 內存帶寬瓶頸如何破?
內存帶寬瓶頸如何破?
內存帶寬是當下阻礙某些應用程序性能的亟需解決的問題,現在你可以通過地選擇芯片來調整 CPU 內核與內存帶寬的比率,并且您可以依靠芯片制造商和系統構建商進一步推動它。
如果 CPU 在內存帶寬和某些情況下的內存容量方面不受限制,那么考慮一下 HPC 和 AI 計算會是什么樣子是很有趣的。或者更準確地說,如果內存相對于計算而言不是那么昂貴。或許,我們可以對前者做點什么,我們會臉色發青,也許會死于等待對后者發生的事情,正如我們上周簡要談到的那樣。
有時候,你所能做的就是做一個止血帶,即使你不能立即永久性地解決手頭的問題,也要試著繼續運動。或者腳,或者傷口所在的地方。這讓我們思考,現在的服務器購買者如何通過服務器CPU和系統制造商的一些適度調整,至少可以使每個核心的內存帶寬更加平衡。
正如去年的圖靈獎得主、行業名人Jack Dongarra在主題演講中恰當地指出的那樣,幾十年來,情況一年比一年糟糕。
我們考慮這個問題已經有一段時間了,早在 2019 年 8 月,IBM 就對 Power10 處理器進行了預覽,并且預期(但從未交付過)高帶寬 Power9'——這是 Power9 “prime”,而不是打字錯誤——系統藍色巨人在 2019 年 10 月與我們談到了我們對具有高內存帶寬的系統的興趣。(我們稱它為 Power E955,這樣它就有了一個名字,盡管它從未推出過。)IBM 展示了它的 OpenCAPI 內存接口 (OMI) 以及它隨 Power10 機器一起提供的內存,但這張圖表概括了 IBM 的內容相信它可以在各種技術的電源芯片插座上做:
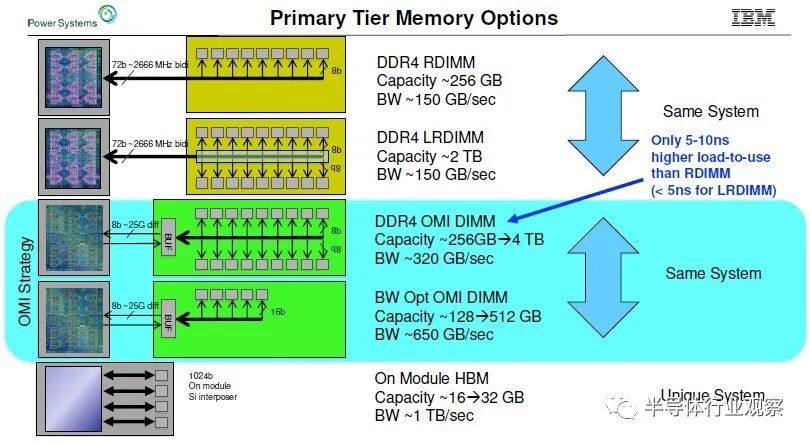
IBM 的 OMI 差分 DDR 內存,它使用串行接口和 SerDes,本質上與處理器上用于 NUMA、NVLink 和 OpenCAPI 端口的“Bluelink”信號相同,與普通的并行 DDR4 接口有很大不同,具體DDR 協議,無論是 DDR4 還是 DDR5,都位于存儲卡上的緩沖芯片上,而從存儲卡到 CPU 的接口是一種更通用的 OMI 協議。
這種早在 2019 年就在開發中的 OMI 內存提供了大約 320 GB/秒的每個插槽和從 256 GB 到 4 TB 的每個插槽的容量。通過帶寬優化版本,將內存模塊數量減少四分之一,并為每個插槽提供 128 GB 至 512 GB 的 DDR4 容量,IBM 可以將 Power9 芯片上的內存帶寬提高到 650 GB/秒,并且借助預計在 2021 年推出的 Power10 服務器,它可以使用時鐘速度更快的 DDR5 內存將速度提高到 800 GB/秒。
同時,對于預計在 2020 年交付的 Power9 系統,IBM 估計如果它使用 HBM2 堆疊內存,它可以提供 16 GB 到 32 GB 的容量,并提供大約 1 TB/秒的每個插槽帶寬。這是每個插槽的大量內存帶寬,但內存容量并不是很大。
無論出于何種原因——我們認為無論它們是什么,它們都不是好產品,但這可能與藍色巨人與當時的代工合作伙伴 Globalfoundries 的技術和法律困難有關——Power9 系統,很可能是四路機器每個插座中都帶有雙芯片模塊,從未面世。
