 OpenVINO? 中用于推理優化的自適應參數選擇功能介紹
OpenVINO? 中用于推理優化的自適應參數選擇功能介紹
本文簡介
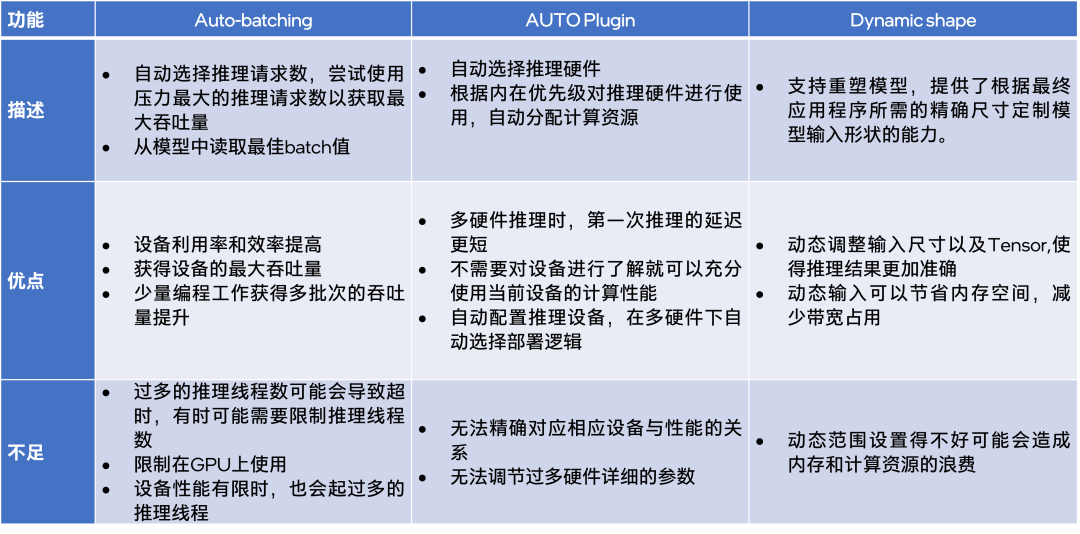
當你使用 AI 模型進行推理時,往往需要設置一些參數與選項,相應地,OpenVINO 工具套件為此提供了一些自動設定參數選項的功能。本文主要介紹 OpenVINO中與模型推理相關的3個功能,它們分別是:
用于 input 數據足夠多時,提供最大 throughput 的 Auto-batching 功能;
用于自動選擇設備進行推理的 Auto Plugin 功能;
以及用于滿足特定模型動態輸入的 Dynamic Shape 功能。
本文將逐一介紹這三個實用的功能,并在文末給出這三功能的優缺點總結對比。
功能介紹
Auto-batching
Auto-batching 設計目的是讓開發者利用最少的代碼去實現使用英特爾顯卡做模型推理的數據吞吐量最大化。在沒有設定 input 以及沒有限制范圍的情況下,它會按照集成顯卡或者是獨立顯卡能承受的最大吞吐量去設定推理線程數。如果應用程序有大量的輸入數據且以高頻率連續提交推理請求,推薦使用 Auto-batching 功能。
該功能通過幾行代碼實現了最多推理線程的響應,同時也不會對原先的示例代碼造成影響。如果在推理設備設置中,將“device“參數設置為:“BATCH:GPU“ 該功能將會被激活。例如,在 benchmark_app 應用使用 Auto-batching 的方式如下:
$benchmark_app -hint none -d BATCH:GPU -m ‘path to your favorite model’
向右滑動查看完整代碼
另外一種方法是:在 GPU 推理時,選擇性能模式為”THROUGHPUT”,該功能將會被自動觸發。所以在示例代碼中添加如下兩行,即可在 GPU 進行推理時,啟動 Auto-batching 功能:
config = {"PERFORMANCE_HINT": "THROUGHPUT"} compiled_model = core.compile_model(model, "GPU", config)
向右滑動查看完整代碼
無論是通過設置 BATCH:GPU,還是選擇”THROUGHPUT”的推理模式,推理的 batch size 值都會自動進行選取。選取的方式是查詢當前設備的 ov::optimal_batch_size 屬性并且通過模型拓撲結構的輸入端獲取 batch size 的值作為模型推理的 batch size 值。
接下來,是使用 Benchmark APP 做的對比實驗:
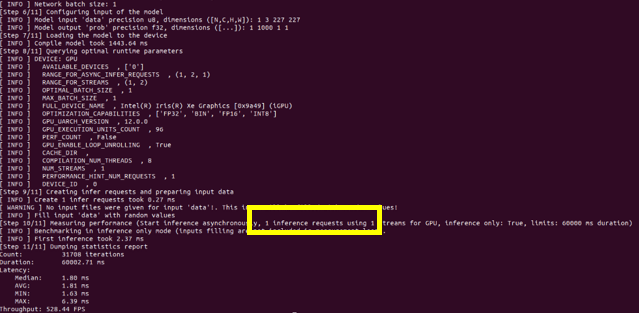
圖1:Disable Auto-batching
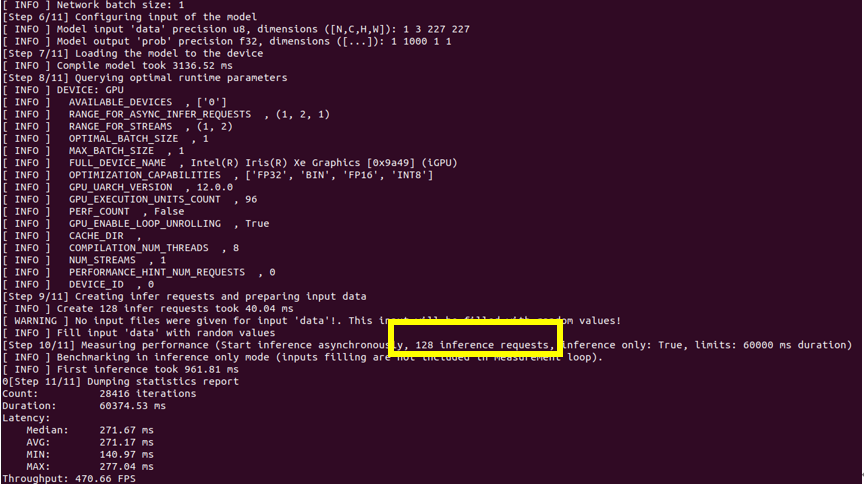
圖2:Enable Auto-batching
