 開源模型OpenCLIP達成ImageNet里程碑成就
開源模型OpenCLIP達成ImageNet里程碑成就
【導讀】開源模型OpenCLIP達成ImageNet里程碑成就!
? ? 雖然ImageNet早已完成歷史使命,但其在計算機視覺領域仍然是一個關鍵的數據集。 2016年,在ImageNet上訓練后的分類模型,sota準確率仍然還不到80%;時至今日,僅靠大規模預訓練模型的zero-shot泛化就能達到80.1%的準確率。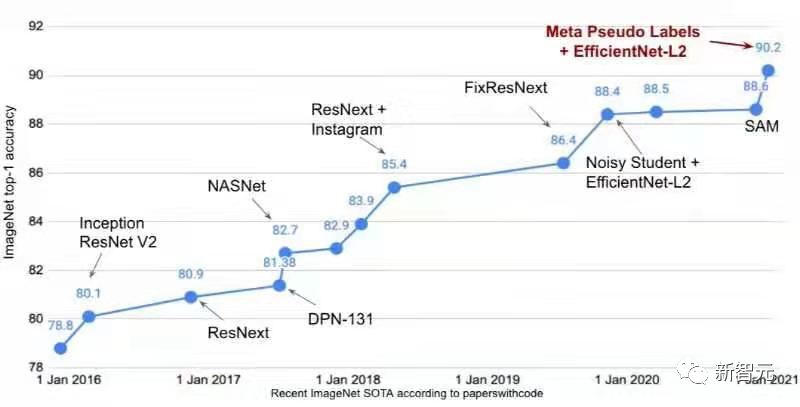 最近LAION使用開源代碼OpenCLIP框架訓練了一個全新的 ViT-G/14 CLIP 模型,在 ImageNet數據集上,原版OpenAI CLIP的準確率只有75.4%,而OpenCLIP實現了80.1% 的zero-shot準確率,在 MS COCO 上實現了74.9% 的zero-shot圖像檢索(Recall@5),這也是目前性能最強的開源 CLIP 模型。
最近LAION使用開源代碼OpenCLIP框架訓練了一個全新的 ViT-G/14 CLIP 模型,在 ImageNet數據集上,原版OpenAI CLIP的準確率只有75.4%,而OpenCLIP實現了80.1% 的zero-shot準確率,在 MS COCO 上實現了74.9% 的zero-shot圖像檢索(Recall@5),這也是目前性能最強的開源 CLIP 模型。
 LAION全稱為Large-scale Artificial Intelligence Open Network,是一家非營利組織,其成員來自世界各地,旨在向公眾提供大規模機器學習模型、數據集和相關代碼。他們聲稱自己是真正的Open AI,100%非盈利且100%免費。
感興趣的小伙伴可以把手頭的CLIP模型更新版本了!
LAION全稱為Large-scale Artificial Intelligence Open Network,是一家非營利組織,其成員來自世界各地,旨在向公眾提供大規模機器學習模型、數據集和相關代碼。他們聲稱自己是真正的Open AI,100%非盈利且100%免費。
感興趣的小伙伴可以把手頭的CLIP模型更新版本了!
