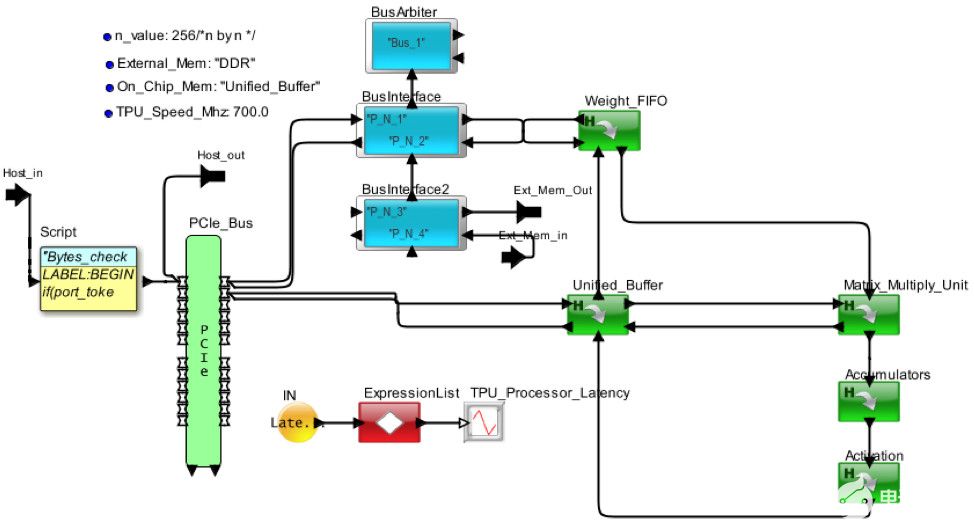
圖5.AI 硬件架構的 VisualSim 模型的俯視圖
處理器模型分析
在圖 6 中,您可以查看片外 DDR3 中的延遲和反向傳播權重管理。延遲是從主機發送請求到接收響應的時間。您將看到TG3和TG4能夠分別在200 us和350 us之前保持低延遲。MM和TG2在仿真早期開始緩沖。由于存在相當大的緩沖,并且這組流量配置文件的延遲正在增加,因此當前的 TPU 配置不足以處理負載和處理。TG3和TG4的優先級較高,有助于維持更長的運營時間。
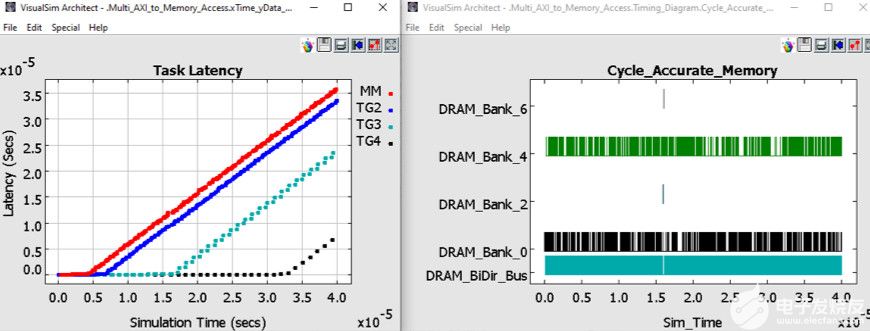
圖6.架構探索權衡的統計信息
汽車設計施工
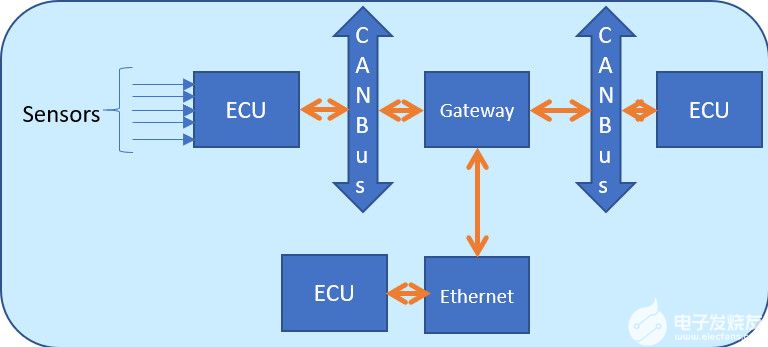
圖7.帶有CAN總線、傳感器和ECU的汽車網絡
當今的汽車設計融合了許多安全和自動駕駛功能,需要大量的機器學習和推理。可用的時間表將決定處理是在ECU完成還是發送到數據中心。例如,可以在本地完成制動決策,同時可以發送更改空調溫度進行遠程處理。兩者都需要基于輸入傳感器和攝像頭的一定數量的人工智能。
圖 7 是包含 ECU、CAN-FD、以太網和網關的網絡框圖。
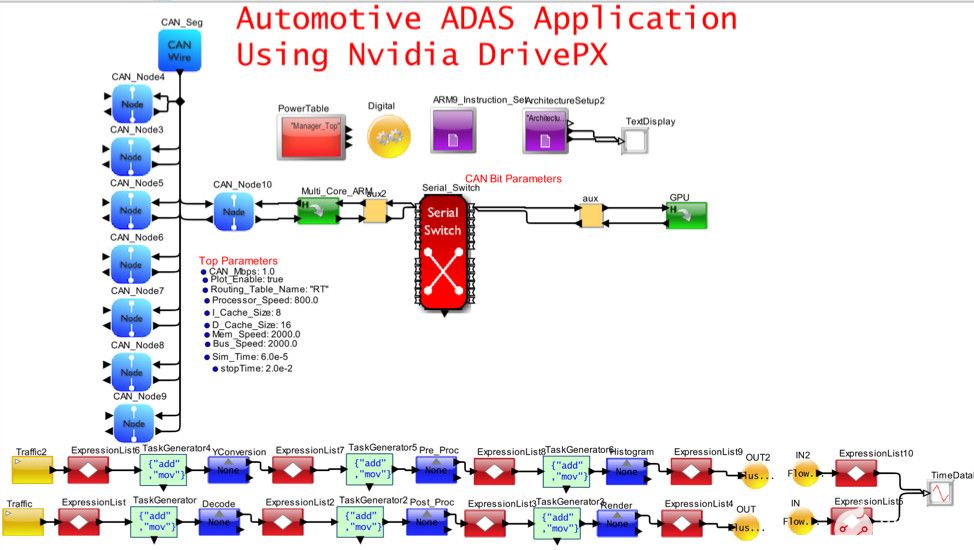
圖8.自動駕駛和E/E架構的可視化模擬模型
圖 8 捕獲了圖 7 的一部分,該部分將 CAN-FD 網絡與包含多個 ARM 內核和一個 GPU 的高性能 Nvidia DrivePX 集成在一起。以太網/TSN/AVB 和網關已從模型中刪除,以簡化視圖。在此模型中,重點是了解 SoC 的內部行為。該應用程序是由車輛上的攝像頭傳感器觸發的 MPEG 視頻捕獲、處理和渲染。
汽車設計分析
圖 9 顯示了 AMBA 總線和 DDR3 內存的統計信息。您可以查看工作負載在多個主節點之間的分布情況。可以評估應用程序管道的瓶頸,確定最高周期時間任務、內存使用情況配置文件以及每個任務的延遲。
