") 一起來看看YOLOv8的結(jié)構(gòu)亮點
一起來看看YOLOv8的結(jié)構(gòu)亮點
導(dǎo)讀
出品YOLOv5的公司發(fā)布了最新的YOLOv8!一起來看看YOLOv8的結(jié)構(gòu)亮點。
回顧一下YOLOv5,不然沒機會了
這里粗略回顧一下,這里直接提供YOLOv5的整理的結(jié)構(gòu)圖吧:
Backbone:CSPDarkNet結(jié)構(gòu),主要結(jié)構(gòu)思想的體現(xiàn)在C3模塊,這里也是梯度分流的主要思想所在的地方;
PAN-FPN:雙流的FPN,必須香,也必須快,但是量化還是有些需要圖優(yōu)化才可以達到最優(yōu)的性能,比如cat前后的scale優(yōu)化等等,這里除了上采樣、CBS卷積模塊,最為主要的還有C3模塊(記住這個C3模塊哦);
Head:Coupled Head+Anchor-base,毫無疑問,YOLOv3、YOLOv4、YOLOv5、YOLOv7都是Anchor-Base的,后面會變嗎?
Loss:分類用BEC Loss,回歸用CIoU Loss。
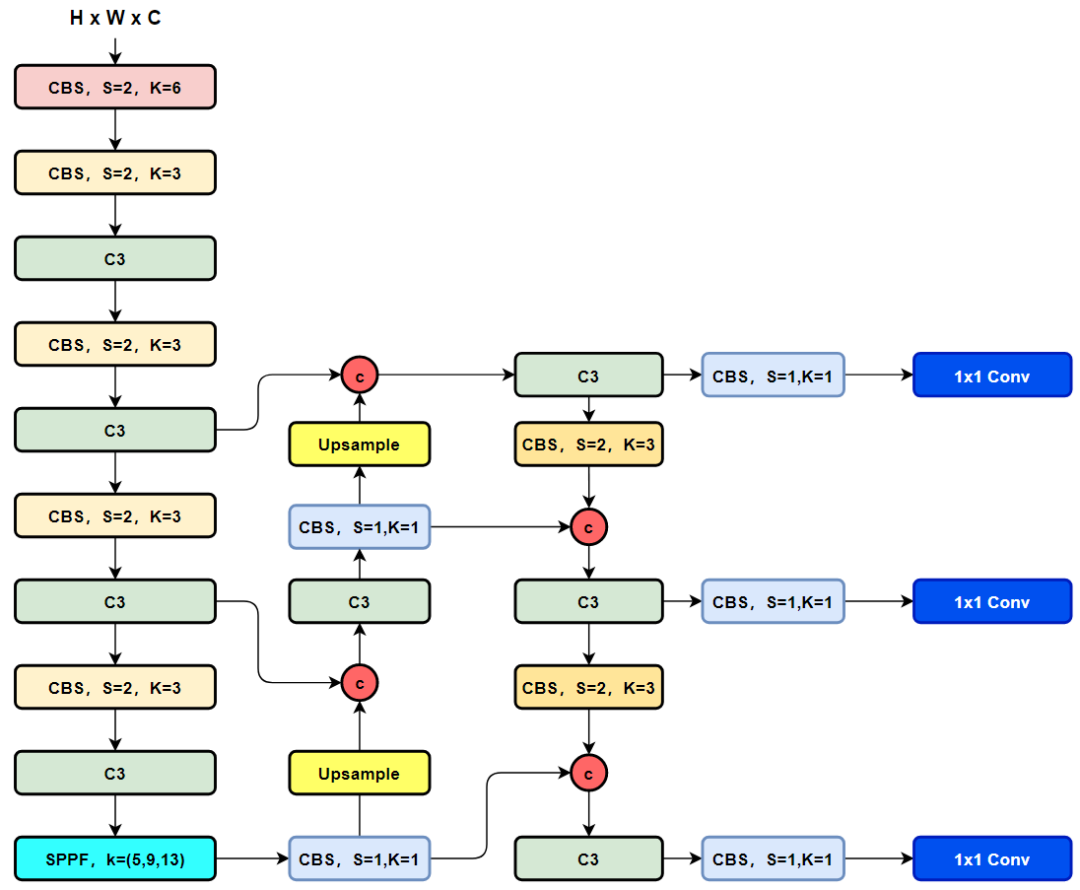
話不多說,直接YOLOv8吧!
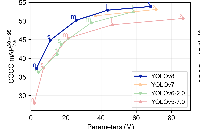
直接上YOLOv8的結(jié)構(gòu)圖吧,小伙伴們可以直接和YOLOv5進行對比,看看能找到或者猜到有什么不同的地方?