模型地址:https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k
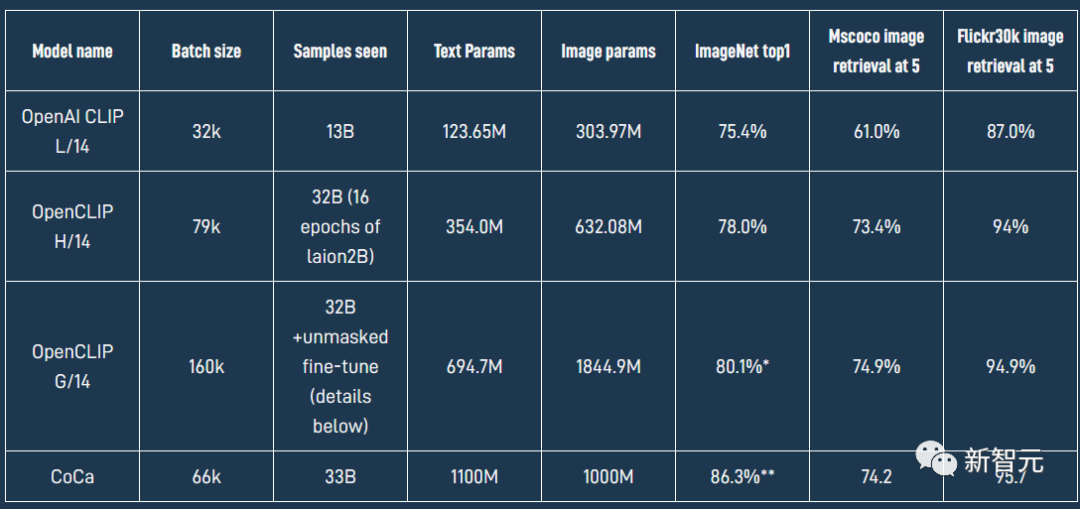
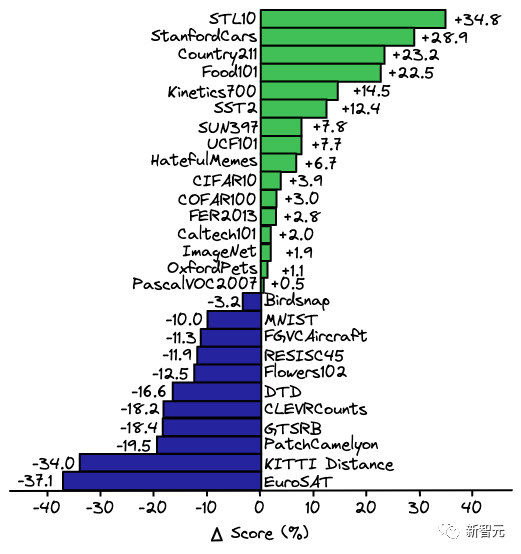
OpenCLIP模型在各個數據集上具體的性能如下表所示。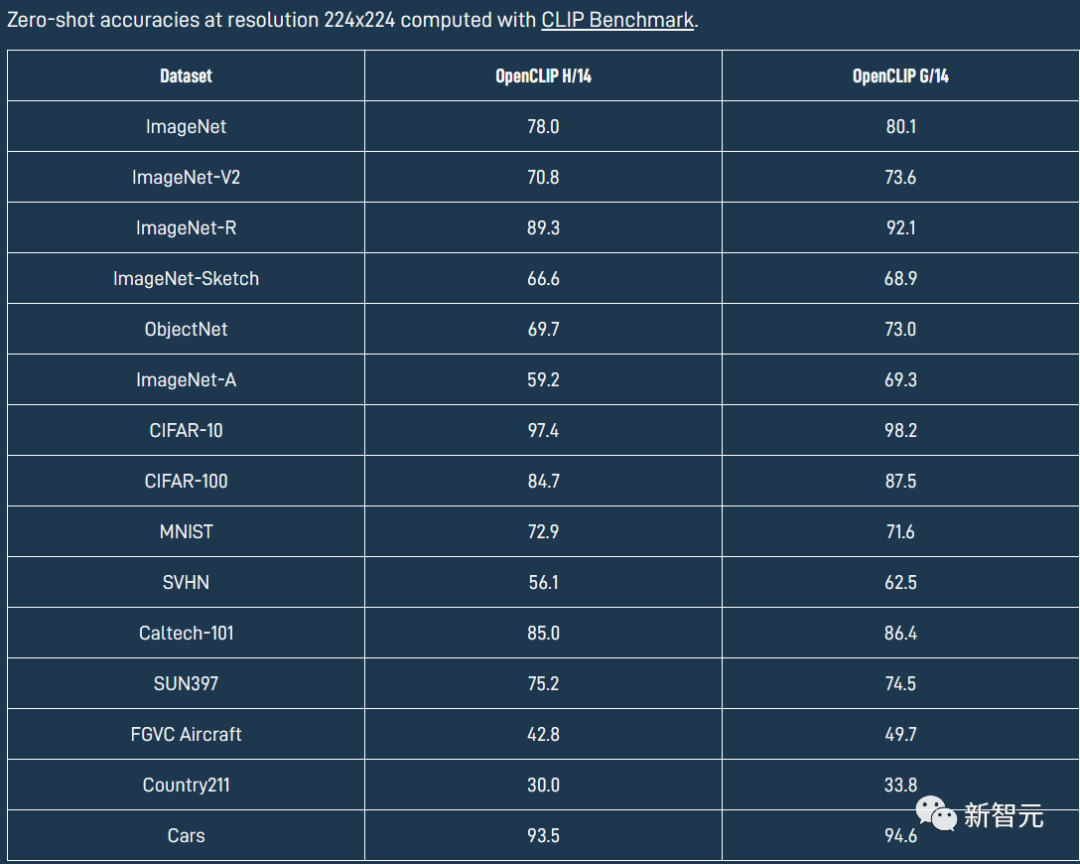
Zero-shot能力
一般來說,計算機視覺(CV)模型在各個任務上的sota性能都是基于特定領域的訓練數據,無法泛化到其他領域或任務中,導致對視覺世界的通用屬性理解有限。泛化問題對于那些缺少大量訓練數據的領域尤其重要。 理想情況下,CV模型應該學會圖像的語義內容,而非過度關注訓練集中的特定標簽。比如對于狗的圖像,模型應該能夠理解圖像中有一只狗,更進一步來理解背景中有樹、時間是白天、狗在草地上等等。 但當下采用「分類訓練」得到的結果與預期正好相反,模型學習將狗的內部表征推入相同的「狗向量空間」,將貓推入相同的「貓向量空間」,所有的問題的答案都是二元,即圖像是否能夠與一個類別標簽對齊。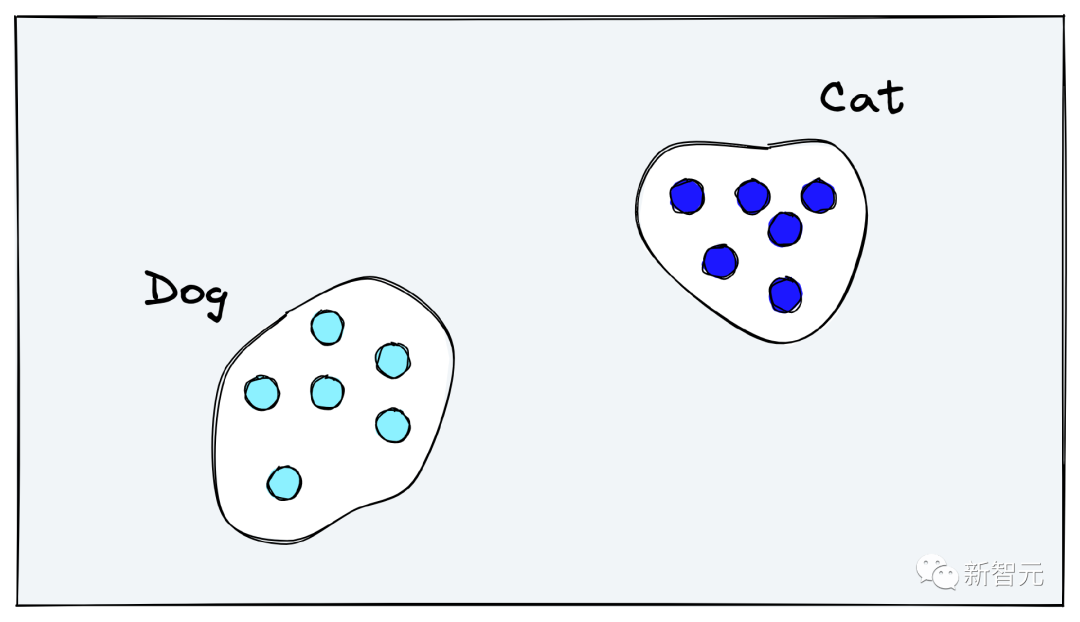 對新任務重新訓練一個分類模型也是一種方案,但是訓練本身需要大量的時間和資金投入來收集分類數據集以及訓練模型。
