 99%開發者從未聽說過的堆棧模型
99%開發者從未聽說過的堆棧模型
朋友: 你知道如何設置棧最安全么?你知道如何不寫一行匯編代碼就能設置棧的大小么?你知道如何在鏈接腳本中使用宏和頭文件么?你知道如何在代碼中隨時隨地檢查棧的最大使用情況么? 本文從理論到實踐,從知其然到知其所以然,一杯奶茶的功夫就給你講得明明白白。
在中文嵌入式環境中,時不時的總能看到不少朋友”堆”“棧“傻傻分不清楚,我很早之前在文章《漫談C變量——夏蟲不可語冰》介紹過二者的區別,這里就不再深入展開,總之:
棧(Stack)“是我們用來分配局部變量、實現函數調用和在異常響應時保存被打斷代碼上下文的地方——具體細節不重要,在本文的討論中,我們只需要記住以下信息:
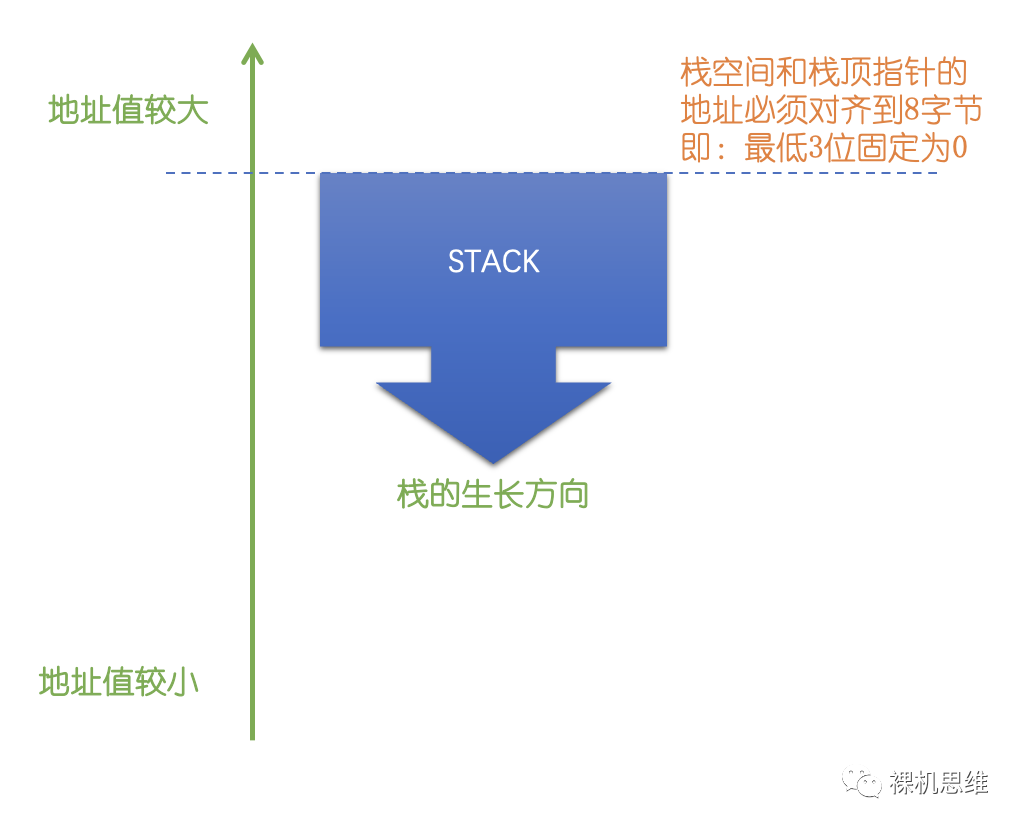
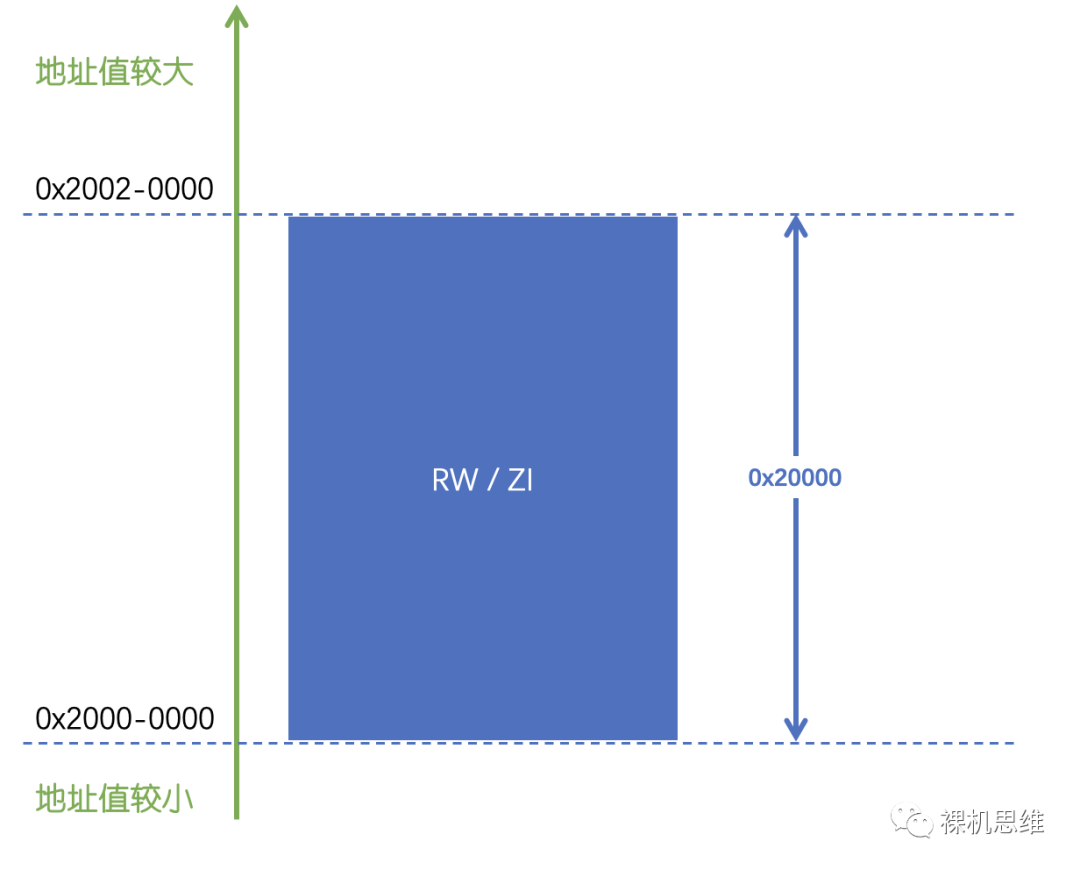
- Cortex-M系統棧的生長方向是自上而下的,也就是隨著更多內容被壓入(PUSH)棧中,棧頂指針的地址值是越來越小的——也就是從地址值較大的位置向地址值較小的位置移動。
- Cortex-M的棧頂指針指向的是“棧頂部的空位”。
- 從最大兼容性角度考慮,Cortex-M架構下棧存儲空間必須對齊到8字節。
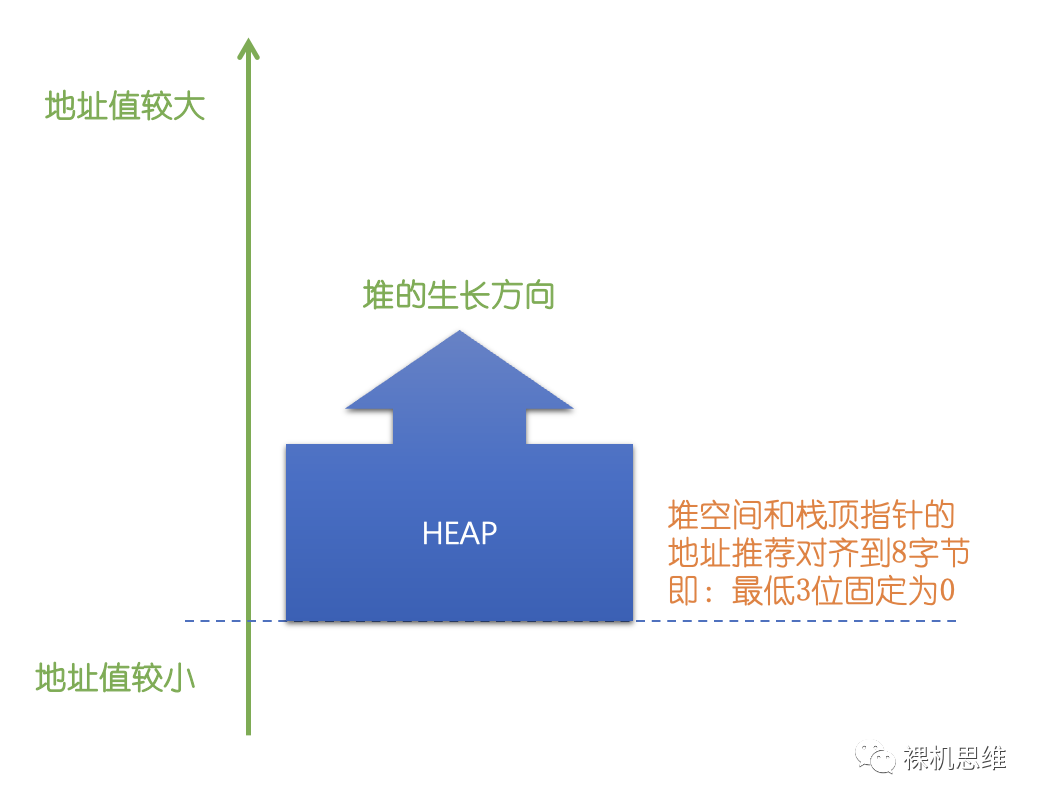
- 堆本身只是一個內存管理的算法,它所要管理的RAM空間需要用戶通過某種手段將指定大小的RAM空間交到Heap算法手里。
- 與棧不同,堆的生長方向其實完全由具體的管理算法決定,而堆的算法數量雖然不能說是燦若星辰,至少一雙手肯定數不過來——但一般來說我們可以大體認為堆的生長方向是“自下而上的”——也就是從地址值較小的位置延伸到地址值較大的位置。
