 AIGC可編輯的圖像生成方案
AIGC可編輯的圖像生成方案
ControlNet給出的實驗結果實在是過于驚艷了,近期視覺領域最讓人興奮的工作。可編輯圖像生成領域異常火熱,看了一些相關文章,選出幾篇感興趣的文章記錄一下。
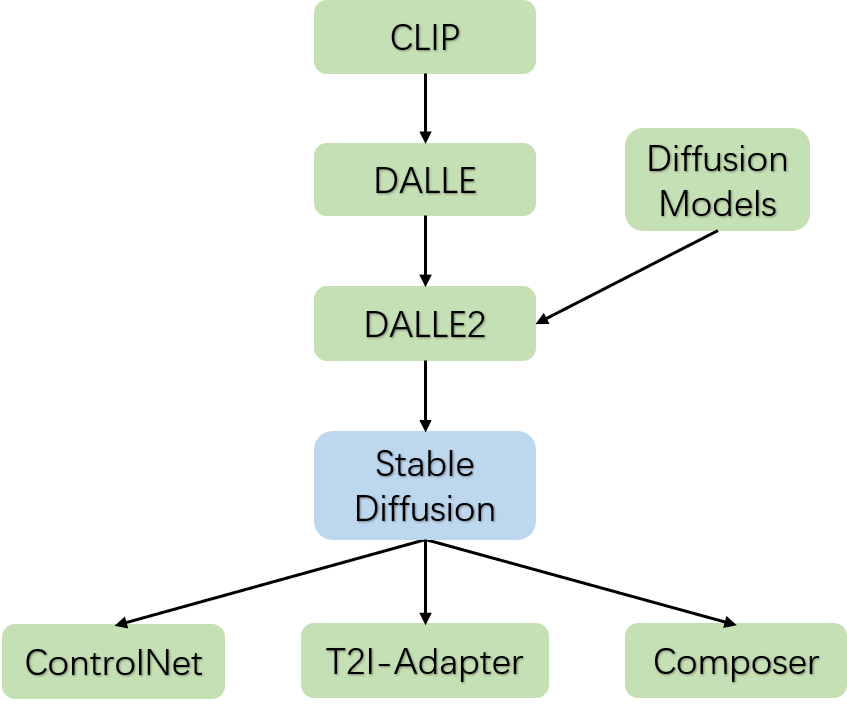
從CLIP模型開始,OpenAI走通了大規模圖文對預訓練模型的技術路徑,這代表著文字域和圖片域是可以很好的對齊;緊隨其后,OpenAI在CLIP的技術基礎上,發布了DALLE文字生成圖片的模型,生成圖片的質量遠超之前的模型,這主要得益于大規模圖文對預訓練的CLIP模型;
與此同時,Diffusion Models的圖像生成方法的圖像生成質量也超越了以往的GAN、VAE等模型,并且隨著算法的精進,推理速度不斷加快,預示著Diffusion Models即將全面替代GAN、VAE等生成模型;果不其然,OpenAI將DALLE模型和Diffusion Models結合發布了DALLE2模型,生成圖片的質量進一步提高。
在DALLE2這個階段,雖然圖像生成質量相比以往有了質變,但是圖像生成的過程是不可控,這導致各種繪畫設計行業無法在工作中使用,況且DALLE2還沒有開源。隨著Stable Diffusion模型的發布和開源,可編輯圖像生成領域變得空前火熱,出現了各種各樣DIY的產物,Stable Diffusion模型算是一個關鍵的時間節點。
而在2023年2月份大概1周之內同時涌現出了ControlNet、T2I-Adapter和Composer三個基于Stable Diffusion的可編輯圖像生成模型,其中ControlNet再一次帶熱了AI繪畫設計。
下面主要介紹一下Stable Diffusion、ControlNet、T2I-Adapter和Composer四篇文章,最后談談圖像結構化和圖像生成之間的關系。
Stable Diffusion
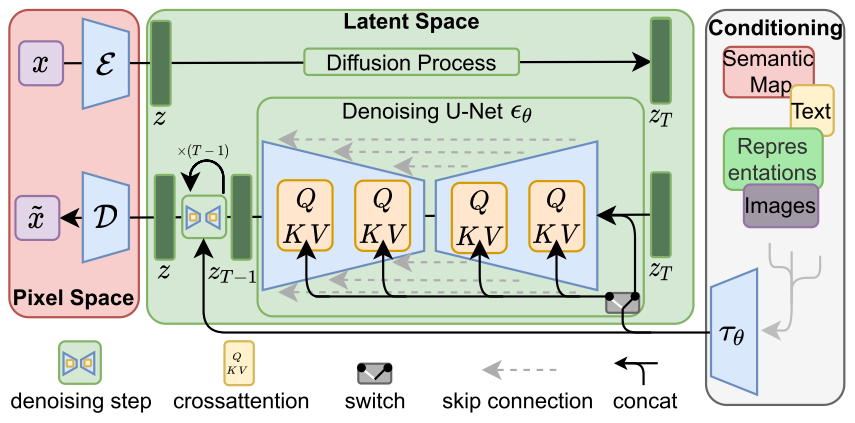
Stable Diffusion模型在Diffusion Models(DM)的基礎上,增加了conditioning機制。
