 ChatGPT原理介紹
ChatGPT原理介紹
( 本文是chatGPT原理介紹,但沒有任何數學公式,可以放心食用 )
前言
這兩天,chatGPT模型真可謂稱得上是狂拽酷炫D炸天的存在了。一度登上了知乎熱搜,這對科技類話題是非常難的存在。不光是做人工智能、機器學習的人關注,而是大量的各行各業從業人員都來關注這個模型,真可謂空前盛世。
我趕緊把 openai 以往的 GPT-n 系列論文又翻出來,重新學習一下,認真領會 大規模預訓練語言模型(Large Language Model) 的強大之處。
可能很多深度學習相關從業人員的感受和我一樣,大家之前對 LLM 的感受依然是,預訓練+finetune,處理下游任務,依然需要大量的標注數據和人工干預,怎么突然間,chatGPT 就智能到如此地步?
接下來,我簡要梳理一下 openai 的 GPT 大模型的發展歷程。
一、還得從 Bert 說起
2018年,自然語言處理 NLP 領域也步入了 LLM 時代,谷歌出品的 Bert 模型橫空出世,碾壓了以往的所有模型,直接在各種NLP的建模任務中取得了最佳的成績。
Bert做了什么,主要用以下例子做解釋。
請各位做一個完形填空:___________和阿里、騰訊一起并成為中國互聯網 BAT 三巨頭。
請問上述空格應該填什么?有的人回答“ 百度 ”,有的人可能覺得,“ 字節 ”也沒錯。但總不再可能是別的字了。
不論填什么,這里都表明, 空格處填什么字,是受到上下文決定和影響的 。
Bert 所作的事就是從大規模的上億的文本預料中,隨機地扣掉一部分字,形成上面例子的完形填空題型,不斷地學習空格處到底該填寫什么。所謂語言模型,就是從大量的數據中學習復雜的上下文聯系。
二、GPT 初代
與此同時,openai 早于 Bert 出品了一個初代 GPT 模型。
他們大致思想是一樣的。都基于 Transformer 這種編碼器,獲取了文本內部的相互聯系。
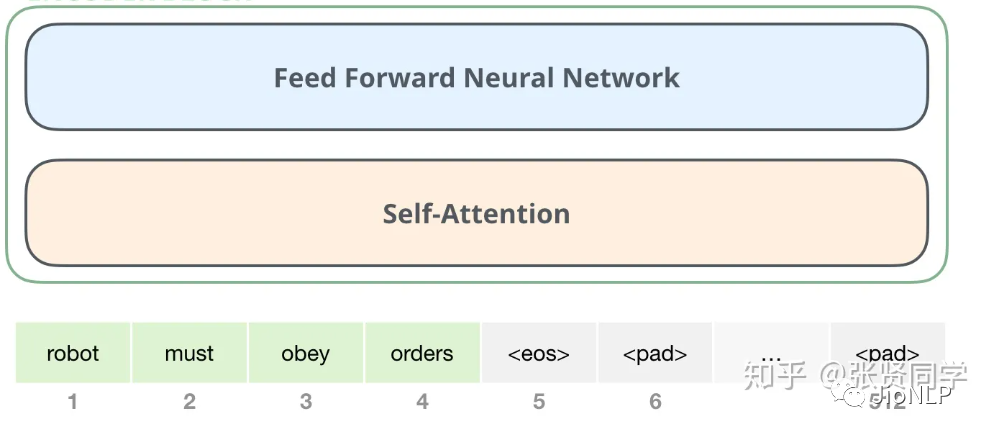
Transformer結構
編解碼的概念廣泛應用于各個領域,在 NLP 領域,人們使用語言一般包括三個步驟:
接受聽到或讀到的語言 -> 大腦理解 -> 輸出要說的語言。
語言是一個顯式存在的東西,但大腦是如何將語言進行理解、轉化和存儲的,則是一個目前仍未探明的東西。因此,大腦理解語言這個過程,就是大腦將語言編碼成一種可理解、可存儲形式的過程,這個過程就叫做 語言的編碼 。
相應的,把大腦中想要表達的內容,使用語言表達出來,就叫做 語言的解碼 。
在語言模型中,編碼器和解碼器都是由一個個的 Transformer 組件拼接在一起形成的。

