") GAN原理與應(yīng)用入門
GAN原理與應(yīng)用入門

生成對(duì)抗網(wǎng)絡(luò)(GAN)是一類在無(wú)監(jiān)督學(xué)習(xí)中使用的神經(jīng)網(wǎng)絡(luò),其有助于解決按文本生成圖像、提高圖片分辨率、藥物匹配、檢索特定模式的圖片等任務(wù)。Statsbot 小組邀請(qǐng)數(shù)據(jù)科學(xué)家 Anton Karazeev 通過(guò)日常生活實(shí)例深入淺出地介紹 GAN 原理及其應(yīng)用。
生成對(duì)抗網(wǎng)絡(luò)由 Ian Goodfellow 于 2014 年提出。GAN 不是神經(jīng)網(wǎng)絡(luò)應(yīng)用在無(wú)監(jiān)督學(xué)習(xí)中的唯一途徑,還有玻爾茲曼機(jī)(Geoffrey Hinton 和 Terry Sejnowski,1985)和自動(dòng)解碼器(Dana H. Ballard,1987)。三者皆致力于通過(guò)學(xué)習(xí)恒等函數(shù) f(x)= x 從數(shù)據(jù)中提取特征,且都依賴馬爾可夫鏈來(lái)訓(xùn)練或生成樣本。
GAN 設(shè)計(jì)之初衷就是避免使用馬爾可夫鏈,因?yàn)楹笳叩挠?jì)算成本很高。相對(duì)于玻爾茲曼機(jī)的另一個(gè)優(yōu)點(diǎn)是 GAN 的限制要少得多(只有幾個(gè)概率分布適用于馬爾可夫鏈抽樣)。
在本文中,我們將講述 GAN 的基本原理及最流行的現(xiàn)實(shí)應(yīng)用。
GAN 原理
讓我們用一個(gè)比喻解釋 GAN 的原理吧。
假設(shè)你想買塊好表。但是從未買過(guò)表的你很可能難辨真假;買表的經(jīng)驗(yàn)可以免被奸商欺騙。當(dāng)你開(kāi)始將大多數(shù)手表標(biāo)記為假表(當(dāng)然是被騙之后),賣家將開(kāi)始「生產(chǎn)」更逼真的山寨表。這個(gè)例子形象地解釋了 GAN 的基本原理:判別器網(wǎng)絡(luò)(手表買家)和生成器網(wǎng)絡(luò)(生產(chǎn)假表的賣家)。
兩個(gè)網(wǎng)絡(luò)相互博弈。GAN 允許生成逼真的物體(例如圖像)。生成器出于壓力被迫生成看似真實(shí)的樣本,判別器學(xué)習(xí)分辨生成樣本和真實(shí)樣本。
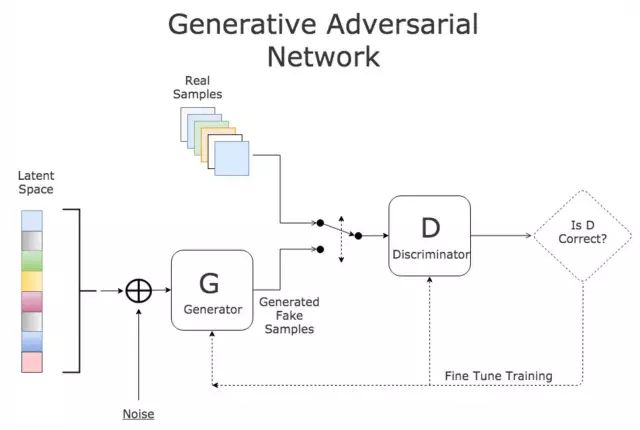
判別算法和生成算法有何不同?簡(jiǎn)單地說(shuō):判別算法學(xué)習(xí)類之間的邊界(如判別器做的那樣),而生成算法學(xué)習(xí)類的分布(如生成器做的那樣)。
如果你準(zhǔn)備深入了解 GAN
想要學(xué)習(xí)生成器的分布,應(yīng)該定義數(shù)據(jù) x 的參數(shù) p_g,以及輸入噪聲變量 p_z(z)的分布。然后 G(z,θ_g)將 z 從潛在空間 Z 映射到數(shù)據(jù)空間,D(x,θ_d)輸出單個(gè)標(biāo)量——一個(gè) x 來(lái)自真實(shí)數(shù)據(jù)而不是 p_g 的概率。
訓(xùn)練判別器以最大化正確標(biāo)注實(shí)際數(shù)據(jù)和生成樣本的概率。訓(xùn)練生成器用于最小化 log(1-D(G(z)))。換句話說(shuō),盡量減少判別器得出正確答案的概率。
可以將這樣的訓(xùn)練任務(wù)看作具有值函數(shù) V(G,D)的極大極小博弈:

