") 分布式實(shí)時(shí)日志分析解決方案ELK部署架構(gòu)
分布式實(shí)時(shí)日志分析解決方案ELK部署架構(gòu)
一、概述
ELK 已經(jīng)成為目前最流行的集中式日志解決方案,它主要是由 Beats、Logstash、Elasticsearch、Kibana 等組件組成,來共同完成實(shí)時(shí)日志的收集,存儲(chǔ),展示等一站式的解決方案。本文將會(huì)介紹 ELK 常見的架構(gòu)以及相關(guān)問題解決。
Filebeat:Filebeat 是一款輕量級(jí),占用服務(wù)資源非常少的數(shù)據(jù)收集引擎,它是 ELK 家族的新成員,可以代替 Logstash 作為在應(yīng)用服務(wù)器端的日志收集引擎,支持將收集到的數(shù)據(jù)輸出到 Kafka,Redis 等隊(duì)列。
Logstash:數(shù)據(jù)收集引擎,相較于 Filebeat 比較重量級(jí),但它集成了大量的插件,支持豐富的數(shù)據(jù)源收集,對(duì)收集的數(shù)據(jù)可以過濾,分析,格式化日志格式。
Elasticsearch:分布式數(shù)據(jù)搜索引擎,基于 Apache Lucene 實(shí)現(xiàn),可集群,提供數(shù)據(jù)的集中式存儲(chǔ),分析,以及強(qiáng)大的數(shù)據(jù)搜索和聚合功能。
Kibana:數(shù)據(jù)的可視化平臺(tái),通過該 web 平臺(tái)可以實(shí)時(shí)的查看 Elasticsearch 中的相關(guān)數(shù)據(jù),并提供了豐富的圖表統(tǒng)計(jì)功能。
二、ELK 常見部署架構(gòu)
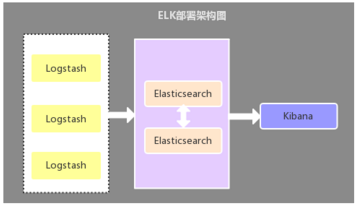
2.1、Logstash 作為日志收集器
這種架構(gòu)是比較原始的部署架構(gòu),在各應(yīng)用服務(wù)器端分別部署一個(gè) Logstash 組件,作為日志收集器,然后將 Logstash 收集到的數(shù)據(jù)過濾、分析、格式化處理后發(fā)送至 Elasticsearch 存儲(chǔ),最后使用 Kibana 進(jìn)行可視化展示,這種架構(gòu)不足的是:Logstash 比較耗服務(wù)器資源,所以會(huì)增加應(yīng)用服務(wù)器端的負(fù)載壓力。
2.2、Filebeat 作為日志收集器
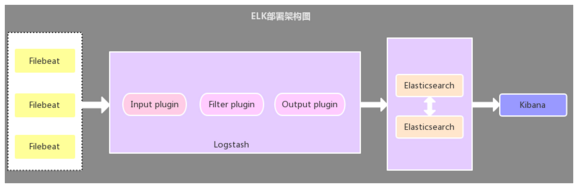
該架構(gòu)與第一種架構(gòu)唯一不同的是:應(yīng)用端日志收集器換成了 Filebeat,F(xiàn)ilebeat 輕量,占用服務(wù)器資源少,所以使用 Filebeat 作為應(yīng)用服務(wù)器端的日志收集器,一般 Filebeat 會(huì)配合 Logstash 一起使用,這種部署方式也是目前最常用的架構(gòu)。
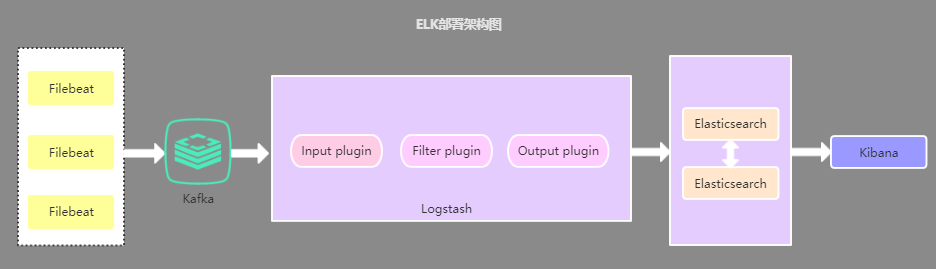
2.3、引入緩存隊(duì)列的部署架構(gòu)
該架構(gòu)在第二種架構(gòu)的基礎(chǔ)上引入了 Kafka 消息隊(duì)列(還可以是其他消息隊(duì)列),將 Filebeat 收集到的數(shù)據(jù)發(fā)送至 Kafka,然后在通過 Logstasth 讀取 Kafka 中的數(shù)據(jù),這種架構(gòu)主要是解決大數(shù)據(jù)量下的日志收集方案,使用緩存隊(duì)列主要是解決數(shù)據(jù)安全與均衡 Logstash 與 Elasticsearch 負(fù)載壓力。
2.4、以上三種架構(gòu)的總結(jié)
第一種部署架構(gòu)由于資源占用問題,現(xiàn)已很少使用,目前使用最多的是第二種部署架構(gòu),至于第三種部署架構(gòu)個(gè)人覺得沒有必要引入消息隊(duì)列,除非有其他需求,因?yàn)樵跀?shù)據(jù)量較大的情況下,F(xiàn)ilebeat 使用壓力敏感協(xié)議向 Logstash 或 Elasticsearch 發(fā)送數(shù)據(jù)。如果 Logstash 正在繁忙地處理數(shù)據(jù),它會(huì)告知 Filebeat 減慢讀取速度。擁塞解決后,F(xiàn)ilebeat 將恢復(fù)初始速度并繼續(xù)發(fā)送數(shù)據(jù)。
三、問題及解決方案
問題:如何實(shí)現(xiàn)日志的多行合并功能?