但早在 2022 年 7 月,“帶寬野獸”的想法就被重新命名為 Power E1050,作為 Power10 中端系統陣容的一部分。
當“Cirrus”Power10 處理器規格于 2020 年 8 月公布時,IBM 表示該芯片每個內核的峰值內存帶寬為 256 GB/秒,每個內核的持續內存帶寬為 120 GB/秒。Power10 芯片上有 16 個內核,但為了在 IBM 的新代工合作伙伴三星的 7 納米工藝上獲得更好的產量,最多只有 15 個內核處于活動狀態。關于去年 7 月推出的入門級和中端 Power10 機器、4、8、10 和 12 核在 SKU 堆棧中可用,而 15 核變體僅在可擴展到 16 插槽的高端“Denali”Power E1080 系統中可用。目前尚不清楚這些峰值和持續內存帶寬數據是否適用于 DDR5 內存,但我們懷疑是這樣。IBM 確實交付了使用基于 DDR4 內存的 OMI 內存的 Power E1050(和其他 Power10 機器),并在其演示中表示配備 DDR5 內存的 Power10 的內存流性能將是 DDR4 內存的 2 倍。
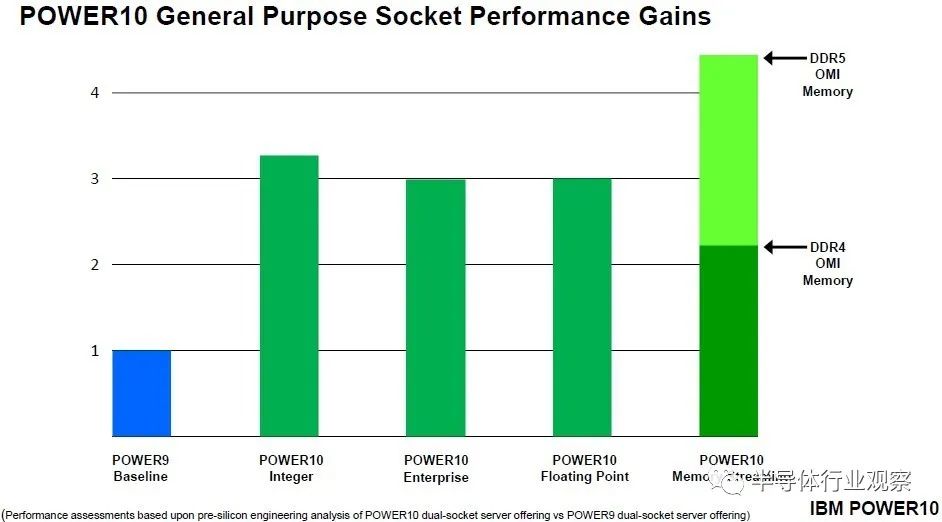
以上比較針對的是單芯片 Power10 模塊。對于雙芯片模塊,將它們加倍,然后針對保持在與單芯片模塊相同的熱包絡內所需的降檔時鐘速度進行調整。
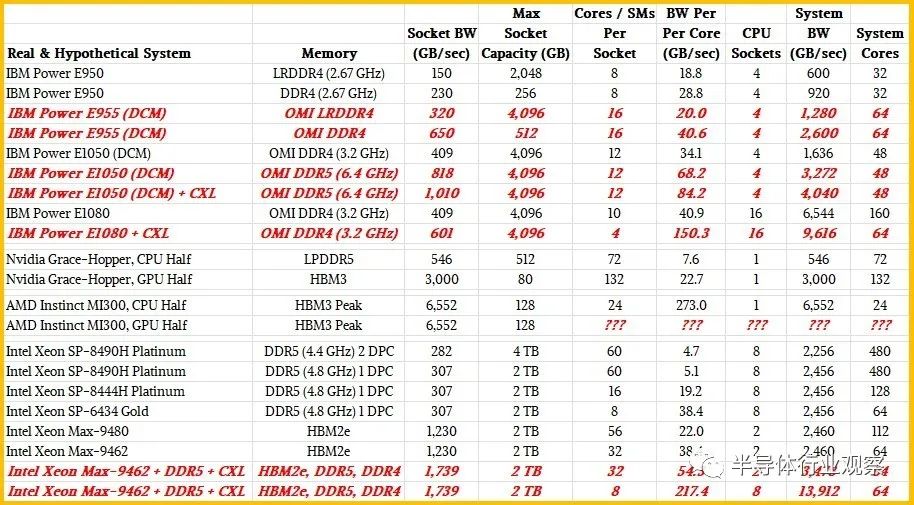
采用 Power E1050 機器,服務器最多有四個 Power10 DCM,總共有 96 個核心。這八個小芯片共有八個 OMI 內存控制器,支持多達 64 個差分 DIMM,DDR4 內存運行頻率為 3.2 GHz,并在內核之間提供 1.6 TB/秒的總帶寬。也就是說,在系統中 96 個核心的峰值時,每個 Power10 核心的內存帶寬為 17 GB/秒。
首先,讓我們回到核心技術。Power E1050的臃腫配置使用了12核Power10芯片,但有一款48核的改型只使用了6核芯片。(是的,Power10內核的成品率只有37.5%。)這使得每核帶寬翻了一番,達到34 GB/秒。如果你改用運行在6.4 GHz的DDR5內存,這是昂貴的,而且價格并不合理,那么你可以獲得每核高達68 GB/秒的內存帶寬。
現在,理論上,如果CXL內存擴展器可用,您可以進一步推動這個真正的Power E1050,您可以在CXL內存上的每個插槽消耗PCI-Express 5.0帶寬的56個通道中的48個,添加6個x8 CXL內存擴展器,每個擴展器以32 GB/秒的速度產生另外192 GB/秒的內存帶寬(當然,還有一些附加延遲)。這使得你的總帶寬達到1.8 TB/秒,每核帶寬達到38 GB/秒。如果IBM使每個Power10芯片上的內核數更小,那么每個內核的內存帶寬就可以調高。如果每個芯片有4個內核,每個系統有32個內核,那么每個內核的內存帶寬最高可達57.1 GB/秒。轉到DDR5內存+ CXL內存,每個核心可以達到84 GB/秒。