- 堆的對齊要求一般是4字節起步,8字節更好,情況不明的直接就32個字節吧。
【常見的堆棧模型】
從單純從我不負責任的經驗來看,由很多GCC領銜使用的“對向生長”模型可能是嵌入式領域最常見的”大聰明模型“,沒有之一。如下圖所示:
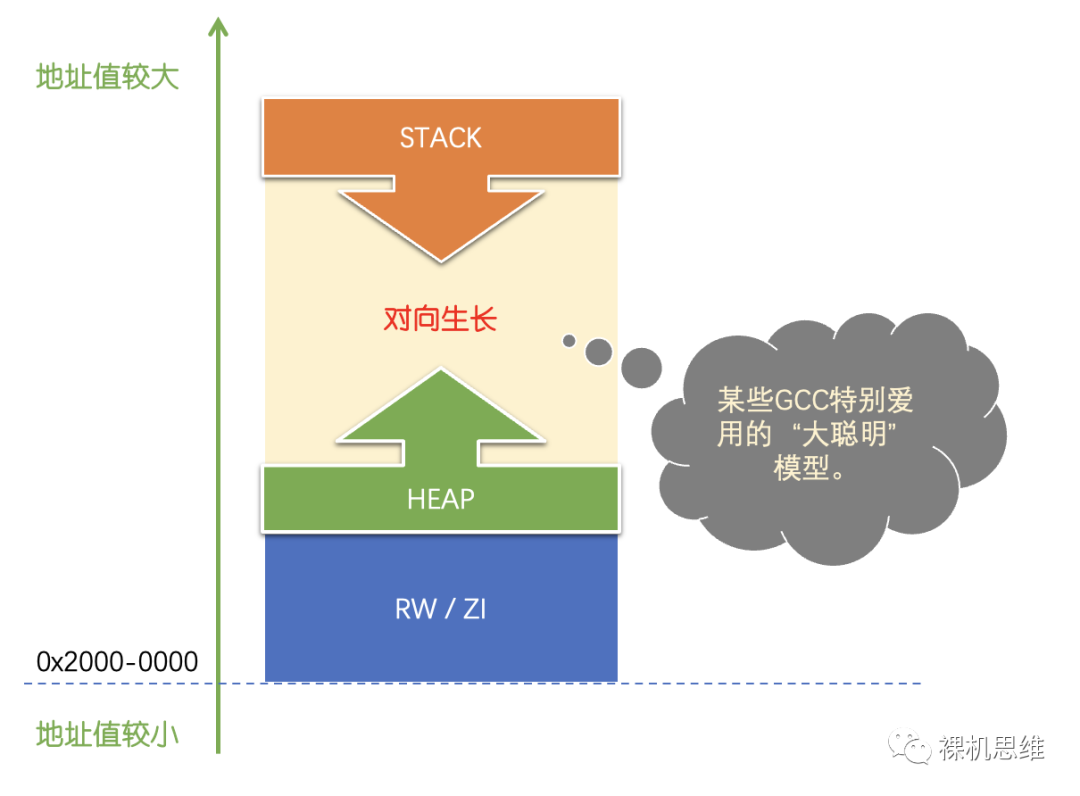
- 該模型棧和堆共用同一塊連續的地址區間
- 配置時不需要操心具體棧有多大、堆有多大
- 配置方法簡單:只需要指定這一整塊”堆棧“區域的起始地址,以及這一整塊堆棧區域的大小
- 堆和棧的最大可用大小是此消彼長的,理論上可以在某種最優的情況下達到動態的”此消彼長“,可以獲得理想狀下最大的空間復用效率。
- 堆和棧的最大可用大小是此消彼長的,在真實場景中,由于”你長我也長誰怕誰”的情況居多,發生隨機性的“雙向奔赴”從而進行“負距離”的互動可能性從理論上就不可避免,因而是系統穩定性的“一生之敵”。
- 實驗室里7x24小時完美通過,一去客戶那里就隨機性宕機的“挖坑之王”。
為了提高系統穩定性,人們簡單地將“堆”和“棧”拆開來單獨配置,就獲得了常見的“兩段式堆棧模型”:
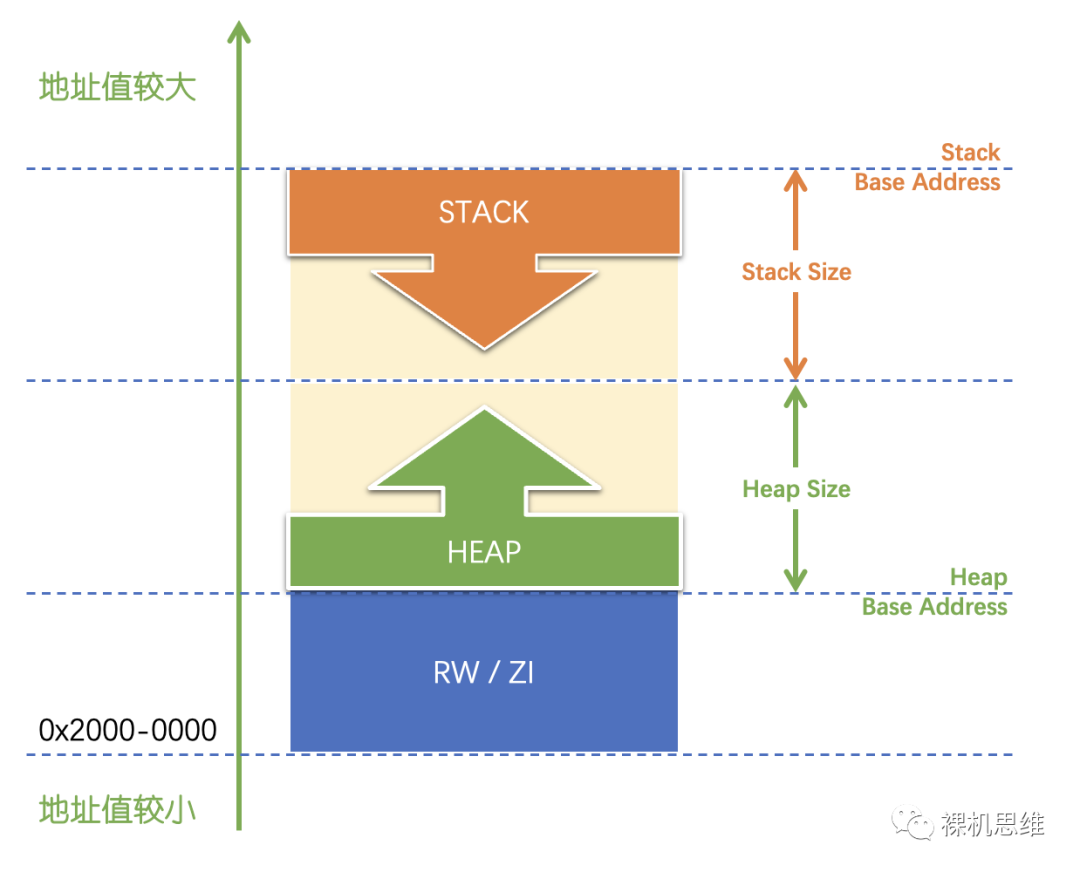
【最安全的“兩面包夾芝士”模型】
將“棧(Stack)”和"堆(Heap)"獨立配置的“兩段式”模型配合邊界金絲雀,為預防和檢測堆棧溢出提供了可能。但對金絲雀的檢測總歸有種“事后諸葛亮”的感覺,而且很多時候,我們是想不起來去檢查金絲雀的,比如:棧曾經一度跨越雷池入侵到了堆空間,但由于此時堆恰巧分配出去的RAM不多,沒有與棧發生實質性的重疊,因而整個系統“安然無恙”——這只能說是運氣好,而風險肯定是存在的——正由于系統“安然無恙”,因此我們在系統開發階段可能不會想起來去檢查一下金絲雀(有自動檢查機制的RTOS除外),那么這類溢出就有可能被隱藏。