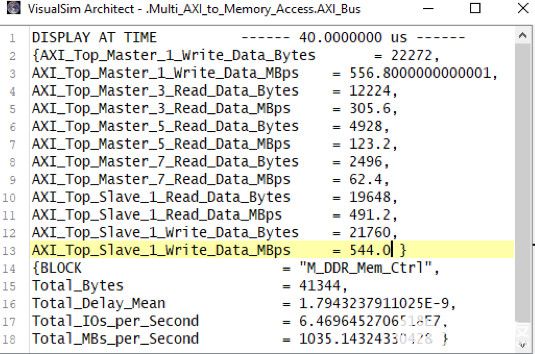
圖9.總線和內存活動報告
用例和流量模式應用于組裝為硬件、RTOS 和網絡組合的架構模型。定期交通狀況用于對雷達、激光雷達和攝像頭進行建模,而用例可以是自動駕駛、聊天機器人、搜索、學習、推理、大數據操作、圖像識別和疾病檢測。用例和流量可以根據輸入速率、數據大小、處理時間、優先級、依賴性、先決條件、反向傳播循環、系數、任務圖和內存訪問而變化。通過改變屬性在系統模型上模擬用例。這會導致生成各種統計信息和繪圖,包括緩存命中率、管道利用率、拒絕的請求數、每條指令或任務的瓦數、吞吐量、緩沖區占用和狀態圖。
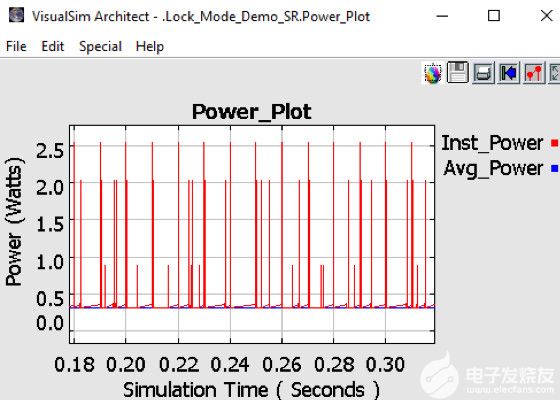
圖 10.實時測量 AI 處理器的功耗
圖10顯示了系統和芯片的功耗。除了散熱、電池充電消耗率和電池生命周期變化外,該模型還可以捕獲動態功率變化。該模型繪制了每個器件的狀態活動、相關的瞬時尖峰和系統的平均功耗。獲得有關功耗的早期反饋有助于熱和機械團隊設計外殼和冷卻方法。大多數機箱對每個板都有最大功率限制。這種早期的功耗信息可用于執行架構與性能的權衡,從而尋找降低功耗的方法。
進一步的勘探方案
以下是一些其他示例,重點介紹了如何使用 AI 體系結構模型和分析。
1. 自動駕駛系統,配備360度激光掃描儀、立體攝像頭、魚眼攝像頭、毫米波雷達、聲納或激光雷達,通過網關連接的多個IEEE802.1Q網絡上的20個ECU連接。原型用于測試 OEM 硬件配置的功能包,以確定硬件和網絡要求。主動安全措施的響應時間是主要標準。
2. 用于學習和推理任務的人工智能處理器使用片上網絡主干網定義,該骨干網由 32 個內核、32 個加速器、4 個 HBM2.0、8 個 DDR5、多個 DMA 和全緩存一致性組成。該模型試驗了 RISC-V、ARM Z1 和專有內核的變體。實現的目標是在鏈路上實現 40Gbps,同時保持低路由器頻率并重新訓練網絡路由。