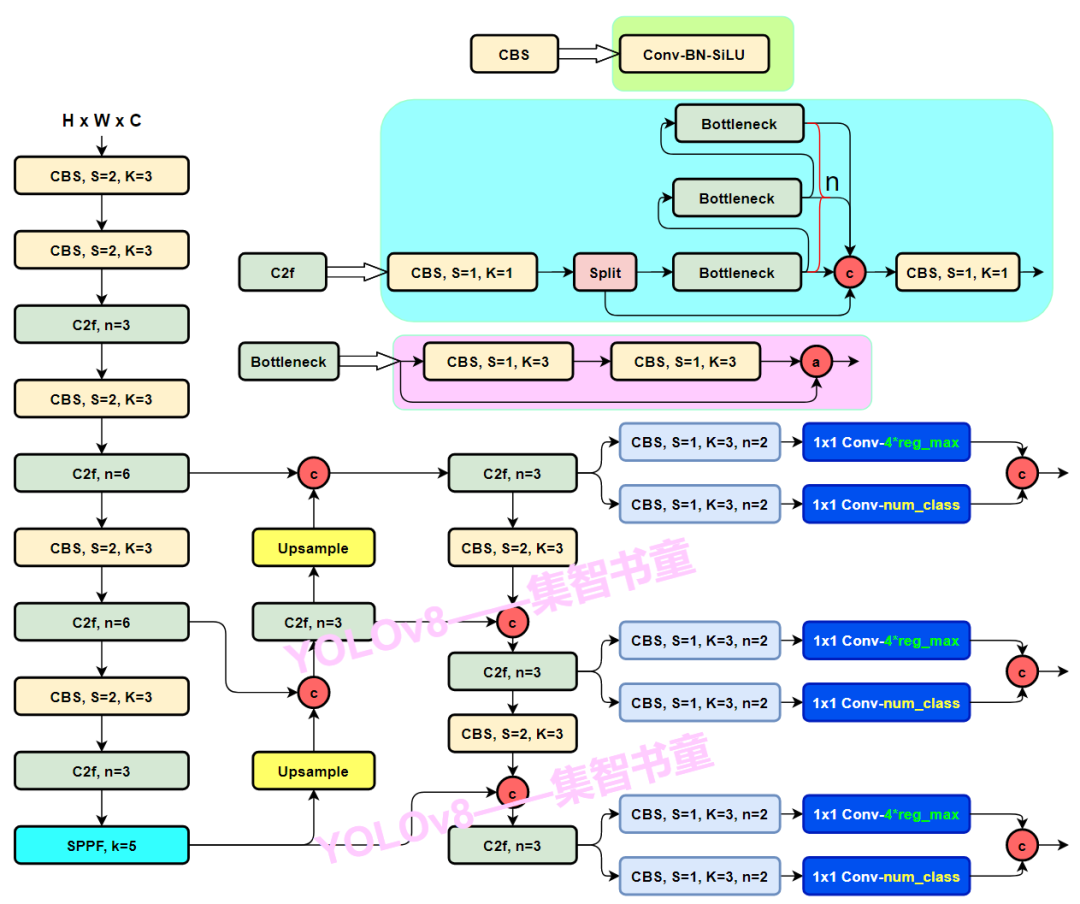
下面就直接揭曉答案吧,具體改進如下:
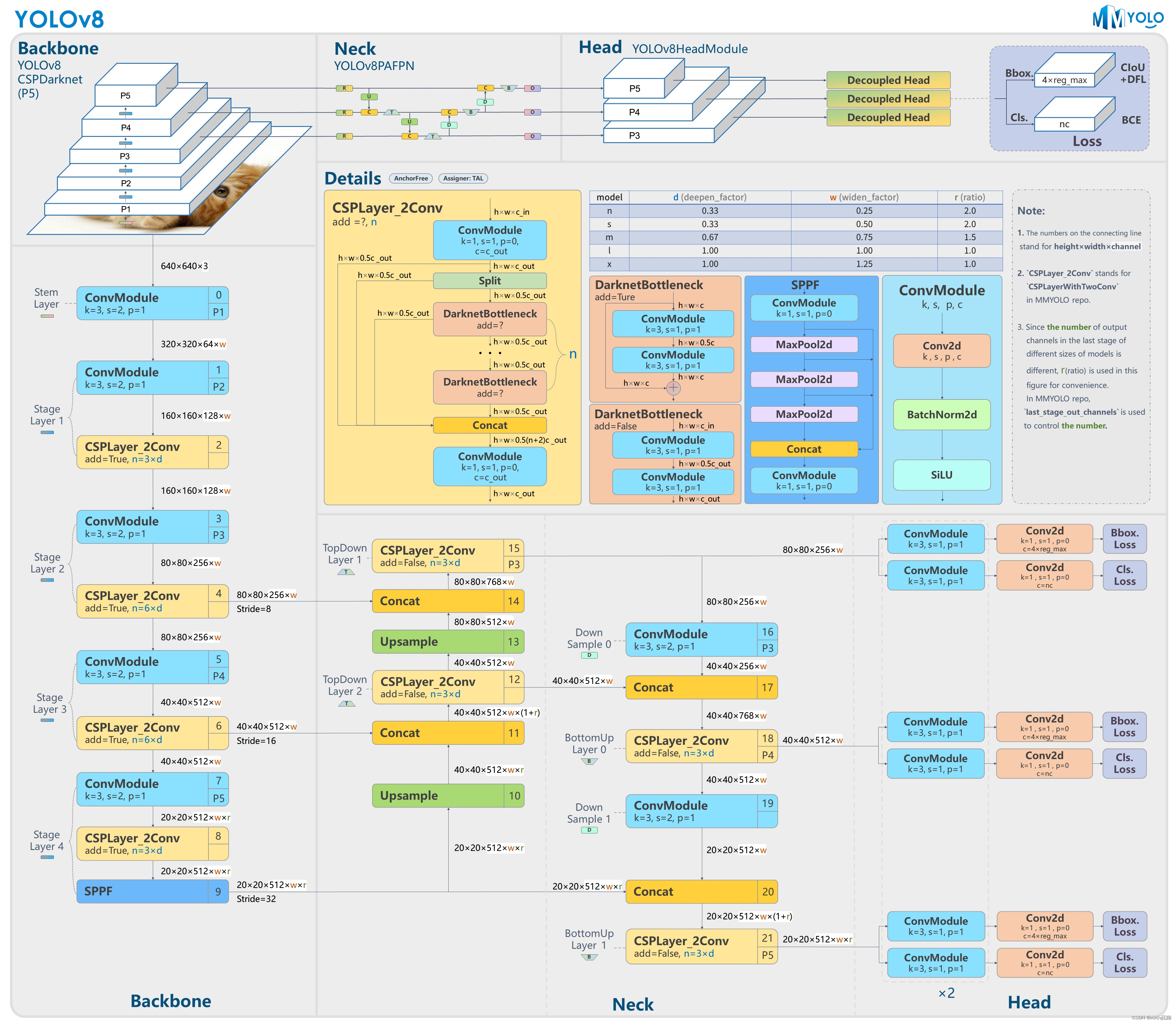
Backbone:使用的依舊是CSP的思想,不過YOLOv5中的C3模塊被替換成了C2f模塊,實現(xiàn)了進一步的輕量化,同時YOLOv8依舊使用了YOLOv5等架構(gòu)中使用的SPPF模塊;
PAN-FPN:毫無疑問YOLOv8依舊使用了PAN的思想,不過通過對比YOLOv5與YOLOv8的結(jié)構(gòu)圖可以看到,YOLOv8將YOLOv5中PAN-FPN上采樣階段中的卷積結(jié)構(gòu)刪除了,同時也將C3模塊替換為了C2f模塊;
Decoupled-Head:是不是嗅到了不一樣的味道?是的,YOLOv8走向了Decoupled-Head;
Anchor-Free:YOLOv8拋棄了以往的Anchor-Base,使用了Anchor-Free的思想;
損失函數(shù):YOLOv8使用VFL Loss作為分類損失,使用DFL Loss+CIOU Loss作為分類損失;
樣本匹配:YOLOv8拋棄了以往的IOU匹配或者單邊比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
1、C2f模塊是什么?與C3有什么區(qū)別?
