 CPU Cache偽共享問題
CPU Cache偽共享問題

先看下這兩段代碼:
代碼段1:
const int row = 10240;
const int col = 10240;
int matrix[row][col];
int TestRow() {
//按行遍歷
int sum_row = 0;
for (int r = 0; r < row; r++) {
for (int c = 0; c < col; c++) {
sum_row += matrix[r][c];
}
}
return sum_row;
}
代碼段2:
int TestCol() {
//按列遍歷
int sum_col = 0;
for (int c = 0; c < col; c++) {
for (int r = 0; r < row; r++) {
sum_col += matrix[r][c];
}
}
return sum_col;
}
兩段代碼的目的相同,都是為了計算矩陣中所有元素的總和。
但有些區別:一個是按行遍歷元素做計算,一個是按列遍歷元素做計算。
它倆的運行速度有什么區別嗎?
如圖:
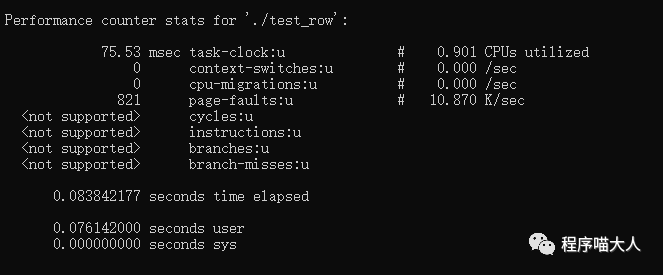
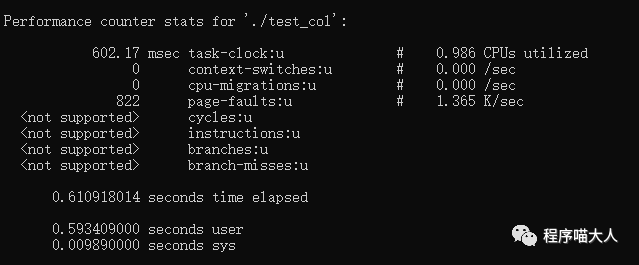
圖中可以看到,行遍歷的代碼速度比列遍歷的代碼速度快很多。
為什么按行遍歷的代碼比按列遍歷的代碼速度快?這里就是CPU Cache在起作用。
什么是CPU Cache?
可以先看下這個存儲器相關的金字塔圖:
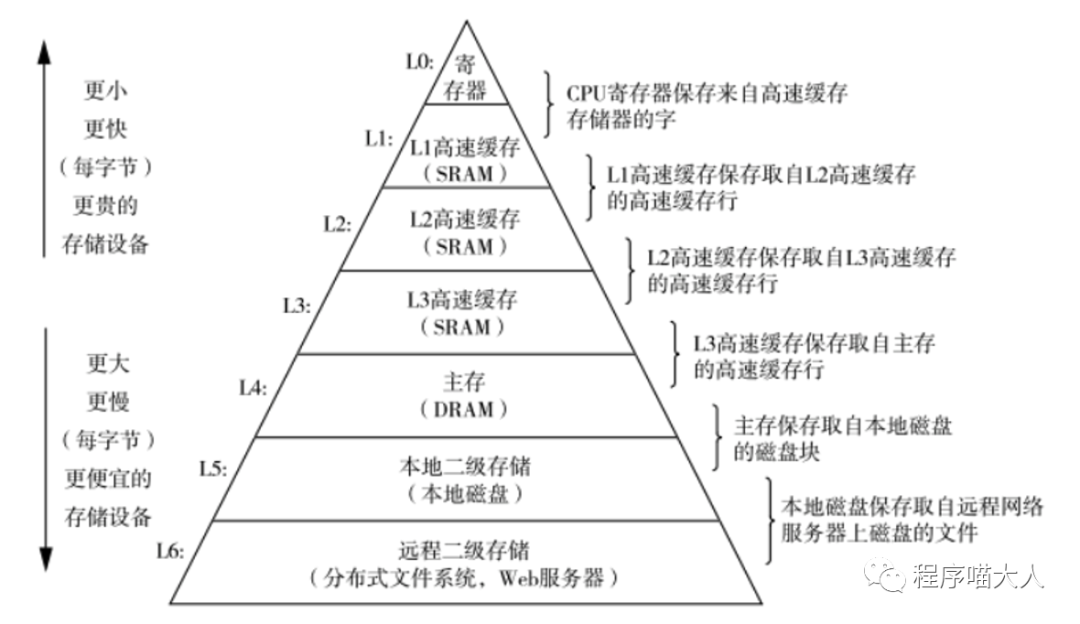
從下到上,空間雖然越來越小,但是處理速度越來越快,相應的,設備價格也越來越貴。
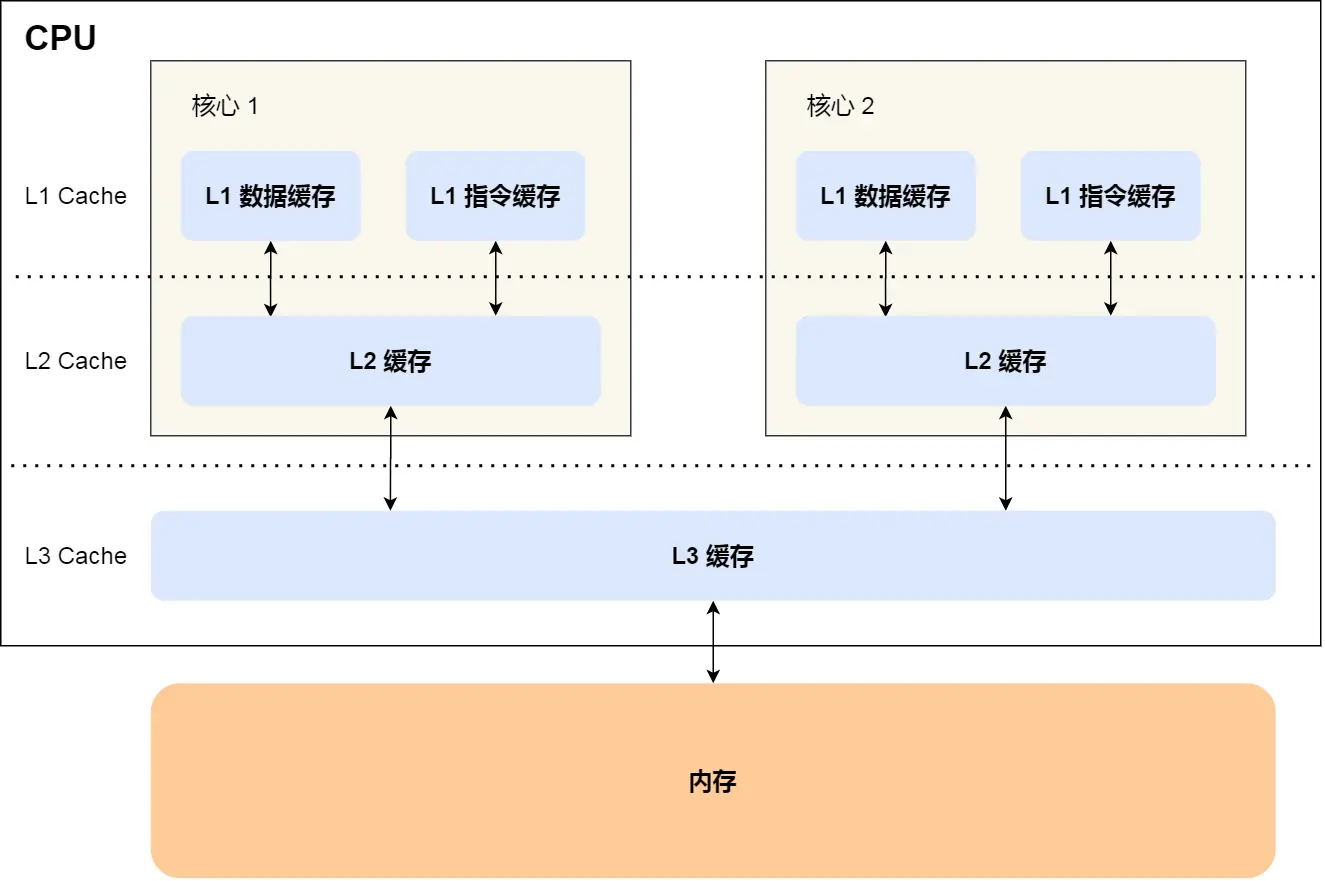
圖中的寄存器和主存估計大家都知道,那中間的L1 、L2、L3是什么?它們起到了什么作用?