通過對比 Auto-batching 功能開閉的推理結果圖,可以看到當此功能開啟的時候:即使推理設備選擇的是集成顯卡,推理線程數仍舊被推上了128個,說明此功能確實會嘗試使用當前狀態下壓力最大的推理線程數,來達到推理最大的吞吐量。但是結果是當推理性能有限的集成顯卡啟動了128個線程的時候,整體的 throughput 的數值比單推理線程的 throughput 要低一些,所以當硬件推理性能有限時,需要對推理線程數進行限定。同樣,在 Auto-batching 中限定推理線程有兩種方式分別為,設置 BATCH: GPU (4)或設置 ov::num_requests 參數可以將推理線程設為4:
auto compiled_model = core.compile_model(model, "GPU", ov::THROUGHPUT), ov::num_requests(4));
向右滑動查看完整代碼
Auto-batching 中內置了 Auto_batch_timeout 參數,該參數用于監測輸入數據送達的時延,初始值為1000,表示若1000毫秒后無數據輸入則提示推理超時。注意,如果推理頻率較低,或者根據 Auto_batch_timeout 參數發現推理超時,可以手動關閉 Auto-batching:
// disabling the automatic batching auto compiled_model = core.compile_model(model, "GPU", ov::THROUGHPUT), ov::allow_auto_batching(false));
向右滑動查看完整代碼
AUTO Plugin
在 OpenVINO 工具套件的推理插件(Plugin)選擇上,除了常規的 CPU,iGPU,Myriad,您還可以選擇使用 AUTO Plugin。開發者通過它快速部署 AI 示例用于實驗,且不用考慮推理設備的選擇就能獲得一個不錯的推理性能。不需要指定設備,它會自動配置推理硬件,當有多個設備時,它也會自動聯合調用多個硬件進行推理。
AUTO Plugin 的工作流程是:首先,檢測當前環境下所有的可用設備,之后根據預制的硬件選擇規則,選擇相應的推理設備,并且優化推理的整體配置,最后執行 AI 推理。AUTO Plugin 對于推理設備選擇遵循以下的規則:
dGPU (e.g. Intel Iris Xe MAX) ->
iGPU (e.g. Intel UHD Graphics 620 (iGPU)) ->
Intel Movidius Myriad X VPU(e.g. Intel Neural Compute Stick 2 (Intel NCS2)) ->
Intel CPU (e.g. Intel Core i7-1165G7)
#常規用法: compiled_model = core.compile_model(model=model, device_name="AUTO") #您可以限定設備使用AUTO Plugin: compiled_model = core.compile_model(model=model, device_name="AUTO:GPU,CPU") #您也可以剔除使用AUTO Plugin的設備: compiled_model = core.compile_model(model=model, device_name="AUTO:-CPU")
向右滑動查看完整代碼
AUTO Plugin 內置有三個模式可供選擇:
1.THROUGHPUT