我們不著急,先看一下C3模塊的結(jié)構(gòu)圖,然后再對比與C2f的具體的區(qū)別。針對C3模塊,其主要是借助CSPNet提取分流的思想,同時結(jié)合殘差結(jié)構(gòu)的思想,設(shè)計了所謂的C3 Block,這里的CSP主分支梯度模塊為BottleNeck模塊,也就是所謂的殘差模塊。同時堆疊的個數(shù)由參數(shù)n來進行控制,也就是說不同規(guī)模的模型,n的值是有變化的。

其實這里的梯度流主分支,可以是任何之前你學(xué)習(xí)過的模塊,比如,美團提出的YOLOv6中就是用來重參模塊RepVGGBlock來替換BottleNeck Block來作為主要的梯度流分支,而百度提出的PP-YOLOE則是使用了RepResNet-Block來替換BottleNeck Block來作為主要的梯度流分支。而YOLOv7則是使用了ELAN Block來替換BottleNeck Block來作為主要的梯度流分支。
C3模塊的Pytorch的實現(xiàn)如下:
classC3(nn.Module): #CSPBottleneckwith3convolutions def__init__(self,c1,c2,n=1,shortcut=True,g=1,e=0.5):#ch_in,ch_out,number,shortcut,groups,expansion super().__init__() c_=int(c2*e)#hiddenchannels self.cv1=Conv(c1,c_,1,1) self.cv2=Conv(c1,c_,1,1) self.cv3=Conv(2*c_,c2,1)#optionalact=FReLU(c2) self.m=nn.Sequential(*(Bottleneck(c_,c_,shortcut,g,e=1.0)for_inrange(n))) defforward(self,x): returnself.cv3(torch.cat((self.m(self.cv1(x)),self.cv2(x)),1))
下面就簡單說一下C2f模塊,通過C3模塊的代碼以及結(jié)構(gòu)圖可以看到,C3模塊和名字思路一致,在模塊中使用了3個卷積模塊(Conv+BN+SiLU),以及n個BottleNeck。