換句話說(shuō),生成器努力生成判別器難以辨認(rèn)的圖像,判別器也愈加聰明,以免被生成器欺騙。
「對(duì)抗訓(xùn)練是繼切片面包之后最酷的事情。」- Yann LeCun
當(dāng)判別器不能區(qū)分 p_g 和 p_data,即 D(x,θ_d)= 1/2 時(shí),訓(xùn)練過(guò)程停止。達(dá)成生成器與判別器之間判定誤差的平衡。
歷史檔案圖像檢索
一個(gè)有趣的 GAN 應(yīng)用實(shí)例是在「Prize Papers」中檢索相似標(biāo)記,Prize Papers 是海洋史上最具價(jià)值的檔案之一。對(duì)抗網(wǎng)絡(luò)使得處理這些具有歷史意義的文件更加容易,這些文件還包括海上扣留船只是否合法的信息。

每個(gè)查詢到的記錄都包含商家標(biāo)記的樣例——商家屬性的唯一標(biāo)識(shí),類似于象形文字的草圖樣符號(hào)。
我們應(yīng)該獲得每個(gè)標(biāo)記的特征表示,但是應(yīng)用常規(guī)機(jī)器學(xué)習(xí)和深度學(xué)習(xí)方法(包括卷積神經(jīng)網(wǎng)絡(luò))存在一些問(wèn)題:
- 它們需要大量標(biāo)注圖像;
- 商標(biāo)沒(méi)有標(biāo)注;
- 標(biāo)記無(wú)法從數(shù)據(jù)集分割出去。
這種新方法顯示了如何使用 GAN 從商標(biāo)的圖像中提取和學(xué)習(xí)特征。在學(xué)習(xí)每個(gè)標(biāo)記的表征之后,就可以在掃描文檔上按圖形搜索。
將文本翻譯成圖像
其他研究人員表明,使用自然語(yǔ)言的描述屬性生成相應(yīng)的圖像是可行的。文本轉(zhuǎn)換成圖像的方法可以說(shuō)明生成模型模擬真實(shí)數(shù)據(jù)樣本的性能。
圖片生成的主要問(wèn)題在于圖像分布是多模態(tài)的。例如,有太多的例子完美契合文本描述的內(nèi)容。GAN 有助于解決這一問(wèn)題。

我們來(lái)考慮以下任務(wù):將藍(lán)色輸入點(diǎn)映射到綠色輸出點(diǎn)(綠點(diǎn)可能是藍(lán)點(diǎn)的輸出)。這個(gè)紅色箭頭表示預(yù)測(cè)的誤差,也意味著經(jīng)過(guò)一段時(shí)間后,藍(lán)點(diǎn)將被映射到綠點(diǎn)的平均值——這一精確映射將會(huì)模糊我們?cè)噲D預(yù)測(cè)的圖像。
GAN 不直接使用輸入和輸出對(duì)。相反,它們學(xué)習(xí)如何給輸入和輸出配對(duì)。
下面是從文本描述中生成圖像的示例:

用于訓(xùn)練 GAN 的數(shù)據(jù)集:
- Caltech-UCSD-200-2011 是一個(gè)具有 200 種鳥(niǎo)類照片、總數(shù)為 11,788 的圖像數(shù)據(jù)集。
- Oxford-102 花數(shù)據(jù)集由 102 個(gè)花的類別組成,每個(gè)類別包含 40 到 258 張圖片不等。
藥物匹配
當(dāng)其它研究員應(yīng)用 GAN 處理圖片和視頻時(shí),Insilico Medicine 的研究人員提出了一種運(yùn)用 GAN 進(jìn)行藥物匹配的方法。
我們的目標(biāo)是訓(xùn)練生成器,以盡可能精確地從一個(gè)藥物數(shù)據(jù)庫(kù)中對(duì)現(xiàn)有藥物進(jìn)行按病取藥的操作。
經(jīng)過(guò)訓(xùn)練后,可以使用生成器獲得一種以前不可治愈的疾病的藥方,并使用判別器確定生成的藥方是否治愈了特定疾病。
腫瘤分子生物學(xué)的應(yīng)用
Insilico Medicine 另一個(gè)研究表明,產(chǎn)生一組按參數(shù)定義的新抗癌分子的管道。其目的是預(yù)測(cè)具有抗癌作用的藥物反應(yīng)和化合物。
研究人員提出了一個(gè)基于現(xiàn)有生化數(shù)據(jù)的用于識(shí)別和生成新化合物的對(duì)抗自編碼器(AAE)模型。