它們就是CPU 的Cache,如下圖:
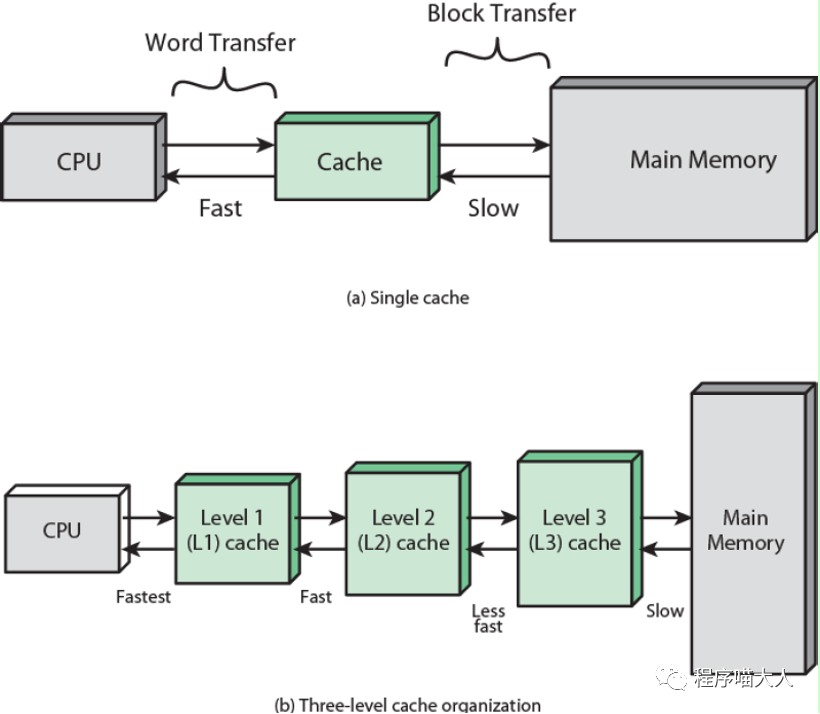
可以理解為CPU Cache就是CPU與主存之間的橋梁。
當CPU想要訪問主存中的元素時,會先查看Cache中是否存在,如果存在(稱為Cache Hit),直接從Cache中獲取,如果不存在(稱為Cache Miss),才會從主存中獲取。Cache的處理速度比主存快得多。
所以,如果每次訪問數據時,都能直接從Cache中獲取,整個程序的性能肯定會更高。
那,如何提高CPU Cache的命中率?
這里我不多介紹,感興趣的直接移步到我這篇文章:https://mp.weixin.qq.com/s/iKWQZxn6XYKU9KnlBRynfg
但CPU Cache這里還有個小問題,看下這兩段代碼:
代碼段1:
struct Point {
std::atomic<int> x;
// char a[128];
std::atomic<int> y;
};
void Test() {
Point point;
std::thread t1(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->x += 1;
}
},
&point);
std::thread t2(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->y += 1;
}
},
&point);
t1.join();
t2.join();
}
代碼段2:
struct Point {
std::atomic<int> x;
char a[128];
std::atomic<int> y;
};
void Test() {
Point point;
std::thread t1(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->x += 1;
}
},
&point);
std::thread t2(
[](Point *point) {
for (int i = 0; i < 100000000; ++i) {
point->y += 1;
}
},
&point);
t1.join();
t2.join();
}
兩端代碼的核心邏輯都是對Point結構體中的x和y不停+1。只有一點區別就是在中間塞了128字節的數組。
它們的執行速度卻相差很大。

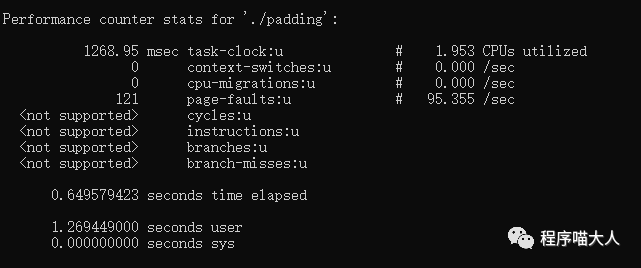
