") 數(shù)據(jù)采集技術(shù)常用的采集方法包括幾種
數(shù)據(jù)采集技術(shù)常用的采集方法包括幾種
大數(shù)據(jù)的來(lái)源主要包括:商業(yè)數(shù)據(jù)、互聯(lián)網(wǎng)數(shù)據(jù)、物聯(lián)網(wǎng)數(shù)據(jù)。其中,商業(yè)數(shù)據(jù)來(lái)源于企業(yè)的內(nèi)部系統(tǒng)(如企業(yè)ERP、POS 終端系統(tǒng)、網(wǎng)上支付系統(tǒng)等);互聯(lián)網(wǎng)數(shù)據(jù)包括:QQ、微信、微博、網(wǎng)站數(shù)據(jù);物聯(lián)網(wǎng)數(shù)據(jù)來(lái)源于物聯(lián)網(wǎng)硬件設(shè)備(如射頻識(shí)別裝置、全球定位設(shè)備、傳感器設(shè)備、視頻監(jiān)控設(shè)備等)。
大數(shù)據(jù)的數(shù)據(jù)類(lèi)型可分為三種:結(jié)構(gòu)化數(shù)據(jù)、半結(jié)構(gòu)化數(shù)據(jù)、非結(jié)構(gòu)化數(shù)據(jù)。其中,結(jié)構(gòu)化數(shù)據(jù)是關(guān)系數(shù)據(jù)庫(kù)中的數(shù)據(jù),可直接被使用和存儲(chǔ);半結(jié)構(gòu)化數(shù)據(jù)可通過(guò)一定規(guī)律存儲(chǔ),如excel表格中的數(shù)據(jù);非結(jié)構(gòu)化數(shù)據(jù)是雜亂無(wú)章的,如郵件、網(wǎng)頁(yè)的文字和圖像,需要進(jìn)行相應(yīng)的處理才可被存儲(chǔ)。
數(shù)據(jù)采集技術(shù)是數(shù)據(jù)科學(xué)的重要組成部分,技術(shù)是大數(shù)據(jù)處理的關(guān)鍵技術(shù)之一。常用的采集方法包括兩種:ETL工具采集、網(wǎng)頁(yè)數(shù)據(jù)采集。
一、ETL工具采集
ETL工具采集是將業(yè)務(wù)系統(tǒng)的數(shù)據(jù)通過(guò)抽取、清洗轉(zhuǎn)換后加載至數(shù)據(jù)倉(cāng)庫(kù)的過(guò)程,目的是將企業(yè)中的分散零亂、標(biāo)準(zhǔn)不統(tǒng)一的數(shù)據(jù)整合,為企業(yè)的決策提供分析依據(jù)。
ETL采集是商業(yè)智能項(xiàng)目的重要環(huán)節(jié),目前,互聯(lián)網(wǎng)公司會(huì)采用該技術(shù)獲取相關(guān)數(shù)據(jù)。
二、網(wǎng)頁(yè)數(shù)據(jù)采集