「據(jù)我們所知,這是 GAN 技術(shù)在挖掘癌癥藥物領(lǐng)域的首個(gè)應(yīng)用。」- 研究人員說(shuō)。
數(shù)據(jù)庫(kù)中有許多可用的生物化學(xué)數(shù)據(jù),如癌細(xì)胞系百科全書(shū)(CCLE)、腫瘤藥物敏感基因?qū)W(GDSC)和 NCI-60 癌細(xì)胞系。所有這些都包含針對(duì)癌癥的不同藥物實(shí)驗(yàn)的篩選數(shù)據(jù)。

對(duì)抗自編碼器以藥物濃度和指紋作為輸入并使用生長(zhǎng)抑制率數(shù)據(jù)進(jìn)行訓(xùn)練(GI,顯示治療后癌細(xì)胞的數(shù)量減少情況)。
分子指紋在計(jì)算機(jī)中有一個(gè)固定的位數(shù)表示,每一位代表某些特征的保留狀態(tài)。

隱藏層由 5 個(gè)神經(jīng)元組成,其中一個(gè)負(fù)責(zé) GI(癌細(xì)胞抑制率),另外 4 個(gè)由正態(tài)分布判別。因此,一個(gè)回歸項(xiàng)被添加到編碼器代價(jià)函數(shù)中。此外,編碼器只能將相同的指紋映射到相同的潛在向量,這一過(guò)程獨(dú)立于通過(guò)額外的流形代價(jià)集中輸入。

經(jīng)過(guò)訓(xùn)練,網(wǎng)絡(luò)可以從期望的分布中生成分子,并使用 GI 神經(jīng)元作為輸出化合物的微調(diào)器。
這項(xiàng)工作的成果如下:已訓(xùn)練 AAE 模型預(yù)測(cè)得到的化合物已被證明是抗癌藥物,和需接受抗癌活性化合物實(shí)驗(yàn)驗(yàn)證的新藥物。
「我們的研究結(jié)果表明,本文提出的 AAE 模型使用深度生成模型顯著提高了特定抗癌能力和新分子的開(kāi)發(fā)效率。」
結(jié)論
無(wú)監(jiān)督學(xué)習(xí)是人工智能的下一個(gè)藍(lán)海,我們正朝著這一方向邁進(jìn)。
生成對(duì)抗網(wǎng)絡(luò)可以應(yīng)用于許多領(lǐng)域,從生成圖像到預(yù)測(cè)藥物,所以不要害怕失敗。我們相信 GAN 有助于建立一個(gè)更好的機(jī)器學(xué)習(xí)的未來(lái)。
原文鏈接:https://blog.statsbot.co/generative-adversarial-networks-gans-engine-and-applications-f96291965b47
-
解碼器
+關(guān)注
關(guān)注
9文章
1173瀏覽量
41952 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103543
發(fā)布評(píng)論請(qǐng)先 登錄
深入淺出學(xué)人工智能神經(jīng)網(wǎng)絡(luò):GAN原理與應(yīng)用入門介紹
GaN可靠性的測(cè)試
未找到GaN器件
基于GaN的開(kāi)關(guān)器件
如何精確高效的完成GaN PA中的I-V曲線設(shè)計(jì)?
為什么GaN會(huì)在射頻應(yīng)用中脫穎而出?
圖像生成對(duì)抗生成網(wǎng)絡(luò)gan_GAN生成汽車圖像 精選資料推薦
GaN和SiC區(qū)別
如何實(shí)現(xiàn)高效GaN的電源設(shè)計(jì)

萬(wàn)丈高樓平地起—GAN入門介紹
GaN HEMT 模型初階入門:非線性模型如何幫助進(jìn)行 GaN PA 設(shè)計(jì)?(第一部分,共兩部分)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論