") 使用AXI CDMA制作FPGA AI加速器通道
使用AXI CDMA制作FPGA AI加速器通道
介紹
使用 AMD-Xilinx FPGA設(shè)計一個全連接DNN核心現(xiàn)在比較容易(Vitis AI),但是利用這個核心在 DNN 計算中使用它是另一回事。本項目主要是設(shè)計AI加速器,利用Xilinx的CDMA加載權(quán)重,輸入到PL區(qū)的Block Ram。
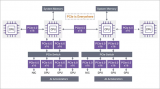
原理框圖
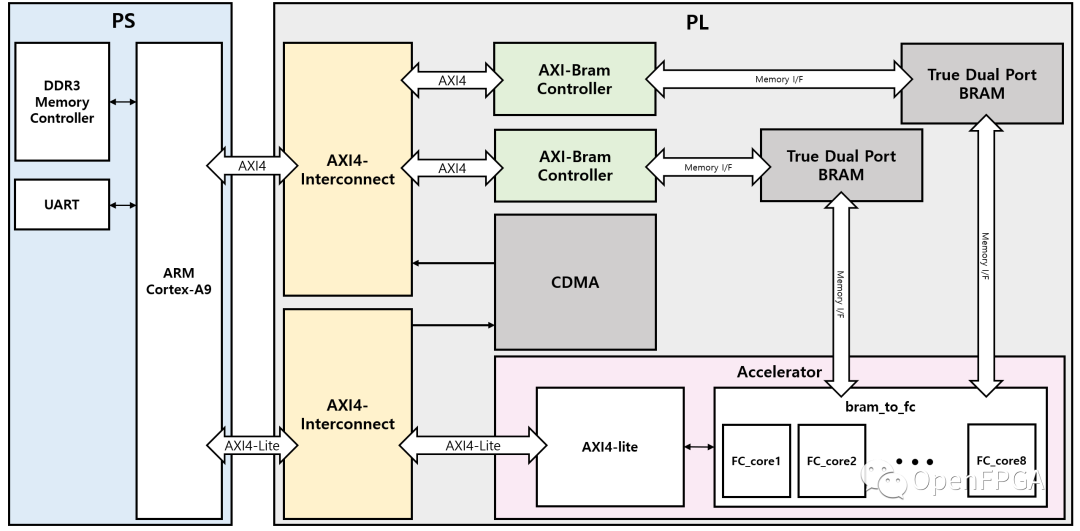
首先,我們創(chuàng)建了整個系統(tǒng)的示意圖。有兩個 Block RAW 分別用于存儲輸入特征和權(quán)重數(shù)據(jù)。每個Block RAM 都連接到一個 CDMA ,允許 DRAM 訪問 Bram。每個 Block RAM 還連接到由 8 個 FCN 內(nèi)核和 FSM 組成的主加速器,控制內(nèi)核的操作。
完整的激活順序如下:
在 DDR 內(nèi)存中存儲特征和權(quán)重。
使用CDMA 將這些數(shù)據(jù)分別發(fā)送到block ram1 和block ram2。
向 FC core 發(fā)送 activate 信號,進(jìn)行 FCN 計算。
將結(jié)果存儲在 blcok ram 中。
重復(fù)此過程,直到完成第一層前向傳播。
重復(fù)整個過程,將輸入鏈接到存儲在Block RAM 中的結(jié)果。
碼分多址
為了直接訪問內(nèi)存,我們使用了 cdma。可以在XIinx 網(wǎng)站上參考 xilinx turoial(https://www.xilinx.com/support/university/vivado/vivado-workshops/Vivado-adv-embedded-design-zynq.html)。