Transformer編碼器組成的 Encoder-decoder模型
這里不展開講 Transformer 里的內部結構,僅僅講一下 Bert 和 GPT 的區別。
兩者最主要的區別在于,Bert 僅僅使用了 encoder 也就是編碼器部分進行模型訓練,GPT 僅僅使用了 decoder 部分。兩者各自走上了各自的道路,根據我粗淺的理解, GPT 的decoder 模型更加適應于文本生成領域 。
GPT 初代其實個人認為(當然普遍也都這么認為)略遜色于 Bert,再加上宣傳地不夠好,影響力也就小于 Bert。
我相信很多的 NLP 從業者對 LLM 的理解也大都停留在此。即,本質上講,LLM 是一個非常復雜的編碼器,將文本表示成一個向量表示,這個向量表示有助于解決 NLP 的任務。
三、GPT-2
自從 Bert 炸街后,跟風效仿的改進模型也就越來越多了,比如 albert、roberta、ERNIE,BART、XLNET、T5 等等五花八門。
最初的時候,僅僅是一個完形填空任務就可以讓語言模型有了極大進步,那么,給 LLM 模型出其它的語言題型,應該也會對模型訓練有極大的幫助。
想要出語言題型不是很簡單么,什么句子打亂順序再排序、選擇題、判斷題、改錯題、把預測單字改成預測實體詞匯等等,紛紛都可以制定數據集添加在模型的預訓練里。很多模型也都是這么干的。
既然出題也可以,把各種NLP任務的數據集添加到預訓練階段當然也可以。
這個過程也和人腦很像,人腦是非常穩定和泛化的,既可以讀詩歌,也可以學數學,還可以學外語,看新聞,聽音樂等等,簡而言之,就是 一腦多用 。
我們一般的 NLP 任務,文本分類模型就只能分類,分詞模型就只能分詞,機器翻譯也就只能完成翻譯這一件事,非常不靈活。
GPT-2 主要就是在 GPT 的基礎上,又添加了多個任務,擴增了數據集和模型參數,又訓練了一番。

GPT-2學習效果圖
既然多個任務都在同一個模型上進行學習,還存在一個問題,這一個模型能承載的并不僅僅是任務本身,“ 汪小菲的媽是張蘭 ”,這條文字包含的信息量是通用的,它既可以用于翻譯,也可以用于分類,判斷錯誤等等。也就是說,信息是脫離具體 NLP 任務存在的,舉一反三,能夠利用這條信息,在每一個 NLP 任務上都表現好,這個是 元學習(meta-learning),實際上就是語言模型的一腦多用 。
四、GPT-3
大模型中的大模型
首先, GPT-3 的模型所采用的數據量之大,高達上萬億,模型參數量也十分巨大,學習之復雜,計算之繁復不說了,看圖吧。