通過conditioning機制,可以將semantic map、text、representations和images等信息傳遞到DM模型中,通過cross-attention機制進行信息的融合,通過多個step進行擴散生成圖片。


如上面兩個結果圖所示,Stable Diffusion可以通過版面結構圖或者語義分割圖來控制圖像的生成。
ControlNet
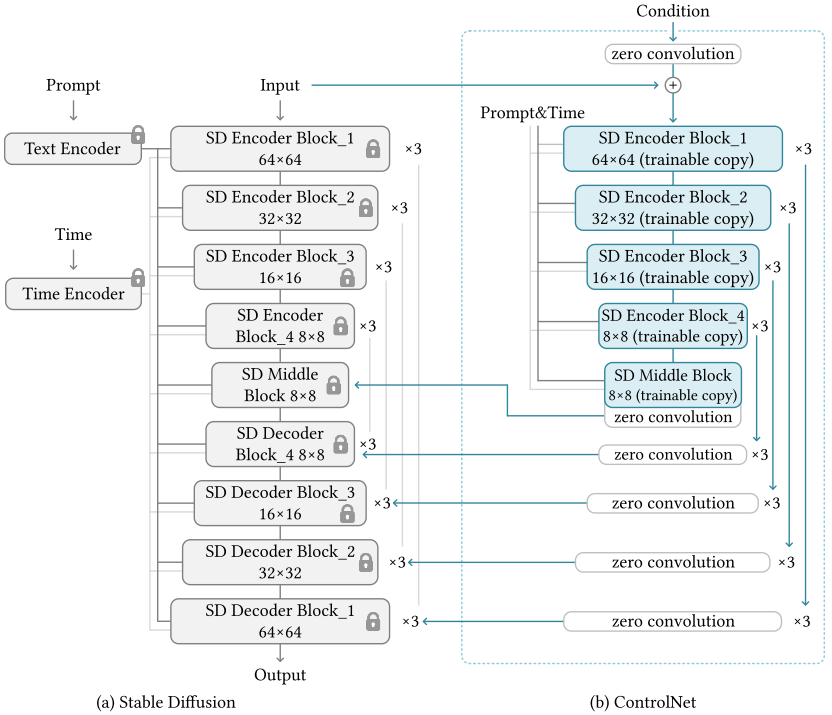
ControlNet在Stable Diffusion(SD)的基礎上,鎖住SD的參數,并且增加了一個可學習的分支,該分支的開頭和結尾都增加zero convolution(初始化參數為0),保證訓練的穩定性,并且Condition的特征會疊加回SD的Decoder特征上,進而達到控制圖像生成的目的。
相比于SD模型,ControlNet有兩點區別:
ControlNet相比于SD,豐富了Condition的種類,總共9大類,包括Canny Edge、Canny Edge(Alter)、Hough Line、HED Boundary、User Sketching、Human Pose(Openpifpaf)、Human Pose(Openpose)、Semantic Segmentation(COCO)、Semantic Segmentation(ADE20K)、Depth(large-scale)、Depth(small-scale)、Normal Maps、Normal Maps(extended)和Cartoon Line Drawing。
ControlNet不需要重新訓練SD模型,這極大的降低了可編輯圖像生成領域的門檻,減少二次開發的成本。

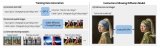
從上圖可以看到,ControlNet可以先提取出動物的Canny edge,然后再在Canny edge的基礎上渲染出不同風格環境色彩的動物圖片,amazing!