01進入混合計算引擎
請注意,沒有人說這很便宜。但對于某些工作負載,這可能是一個比將代碼移植到GPU或等待CPU-GPU混合計算引擎(AMD的Instinct MI300A, Nvidia的Grace-Hopper, Intel的Falcon Shores)上市更好的答案。雖然這些處理器每個核心都有很高的內存帶寬,但內存容量將受到限制,因此比IBM Power10和英特爾“Sapphire Rapids”Max系列CPU(混合HBM 2e/DDR5內存)的性能要有限得多。
英偉達Grace芯片擁有72個核心和16組LPDDR5內存,總容量為512 GB,每個插槽的內存為546 GB/秒。計算出來每個核的內存帶寬為7.6 GB/秒。Hopper GPU擁有132個流多處理器(相當于CPU的核心),其HBM3堆疊內存的帶寬最高可達3000 GB/秒。(在H100加速器上,有5個堆棧產出80gb。)計算出來,每個GPU“核心”的帶寬為22.7 GB/秒,這只是給你一個參考框架。如果您將Grace上的所有LPDDR5內存視為一種類似cxl的內存,則可以將CPU-GPU復合物的內存容量提高到總共592 GB,并將聚合內存帶寬提高到3,536 GB/秒。根據您的意愿在該綜合體中分配核心和SMs。您可以將GPU視為CPU核心的非常昂貴的快速內存加速器,計算出每個Grace核心的內存帶寬為49.3 GB/秒,每個Hopper SM的內存帶寬為26.9 GB/秒。
上面提到的Power10系統就在這個范圍內,沒有太多的工程方法。
對于AMD Instinct MI300A,我們知道它有128 GB的HBM3堆疊內存,分布在8個組、6個GPU和2個12核Epyc 9004 CPU芯片上,但我們不知道帶寬,也不知道MI300A包上的6個GPU芯片集合上的短信數量。我們可以對帶寬做一個有根據的猜測。HBM3以每引腳6.4 Gb/秒的速度運行信令,最多可達16個通道。根據堆疊的DRAM芯片數量(從4個到16個)和它們的容量(每個堆棧從4 GB到64 GB),您可以獲得不同的容量和帶寬。
使用16 Gb DRAM,最初的HBM3堆棧預計每個堆棧提供819 Gb /秒的帶寬。看起來AMD可能會使用8個16gb芯片堆棧,每個堆棧有8個芯片,這將提供128 Gb的容量,并將產生6552 Gb /秒的總帶寬,以去年4月HBM3規范宣布時的預期速度。我們認為MI300A封裝上的Epyc 9004芯片有16個內核,但其中只有12個用于提高產量和可能的時鐘速度,當這些Epyc內核達到HBM3內存時,每個內核的內存帶寬將達到驚人的273 GB/秒。
很難說這六個GPU芯片上有多少短信,但與之前的AMD和Nvidia GPU加速器相比,每條短信的帶寬可能會非常高。但是,同樣,每個計算引擎的總內存為128 GB并不是很大的容量。
而且,為了抑制我們的熱情,由于熱的原因,AMD可能不得不削減DRAM堆棧和/或HBM3內存速度,因此可能達不到我們預期的帶寬數字。即使是每個CPU核心帶寬的一半,這也會令人印象深刻。同樣,對于只使用cpu的應用程序,GPU是一個非常昂貴的附加組件。