帶128的比不帶128的代碼,執行速度快很多。
為什么?
看過我上面文章的同學應該就知道,每個CPU都有自己的L1和L2 Cache,而Cache line的大小一般是64字節,如果x和y之間沒有128字節的填充,它倆就會在同一個Cache line上。
代碼中開了兩個線程,兩個線程大概率會運行在不同的CPU上,每個CPU有自己的Cache。
當CPU1操作x時,會把y裝載到Cache中,其他CPU對應的的Cache line失效。
然后CPU2加載y,會觸發Cache Miss,它后面又把x裝載到了自己的Cache中,其他CPU對應的Cache line失效。
然后CPU1操作x時,又觸發Cache Miss。
它倆就會是大體這個流程:
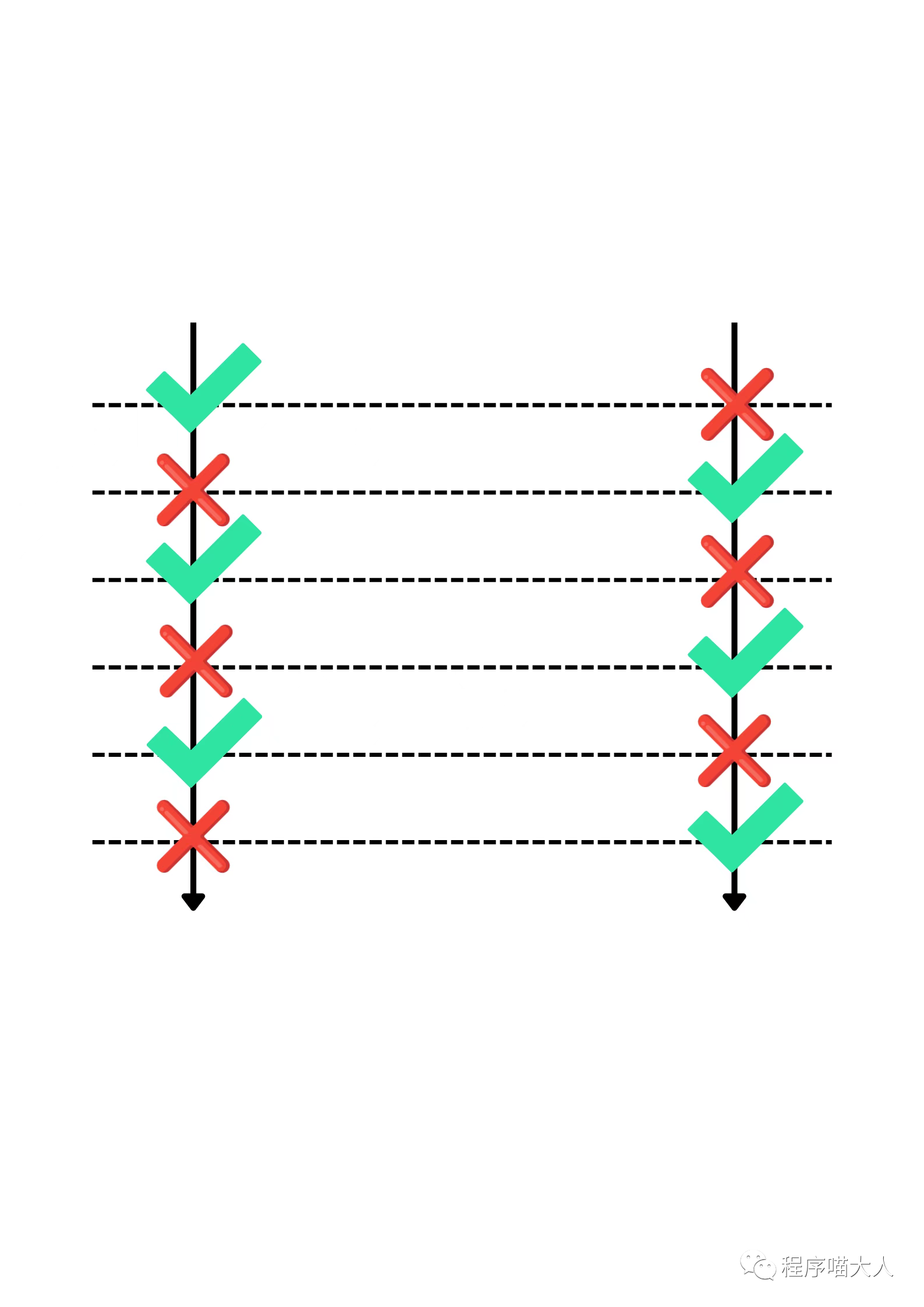
頻繁的觸發Cache Miss,導致程序的性能相當差。
而如果x和y中間加了128字節的填充,x和y不在同一個Cache line上,不同CPU之前不會影響,它倆都會頻繁的命中自己的Cache,整個程序性能就會很高,這就是傳說中的False Sharing問題。
所以我們寫代碼時,可以基于此做深一層思考,如果我們寫單線程程序,最好保證訪問的數據能夠相鄰,在一個Cache line上,可以盡可能的命中Cache。
如果寫多線程程序,最好保證訪問的數據有間隔,讓它們不在一個Cache line上,減少False Sharing的頻率。
上述內容源于前一段的技術分享,完整PPT在一個優質的C++學習圈里,來一起鉆研C++吧。
審核編輯 :李倩
-
cpu
+關注
關注
68文章
11097瀏覽量
217567 -
程序
+關注
關注
117文章
3827瀏覽量
83176 -
代碼
+關注
關注
30文章
4905瀏覽量
70954
發布評論請先 登錄
高性能緩存設計:如何解決緩存偽共享問題
如何在NXP MCU上啟用D-Cache?
腦電偽跡系列之腦電偽跡處理與技術剖析

腦電偽跡全解析:類型、成因與影響
真雙極和準雙極,差動跟偽差動使用的性能有差別嗎?
hyper-v共享,Hyper-V 共享:Hyper-V的資源共享設置
什么是緩存(Cache)及其作用
OPA1642做一個差分和偽差分輸出轉換的電路,在偽差分的情況下遇到的問題求解
Cache和內存有什么區別
做一個差分和偽差分輸出轉換的電路遇到的疑問求解
德國進口蔡司工業CT去散射偽影技術

解析Arm Neoverse N2 PMU事件L2D_CACHE_WR






 工商網監
工商網監
評論