上圖是一些ControlNet圖像生成的例子,更多的例子可以閱讀原文。
T2I-Adapter
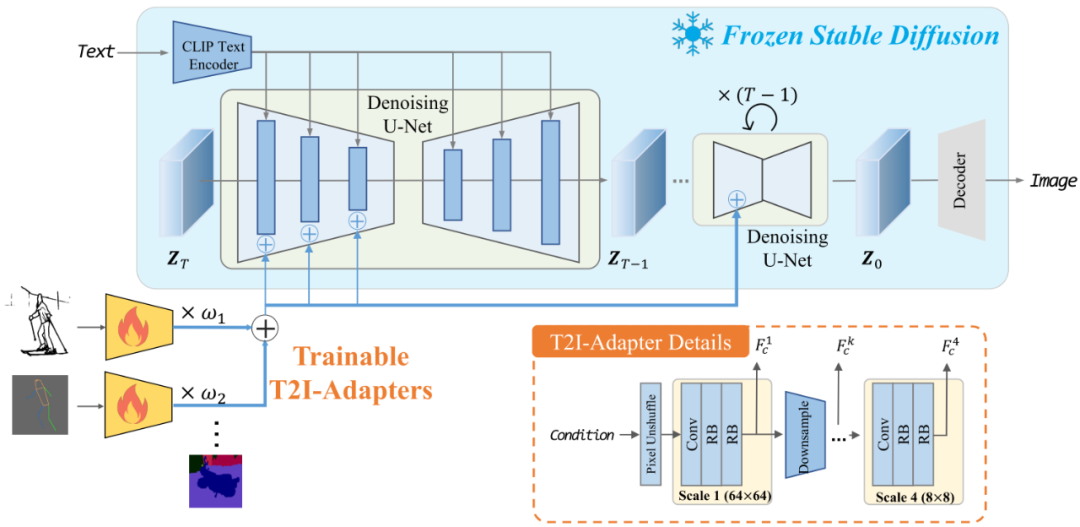
T2I-Adapter跟ControlNet非常類似,主要不同有以下幾點區別:
T2I-Adapter可以同時組合輸入多種類型的Condition
T2I-Adapter是從SD的Encoder部分傳入Condition的
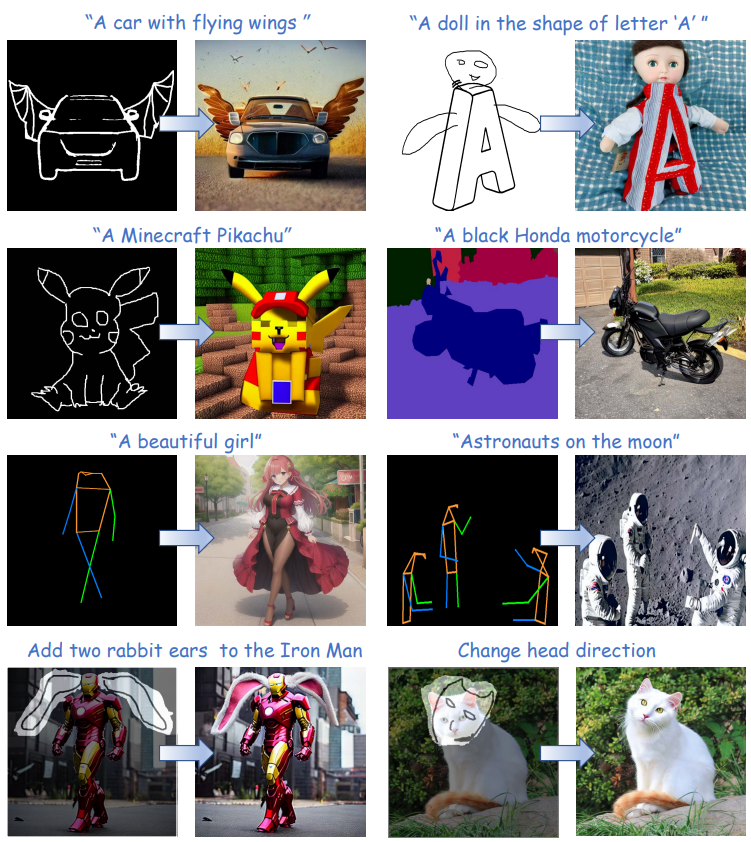
可以看到T2I-Adapter生成的圖像有著類似ControlNe的可編輯效果。
Composer
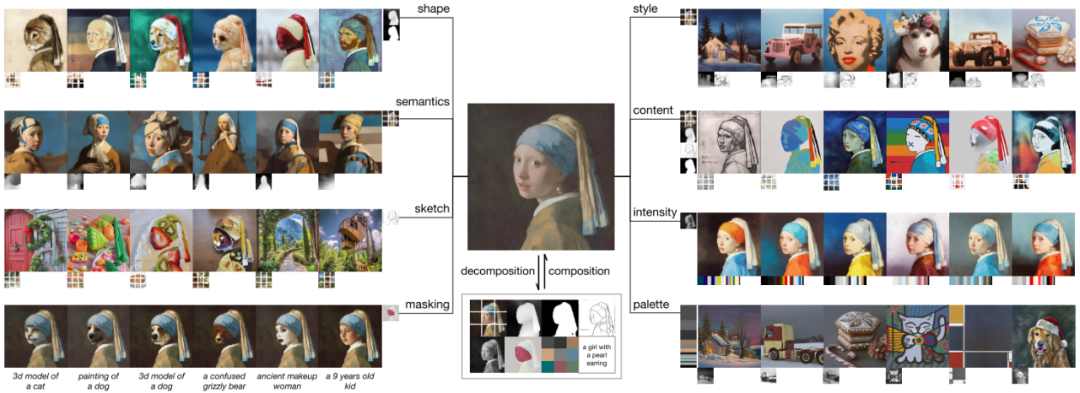
Composer跟ControlNet和T2I-Adapter的思路也是類似的,但是Composer提出了一個有意思的點,就是可編輯圖像生成其實就是對圖像各種元素的組合,Composer先用各種不同的模型將各種不同的圖片分解成各種元素,然后將不同圖片的元素進行重組。比如上圖的戴珍珠耳環的少女,可以分解成shape、semantics、sketch、masking、style、content、intensity、palette、文字等等元素,然后跟其他不同圖片的元素進行想要的重組。
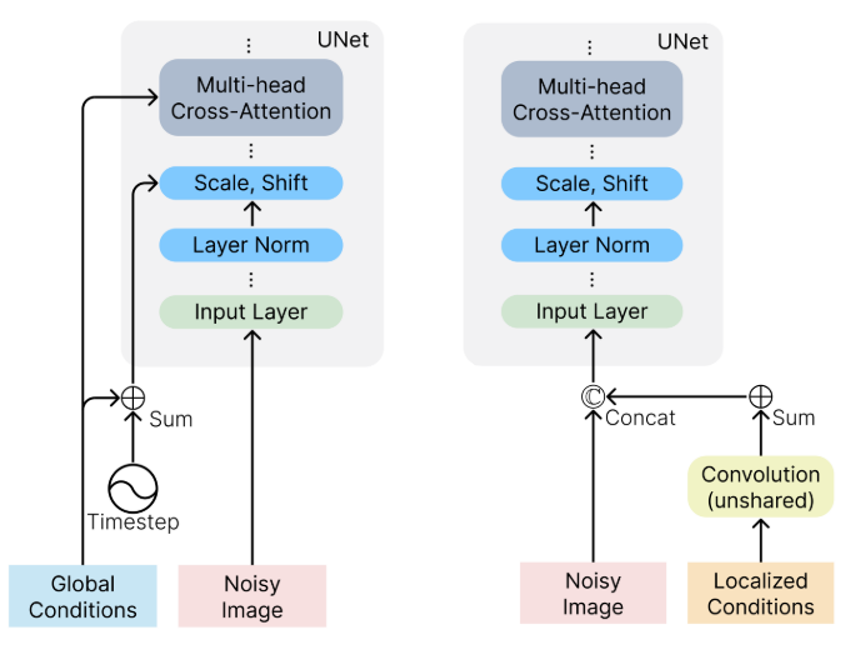