默認模式。該模式優先考慮高吞吐量,在延遲和功率之間進行平衡,最適合于涉及多個任務的推理,例如推理視頻源或大量圖像。注:此模式只會對 CPU 與 GPU 進行調用。若該模式下調用GPU進行推理,將會自動觸發“Auto-batching“功能。
compiled_model = core.compile_model(model=model, device_name="AUTO", config={"PERFORMANCE_HINT":"THROUGHPUT"})
向右滑動查看完整代碼
2.LATENCY
此選項優先考慮低延遲,為每個推理任務提供比較短的響應時間。它對于需要對單個輸入圖像進行推斷的任務(例如超聲掃描圖像的醫學分析)。此外,它還適用于實時或接近實時應用的任務,例如工業機器人對其環境中動作的響應或自動駕駛車輛的避障。注:此模式只會對 CPU 與 GPU 進行調用。
compiled_modecompiled_model = core.compile_model(model=model, device_name="AUTO", config={"PERFORMANCE_HINT":"LATENCY"})compiled_mode = core.compile_model(model, "AUTO", ov:: CUMULATIVE_THROUGHPUT)); l = core.compile_model(model=model, device_name="AUTO", config={"PERFORMANCE_HINT":"LATENCY"})
向右滑動查看完整代碼
3.CUMULATIVE_THROUGHPUT
CUMULTIVE_THROUGHPUT 模式允許同時在多個設備上運行推理以獲得更高的吞吐量。
使用 CUMULTIVE_THROUGHPUT 模式時,AUTO Plugin 將網絡模型加載到候選列表中的所有可用設備,然后根據默認的優先級載入設備運行推理。
compiled_mode = core.compile_model(model, "AUTO", ov:: CUMULATIVE_THROUGHPUT));
向右滑動查看完整代碼
注意:如果指定了沒有任何設備名稱的 AUTO,并且系統有兩個以上的 GPU 設備,則 AUTO 將從設備候選列表中刪除 CPU,以保持 GPU 以滿容量運行。如果指定了設備優先級,AUTO 將根據優先級在設備上運行推理請求。
Dynamic Shape
模型的動態輸入對于某些領域十分重要,比如說在自然語言處理(NLP)中就需要實時對語句進行分割,所以模型的輸入是實時變化的,又比如在圖像識別中,分割塊的形狀大小也會根據目標的大小實時變動。對于分割之后的圖像來說,進行 resize 操作往往會破壞它的特征屬性,導致在后期推理中造成推理準確性降低。動態形狀輸入功能的引入使得一些基于圖像識別的模型,運行結果的準確度提高。使用 Dynamic Shape 功能能夠更好地保留圖像的特征,根據輸入圖像的大小,動態調節模型輸入,最終模型推理的準確率獲得了提升。
在2022.1以前的 OpenVINO 版本中,使用 WPOD-NET (GitHub - sergiomsilva/alpr-unconstrained: License Plate Detection and Recognition in Unconstrained Scenarios):