幸運的是,OpenAI 的CLIP模型是一個非常靈活的分類模型,通常不需要重新訓練即可用于新的分類任務中。
對新任務重新訓練一個分類模型也是一種方案,但是訓練本身需要大量的時間和資金投入來收集分類數據集以及訓練模型。
幸運的是,OpenAI 的CLIP模型是一個非常靈活的分類模型,通常不需要重新訓練即可用于新的分類任務中。
CLIP為何能Zero-Shot
對比語言-圖像預訓練(CLIP, Contrastive Language-Image Pretraining)是 OpenAI 于2021年發布的一個主要基于Transformer的模型。
CLIP 由兩個模型組成,一個Transformer編碼器用于將文本轉換為embedding,以及一個視覺Transformer(ViT)用于對圖像進行編碼。
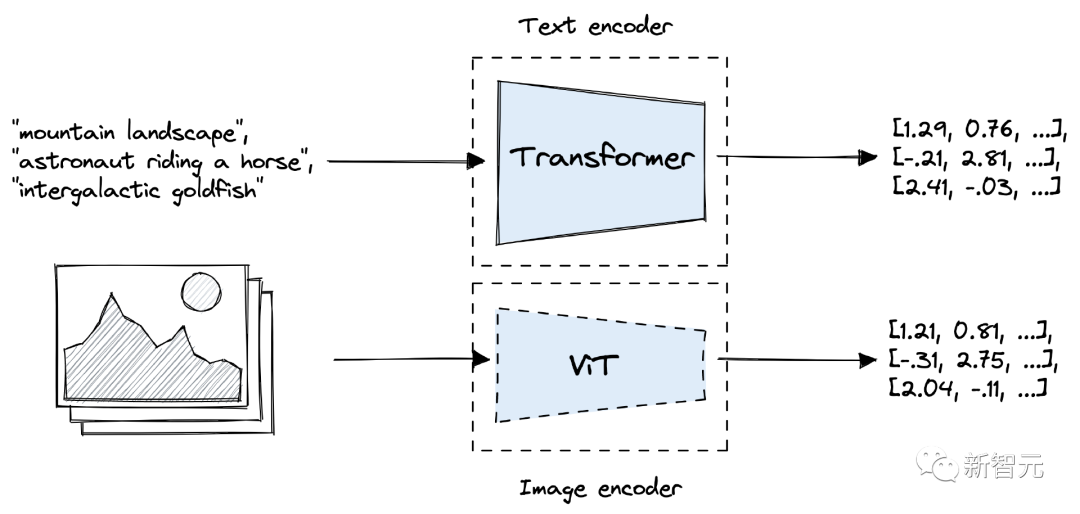
CLIP內的文本和圖像模型在預訓練期間都進行了優化,以在向量空間中對齊相似的文本和圖像。在訓練過程中,將數據中的圖像-文本對在向量空間中將輸出向量推得更近,同時分離不屬于一對的圖像、文本向量。
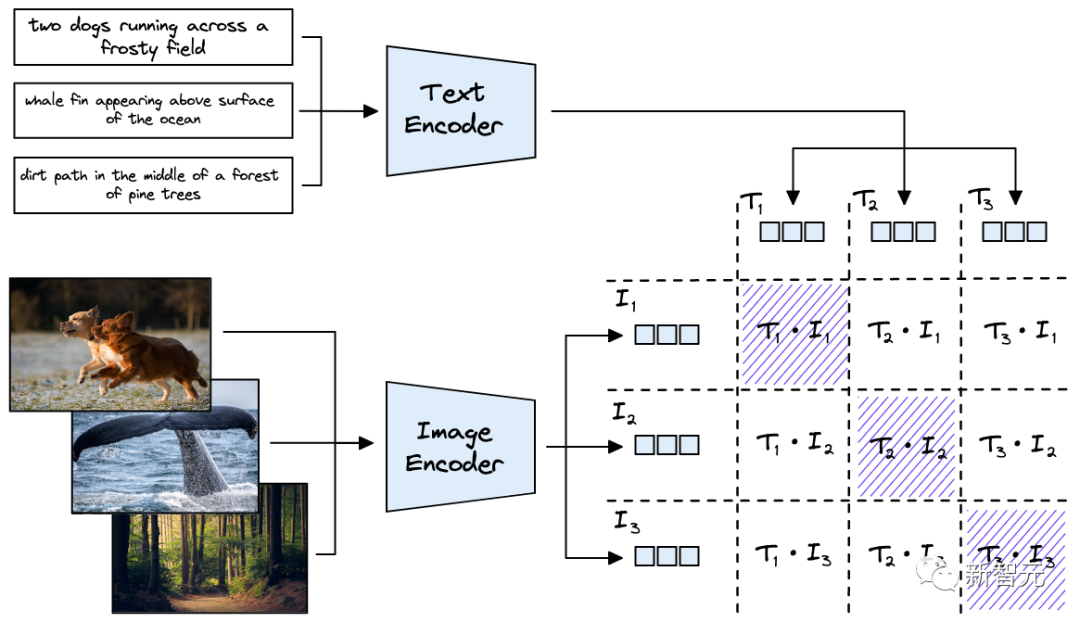
CLIP與一般的分類模型之間有幾個區別:
首先,OpenAI 使用從互聯網上爬取下來的包含4億文本-圖像對的超大規模數據集進行訓練,其好處在于:
1. CLIP的訓練只需要「圖像-文本對」而不需要特定的類標簽,而這種類型的數據在當今以社交媒體為中心的網絡世界中非常豐富。