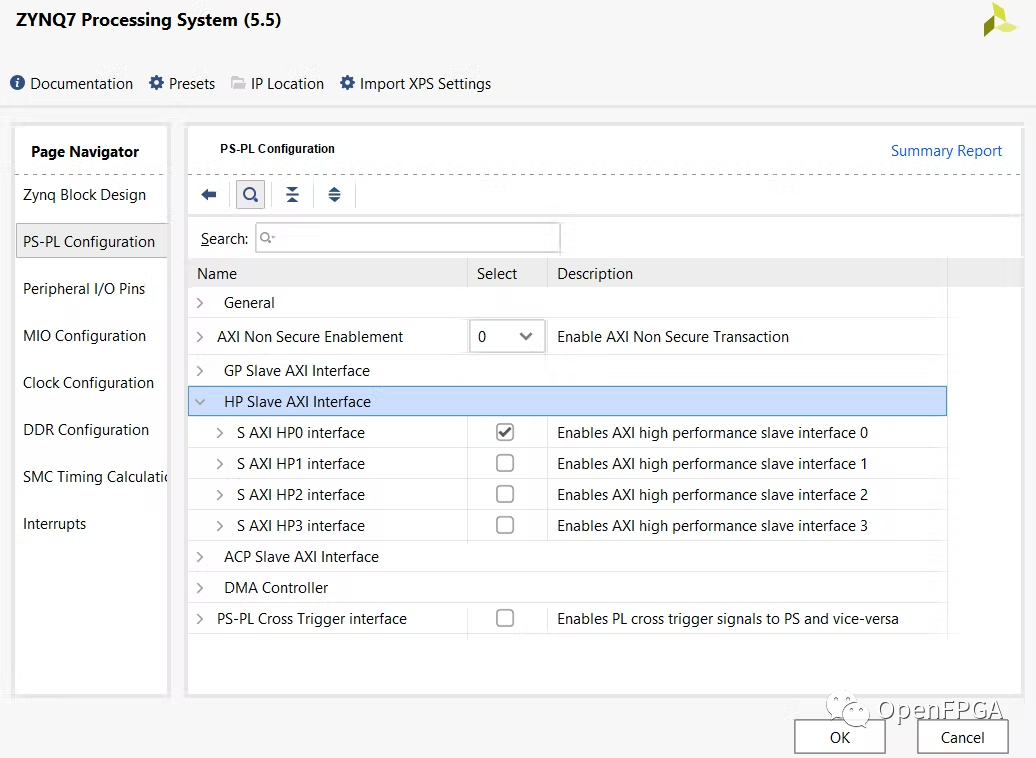
二、添加cdma和bram模塊。Vivado 通過 Run Connection Automation 將 cdma 和 bram 連接到處理器。那么設(shè)計應(yīng)該類似于下圖。
加速器IP
加速器 IP 由 4 個源文件組成。
加速器:連接 AXI4-lite 模塊和 bram_to_fc 模塊。
AXI4-lite :它執(zhí)行 AXI4-lite 接口將結(jié)果值從 PL 傳輸?shù)?PS。并將 fsm 信號傳輸?shù)?bram_to_fc 模塊。
bram_to_fc :它從 bram0、bram1 接收特征圖和權(quán)重,并將它們發(fā)送到 sumproduct_core。
sumproduct_core :它使用 8 位輸入執(zhí)行 sumproduct 計算。并返回 32 位輸出。
創(chuàng)建 AXI4 外設(shè)來制作 AXI4-lite 模板。接口類型是lite版,制作 10 個寄存器。然后修改模板來制作 AXI4-lite 模塊。
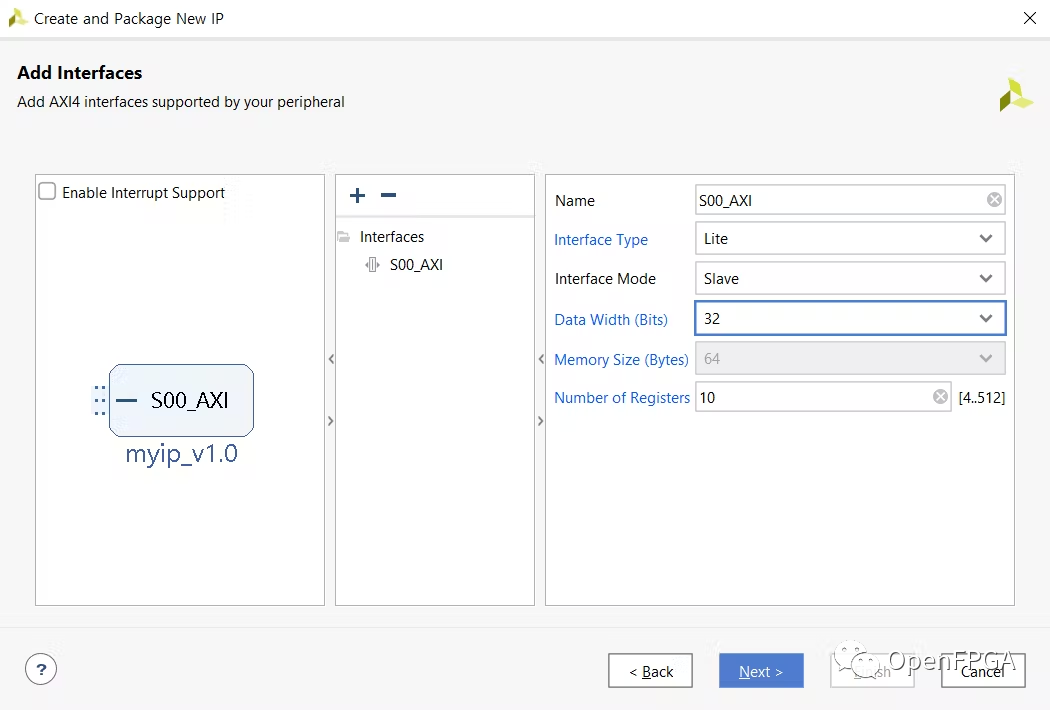
添加以上 4 個 Verilog 文件來生成加速器 IP。
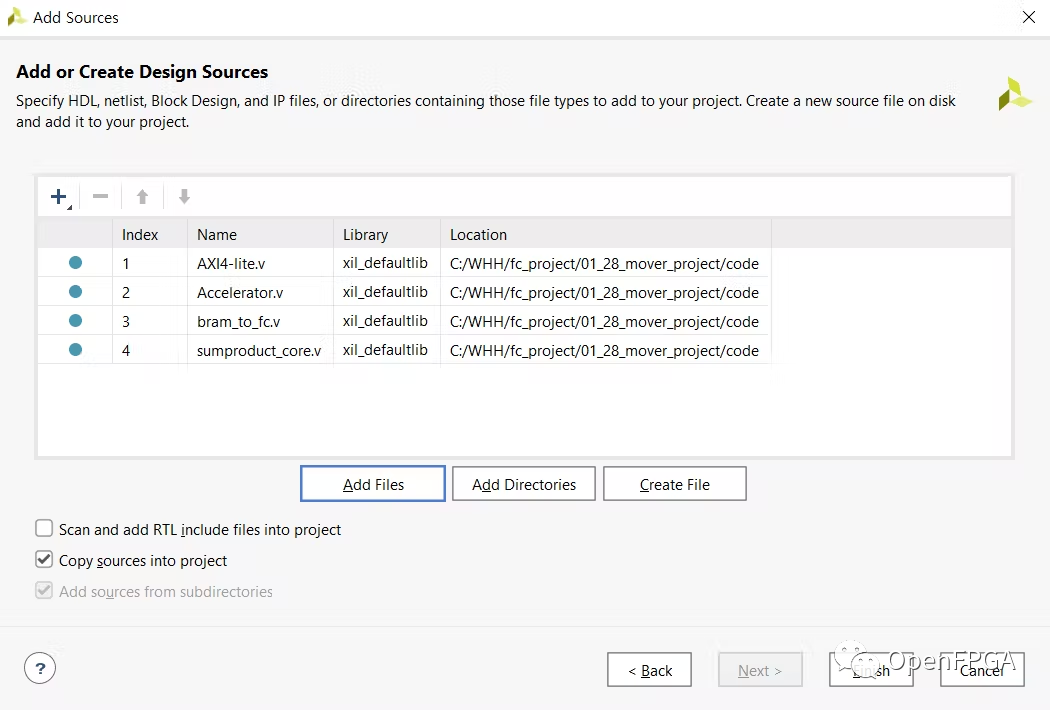
Vivado Block設(shè)計
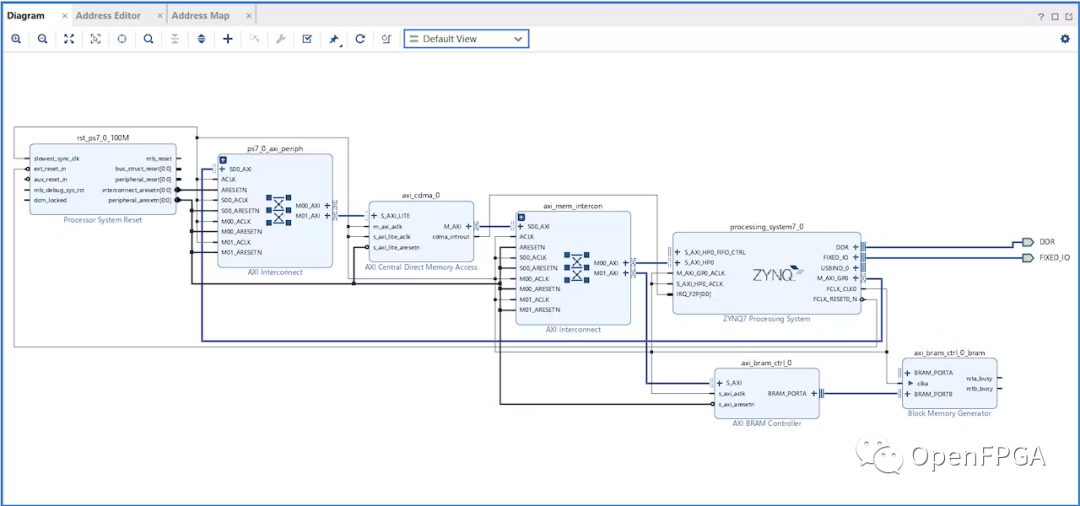
然后我們使用 VIVADO block digram 工具構(gòu)建整個設(shè)計。我們使用具有 64 位數(shù)據(jù)寬度的雙端口 bram 來最大化系統(tǒng)的效率。
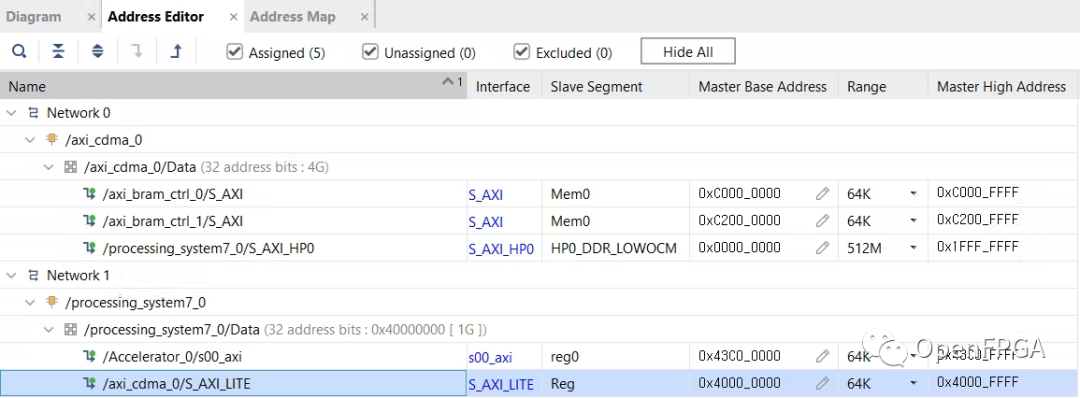
在地址編輯器中,將 axi_bram_ctrl 范圍從 8k 更改為 64k。
測試