地址(復制到瀏覽器打開)
https://github.com/sergiomsilva/alpr-unconstrained
模型進行車牌識別,如果出現動態形態輸入的話,在 MO 轉換時就會報錯,必須強制轉成靜態輸入,例如:
python3 $INTEL_OPENVINO_DIR/deployment_tools/model_optimizer/mo_tf. py --data_type=FP32 --saved_model_dir=./data/lpdetector/tf2/models/saved_model/ --model_name=wpod-net -- reverse_input_channels --input_shape [1,416,416,3] -- output_dir=./data/lpdetector/tf2/models/saved_model/FP32_416
向右滑動查看完整代碼
這會導致該模型在特定的例子下識別精度降低:
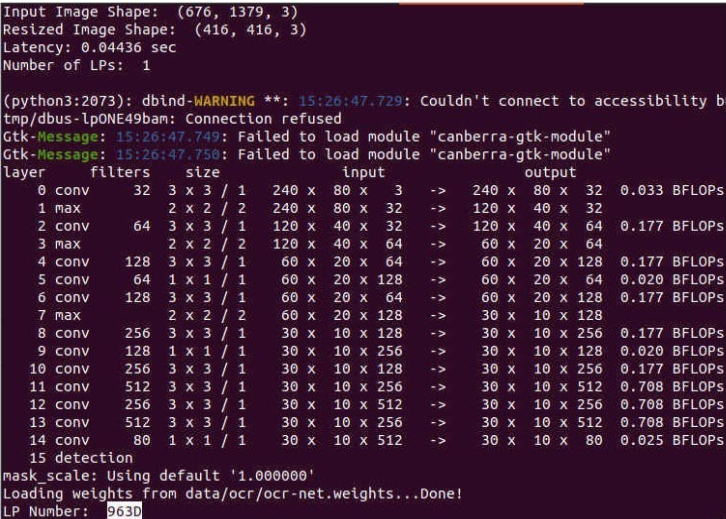

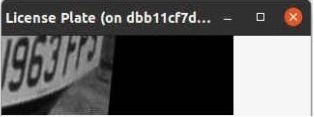
圖例:輸入圖像Resize 為固定尺寸后進行模型推理
由于模型被強制轉成了靜態輸入,可以很明顯的發現輸入的圖像被被強制Resize到了(416,416),圖像分割的錯誤,最后導致了最后車牌識別的結果是不正確的。
在2022.1以后的 OpenVINO 版本中,MO 支持了 Dynamic Shape 的功能,故使用新版本 OpenVINO 工具套件中的模型優化器進行模型轉換:
mo --saved_model_dir ./data/lpdetector/tf2/models/saved_model/ -- output_dir ./data/lpdetector/tf2/models/FP32/
向右滑動查看完整代碼
在生成的 xml 文件中,可以開到 input shape 被識別為動態輸入,動態參數以“?”或“-1”進行顯示:
向右滑動查看完整代碼
使用包含動態輸入的模型進行試驗,實驗結果如下:
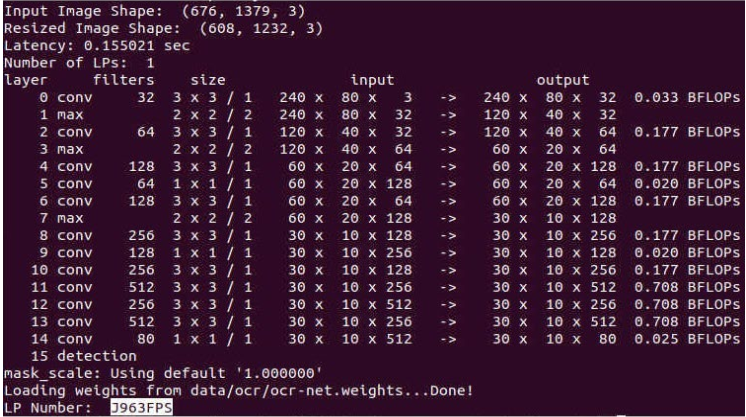


圖例:模型使用動態輸入進行推理
通過 WPOD-NET 的內置算法,計算得到合適的 Resize 長和寬(1232x608),將圖片 Resize 至1232x608,分割到的車牌是清晰完整且最終車牌號碼識別是正確的。
模型的動態輸入在這個例子中顯得十分重要,因為動態輸入的支持使得模型推理識別的精度更加準確了。如果模型優化器沒有識別到模型的動態輸入參數,您可以在代碼中手動指定 Dynamic Shape:
core = ov.Core() model = core.read_model("model.xml") # Set one static dimension (= 1) and another dynamic dimension (= Dimension()) model.reshape([1, ov.Dimension()])
向右滑動查看完整代碼
您也可以指定動態輸入的動態范圍:
# Both dimensions are dynamic, first has a size within 1..10 and the second has a size within 8..512 model.reshape([ov.Dimension(1, 10), ov.Dimension(8, 512)])
向右滑動查看完整代碼
由于您的輸入圖像是動態的,所以說您在初始化 input tensor 的時候,根據需要進行設定,您可以手動對每一個推理 tensor 進行指定:
# Get the tensor, shape is not initialized input_tensor = infer_request.get_input_tensor() # Set shape is required input_tensor.shape = [1, 128] input_tensor.shape = [1, 200]
向右滑動查看完整代碼
當然,也可以通過模型的 input layer 進行指定:
input_tensor = np.expand_dims(image_resized, 0) results = compiled_model.infer_new_request({0: input_tensor})
向右滑動查看完整代碼
總結
針對不同模型推理場景下, Auto-batching 能夠自動給予設備最大壓力達到最大吞吐量;AUTO Plugin 能夠自動選擇推理設備;Dynamic shape 能供根據輸入圖像動態調整模型的 input shape 大小。這些功能都依據開發者的需求,在進行模型推理時,幫助住開發者自動完成相應的配置,對開發 OpenVINO 的示例應用進行輔助。
不過這些功能在使用時,也有一些注意事項需要知曉,請您在使用這些功能之前,了解每個功能的局限性以及每個功能正確的用法。
OpenVINO 工具套件下載地址:
https://www.intel.cn/content/www/cn/zh/developer/tools/openvino-toolkit/download.html
OpenVINO 使用文檔:
https://docs.openvino.ai/latest/
審核編輯 :李倩
-
AI
+關注
關注
88文章
34589瀏覽量
276258 -
模型
+關注
關注
1文章
3500瀏覽量
50137 -
線程
+關注
關注
0文章
507瀏覽量
20112
原文標題:OpenVINO? 中用于推理優化的自適應參數選擇功能介紹 | 開發者實戰
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何在自己的固件中增加wifi自適應性相關功能,以通過wifi自適應認證測試?
為什么無法在運行時C++推理中讀取OpenVINO?模型?
使用Python API在OpenVINO?中創建了用于異步推理的自定義代碼,輸出張量的打印結果會重復,為什么?
自適應逆變電源的設計與實現
基于遺傳優化和模糊推理PID參數及MATLAB仿真
基于反饋的自適應參考幀選擇的率失真優化分析
自適應系統決策:一種模型驅動的方法
基于自適應動態規劃的SVC自適應優化控制策略





 工商網監
工商網監
評論