3. 需要 32 層深度神經網絡才能將內存從 40GB 增加到 7GB 以下。數據吞吐量和響應時間未更改。該模型是使用行為的功能流程圖設置的,其中包含處理和反向傳播的內存訪問。對于不同的數據大小和任務圖,該模型確定了數據的丟棄量以及各種片外DRAM大小和SSD存儲選項。任務圖通過任意數量的圖和多個輸入和輸出而變化。
4. 通用SoC,使用ARM處理器和AXI總線進行低成本AI處理。目標是獲得最低的每瓦功率,從而最大化內存帶寬。乘法累加函數被卸載到矢量指令,加密到IP核,自定義算法卸載到加速器。構建該模型的明確目的是評估不同的緩存內存層次結構,以提高命中率和總線拓撲以減少延遲。
5. 模數AI處理器需要對功耗進行徹底分析,并對所達到的吞吐量進行準確分析。在該模型中,非線性控制在離散事件模擬器中建模為一系列線性函數,以加快仿真時間。在本例中,對功能進行了測試,以檢查行為并衡量真正的節能效果。
審核編輯:郭婷
-
處理器
+關注
關注
68文章
19833瀏覽量
233925 -
FPGA
+關注
關注
1644文章
21993瀏覽量
615358 -
人工智能
+關注
關注
1805文章
48843瀏覽量
247405
發布評論請先 登錄
ARM發布兩款針對移動終端的AI芯片架構:物體檢測和機器學習處理器

Alif Semiconductor宣布推出先進的BLE和Matter無線微控制器,搭載適用于AI/ML工作負載的神經網絡協同處理器

端側 AI 音頻處理器:集成音頻處理與 AI 計算能力的創新芯片
淺談ARM處理器架構
學AI的鯉躍龍門之路:AI的探索技藝
ARM公版架構 真的是麒麟處理器的槽點嗎?


AI/ML應用和處理器的架構探索
處理器架構與指令集
簡單認識MIPS架構處理器
聯發科或將與英偉達開發Arm架構AI PC處理器
在線研討會 @4/10 ASTRA?賦能邊緣 AI:探索 Synaptics SL &amp; SR 處理器的無限可能






 工商網監
工商網監
評論