任何CXL內存可能掛在這個處理器上以增加額外的容量,這將在這方面有所幫助,但不會對每個核心或SM的帶寬增加太多。
我們對未來的英特爾獵鷹海岸CPU-GPU混合處理器的了解還不夠多,根本無法進行任何計算。
02在CPU和NUMA拯救HBM嗎?
這讓我們想到了英特爾的藍寶石Rapids與HBM2e內存,它也有一種模式,同時支持HBM2e和DDR5內存。我們之所以對Sapphire Rapids感興趣,不僅是因為它在某些變體中支持HBM2e堆疊內存,還因為它在其他變體中也具有八路NUMA可伸縮性。
我們認為可以允許創建一個八路,hbm功能的系統,同時使用DDR5和CXL主存。讓我們從頭開始,從普通的Sapphire Rapids Xeon SP CPU開始。
據我們所能估計,Sapphire Rapids Xeon SP上的8個DDR5內存通道可以在一個插座上提供略高于307 GB/秒的內存帶寬。如果每個通道有一個DIMM,運行頻率為4.8 GHz,則最大容量為2tb。使用每個通道兩個內存,每個插槽的容量可以翻倍,達到4 TB,但運行速度較慢的4.4 GHz,每個插槽只能產生282 GB/秒的內存帶寬。(后一種情況是內存容量大,而不是內存帶寬大。)在Xeon SP-8490H上,每個通道有一個內存,60個內核運行在1.9 GHz,計算出來每個內核的帶寬只有5.1 GB/秒。如果你使用Xeon SP-8444H處理器,它只有16個核心,但運行在更高的2.9 GHz,所以你可以恢復掉核時失去的一些性能,每個核心的帶寬為19.2 GB/秒。
好吧,如果你想提高插座上每個核心的內存帶寬,你可以切換到Xeon SP-6434,它有8個內核,運行頻率為3.7 GHz。在4.8 GHz DDR5速度下,每核帶寬將增加一倍,達到38.4 GB/秒。這個處理器上活動的UPI鏈路少了一個,因此雙插座服務器上的耦合效率會低一些,而且延遲和帶寬也會低一些。這與使用3.2 GHz DDR4內存的六核Power10芯片大致相同,類似于Grace Arm服務器CPU上的每個核從其本地LPDDR5內存中看到的情況。
現在,讓我們談談藍寶石急流HBM變體。頂部的bin Max系列CPU有56個核,四個HBM2e堆棧有64gb的容量和1230gb /秒的總帶寬。計算出來,每個核的內存帶寬為22 GB/秒。低倉部分有32個核,相同的1230 GB/秒內存,或每個核38 GB/秒。如果在插座上添加DDR5內存,則可以再增加307 GB/秒,如果添加CXL內存擴展器,則可以再增加192 GB/秒。所以現在32個核心的內存總量達到了1729 GB/秒,也就是54 GB/秒。
現在,讓我們將其發揮到極致,利用NUMA互連將8個Sapphire Rapids HBM插座(英特爾不允許這樣做)連接在一起,并將每個插座在4 GHz下運行的內核數降至8個內核。這將產生64個運行頻率為4 GHz的內核,比藍寶石Rapids 60核至強SP-8490H更具魅力。但是現在,將HBM、DDR5和CXL內存全部添加進來后,這8個插槽的內存帶寬總計為13,912 GB/秒,每個核的總帶寬為217.4 GB/秒。