通過C3代碼可以看出,對于cv1卷積和cv2卷積的通道數(shù)是一致的,而cv3的輸入通道數(shù)是前者的2倍,因為cv3的輸入是由主梯度流分支(BottleNeck分支)依舊次梯度流分支(CBS,cv2分支)cat得到的,因此是2倍的通道數(shù),而輸出則是一樣的。
不妨我們再看一下YOLOv7中的模塊:
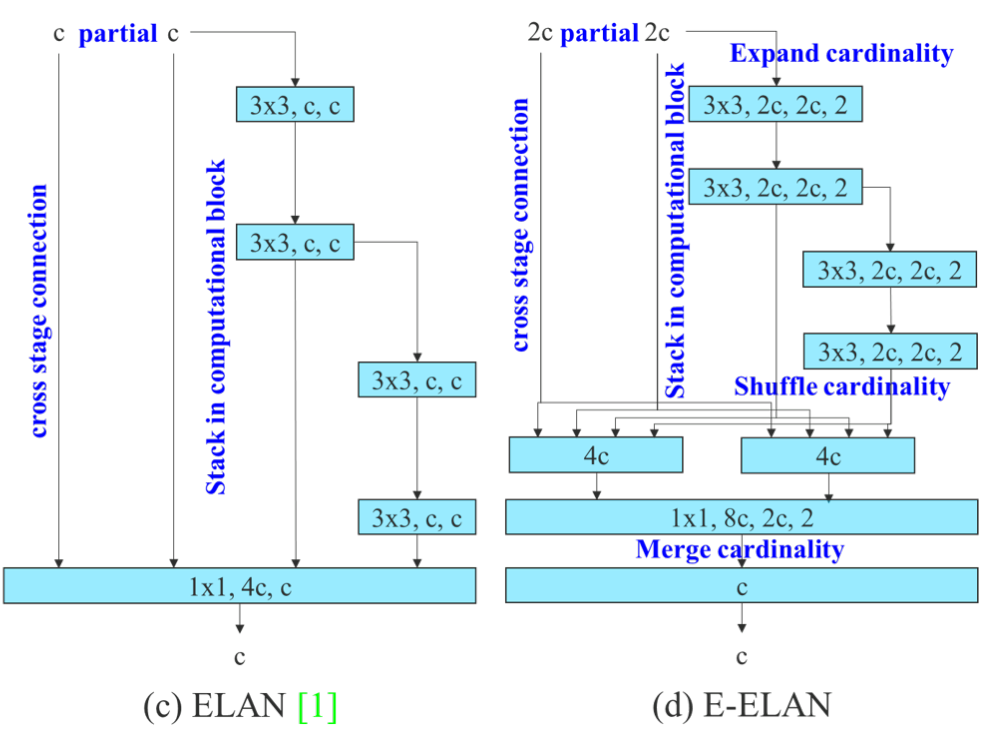
YOLOv7通過并行更多的梯度流分支,放ELAN模塊可以獲得更豐富的梯度信息,進而或者更高的精度和更合理的延遲。
C2f模塊的結(jié)構(gòu)圖如下:
我們可以很容易的看出,C2f模塊就是參考了C3模塊以及ELAN的思想進行的設(shè)計,讓YOLOv8可以在保證輕量化的同時獲得更加豐富的梯度流信息。
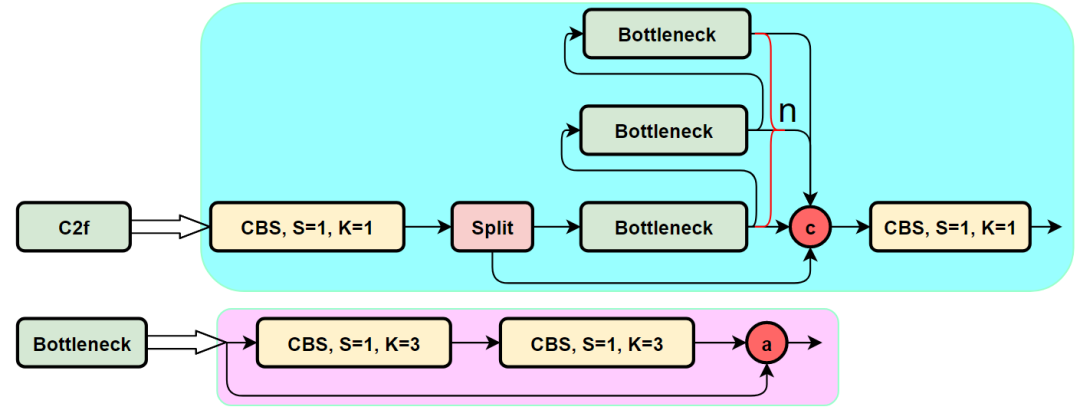
C2f模塊對應(yīng)的Pytorch實現(xiàn)如下:
classC2f(nn.Module): #CSPBottleneckwith2convolutions def__init__(self,c1,c2,n=1,shortcut=False,g=1,e=0.5):#ch_in,ch_out,number,shortcut,groups,expansion super().__init__() self.c=int(c2*e)#hiddenchannels self.cv1=Conv(c1,2*self.c,1,1) self.cv2=Conv((2+n)*self.c,c2,1)#optionalact=FReLU(c2) self.m=nn.ModuleList(Bottleneck(self.c,self.c,shortcut,g,k=((3,3),(3,3)),e=1.0)for_inrange(n)) defforward(self,x): y=list(self.cv1(x).split((self.c,self.c),1)) y.extend(m(y[-1])forminself.m) returnself.cv2(torch.cat(y,1))
SPPF改進了什么?
這里講解的文章就很多了,這里也就不具體描述了,直接給出對比圖了
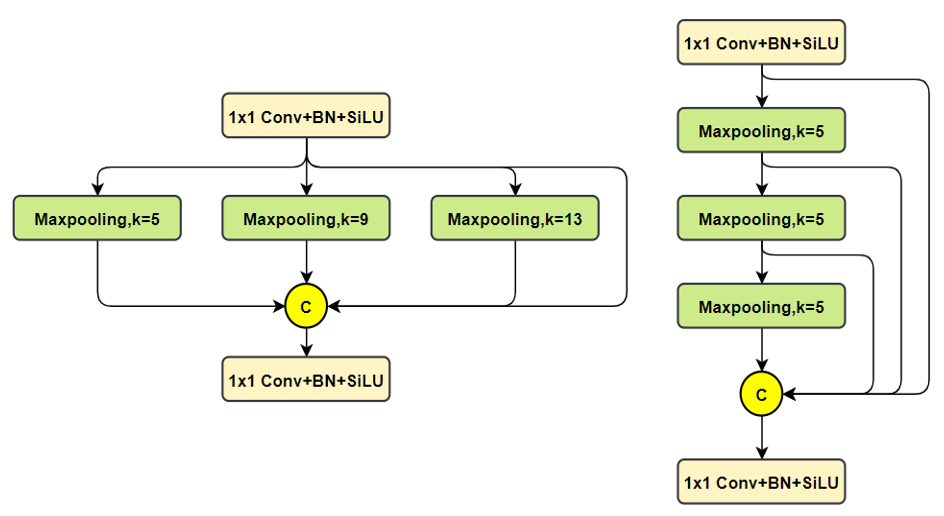
上圖中,左邊是SPP,右邊是SPPF。
PAN-FPN改進了什么?