2. 大型數據集意味著 CLIP 可以對圖像中的通用文本概念進行理解的能力。
3. 文本描述(text descriptor)中往往包含圖像中的各種特征,而不只是一個類別特征,也就是說可以建立一個更全面的圖像和文本表征。
上述優勢也是CLIP其建立Zero-shot能力的關鍵因素,論文的作者還對比了在ImageNet上專門訓練的 ResNet-101模型和 CLIP模型,將其應用于從ImageNet 派生的其他數據集,下圖為性能對比。
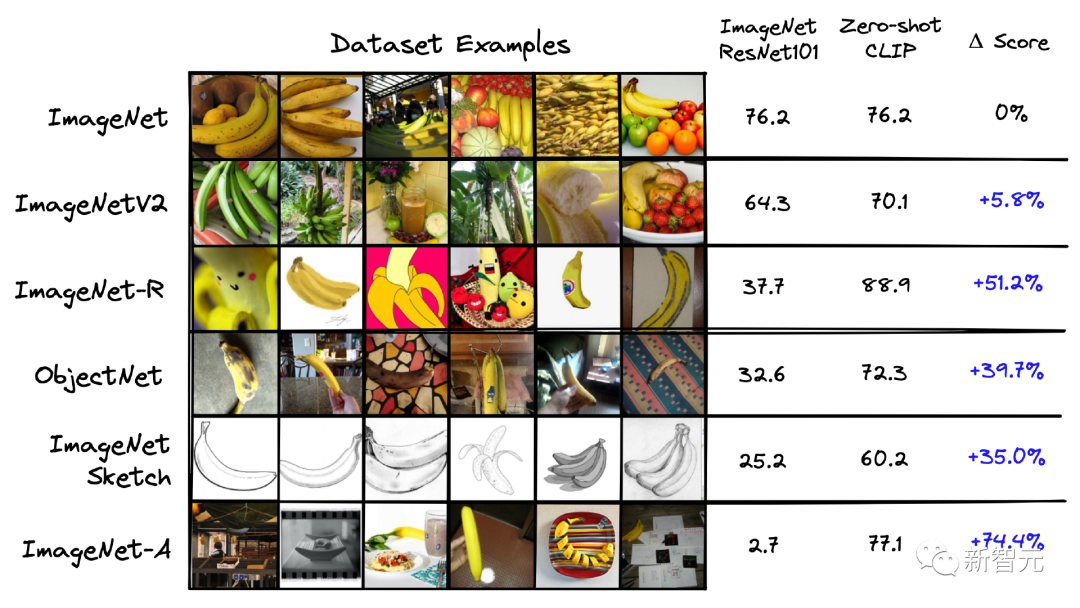
可以看到,盡管 ResNet-101是在ImageNet上進行訓練的,但它在相似數據集上的性能要比 CLIP 在相同任務上的性能差得多。
在將 ResNet 模型應用于其他領域時,一個常用的方法是「linear probe」(線性探測),即將ResNet模型最后幾層所學到的特性輸入到一個線性分類器中,然后針對特定的數據集進行微調。
在CLIP論文中,線性探測ResNet-50與zero-shot的CLIP 進行了對比,結論是在相同的場景中,zero-shot CLIP 在多個任務中的性能都優于在ResNet-50中的線性探測。
不過值得注意的是,當給定更多的訓練樣本時,Zero-shot并沒有優于線性探測。
用CLIP做Zero-shot分類
從上面的描述中可以知道,圖像和文本編碼器可以創建一個512維的向量,將輸入的圖像和文本輸入映射到相同的向量空間。