系統(tǒng)應(yīng)用中的日志一般都是以特定格式進(jìn)行打印的,屬于同一條日志的數(shù)據(jù)可能分多行進(jìn)行打印,那么在使用 ELK 收集日志的時(shí)候就需要將屬于同一條日志的多行數(shù)據(jù)進(jìn)行合并。
解決方案:使用 Filebeat 或 Logstash 中的 multiline 多行合并插件來實(shí)現(xiàn)
在使用 multiline 多行合并插件的時(shí)候需要注意,不同的 ELK 部署架構(gòu)可能 multiline 的使用方式也不同,如果是本文的第一種部署架構(gòu),那么 multiline 需要在 Logstash 中配置使用,如果是第二種部署架構(gòu),那么 multiline 需要在 Filebeat 中配置使用,無需再在 Logstash 中配置 multiline。
1、multiline 在 Filebeat 中的配置方式:
filebeat.prospectors: - paths: -/home/project/elk/logs/test.log input_type:log multiline: pattern:'^[' negate:true match:after output: logstash: hosts:["localhost:5044"]
pattern:正則表達(dá)式
negate:默認(rèn)為 false,表示匹配 pattern 的行合并到上一行;true 表示不匹配 pattern 的行合并到上一行
match:after 表示合并到上一行的末尾,before 表示合并到上一行的行首
如:
pattern:'[' negate:true match:after
該配置表示將不匹配 pattern 模式的行合并到上一行的末尾
2、multiline 在 Logstash 中的配置方式
input{
beats{
port=>5044
}
}
filter{
multiline{
pattern=>"%{LOGLEVEL}s*]"
negate=>true
what=>"previous"
}
}
output{
elasticsearch{
hosts=>"localhost:9200"
}
}
(1)Logstash 中配置的 what 屬性值為 previous,相當(dāng)于 Filebeat 中的 after,Logstash 中配置的 what 屬性值為 next,相當(dāng)于 Filebeat 中的 before。(2)pattern => "%{LOGLEVEL}s*]" 中的 LOGLEVEL 是 Logstash 預(yù)制的正則匹配模式,預(yù)制的還有好多常用的正則匹配模式,詳細(xì)請(qǐng)看:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
問題:如何將 Kibana 中顯示日志的時(shí)間字段替換為日志信息中的時(shí)間?
默認(rèn)情況下,我們?cè)?Kibana 中查看的時(shí)間字段與日志信息中的時(shí)間不一致,因?yàn)槟J(rèn)的時(shí)間字段值是日志收集時(shí)的當(dāng)前時(shí)間,所以需要將該字段的時(shí)間替換為日志信息中的時(shí)間。
解決方案:使用 grok 分詞插件與 date 時(shí)間格式化插件來實(shí)現(xiàn)
在 Logstash 的配置文件的過濾器中配置 grok 分詞插件與 date 時(shí)間格式化插件,如:
input{
beats{
port=>5044
}
}
filter{
multiline{
pattern=>"%{LOGLEVEL}s*][%{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME}]"
negate=>true
what=>"previous"
}
grok{
match=>["message","(?%{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME})"]
}
date{
match=>["customer_time","yyyyMMddHHss,SSS"]//格式化時(shí)間
target=>"@timestamp"http://替換默認(rèn)的時(shí)間字段
}
}
output{
elasticsearch{
hosts=>"localhost:9200"
}
}
如,要匹配的日志格式為:“[DEBUG][20170811 1031,359][DefaultBeanDefinitionDocumentReader:106] Loading bean definitions”,解析出該日志的時(shí)間字段的方式有:
通過引入寫好的表達(dá)式文件,如表達(dá)式文件為 customer_patterns,內(nèi)容為:CUSTOMER_TIME %{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME} 注:內(nèi)容格式為:[自定義表達(dá)式名稱] [正則表達(dá)式] 然后 logstash 中就可以這樣引用:
filter{
grok{
patterns_dir=>["./customer-patterms/mypatterns"]//引用表達(dá)式文件路徑
match=>["message","%{CUSTOMER_TIME:customer_time}"]//使用自定義的grok表達(dá)式
}
}
以配置項(xiàng)的方式,規(guī)則為:(?< 自定義表達(dá)式名稱> 正則匹配規(guī)則),如:
filter{
grok{
match=>["message","(?%{YEAR}%{MONTHNUM}%{MONTHDAY}s+%{TIME})"]
}
}
問題:如何在 Kibana 中通過選擇不同的系統(tǒng)日志模塊來查看數(shù)據(jù)
一般在 Kibana 中顯示的日志數(shù)據(jù)混合了來自不同系統(tǒng)模塊的數(shù)據(jù),那么如何來選擇或者過濾只查看指定的系統(tǒng)模塊的日志數(shù)據(jù)?