網(wǎng)頁(yè)數(shù)據(jù)采集是在互聯(lián)網(wǎng)中采集數(shù)據(jù)。網(wǎng)頁(yè)數(shù)據(jù)具有多元異構(gòu)交互性、社會(huì)性、突發(fā)性、高噪聲等特點(diǎn),非結(jié)構(gòu)化數(shù)據(jù)比例較高,且數(shù)據(jù)實(shí)時(shí)性較強(qiáng)。
目前,網(wǎng)頁(yè)數(shù)據(jù)主要通過(guò)爬蟲(chóng)采集。爬蟲(chóng)采集需編寫(xiě)爬蟲(chóng)程序或爬蟲(chóng)腳本,爬蟲(chóng)流程是訪問(wèn)一個(gè)url(根據(jù)網(wǎng)絡(luò)資料理解:url的中文名稱(chēng)是統(tǒng)一資源定位符,統(tǒng)一資源定位符是互聯(lián)網(wǎng)資源位置和訪問(wèn)方法的一種簡(jiǎn)潔的表示,俗稱(chēng)網(wǎng)址),并通過(guò)模仿HTTP請(qǐng)求(根據(jù)網(wǎng)絡(luò)資料:HTTP請(qǐng)求是指從客戶(hù)端到服務(wù)器端的請(qǐng)求消息)獲取網(wǎng)頁(yè)。爬蟲(chóng)過(guò)程類(lèi)似于通過(guò)瀏覽器查看并獲取網(wǎng)頁(yè)的信息。
因?yàn)?a href="http://m.xsypw.cn/tags/python/" target="_blank">Python運(yùn)行效率較高,且具有較成熟的爬蟲(chóng)框架和網(wǎng)頁(yè)解析庫(kù)文件,所以可快速處理網(wǎng)絡(luò)數(shù)據(jù)。后文通過(guò)Python介紹爬蟲(chóng)(網(wǎng)絡(luò)爬蟲(chóng))。
網(wǎng)絡(luò)爬蟲(chóng)(Web crawler) 是按照一定規(guī)則,自動(dòng)抓取萬(wàn)維網(wǎng)(英文名稱(chēng)為World Wide Web,簡(jiǎn)稱(chēng)WWW)信息的程序或腳本,一般可分為數(shù)據(jù)采集,處理,儲(chǔ)存三部分。
其中,數(shù)據(jù)采集是通過(guò)模仿HTTP請(qǐng)求獲取網(wǎng)頁(yè),數(shù)據(jù)處理是對(duì)網(wǎng)頁(yè)中非結(jié)構(gòu)化的數(shù)據(jù)進(jìn)行處理,數(shù)據(jù)存儲(chǔ)包括將新URL放置于URL隊(duì)列中和將爬取的數(shù)據(jù)存儲(chǔ)至數(shù)據(jù)存儲(chǔ)介質(zhì)中。 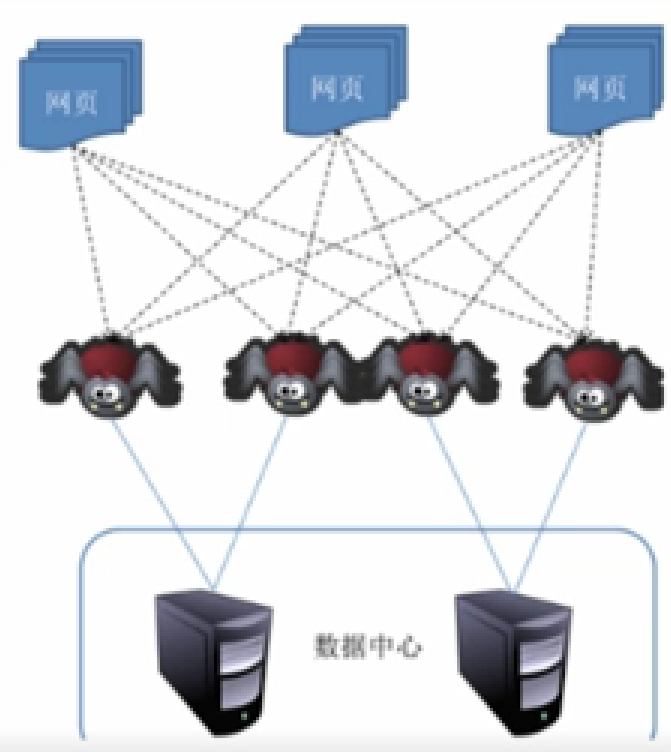
圖片來(lái)源:學(xué)堂在線《大數(shù)據(jù)導(dǎo)論》