在 FPGA 板卡上測試了我們的加速器,將硬件導(dǎo)出到 VITIS,為了測試我們的加速器性能,我們比較了軟件和硬件之間的相同任務(wù)運行時間。
HW運行時間:數(shù)據(jù)發(fā)送時間+HW計算時間+數(shù)據(jù)接收時間
SW runtime : SW計算時間
1. 使用 CDMA 將特征圖和權(quán)重從 DDR3 傳輸?shù)?BRAM。
//transferfeauturemapfromDDR3toBram0 XAxiCdma_IntrEnable(&xcdma,XAXICDMA_XR_IRQ_ALL_MASK); Status=XAxiCdma_SimpleTransfer(&xcdma,(u32)source_0,(u32)cdma_memory_destination_0,numofbytes,Example_CallBack,(void*)&xcdma); //transferweightfromDDR3toBram1 XAxiCdma_IntrEnable(&xcdma,XAXICDMA_XR_IRQ_ALL_MASK); Status=XAxiCdma_SimpleTransfer(&xcdma,(u32)source_1,(u32)cdma_memory_destination_1,numofbytes,Example_CallBack,(void*)&xcdma);
2. 發(fā)送 FSM 運行信號和要傳輸?shù)妮斎霐?shù)量。
Xil_Out32((XPAR_ACCELERATOR_0_BASEADDR)+(CTRL_REG*4),(u32)(numofbytes|0x80000000));
3. 檢查硬件計算結(jié)果。