基于上述原因,有沒有一種方法可以:
- 徹底避免棧/堆入侵對系統的破壞
- 在棧/堆入侵的瞬間就立即表現出來——方便我們在調試階段立即發現
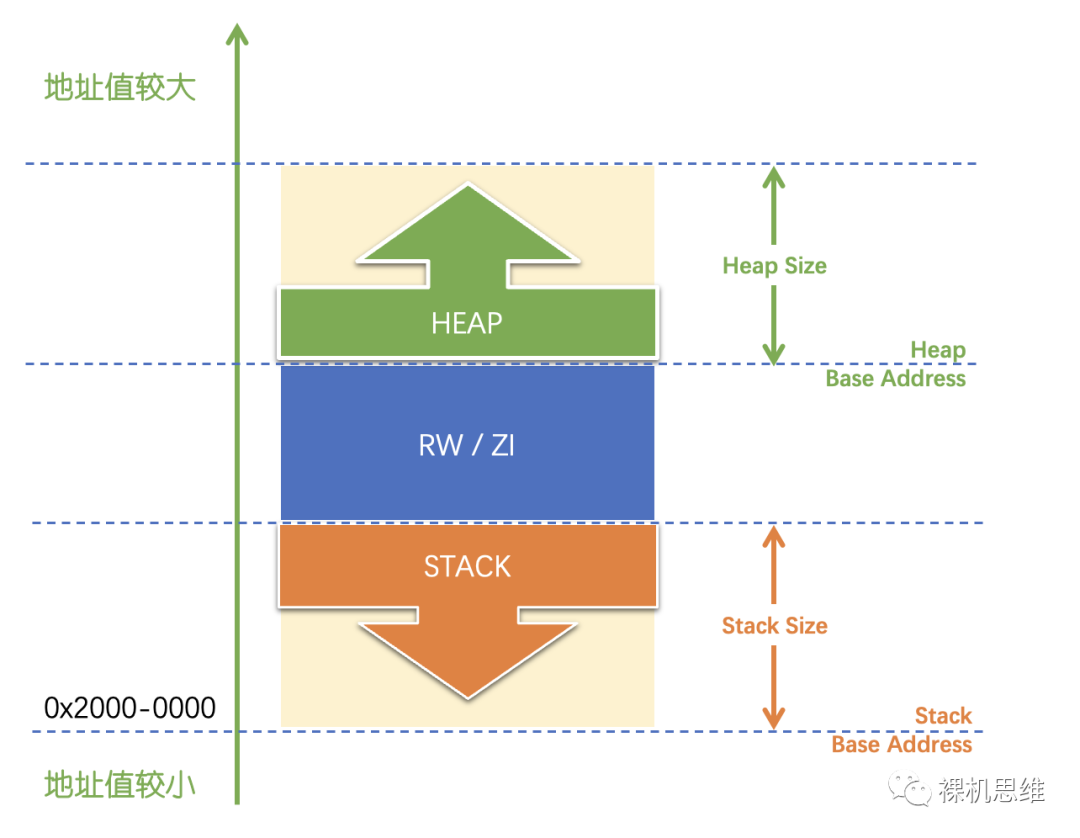
- 該模型屬于“兩段式模型”的變種
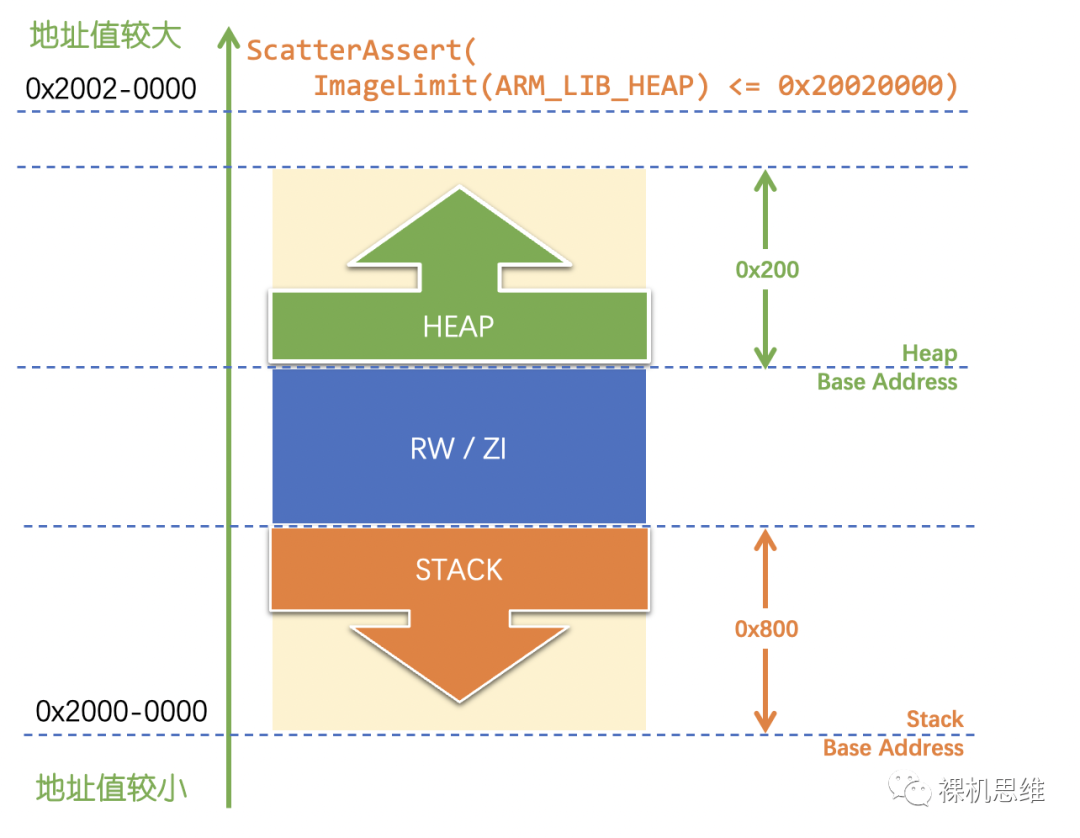
- 與過去堆和棧的“相向生長”不同,該模型采用了“背向生長”的方式——避免了棧與堆的相互傷害
- 棧被放在了SRAM的起始位置(Cortex-M從架構上鼓勵將SRAM放置在從0x2000-0000開始的地址上),這樣一旦發生棧溢出,指針就會指向SRAM存儲器以外的無效位置——這在大部分芯片上會觸發“Bus Fault”,從而產生故障異常——這就實現了對棧溢出的當場捕獲,并且不依賴MPU或者“棧底地址限制檢測(Stack Limit Checking)”之類的架構特性。
當然有些芯片設計者可能會選擇“隱藏這類錯誤”,不僅不會觸發異常,而且會當做無事發生,具體表現為:對無效地址的寫入操作將被無視,對無效地址的讀取操作將會返回0值。具體可以參考芯片手冊,或者干脆做個實驗。
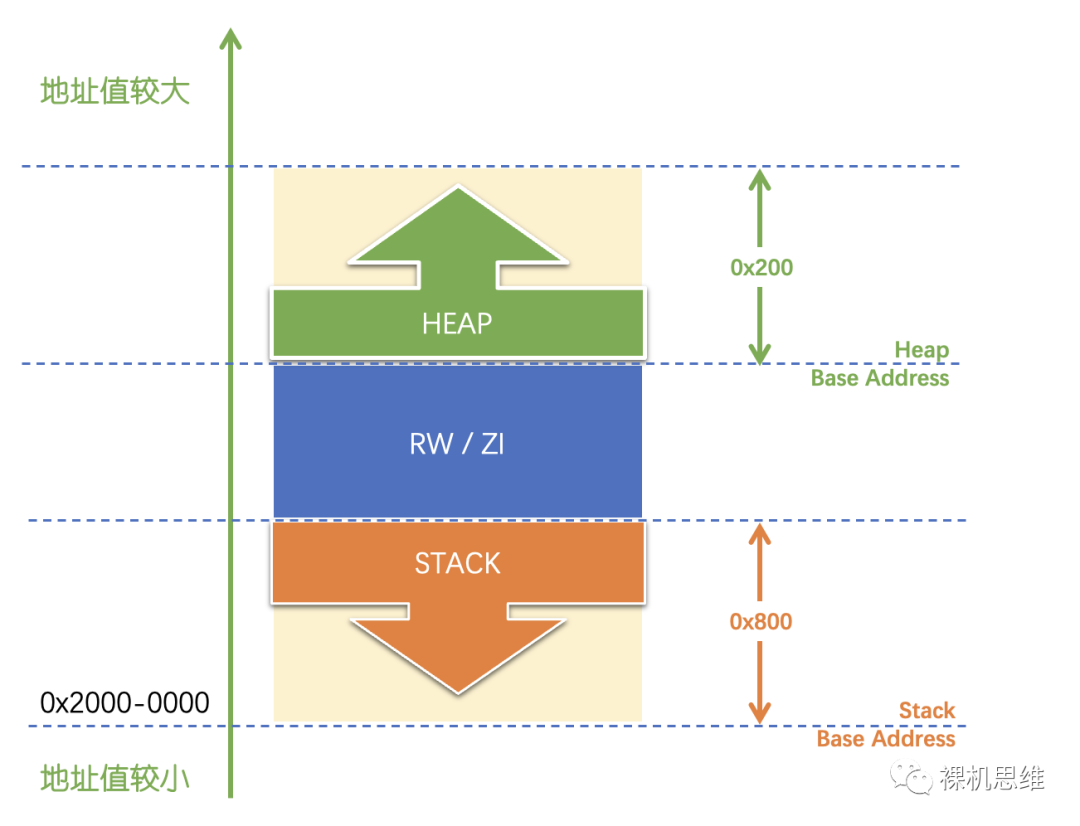
- 堆被放置在了RAM的最后,中間夾著存放靜態/全局變量的“RW/ZI區域”,這也是“兩面包夾芝士”模型(或者“三明治”模型)名稱的由來。這樣的安排也徹底杜絕了棧和堆對“RW/ZI區域”發生入侵的可能。當堆溢出時,與棧類似,對大部分芯片來說都會觸發故障異常,從而在開發調試階段第一時間被我們所捕獲。
【Arm官方低調推薦的”新“方法】