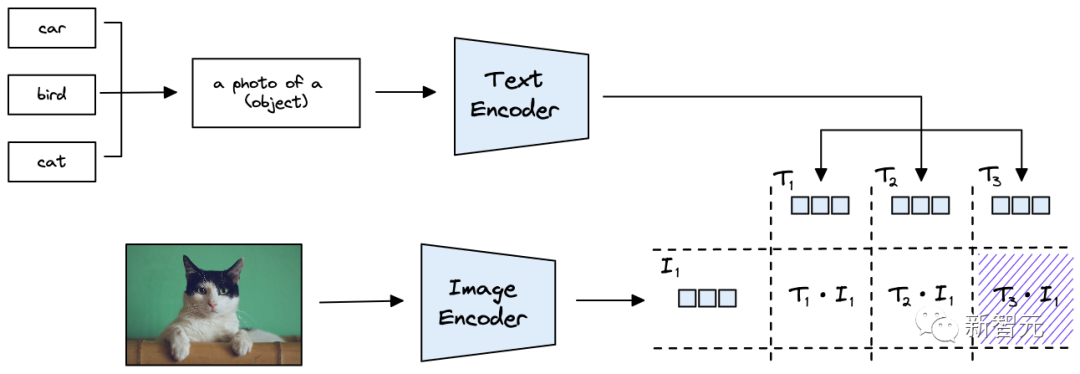
用CLIP做Zero-shot分類也就是把類別信息放入到文本句子中。
舉個例子,輸入一張圖像,想要判斷其類別為汽車、鳥還是貓,就可以創建三個文本串來表示類別:
T1代表車:a photo of a car
T2代表鳥:a photo of a bird
T3代表貓:a photo of a cat
將類別描述輸入到文本編碼器中,就可以得到可以代表類別的向量。
假設輸入的是一張貓的照片,用 ViT 模型對其進行編碼獲取圖像向量后,將其與類別向量計算余弦距離作為相似度,如果與T3的相似度最高,就代表圖像的類別屬于貓。
可以看到,類別標簽并不是一個簡單的詞,而是基于模板「a photo of a {label}」的格式重新改寫為一個句子,從而可以擴展到不受訓練限制的類別預測。
實驗中,使用該prompt模板在ImageNet的分類準確性上提高了1.3個百分點,但prompt模板并不總是能提高性能,在實際使用中需要根據不同的數據集進行測試。
Python實現
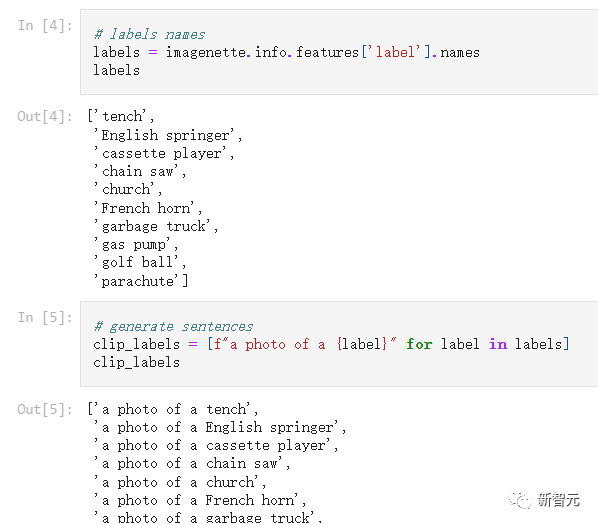
想要快速使用CLIP做zero-shot分類也十分容易,作者選取了Hugging Face中的frgfm/imagenette數據集作為演示,該數據集包含10個標簽,且全部保存為整數值。