OT_RSLT_HW[0]=Xil_In64((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_0_REG*AXI_DATA_BYTE)); OT_RSLT_HW[1]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_1_REG*AXI_DATA_BYTE)); OT_RSLT_HW[2]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_2_REG*AXI_DATA_BYTE)); OT_RSLT_HW[3]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_3_REG*AXI_DATA_BYTE)); OT_RSLT_HW[4]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_4_REG*AXI_DATA_BYTE)); OT_RSLT_HW[5]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_5_REG*AXI_DATA_BYTE)); OT_RSLT_HW[6]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_6_REG*AXI_DATA_BYTE)); OT_RSLT_HW[7]=Xil_In32((XPAR_ACCELERATOR_0_BASEADDR)+(RESULT_7_REG*AXI_DATA_BYTE)); for(ii=0;ii<8;?ii++){ ???????printf("%d? ",?OT_RSLT_HW[ii]); ??????????}
4. 檢查SW計算結(jié)果。
可以在下面看到測試結(jié)果。
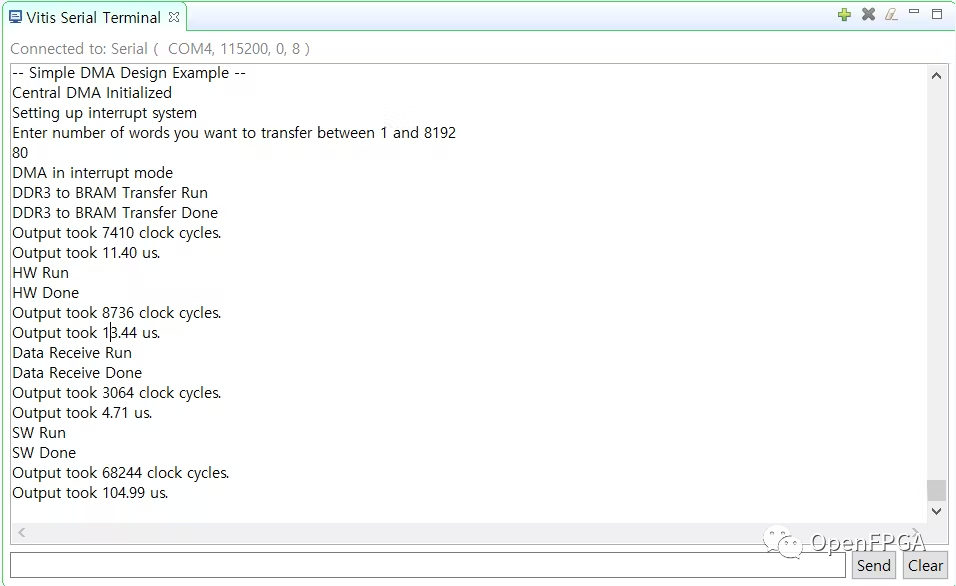
正如在這個結(jié)果中看到的那樣,我們加速器的使用時間(11.40+13.44+4.71 us)比在 PS 區(qū)域(104.99 us)上要少得多。
代碼