解決方案:新增標(biāo)識(shí)不同系統(tǒng)模塊的字段或根據(jù)不同系統(tǒng)模塊建 ES 索引
1、新增標(biāo)識(shí)不同系統(tǒng)模塊的字段,然后在 Kibana 中可以根據(jù)該字段來過濾查詢不同模塊的數(shù)據(jù) 這里以第二種部署架構(gòu)講解,在 Filebeat 中的配置內(nèi)容為:
filebeat.prospectors: - paths: -/home/project/elk/logs/account.log input_type:log multiline: pattern:'^[' negate:true match:after fields://新增log_from字段 log_from:account - paths: -/home/project/elk/logs/customer.log input_type:log multiline: pattern:'^[' negate:true match:after fields: log_from:customer output: logstash: hosts:["localhost:5044"]
通過新增:log_from 字段來標(biāo)識(shí)不同的系統(tǒng)模塊日志
2、根據(jù)不同的系統(tǒng)模塊配置對(duì)應(yīng)的 ES 索引,然后在 Kibana 中創(chuàng)建對(duì)應(yīng)的索引模式匹配,即可在頁(yè)面通過索引模式下拉框選擇不同的系統(tǒng)模塊數(shù)據(jù)。這里以第二種部署架構(gòu)講解,分為兩步:① 在 Filebeat 中的配置內(nèi)容為:
filebeat.prospectors: - paths: -/home/project/elk/logs/account.log input_type:log multiline: pattern:'^[' negate:true match:after document_type:account - paths: -/home/project/elk/logs/customer.log input_type:log multiline: pattern:'^[' negate:true match:after document_type:customer output: logstash: hosts:["localhost:5044"]
通過 document_type 來標(biāo)識(shí)不同系統(tǒng)模塊
② 修改 Logstash 中 output 的配置內(nèi)容為:
output{
elasticsearch{
hosts=>"localhost:9200"
index=>"%{type}"
}
}
在 output 中增加 index 屬性,%{type} 表示按不同的 document_type 值建 ES 索引
四、總結(jié)
本文主要介紹了 ELK 實(shí)時(shí)日志分析的三種部署架構(gòu),以及不同架構(gòu)所能解決的問題,這三種架構(gòu)中第二種部署方式是時(shí)下最流行也是最常用的部署方式,最后介紹了 ELK 作在日志分析中的一些問題與解決方案,說在最后,ELK 不僅僅可以用來作為分布式日志數(shù)據(jù)集中式查詢和管理,還可以用來作為項(xiàng)目應(yīng)用以及服務(wù)器資源監(jiān)控等場(chǎng)景,更多內(nèi)容請(qǐng)看官網(wǎng)。
-
存儲(chǔ)
+關(guān)注
關(guān)注
13文章
4507瀏覽量
87112 -
服務(wù)器
+關(guān)注
關(guān)注
13文章
9717瀏覽量
87370 -
數(shù)據(jù)源
+關(guān)注
關(guān)注
1文章
65瀏覽量
9872 -
日志
+關(guān)注
關(guān)注
0文章
143瀏覽量
10831 -
收集器
+關(guān)注
關(guān)注
0文章
30瀏覽量
3310
原文標(biāo)題:分布式實(shí)時(shí)日志分析解決方案 ELK 部署架構(gòu)
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
使用分布式I/O進(jìn)行實(shí)時(shí)部署系統(tǒng)的設(shè)計(jì)
開放分布式追蹤(OpenTracing)入門與 Jaeger 實(shí)現(xiàn)
微服務(wù)架構(gòu)下分布式事務(wù)解決方案 —— 阿里GTS
一行代碼,保障分布式事務(wù)一致性—GTS:微服務(wù)架構(gòu)下分布式事務(wù)解決方案
Qorvo分布式Wi-Fi網(wǎng)格解決方案
分布式KVM坐席拼控系統(tǒng)解決方案
HDC技術(shù)分論壇:分布式調(diào)試、調(diào)優(yōu)能力解決方案
HDC2021技術(shù)分論壇:分布式調(diào)試、調(diào)優(yōu)能力解決方案
基于Windows平臺(tái)的分布式實(shí)時(shí)仿真系統(tǒng)

基于DOCKER容器的ELK日志收集系統(tǒng)分析
基于分布式仿真系統(tǒng)的實(shí)時(shí)通訊架構(gòu)
什么是分布式系統(tǒng) 分布式架構(gòu)有哪些
分布式實(shí)時(shí)日志:ELK的部署架構(gòu)方案

如何在CentOS系統(tǒng)中部署ELK日志分析系統(tǒng)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論