其實,Arm Compiler 在很久之前就逐步淘汰了“大聰明的單段對向生長模型”,而“兩段模型”早已成為主流。比如,我們在匯編啟動文件中經常可以見到這樣的代碼片段:
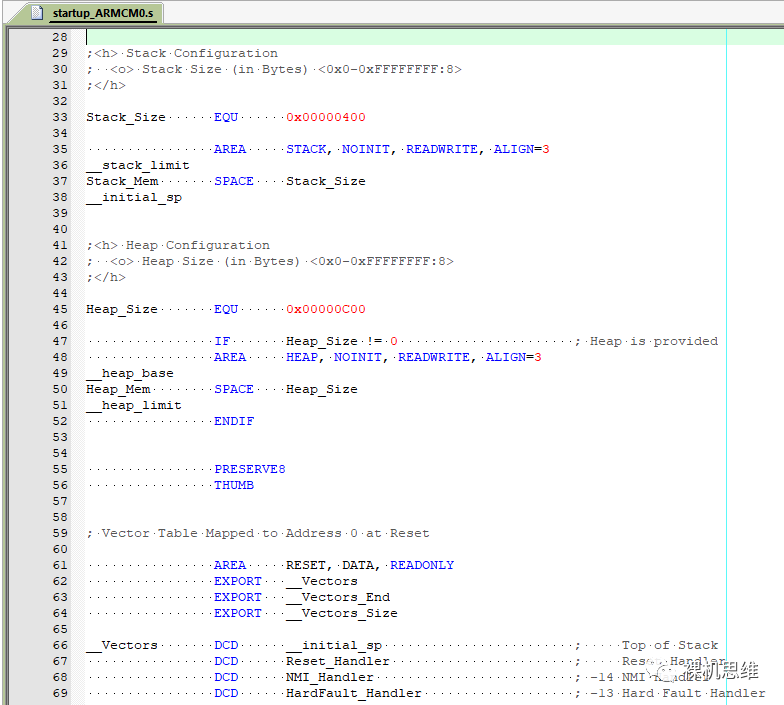
這就是“兩段式”模型的證據。實際上,在啟動代碼的尾部,匯編程序通過:
IMPORT __use_two_region_memory
選擇了對兩段式模型提供支持的libc庫:

注意:此步驟只針對使用匯編啟動文件的情況。如果你的啟動文件是C,則可跳過該步驟。
在工程管理器中找到你的匯編啟動文件,它通常以
startup_<芯片型號>.s
的形式命名:
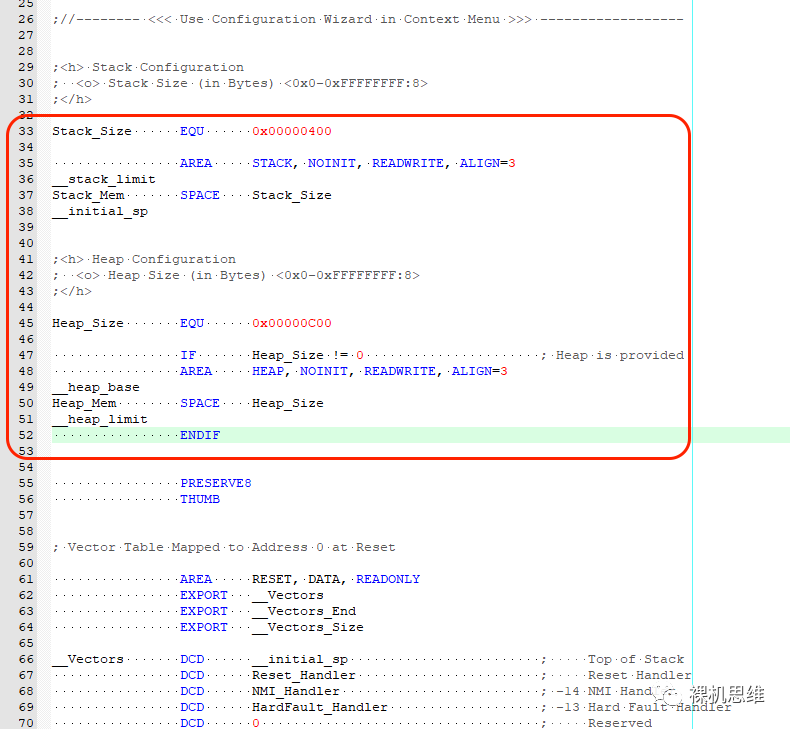
繼續移動到匯編文件的尾部,找到如下的代碼:
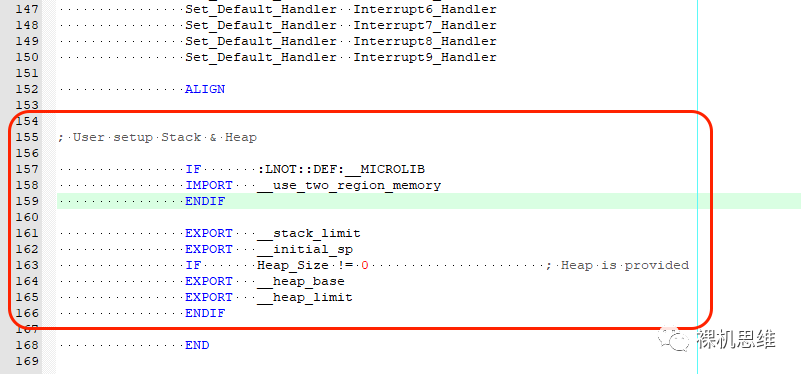
移動到中斷向量表的定義處:
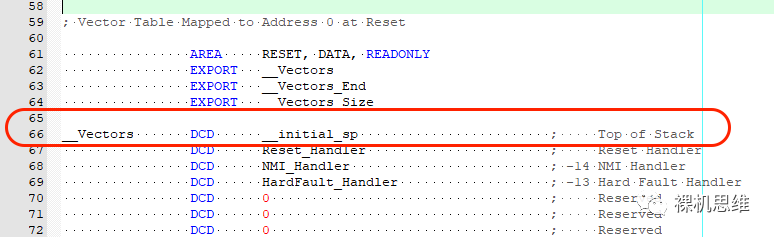
__VectorsDCD__initial_sp
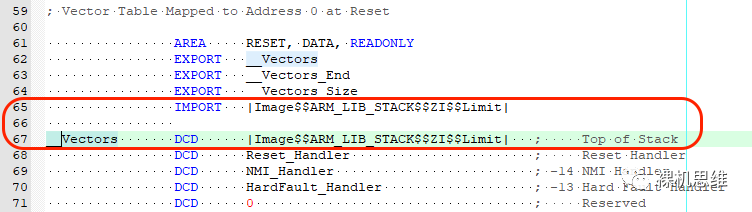
替換為如下內容:
IMPORT |Image$$ARM_LIB_STACK$$ZI$$Limit|
__VectorsDCD|Image$$ARM_LIB_STACK$$ZI$$Limit|
即:
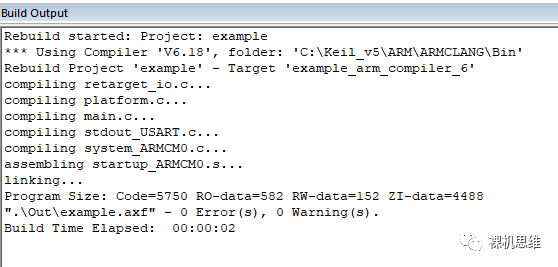
此時,如果你著急編譯,當你當你開啟了microLib時,很可能會看到如下的鏈接錯誤:
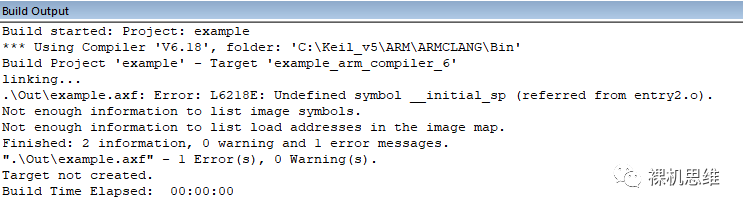
Error: L6218E: Undefined symbol __initial_sp (referred from entry2.o).