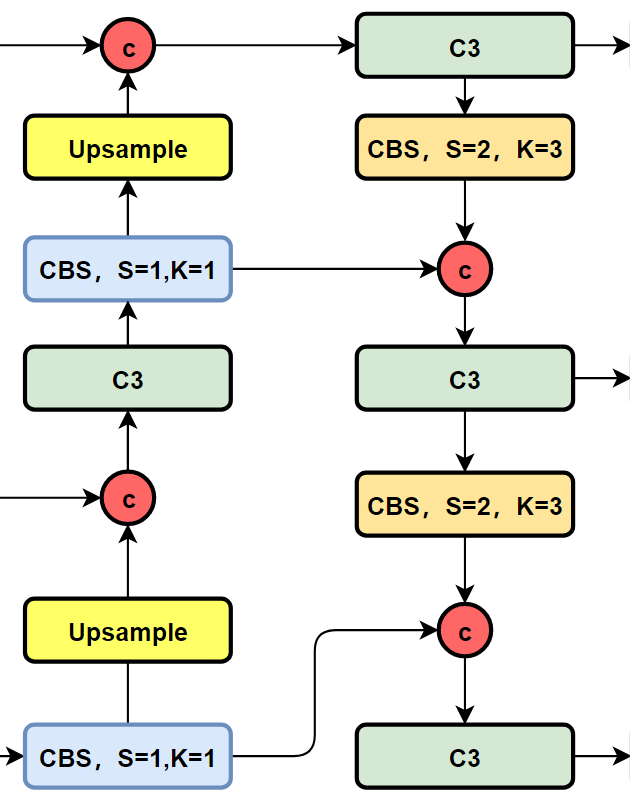
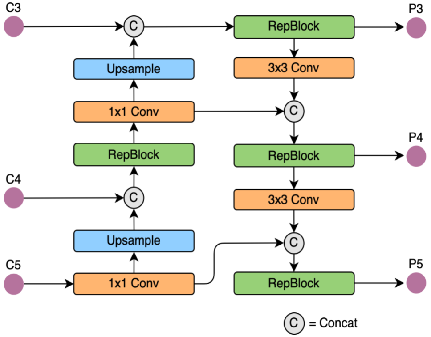
我們先看一下YOLOv5以及YOLOv6的PAN-FPN部分的結(jié)構(gòu)圖:
YOLOv5的Neck部分的結(jié)構(gòu)圖如下:
YOLOv6的Neck部分的結(jié)構(gòu)圖如下:
我們再看YOLOv8的結(jié)構(gòu)圖:
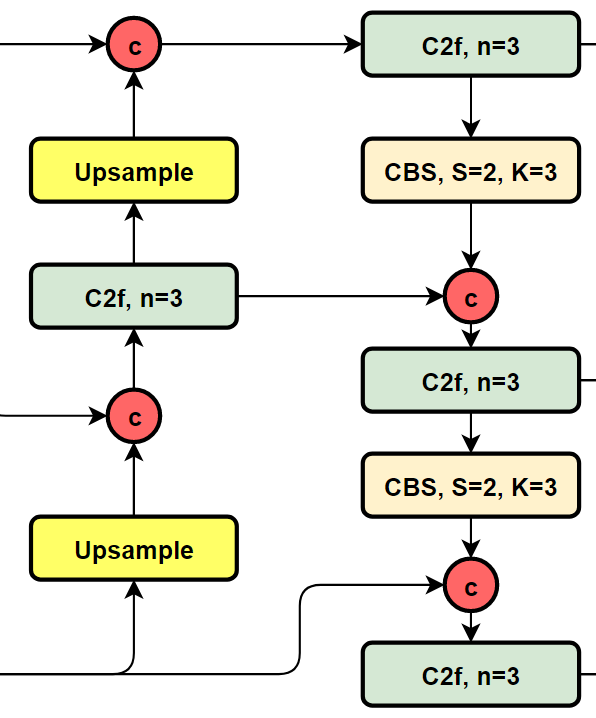
可以看到,相對于YOLOv5或者YOLOv6,YOLOv8將C3模塊以及RepBlock替換為了C2f,同時細(xì)心可以發(fā)現(xiàn),相對于YOLOv5和YOLOv6,YOLOv8選擇將上采樣之前的1×1卷積去除了,將Backbone不同階段輸出的特征直接送入了上采樣操作。
Head部分都變了什么呢?