我們確信,這不會是一個便宜的盒子。但話說回來,Power E1050也不是。
如果IBM將Power E1080的核心撥下來,并添加CXL擴展器,它可以通過16個插槽獲得一些東西,這將是連接到這16個插槽的OMI內存的6544 GB/秒,再加上PCI-Express 5.0總線上的6個CXL內存模塊的3,072 GB/秒,總共9,616 GB/秒。你想要多少核?每個Power10 SCM有4個內核,即64個內核,計算出來每個內核的主存帶寬為150 GB/秒。
關鍵是,有一種方法可以構建專注于每個核心更好的內存帶寬的服務器節點,因此適合加速某些類型的HPC和分析工作負載,甚至可能是部分AI訓練工作負載。你的計算能力會比內存容量或內存帶寬的限制更大,你必須非常小心,不要因為沒有足夠的內核從內存中提取數據和向內存中插入數據而使昂貴的內存負擔過重。
順便說一下,我們不太確定這種帶寬野獸方法如何加速人工智能訓練——也許只在預訓練的模型上進行修剪和調整。我們有一種預感,即使是GPU在GPU核心時延和附加的HBM2e和HBM3堆疊內存帶寬之間也存在不平衡,因此它們無法在接近峰值計算效率的任何地方運行。
我們充分認識到,這一切都不便宜。但GPU加速的機器也不是。但是,對于某些工作負載來說,更好地平衡計算、內存帶寬和內存容量可能比將內存分割成碎片并將數據集分散到幾十個CPU上更好。不可否認,您確實需要以不同的方式加速這些工作負載——并跨內存層次結構對它們進行編程——以突破極限。
這就是思想實驗的作用。
審核編輯:劉清
-
處理器
+關注
關注
68文章
19657瀏覽量
232456 -
IBM
+關注
關注
3文章
1791瀏覽量
75261 -
DDR
+關注
關注
11文章
718瀏覽量
66096 -
HPC
+關注
關注
0文章
331瀏覽量
24096 -
電源芯片
+關注
關注
43文章
1138瀏覽量
77874
原文標題:內存帶寬瓶頸如何破?IBM的方法!
文章出處:【微信號:算力基建,微信公眾號:算力基建】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
內存擴展CXL加速發展,繁榮AI存儲

HBM新技術,橫空出世:引領內存芯片創新的新篇章


使用 Memtester 對華為云 X 實例進行內存性能測試

南亞科技與補丁科技攜手開發定制超高帶寬內存
固定帶寬與動態帶寬的區別
HBM與GDDR內存技術全解析

HBM4需求激增,英偉達與SK海力士攜手加速高帶寬內存技術革新
SK海力士第三季度業績創歷史新高,高帶寬內存與HBM需求旺盛
前端總線與內存頻率怎么配
正常音量信號輸入tas5548后破音的原因?怎么解決?
三星電子突破瓶頸,HBM3e內存芯片獲英偉達質量認證
成都匯陽投資關于跨越帶寬增長極限,HBM 賦能AI新紀元
集成32GB HBM2e內存,AMD Alveo V80加速卡助力傳感器處理、存儲壓縮等






 工商網監
工商網監
評論