或者你沒有開啟 microLib,則會看到一個不同的錯誤:

Error: L6915E: Library reports error: The semihosting __user_initial_stackheap cannot reliably set up a usable heap region if scatter loading is in use
這都是正常的,不必驚慌。這類錯誤會在完成后面的步驟后自然消失。步驟二:獲取鏈接腳本(Scatter Script)
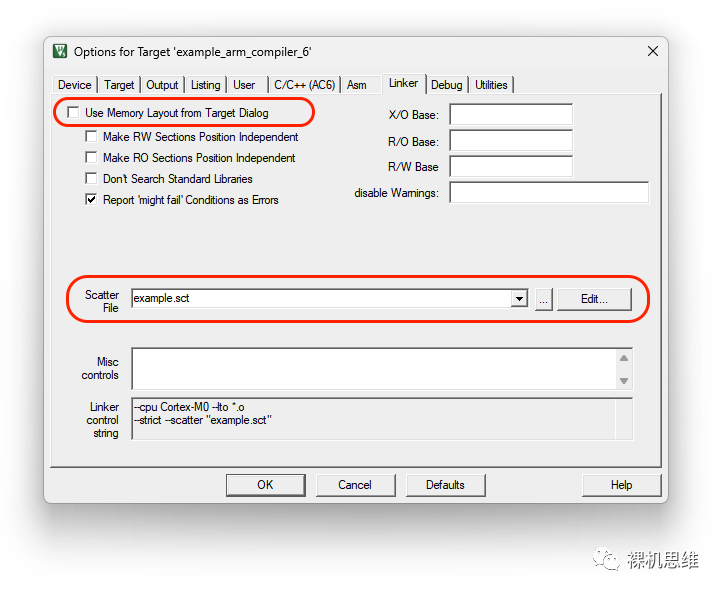
打開工程配置窗口“Options for Target”,切換到“Linker”選項卡:
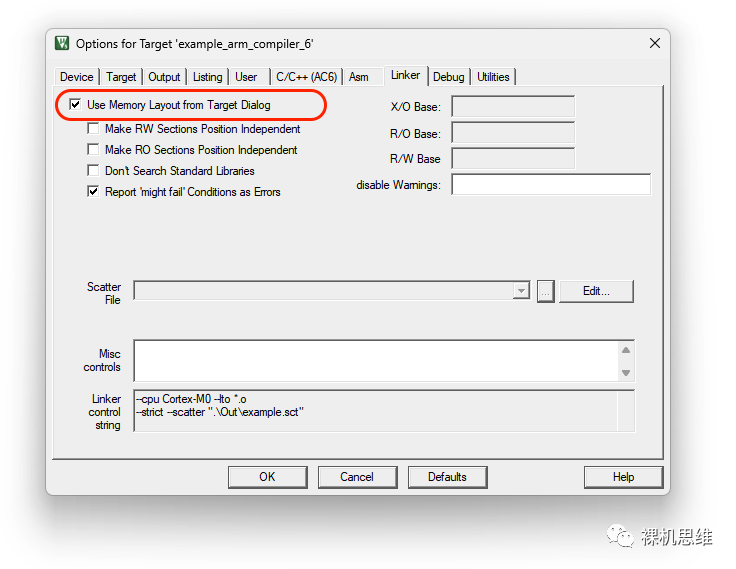
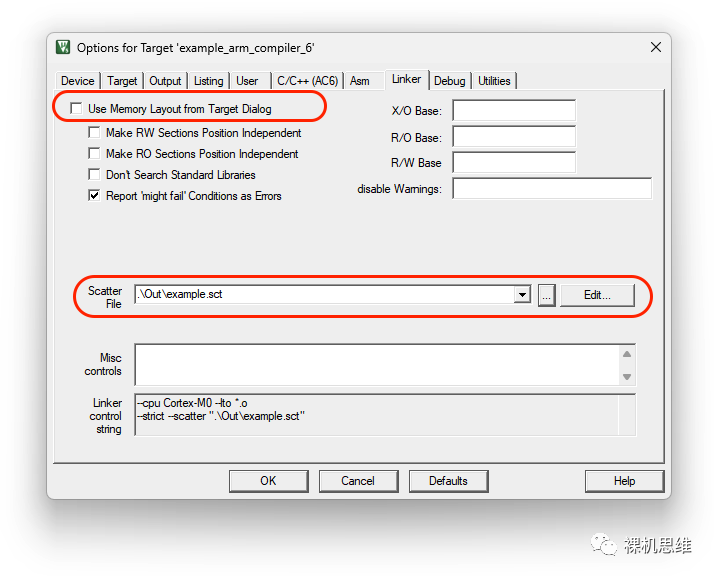
單擊 Edit 按鈕,可以看到腳本的內容:
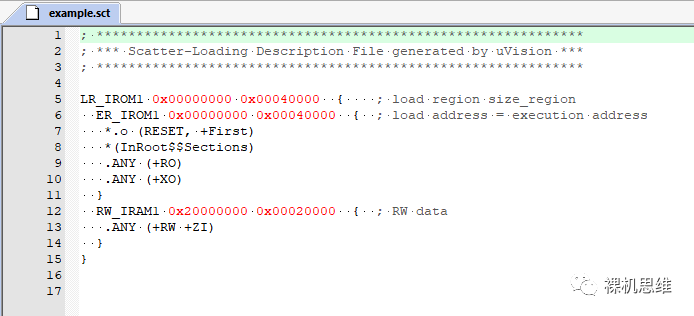
為了避免該問題,應該將它從 Out 目錄中移動到工程目錄下。具體步驟為,右鍵單擊腳本文件名:
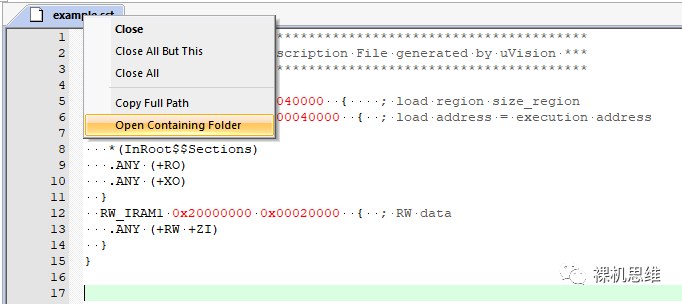
在編輯器中打開我們的腳本文件:
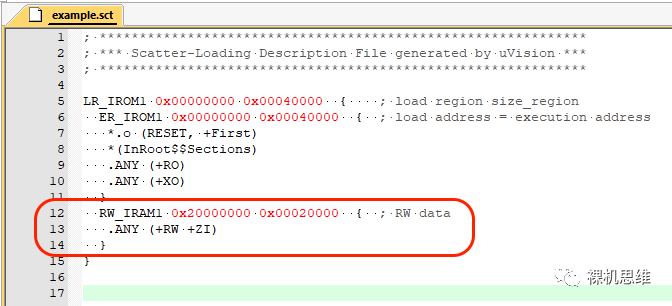
是的,你的猜測沒錯:當我們沒有特別說明時,Stack和Heap都以ZI的形式存在于上述空間內,其位置任由Linker擺布——這當然也帶來了很多不確定性。
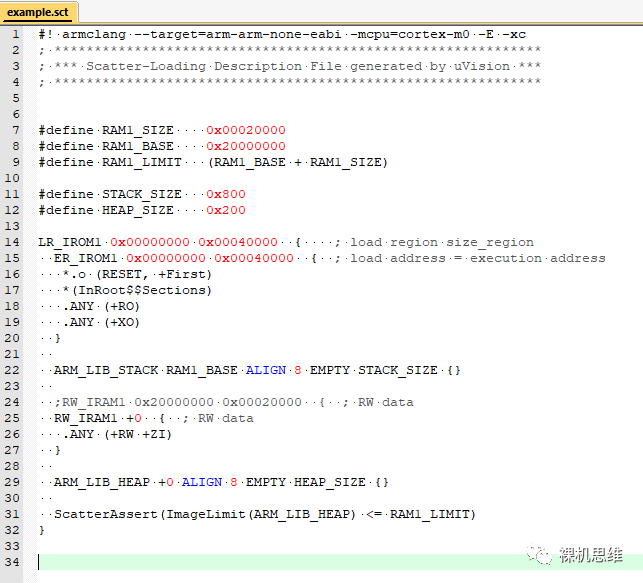
接下來我們要做的就是按照我們的設計——“兩面包夾芝士”來明確的指定棧和隊列的大小和位置:
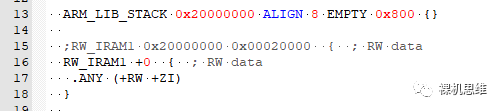
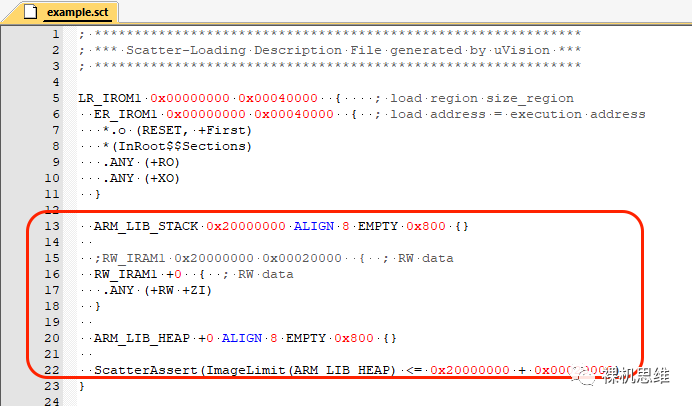
ARM_LIB_STACK 0x20000000 ALIGN 8 EMPTY 0x800 {}
這里:- 起始地址是 0x20000000
- STACK的大小是 0x800
- ALIGN 8 指定對齊是8個字節
- EMPTY是必須要保留的,它用來說明 ARM_LIB_STACK 是一個大數組,里面默認填充了0。
- 如果你想修改填充的內容還可以通過關鍵字 FILL <填充值> 來指定填充的32bit數值,比如:
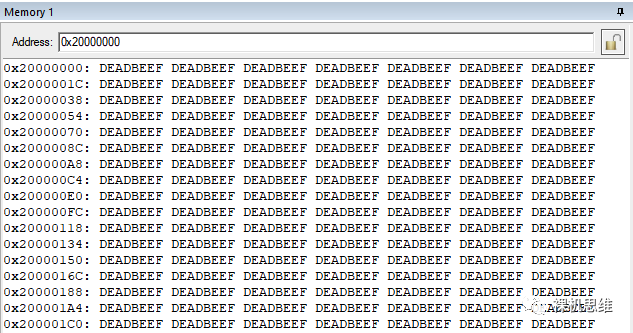
ARM_LIB_STACK 0x20000000 ALIGN 8 FILL 0xDEADBEEF EMPTY 0x800 {}
它實現了往0x20000000開始的0x800(2KB)大小的棧空間中填充0xDEADBEEF的功能:
為了讓ZI/RW緊隨其后——放在STACK的后面,我們需要對 RW_IRAM1 的描述進行修改,即從:
RW_IRAM1 0x20000000 0x00020000 {
修改為:
RW_IRAM1+0{
即:
接下來,我們要用類似的方法緊隨 RW_IRAM1 之后放置名為 ARM_LIB_HEAP 的execution region——用來指定堆的位置和大小:
ARM_LIB_HEAP +0 ALIGN 8 EMPTY 0x200 {}
可以看到,這里與棧的設置方式幾乎一樣,而“+0”則同樣告訴linker:請將ARM_LIB_HEAP緊鄰前面的 RW_IRAM1 放置。最終的效果如下:
LR_IROM1 0x00000000 0x00040000 {
ER_IROM1 0x00000000 0x00040000 {
(RESET, +First)
*(InRoot$$Sections)
(+RO)
(+XO)
}
ARM_LIB_STACK 0x20000000 ALIGN 8 EMPTY 0x800 {}
0x20000000 0x00020000 { ; RW data
RW_IRAM1 +0 { ; RW data
(+RW +ZI)
}
ARM_LIB_HEAP+0ALIGN8EMPTY0x200{}
}
還記得我們前面刪除了原本對RW_IRAM1的尺寸限制(也就是0x0002000)么?這意味著,現階段的腳本文件對我們實際使用的RAM空間是沒有任何限制的——換句話說,如果超出了芯片實際的SRAM大小,編譯器也是不會報告錯誤的。為了重新加入這一限制,我們可以在 ARM_LIB_HEAP的后面加入下面的語句:
ScatterAssert(ImageLimit(ARM_LIB_HEAP) <= 0x20000000 + 0x20000)
這里:- ScatterAssert() 是讓linker對括號中的內容進行檢查
- ImageLimit() 是在編譯時刻獲得括號內指定execution region的終止地址
- 0x20000000+0x20000是例子中整個RAM的終止地址(這里假設RAM從0x20000000開始,大小是0x20000)
- 綜合來說,上述代碼的作用是在linker的鏈接階段計算HEAP的終止地址,確認它是否落在了RAM的有效范圍內。
Error:L6388E:ScatterAssertexpression(ImageLimit(ARM_LIB_HEAP)<=?0x20000000?+?0x20000)?failed?on?line?22?:?(0x20001220?<=?0x20020000)
最終效果如下:
對應的“兩面包夾芝士”圖示如下:
【“雖遲但到”的宏和頭文件】
是的,你猜得沒錯,我們可以在鏈接腳本中使用編譯預處理,這意味著:
- 我們可以使用宏
- 我們可以include頭文件
- 我們可以進行條件編譯
具體方法并不難,只需要在鏈接腳本的“第一行”,注意一定要是第一行(Number One)——前面不能有任何內容,空行或者注釋都不行——放置如下的內容:
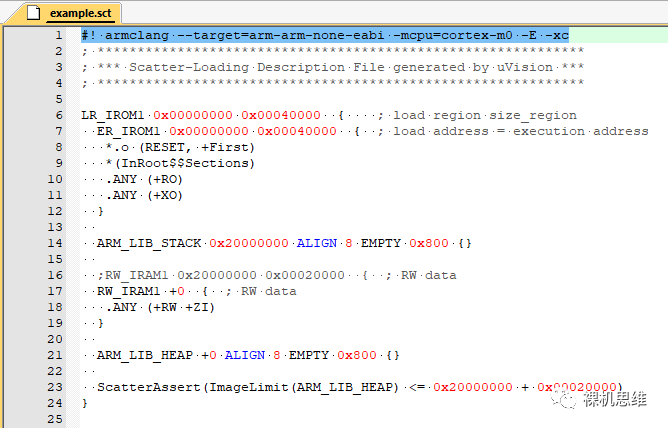
#define RAM1_SIZE 0x00020000
#define RAM1_BASE 0x20000000
#define RAM1_LIMIT (RAM1_BASE + RAM1_SIZE)
#define STACK_SIZE 0x800
#define HEAP_SIZE 0x200
需要注意的是:
- 在較新版本的MDK中,上述方法“應該”同時支持Arm Compiler 5(armcc)和Arm Compiler 6(armclang)。你可以關注【裸機思維】公眾號后,發送關鍵字“MDK”來獲取最新的MDK。
...
以解決可能出現的編譯錯誤。
- 如果你的頭文件并沒有“直接”放置在工程目錄下,而是存在一個相對路徑,則可以通過在上述命令行中追加 -I <路徑> 的形式來告知編譯器去哪里搜索我們的頭文件。比如:
或者
則是告訴編譯器從相對路徑 "../../cfg" 下去搜索頭文件。
-
當你通過修改頭文件的方式來更新scatter script的內容后,第一次編譯,請務必一定要以“Rebuild All”的形式進行,否則你的修改不會生效。
別說我沒提醒過你哦!
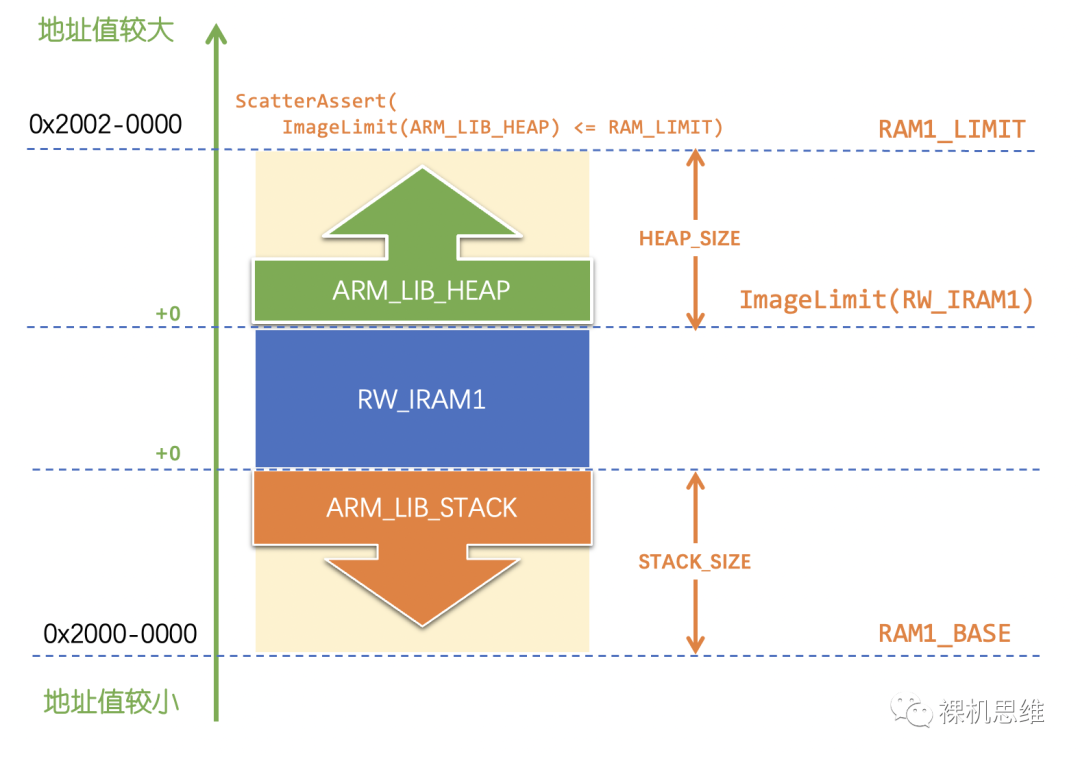
【如何把剩余的空間都留給堆】
很多時候,把剩余空間都留給堆是一個不錯的想法,這樣“兩面包夾芝士”模型就獲得了和“單段相向生長”模型一樣的優勢——配置簡單。由于我們已經有了宏的幫助,借助 ImageLimit() 我們可以將 HEAP_SIZE 的宏定義修改為:
它的意思是:用RAM1的終止地址減去 RW_IRAM1的終止地址,獲得中間的差額,其圖示如下:
看似完美,有的小伙伴一編譯就會報告如下的錯誤:

即:
Error: L6388E: ScatterAssert expression (ImageLimit(ARM_LIB_HEAP) <= (0x20000000 + 0x20000)) failed on line 29 : (0x20020004 <= 0x20020000)
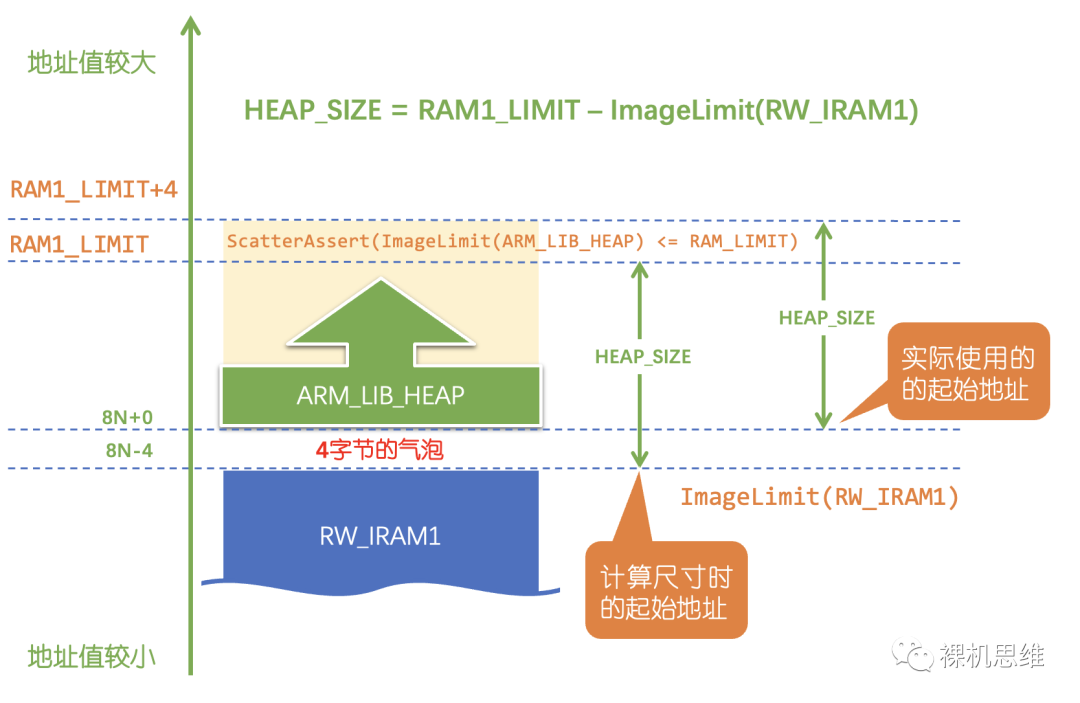
奇怪,我們的計算公式應該沒錯啊——Heap的尺寸應該就是使用整個 RAM的終止地址減去 RW_IRAM1 的終止地址啊,為什么提示差4個字節呢?
聰明的小伙伴一定已經注意到了,我們在 ARM_LIB_HEAP 的定義中,指定了其首地址的對齊為8字節:
ARM_LIB_HEAP +0 ALIGN 8 EMPTY HEAP_SIZE {}
而 RW_IRAM1 的尺寸不一定是8的整倍數,當它只是“4的整倍數”而不滿足“8的整倍數”這一條件時,ImageLimit(RW_IRAM1)的后面與 ARM_LIB_HEAP的起始地址之間就會產生一個4字節的氣泡:
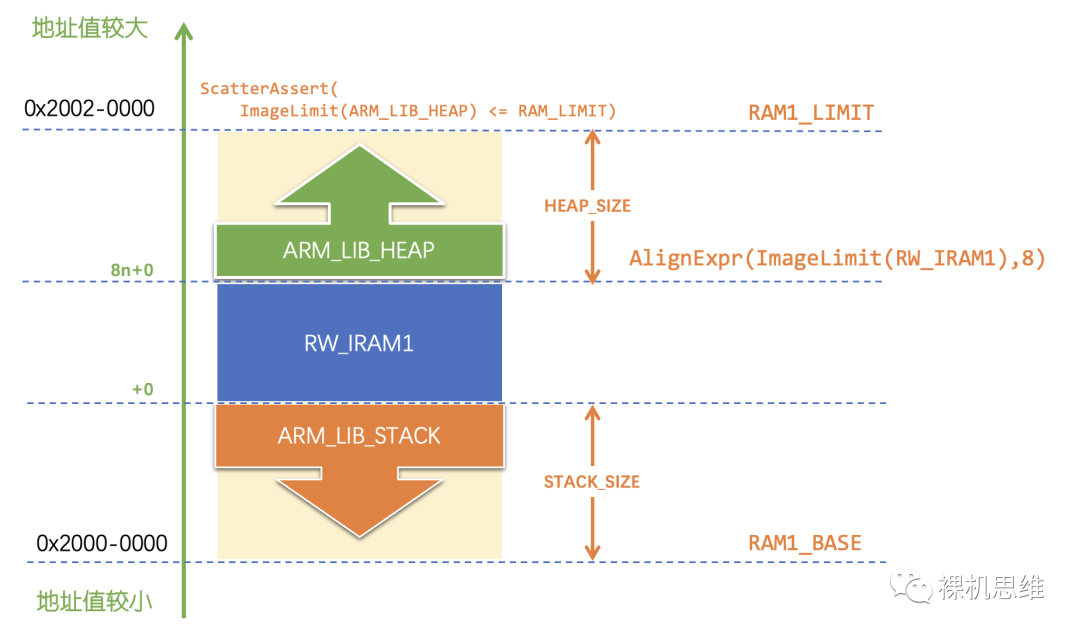
要解決這一問題也很簡單,我們可以使用 scatter script 腳本為我們提供的一個專門來進行地址對齊的函數:
AlignExpr(<地址數值>,<對齊要求>)
比如:
AlignExpr(ImageLimit(RW_IRAM1), 8)
就表示對 RW_IRAM1 的終止地址進行 8 字節對齊。借助它的幫助,我們可以修改腳本如下:
(RAM1_LIMIT-AlignExpr(ImageLimit(RW_IRAM1),8))
即:
再編譯時,已然沒有問題。
【如何隨時隨地的了解棧的最大使用情況】
水印法是實現“最大棧用量統計”的最有效方式。其原理也不復雜:
- 先用指定的水印常數(比如 0xDEADBEEF)將整個棧填滿;
- 從棧空間的最初頂部(棧存儲空間的終止地址)向下開始搜索之前填充的水印常數——一旦碰到水印,就將當前已經經歷過的RAM總量作為棧的最大深度(最大用量);
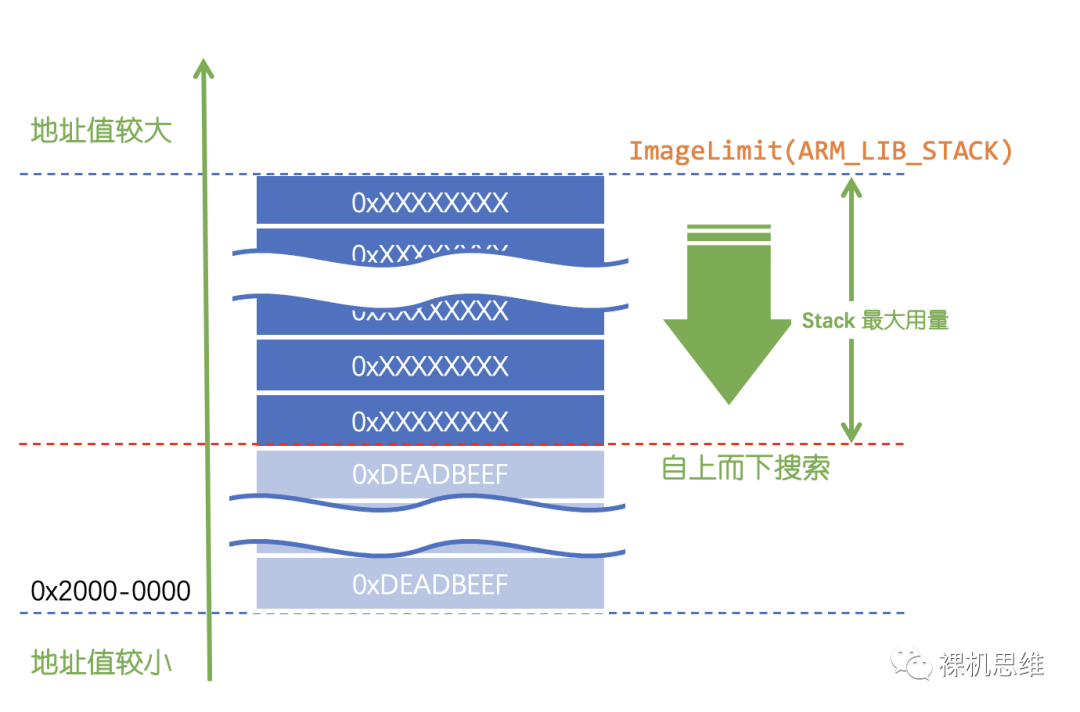
ARM_LIB_STACK0x20000000ALIGN8FILL0xDEADBEEFEMPTYSTACK_SIZE
{
}
然后借助下面的代碼完成統計工作:
uint32_t calculate_stack_usage_topdown(void)
{
extern uint32_t Image$$ARM_LIB_STACK$$Limit[];
extern uint32_t Image$$ARM_LIB_STACK$$Length;
uint32_t *pwStack = Image$$ARM_LIB_STACK$$Limit;
uint32_t wStackSize = (uintptr_t)&Image$$ARM_LIB_STACK$$Length / 4;
uint32_t wStackUsed = 0;
do {
if (*--pwStack == 0xDEADBEEF) {
break;
}
wStackUsed++;
} while(--wStackSize);
printf("
Stack Usage: [%d/%d] %2.2f%%
",
wStackUsed * 4,
(uintptr_t)&Image$$ARM_LIB_STACK$$Length,
( (float)wStackUsed * 400.0f
/ (float)(uintptr_t)&Image$$ARM_LIB_STACK$$Length));
return wStackUsed * 4;
}
這里有幾點需要說明一下:
-
armlink 為我們提供了通用的語法來獲取 execution region 的起始地址、大小和終止地址:
extern uint32_t Image$$$$Base[];
externuint32_tImage$$$$Length;
extern uint32_t Image$$$$Limit[];
這里,Base和Limit被定義成了不定長數組的形式,因此我們可以直接把它們當做常量指針來使用——獲取所需的地址。Length被定義成了一個普通的uint32_t型的變量,按照官方文檔的要求,雖然很反直覺,但如果要獲取它的值——也就是對應execution region的大小,必須要對其進行&操作,并隨后強制轉化為整形數值。這么說也許有點抽象,不妨對照前面的代碼來看:
#include
這里,我們通過 Image$ARM_LIB_STACK$$Limit[] 將棧的終止地址賦值給了(uint32_t *)型的指針 pwStack。以表達式 (uintptr_t)&Image$$ARM_LIB_STACK$$Length 獲取了 ARM_LIB_STACK 的實際大小。
-
普通情況下,在變量名中使用 “$” 會在Arm Compiler 6引發警告:
warning:'$'inidentifier[-Wdollar-in-identifier-extension]
為了讓編譯器閉嘴,我們臨時對函數 calculate_stack_usage_topdown() 在編譯時刻做了屏蔽warning的操作:
uint32_t calculate_stack_usage_topdown(void)
{
...