GPT-3 里的大模型計算量是 Bert-base 的上千倍 。統統這些都是在燃燒的金錢,真就是 all you need is money。如此巨大的模型造就了 GPT-3 在許多十分困難的 NLP 任務,諸如撰寫人類難以判別的文章,甚至編寫SQL查詢語句,React或者JavaScript代碼上優異的表現。
首先 GPT-n 系列模型都是采用 decoder 進行訓練的,也就是更加適合文本生成的形式。也就是,輸入一句話,輸出也是一句話。也就是對話模式。
對話
我們是如何學會中文的?通過從0歲開始,聽,說,也就是 對話 。
我們是如何學外語的?看教材,聽廣播,背單詞。唯獨缺少了對話! 正是因為缺少了對話這個高效的語言學習方式,所以我們的英語水平才如此難以提高。
對于語言模型,同理。
對話是涵蓋一切NLP 任務的終極任務。從此 NLP不再需要模型建模這個過程。比如,傳統 NLP 里還有序列標注這個任務,需要用到 CRF 這種解碼過程。在對話的世界里,這些統統都是冗余的。
其實 CRF 這項技術還是蠻經典的,在深度學習這塊,CRF這也才過去沒幾年。sigh……
in-context learning
以往的預訓練都是兩段式的,即,首先用大規模的數據集對模型進行預訓練,然后再利用下游任務的標注數據集進行 finetune,時至今日這也是絕大多數 NLP 模型任務的基本工作流程。
GPT-3 就開始顛覆這種認知了。它提出了一種 in-context 學習方式。這個詞沒法翻譯成中文,下面舉一個例子進行解釋。
用戶輸入到 GPT-3:你覺得 JioNLP 是個好用的工具嗎?
GPT-3輸出1:我覺得很好啊。
GPT-3輸出2:JioNLP是什么東西?
GPT-3輸出3:你餓不餓,我給你做碗面吃……
GPT-3輸出4:Do you think jionlp is a good tool?
按理來講,針對機器翻譯任務,我們當然希望模型輸出最后一句,針對對話任務,我們希望模型輸出前兩句中的任何一句。顯然做碗面這個輸出句子顯得前言不搭后語。
這時就有了 in-context 學習,也就是,我們對模型進行引導,教會它應當輸出什么內容。如果我們希望它輸出翻譯內容,那么,應該給模型如下輸入:
用戶輸入到 GPT-3:請把以下中文翻譯成中文:你覺得 JioNLP 是個好用的工具嗎?
如果想讓模型回答問題:
用戶輸入到 GPT-3:模型模型你說說,你覺得 JioNLP 是個好用的工具嗎?
OK,這樣模型就可以根據用戶提示的情境,進行針對性的回答了。
這里,只是告知了模型如何做,最好能夠給模型做個 示范 :
用戶輸入到 GPT-3:**請把以下中文翻譯成中文:蘋果 => apple; 你覺得 JioNLP 是個好用的工具嗎?=>**
其中 蘋果翻譯成 apple,是一個示范樣例,用于讓模型感知該輸出什么。只給提示叫做 zero-shot,給一個范例叫做 one-shot,給多個范例叫做 few-shot。
范例給幾個就行了,不能再給多了!一個是,咱們沒那么多標注數據,另一個是,給多了不就又成了 finetune 模式了么?

在 GPT-3 的預訓練階段,也是按照這樣多個任務同時學習的。比如“ 做數學加法,改錯,翻譯 ”同時進行。這其實就類似前段時間比較火的 prompt 。
這種引導學習的方式,在超大模型上展示了驚人的效果:只需要給出一個或者幾個示范樣例,模型就能照貓畫虎地給出正確答案。 注意啊,是超大模型才可以,一般幾億參數的大模型是不行的。( 我們這里沒有小模型,只有大模型、超大模型、巨大模型 )
這個表格彷佛在嘲諷我:哎,你沒錢,你就看不著這種優質的效果,你氣不氣?
五、chatGPT
終于說到了主角,能看到這里的, 可以關注一下 JioNLP 公眾號嗎 ?我寫的也夠累的。
charGPT 模型上基本上和之前都沒有太大變化,主要變化的是訓練策略變了。
強化學習
幾年前,alpha GO 擊敗了柯潔,幾乎可以說明,強化學習如果在適合的條件下,完全可以打敗人類,逼近完美的極限。
強化學習非常像生物進化,模型在給定的環境中,不斷地根據環境的 懲罰和獎勵(reward) ,擬合到一個最適應環境的狀態。