Composer將各種元素區分成兩類,一類是Global Conditions,另一類是Localized Conditions。其中Global Conditions包括sentence embeddings, image embeddings, and color histograms,并且需要添加到Timestep中;Localized Conditions包括segmentation maps, depthmaps, sketches, grayscale images, and masked images,并且需要添加到Noisy Image中。


上面圖像生成的結果,充分表現出了Composer模型可編輯的多樣性和豐富性。
圖像結構化和圖像生成
我在這里將圖像檢測、圖像分割、深度估計等任務統稱為圖像結構化。從某種意義上來說,圖像結構化其實可以認為是一種特殊的圖像生成,只不過生成的圖片是某個單一維度的特征,比如是深度圖、mask圖、關鍵點圖等等。ControlNet和Composer某種意義上就是將結構化圖片通過文字控制來豐富細節進而生成想要的圖片;而圖像結構化其實就是把維度復雜、細節豐富的圖片生成維度單一、細節簡單的結構化圖片。
圖像結構化和圖像生成其實也就是對應著Composer文章里面提到的分解和合成兩個過程。我對于可編輯圖像生成領域未來的想法是,盡可能準確豐富的提取圖像中各個維度的結構化信息(包括文字信息),然后通過Stable Diffusion模型組合融入想要的結構化信息,進而達到完全自主可控的圖像生成。