使用 CLIP進行分類,需要將整數值標簽轉換為對應的文本內容。
在直接將標簽和照片進行相似度計算前,需要初始化 CLIP模型,可以使用通過 Hugging Face transformers找到的 CLIP 實現。

文本transformer無法直接讀取文本,而是需要一組稱為token ID(或input _ IDs)的整數值,其中每個唯一的整數表示一個word或sub-word(即token)。

將轉換后的tensor輸入到文本transformer中可以獲取標簽的文本embedding

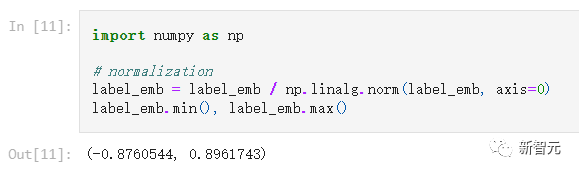
注意,目前CLIP輸出的向量還沒有經過歸一化(normalize),點乘后獲取的相似性結果是不準確的。
下面就可以選擇一個數據集中的圖像作測試,經過相同的處理過程后獲取到圖像向量。

將圖像轉換為尺寸為(1, 3, 224, 224)向量后,輸入到模型中即可獲得embedding

下一步就是計算圖像embedding和數據集中的十個標簽文本embedding之間的點積相似度,得分最高的即是預測的類別。

模型給出的結果為cassette player(盒式磁帶播放器),在整個數據集再重復運行一遍后,可以得到準確率為98.7%

除了Zero-shot分類,多模態搜索、目標檢測、 生成式模型如OpenAI 的 Dall-E 和 Stable disusion,CLIP打開了計算機視覺的新大門。