網(wǎng)絡(luò)爬蟲(chóng)的系統(tǒng)結(jié)構(gòu)如下:首先啟動(dòng)爬蟲(chóng)應(yīng)用程序。一般,爬蟲(chóng)應(yīng)用程序具有初始化隊(duì)列,初始化隊(duì)列中具有種子URL。然后,下載種子URL所對(duì)應(yīng)的網(wǎng)頁(yè),網(wǎng)頁(yè)中可提取新的URL并加入U(xiǎn)RL隊(duì)列。再然后,將網(wǎng)頁(yè)進(jìn)行簡(jiǎn)單處理后存儲(chǔ)至數(shù)據(jù)庫(kù)中。以上爬蟲(chóng)過(guò)程結(jié)束后,再?gòu)腢RL隊(duì)列中獲取新URL,并下載新URL所對(duì)應(yīng)的網(wǎng)頁(yè),重復(fù)爬蟲(chóng)過(guò)程。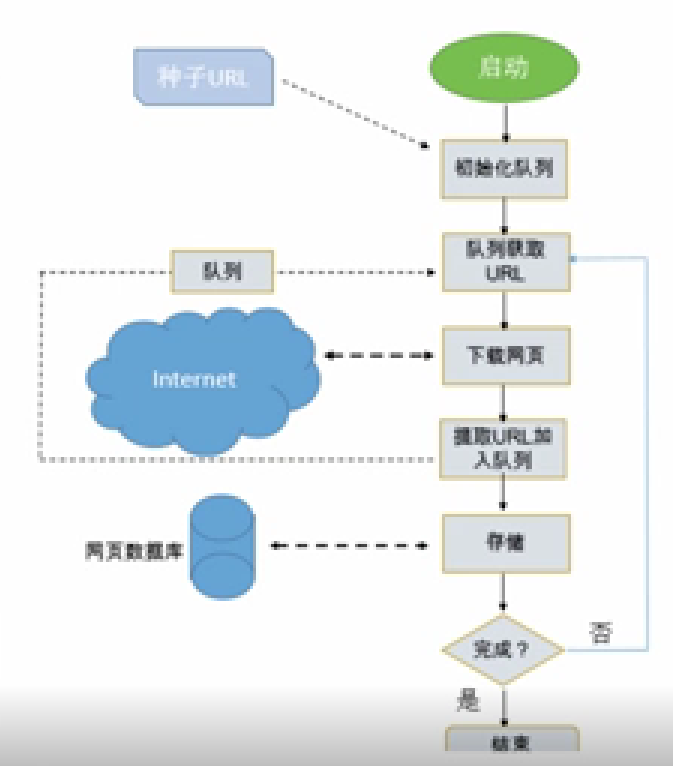
圖片來(lái)源:學(xué)堂在線《大數(shù)據(jù)導(dǎo)論》
審核編輯:劉清
-
傳感器
+關(guān)注
關(guān)注
2564文章
52668瀏覽量
764271 -
數(shù)據(jù)采集
+關(guān)注
關(guān)注
40文章
7000瀏覽量
115842 -
ERP
+關(guān)注
關(guān)注
0文章
551瀏覽量
34853 -
POS
+關(guān)注
關(guān)注
3文章
120瀏覽量
28617
原文標(biāo)題:大數(shù)據(jù)相關(guān)介紹(12)——數(shù)據(jù)采集(上)
文章出處:【微信號(hào):行業(yè)學(xué)習(xí)與研究,微信公眾號(hào):行業(yè)學(xué)習(xí)與研究】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于USB數(shù)據(jù)采集系統(tǒng)的研究與設(shè)計(jì)--ResearchandDesignofDataAequisitio
什么是數(shù)據(jù)采集?
SMT行業(yè)數(shù)據(jù)采集技術(shù)
常見(jiàn)的幾種不同的高速數(shù)據(jù)采集存儲(chǔ)系統(tǒng)介紹
淺談幾種主流數(shù)控機(jī)床的數(shù)據(jù)采集技術(shù)分享
基于PDA的核數(shù)據(jù)采集系統(tǒng)的研究
基于PDA的核數(shù)據(jù)采集系統(tǒng)的研究
工業(yè)數(shù)據(jù)采集類(lèi)型與數(shù)據(jù)采集的方法
數(shù)據(jù)采集技巧和技術(shù)
數(shù)據(jù)采集網(wǎng)關(guān)怎么采集數(shù)據(jù)?
如何采集工業(yè)設(shè)備數(shù)據(jù)?工業(yè)數(shù)據(jù)采集的方法有哪些?

數(shù)據(jù)采集的方法有哪些
AI數(shù)據(jù)采集標(biāo)注類(lèi)型:揭秘數(shù)據(jù)采集與標(biāo)注的關(guān)鍵環(huán)節(jié)
數(shù)據(jù)采集網(wǎng)關(guān):工業(yè)數(shù)據(jù)采集上云






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論