總結
可編輯的圖像生成其實蘊含著人機交互的思想,人的意志通過輸入的文字提示和圖片提示傳遞給模型,而模型(或者說是機器)生成的圖片恰好反映出了人的思想。可編輯圖像生成會改變繪畫設計等領域的創作模式(比如公仔服裝周邊等等,可以無限壓縮設計繪畫的時間),進而孕育出新的更有活力的創業公司,互聯網行業可能會迎來第二增長曲線。
審核編輯:劉清
-
Clip
+關注
關注
0文章
32瀏覽量
6924 -
GaN器件
+關注
關注
1文章
44瀏覽量
8015 -
OpenAI
+關注
關注
9文章
1194瀏覽量
7840 -
AIGC
+關注
關注
1文章
380瀏覽量
2031
原文標題:AIGC—可編輯的圖像生成
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于擴散模型的圖像生成過程

#新年新氣象,大家新年快樂!#AIGC入門及鴻蒙入門
RTthread移植代碼自動生成方案
一種全新的遙感圖像描述生成方法

基于模板、檢索和深度學習的圖像描述生成方法
GAN圖像對抗樣本生成方法研究綜述

AIGC最新綜述:從GAN到ChatGPT的AI生成歷史
伯克利AI實驗室開源圖像編輯模型InstructPix2Pix,簡化生成圖像編輯并提供一致結果





 工商網監
工商網監
評論