}
而 -Wdouble-promotion 則是由printf中的百分比運算引起的,一并屏蔽即可。
在任意時刻,當我們想要知道當前系統的最大棧用量時,可以直接調用函數 calculate_stack_usage_topdown(),比如:
int main(void)
{
...
calculate_stack_usage_topdown();
...
}
一個可能的執行結果如下:

自上而下統計棧用量的方法優點是:當棧空間很大而實際棧用量較小時,可以較快的完成統計;缺點是:如果恰好棧里因為任何原因(比如用戶定義了一個局部變量,然后恰好給他賦予了我們的水印常數),就會造成統計錯誤——沒能實際獲得最大深度。
針對這一問題,我們可以修改搜索策略,從占空間的起始地址(也就是基地址)處向上搜索“非水印常數”——一旦碰到,就可以用已知的棧空間尺寸減去已經經歷過的RAM總量作為棧的最大深度(最大用量)。
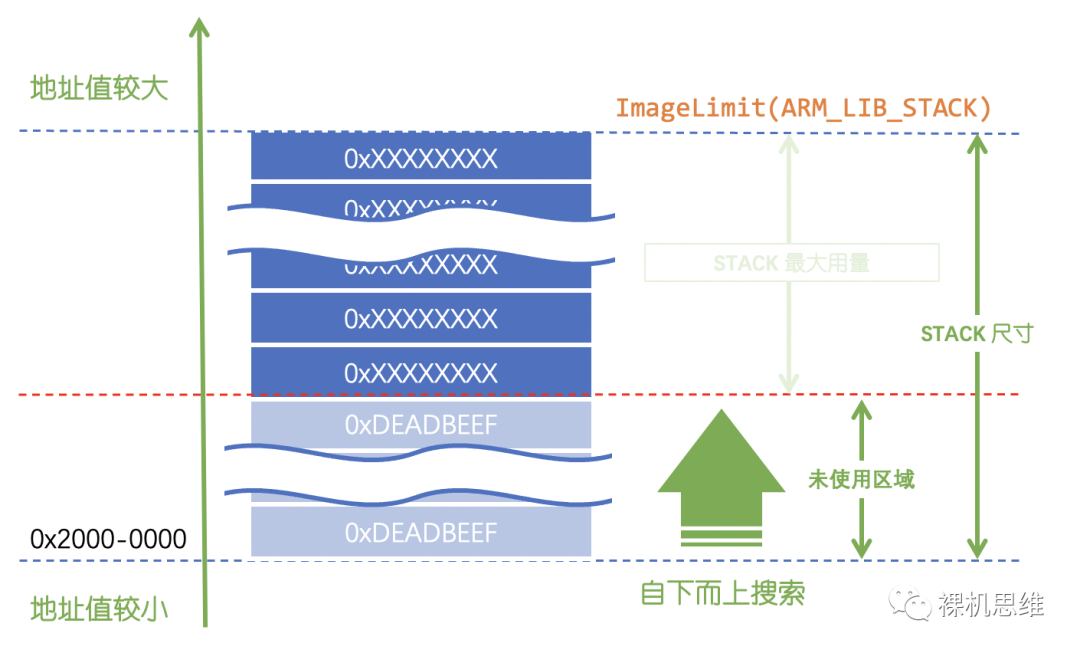
該方法的優點是:不容易發生誤判;缺點是:當棧空間很大而實際棧用量較小時往往較為耗時。對應的代碼如下:
uint32_t calculate_stack_usage_bottomup(void)
{
extern uint32_t Image$$ARM_LIB_STACK$$Base[];
extern uint32_t Image$$ARM_LIB_STACK$$Length;
uint32_t *pwStack = Image$$ARM_LIB_STACK$$Base;
uint32_t wStackSize = (uintptr_t)&Image$$ARM_LIB_STACK$$Length;
uint32_t wStackUsed = wStackSize / 4;
do {
if (*pwStack++ != 0xDEADBEEF) {
break;
}
} while(--wStackUsed);
printf("
Stack Usage: [%d/%d] %2.2f%%
",
wStackUsed * 4,
wStackSize,
((float)wStackUsed*400.0f/(float)wStackSize));
return wStackUsed * 4;
}
【后記】
在這篇文章中,我們介紹了棧和堆在存儲器中的常見排布模型,比較了它們的優劣,并提出了一種被稱為“兩面包夾芝士”的兩段式模型。該模型:
- 可以有效避免堆棧溢出破壞常規變量
- 溢出發生時可以在大部分芯片中第一時間觸發異常——被我們捕捉到
后面,我們以MDK為例介紹了如何在Arm Compiler環境下應用這一模型,并引入了使用宏對其進行進一步拓展的方法。
值得說明的是,這一方法對Arm Compiler 5(armcc)和Arm Compiler 6(armclang)同樣適用。支持MicroLib和非MicroLib的情況。無論啟動文件是否為匯編,都可以正常工作。
實際上,使用鏈接腳本而非匯編啟動文件來對兩段式堆棧模型進行配置是Arm公司一直以來所提倡的。隨著Arm Compiler 6的逐步普及,更多的芯片公司正在追隨Arm的腳步將原本的匯編啟動文件替換為 CMSIS 目錄下所提倡的純C語言啟動文件。
作為【反復橫跳】系列的一部分,我希望通過這篇文章能幫助大家掃清從Arm Compiler 5向Arm Compiler 6過渡圖中與棧相關的障礙。希望對你有所幫助。
審核編輯 :李倩
-
嵌入式
+關注
關注
5143文章
19563瀏覽量
315534 -
堆棧
+關注
關注
0文章
183瀏覽量
20061 -
變量
+關注
關注
0文章
614瀏覽量
28852
原文標題:99%開發者從未聽說過的堆棧模型
文章出處:【微信號:pzh_mcu,微信公眾號:痞子衡嵌入式】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Create2025百度AI開發者大會精彩回顧
Arm亮相2025年游戲開發者大會
云端AI開發者工具的核心功能
涂鴉智能與火山引擎達成重磅合作,億元補貼全力構建AIoT開發者生態

2024年AI開發者中間件工具生態全面總結
2024 RT-Thread開發者大會精彩回顧

開發者的開源鴻蒙故事
《HarmonyOS第一課》煥新升級,賦能開發者快速掌握鴻蒙應用開發
我國軟件開發者數量突破940萬
NVIDIA Jetson Orin Nano開發者套件的新功能

云端AI開發者工具怎么用
2024 VDC人工智能會場:全新藍心大模型矩陣,助力開發者高效創新

KaihongOS 4.1.2開發者預覽版正式上線,誠邀開發者免費試用!

多項AI新成果發布,涂鴉智能引領全球開發者共繪GenAI發展藍圖






 工商網監
工商網監
評論