先看一下YOLOv5本身的Head(Coupled-Head):
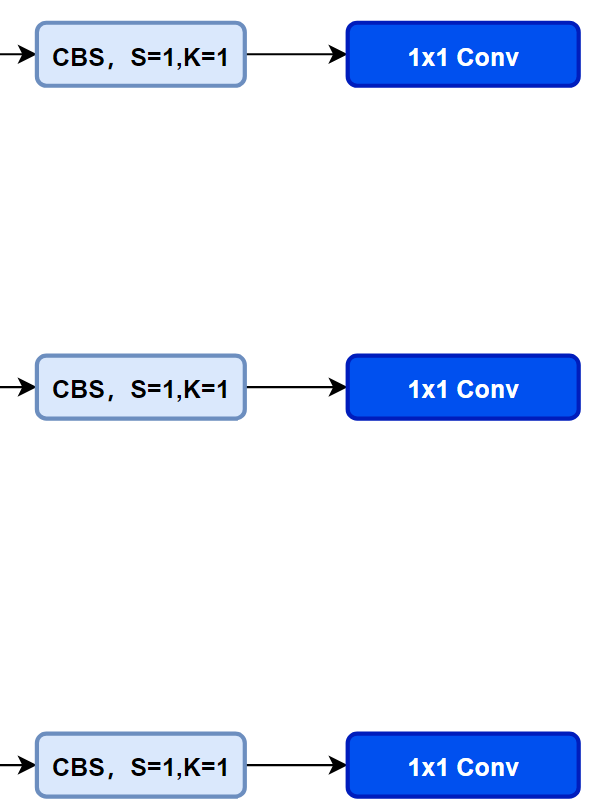
而YOLOv8則是使用了Decoupled-Head,同時由于使用了DFL 的思想,因此回歸頭的通道數(shù)也變成了4*reg_max的形式:
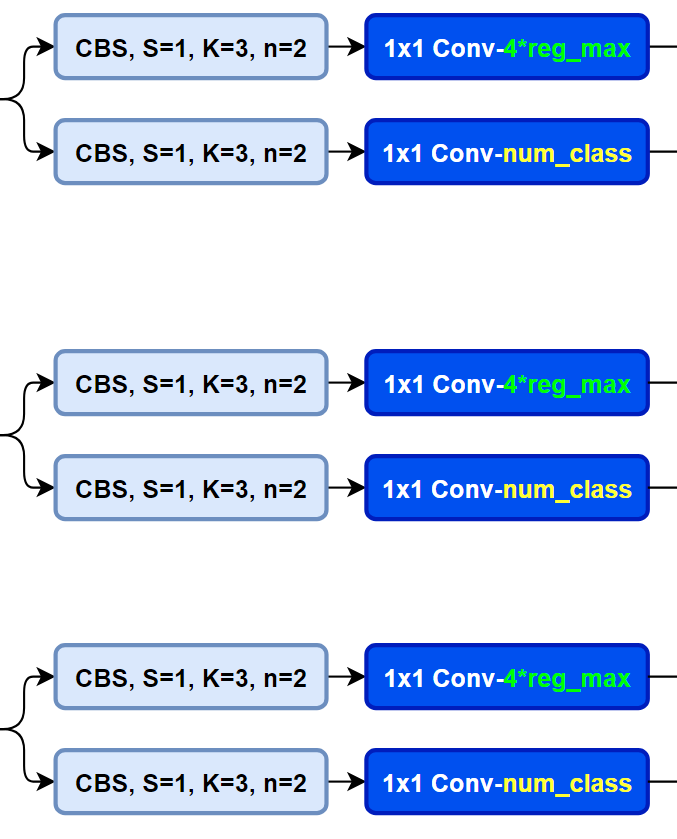
對比一下YOLOv5與YOLOv8的YAML

損失函數(shù)
對于YOLOv8,其分類損失為VFL Loss,其回歸損失為CIOU Loss+DFL的形式,這里Reg_max默認(rèn)為16。
VFL主要改進是提出了非對稱的加權(quán)操作,F(xiàn)L和QFL都是對稱的。而非對稱加權(quán)的思想來源于論文PISA,該論文指出首先正負(fù)樣本有不平衡問題,即使在正樣本中也存在不等權(quán)問題,因為mAP的計算是主正樣本。
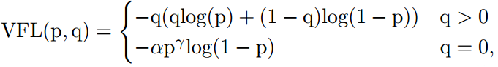
q是label,正樣本時候q為bbox和gt的IoU,負(fù)樣本時候q=0,當(dāng)為正樣本時候其實沒有采用FL,而是普通的BCE,只不過多了一個自適應(yīng)IoU加權(quán),用于突出主樣本。而為負(fù)樣本時候就是標(biāo)準(zhǔn)的FL了。可以明顯發(fā)現(xiàn)VFL比QFL更加簡單,主要特點是正負(fù)樣本非對稱加權(quán)、突出正樣本為主樣本。
針對這里的DFL(Distribution Focal Loss),其主要是將框的位置建模成一個 general distribution,讓網(wǎng)絡(luò)快速的聚焦于和目標(biāo)位置距離近的位置的分布。
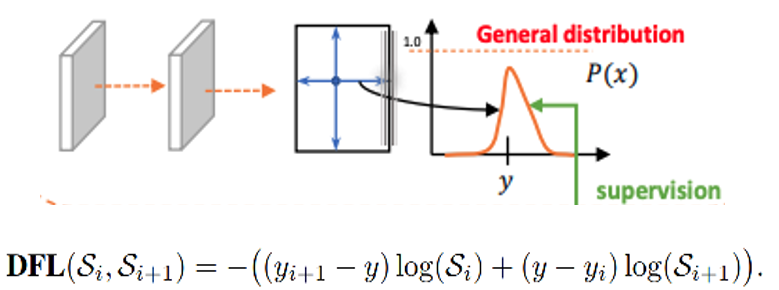
DFL 能夠讓網(wǎng)絡(luò)更快地聚焦于目標(biāo) y 附近的值,增大它們的概率;
DFL的含義是以交叉熵的形式去優(yōu)化與標(biāo)簽y最接近的一左一右2個位置的概率,從而讓網(wǎng)絡(luò)更快的聚焦到目標(biāo)位置的鄰近區(qū)域的分布;也就是說學(xué)出來的分布理論上是在真實浮點坐標(biāo)的附近,并且以線性插值的模式得到距離左右整數(shù)坐標(biāo)的權(quán)重。
樣本的匹配
標(biāo)簽分配是目標(biāo)檢測非常重要的一環(huán),在YOLOv5的早期版本中使用了MaxIOU作為標(biāo)簽分配方法。然而,在實踐中發(fā)現(xiàn)直接使用邊長比也可以達到一阿姨你的效果。而YOLOv8則是拋棄了Anchor-Base方法使用Anchor-Free方法,找到了一個替代邊長比例的匹配方法,TaskAligned。
為與NMS搭配,訓(xùn)練樣例的Anchor分配需要滿足以下兩個規(guī)則:
正常對齊的Anchor應(yīng)當(dāng)可以預(yù)測高分類得分,同時具有精確定位;