審核編輯 :李倩
-
開源
+關注
關注
3文章
3409瀏覽量
42722 -
計算機視覺
+關注
關注
8文章
1701瀏覽量
46137 -
數據集
+關注
關注
4文章
1209瀏覽量
24842
原文標題:ImageNet零樣本準確率首次超過80%,地表最強開源CLIP模型更新
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NVIDIA DRIVE Hyperion平臺達成安全與認證里程碑
開源大模型在多個業務場景的應用案例
e絡盟達成micro:bit分銷里程碑
Meta重磅發布Llama 3.3 70B:開源AI模型的新里程碑
破萬億!中國芯片出口迎來里程碑

e絡盟達成BBC micro:bit計算機制造分銷里程碑
e絡盟達成制造分銷千萬臺BBC micro:bit里程碑
e絡盟實現重要里程碑:成功分銷 1000 萬套 micro:bit 設備

比亞迪達成新能源汽車下線千萬輛里程碑
黑芝麻智能與Nullmax達成重要合作里程碑
比亞迪創歷史,率先實現第900萬輛新能源汽車下線里程碑
特斯拉里程碑達成:第1億顆4680電池震撼問世
Waymo自動駕駛里程碑:Alphabet引領未來出行新篇章
特斯拉迎來里程碑:全球第1000萬個電驅系統下線
它人機器人與俄羅斯的AVIALIFT正式攜手,達成里程碑式合作






 工商網監
工商網監
評論