https://github.com/Hyunho-Won/cdma_accelerator
審核編輯:湯梓紅
-
FPGA
+關(guān)注
關(guān)注
1638文章
21883瀏覽量
610750 -
amd
+關(guān)注
關(guān)注
25文章
5533瀏覽量
135435 -
加速器
+關(guān)注
關(guān)注
2文章
819瀏覽量
38692 -
AI
+關(guān)注
關(guān)注
87文章
33200瀏覽量
273456 -
AXI
+關(guān)注
關(guān)注
1文章
132瀏覽量
16989
原文標(biāo)題:使用 AXI CDMA 制作 FPGA AI 加速器通道
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
數(shù)據(jù)中心加速器就看GRVI Phalanx FPGA加速器
家居智能化,推動AI加速器的發(fā)展

機(jī)器學(xué)習(xí)實戰(zhàn):GNN加速器的FPGA解決方案
使用AMD-Xilinx FPGA設(shè)計一個AI加速器通道
【書籍評測活動NO.18】 AI加速器架構(gòu)設(shè)計與實現(xiàn)
《 AI加速器架構(gòu)設(shè)計與實現(xiàn)》+第2章的閱讀概括
優(yōu)化基于FPGA的深度卷積神經(jīng)網(wǎng)絡(luò)的加速器設(shè)計
基于Xilinx FPGA的Memcached硬件加速器的介紹
基于FPGA的SIMD卷積神經(jīng)網(wǎng)絡(luò)加速器
什么是AI加速器 如何確需要AI加速器
如何采用帶專用CNN加速器的AI微控制器實現(xiàn)CNN的硬件轉(zhuǎn)換
Rapanda流加速器-實時流式FPGA加速器解決方案

PCIe在AI加速器中的作用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論