不對齊的Anchor應(yīng)當(dāng)具有低分類得分,并在NMS階段被抑制。基于上述兩個目標(biāo),TaskAligned設(shè)計了一個新的Anchor alignment metric 來在Anchor level 衡量Task-Alignment的水平。并且,Alignment metric 被集成在了 sample 分配和 loss function里來動態(tài)的優(yōu)化每個 Anchor 的預(yù)測。
Anchor alignment metric:
分類得分和 IoU表示了這兩個任務(wù)的預(yù)測效果,所以,TaskAligned使用分類得分和IoU的高階組合來衡量Task-Alignment的程度。使用下列的方式來對每個實例計算Anchor-level 的對齊程度:
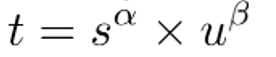
s 和 u 分別為分類得分和 IoU 值,α 和 β 為權(quán)重超參。從上邊的公式可以看出來,t 可以同時控制分類得分和IoU 的優(yōu)化來實現(xiàn) Task-Alignment,可以引導(dǎo)網(wǎng)絡(luò)動態(tài)的關(guān)注于高質(zhì)量的Anchor。
Training sample Assignment:
為提升兩個任務(wù)的對齊性,TOOD聚焦于Task-Alignment Anchor,采用一種簡單的分配規(guī)則選擇訓(xùn)練樣本:對每個實例,選擇m個具有最大t值的Anchor作為正樣本,選擇其余的Anchor作為負(fù)樣本。然后,通過損失函數(shù)(針對分類與定位的對齊而設(shè)計的損失函數(shù))進行訓(xùn)練。
審核編輯:劉清
-
PAN
+關(guān)注
關(guān)注
1文章
20瀏覽量
14381 -
ELAN
+關(guān)注
關(guān)注
0文章
3瀏覽量
5206 -
BEC
+關(guān)注
關(guān)注
0文章
7瀏覽量
5400
原文標(biāo)題:YOLO系列又雙叒更新!詳細(xì)解讀YOLOv8的改進模塊
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
使用YOLOv8做目標(biāo)檢測和實例分割的演示
YOLOv8自定義數(shù)據(jù)集訓(xùn)練到模型部署推理簡析
在AI愛克斯開發(fā)板上用OpenVINO?加速YOLOv8目標(biāo)檢測模型

YOLOv8版本升級支持小目標(biāo)檢測與高分辨率圖像輸入
AI愛克斯開發(fā)板上使用OpenVINO加速YOLOv8目標(biāo)檢測模型

一文徹底搞懂YOLOv8【網(wǎng)絡(luò)結(jié)構(gòu)+代碼+實操】
教你如何用兩行代碼搞定YOLOv8各種模型推理

目標(biāo)檢測算法再升級!YOLOv8保姆級教程一鍵體驗
解鎖YOLOv8修改+注意力模塊訓(xùn)練與部署流程
如何修改YOLOv8的源碼
YOLOv8實現(xiàn)任意目錄下命令行訓(xùn)練
基于YOLOv8的自定義醫(yī)學(xué)圖像分割

基于OpenCV DNN實現(xiàn)YOLOv8的模型部署與推理演示
RV1126 yolov8訓(xùn)練部署教程





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論