NLP + 強化學習
強化學習之所以能比較容易地應用在圍棋以及其它各種棋牌游戲里,原因就是因為對莫 alpha Go 而言,環境就是圍棋,圍棋棋盤就是它的整個世界。
而幾年前知乎上就有提問,NLP + 強化學習,可以做嗎?怎么做呢?
底下回答一片唱衰,原因就是因為, NLP 所依賴的環境,是整個現實世界 ,整個世界的復雜度,遠遠不是一個19乘19的棋盤可以比擬的。無法設計反饋懲罰和獎勵函數,即 reward 函數。除非人們一點點地人工反饋。
哎,open-ai 的 chatGPT 就把這事給干了。
不是需要人工標反饋和獎勵嗎?那就撒錢,找40個外包,標起來!
這種帶人工操作的 reward,被稱之為 RLHF(Reinforcement Learning from Human Feedback) 。
具體操作過程就是下圖的樣子,采用強化學習的方式來對模型進行訓練。已經拋棄了傳統的 LM 方式。
這里重點是第二部中,如何構建一個 reward 函數,具體就是讓那40名外包人員不斷地從模型的輸出結果中篩選,哪些是好的,哪些是低質量的,這樣就可以訓練得到一個 reward 模型。
通過reward 模型來評價模型的輸出結果好壞。
講真,這個 reward 模型,《黑客帝國》的母體 matrix 既視感有木有??!!
只要把預訓練模型接一根管子在 reward 模型上,預訓練模型就會開始像感知真實世界那樣,感知reward。
由此,我們就可以得到這個把全世界都震碎的高音!(誤,模型)
六、影響
NLP 領域的影響
個人認為,NLP 領域的一些里程碑性的技術重要性排序如下:
chatGPT > word2vec > Bert (純個人看法)
chatGPT 的關注度已經很大程度讓人們感覺到,什么天貓精靈、小愛同學等等人工智障的時代似乎過去了。只要模型足夠大,數據足夠豐富,reward 模型經過了更多的人迭代和優化,完全可以創造一個無限逼近真實世界的超級 openai 大腦。
當然,chat GPT 依然是存在回答不好的情況的,比如會重復一些詞句,無法分清楚事實等等。
而且,chatGPT 目前看,它是沒有在推理階段連接外部信息的。
模型知道自己的回答邊界,知道自己只是一個沒有情感的回答工具。那么,試想 openai 把外部信息也導入到 chatGPT 里。
另一些影響
我看到 chatGPT 居然可以寫代碼,還能幫我改代碼,debug, 作為程序員,我不禁深深陷入了沉思 。
據說,debug 程序員網站 stackoverflow,已經下場封殺 chatGPT 了。
當然,完全不僅僅是程序界。據說 GPT-4 正在做圖文理解,那么,對于教師、醫生、咨詢師、等等等等,各行各業,是不是都是一個巨大的沖擊?所謂專業領域的知識門檻,也將被模型一步踏平。 到時候,可能人類真的要靠邊站了,除了某些高精尖的行業精英 。
有人講 google 將被替代,我認為也就還好吧,依照google那財大氣粗的樣子,沒準 google 此時此刻,NLP+強化學習也已經在路上了。
-
人工智能
+關注
關注
1804文章
48726瀏覽量
246625 -
機器學習
+關注
關注
66文章
8492瀏覽量
134117 -
ChatGPT
+關注
關注
29文章
1588瀏覽量
8806
發布評論請先 登錄
【國產FPGA+OMAPL138開發板體驗】(原創)6.FPGA連接ChatGPT 4
在FPGA設計中是否可以應用ChatGPT生成想要的程序呢
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來了

在IC設計/驗證中怎么應用ChatGPT呢?
科技大廠競逐AIGC,中國的ChatGPT在哪?
10分鐘教你如何ChatGPT最詳細注冊教程
ChatGPT介紹和代碼智能

無需注冊試用ChatGPT
關于ChatGPT的自我介紹
最強AI聊天機器人模型ChatGPT驚艷來襲
介紹ChatGPT和高頻測試的基本知識
社區說 | 八仙過海: 機器學習算法專題篇

【今晚開播】社區說 | 八仙過海: 機器學習算法專題篇






 工商網監
工商網監
評論