") 語言模型性能評(píng)估必備下游數(shù)據(jù)集:ZeroCLUE/FewCLUE與Chinese_WPLC數(shù)據(jù)集
語言模型性能評(píng)估必備下游數(shù)據(jù)集:ZeroCLUE/FewCLUE與Chinese_WPLC數(shù)據(jù)集
在大模型開發(fā)過程中,如何利用下游任務(wù)對已有模型進(jìn)行反饋十分重要,這關(guān)系到小模型的快速迭代評(píng)估。例如,為了評(píng)估模型性能,鵬程·盤古α團(tuán)隊(duì)收集了16個(gè)不同類型的中文下游任務(wù),
本文主要介紹ZeroCLUE/FewCLUE數(shù)據(jù)集、中文長下文詞語預(yù)測 (Chinese WPLC)數(shù)據(jù)集幾個(gè)下游任務(wù)數(shù)據(jù)集,供大家參考。
一、ZeroCLUE/FewCLUE數(shù)據(jù)集
零樣本學(xué)習(xí)是AI識(shí)別方法之一。簡單來說就是識(shí)別從未見過的數(shù)據(jù)類別,即訓(xùn)練的分類器不僅僅能夠識(shí)別出訓(xùn)練集中已有的數(shù)據(jù)類別, 還可以對于來自未見過的類別的數(shù)據(jù)進(jìn)行區(qū)分。小樣本學(xué)習(xí)(Few-shot Learning)是解決在極少數(shù)據(jù)情況下的機(jī)器學(xué)習(xí)問題展開的評(píng)測。
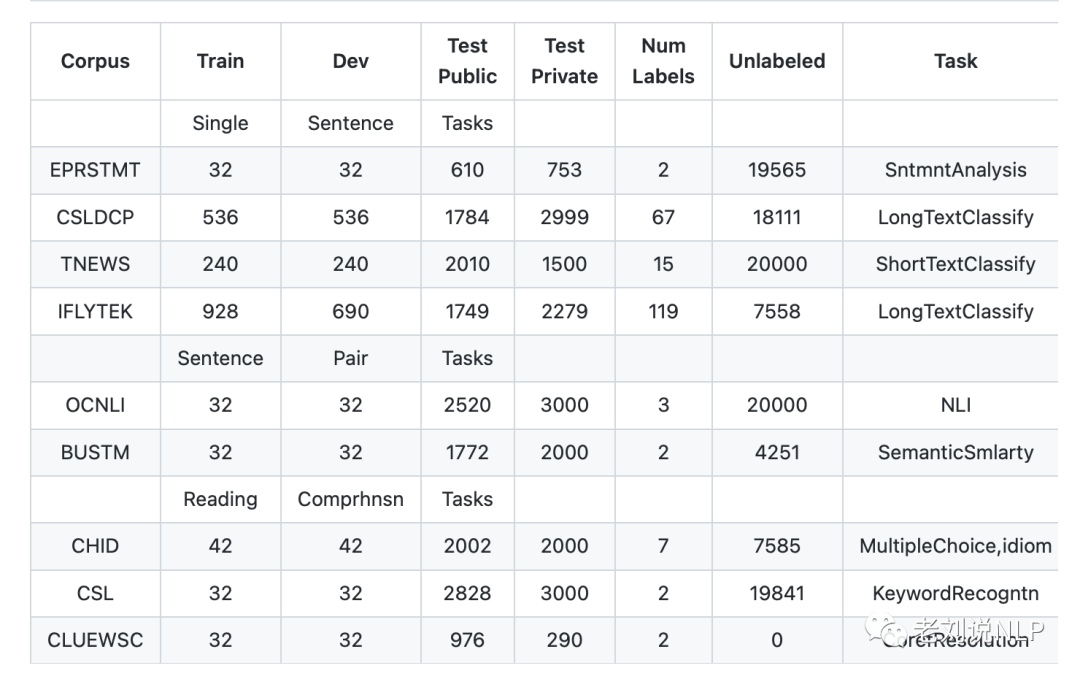
地址:https://github.com/CLUEbenchmark/ZeroCLUE 地址:https://github.com/CLUEbenchmark/FewCLUE
其中:
1、EPRSTMT:電商評(píng)論情感分析
數(shù)據(jù)量:訓(xùn)練集(32),驗(yàn)證集(32),公開測試集(610),測試集(753),無標(biāo)簽語料(19565)
例子:
{"id":23,"sentence":"外包裝上有點(diǎn)磨損,試聽后感覺不錯(cuò)","label":"Positive"}
每一條數(shù)據(jù)有三個(gè)屬性,從前往后分別是 id,sentence,label。其中l(wèi)abel標(biāo)簽,Positive 表示正向,Negative 表示負(fù)向。
2、CSLDCP:科學(xué)文獻(xiàn)學(xué)科分類
中文科學(xué)文獻(xiàn)學(xué)科分類數(shù)據(jù)集,包括67個(gè)類別的文獻(xiàn)類別,這些類別來自于分別歸屬于13個(gè)大類,范圍從社會(huì)科學(xué)到自然科學(xué),文本為文獻(xiàn)的中文摘要。
數(shù)據(jù)量:訓(xùn)練集(536),驗(yàn)證集(536),公開測試集(1784),測試集(2999),無標(biāo)簽語料(67)
例子:
{"content":"通過幾年的觀察和實(shí)踐,初步掌握了盆栽菊花的栽培技術(shù)及方法,并進(jìn)行了總結(jié),以滿足人們對花卉消費(fèi)的需求,提高觀賞植物的商品價(jià)值,為企業(yè)化生產(chǎn)的盆菊提供技術(shù)指導(dǎo)。",
"label":"園藝學(xué)","id":1770}
{"content":"GPS衛(wèi)星導(dǎo)航定位精度的高低很大程度上取決于站星距離(即偽距)的測量誤差.載波相位平滑偽距在保證環(huán)路參數(shù)滿足動(dòng)態(tài)應(yīng)力誤差要求的基礎(chǔ)上。。。本文詳細(xì)論述了載波相位平滑偽距的原理和工程實(shí)現(xiàn)方法,并進(jìn)行了仿真驗(yàn)證.",
"label":"航空宇航科學(xué)與技術(shù)","id":979}
每一條數(shù)據(jù)有三個(gè)屬性,從前往后分別是 id,sentence,label。其中l(wèi)abel標(biāo)簽,Positive 表示正向,Negative 表示負(fù)向。
3、TNEWS:新聞分類
該數(shù)據(jù)集來自今日頭條的新聞版塊,共提取了15個(gè)類別的新聞,包括旅游、教育、金融、軍事等。
例子:
{"label":"102","label_des":"news_entertainment","sentence":"江疏影甜甜圈自拍,迷之角度竟這么好看,美吸引一切事物"}
每一條數(shù)據(jù)有三個(gè)屬性,從前往后分別是分類ID,分類名稱,新聞字符串(僅含標(biāo)題)。
4、IFLYTEK:APP應(yīng)用描述主題分類
該數(shù)據(jù)集關(guān)于app應(yīng)用描述的長文本標(biāo)注數(shù)據(jù),包含和日常生活相關(guān)的各類應(yīng)用主題,共119個(gè)類別:"打車":0,"地圖導(dǎo)航":1,"免費(fèi)WIFI":2,"租車":3,….,"女性":115,"經(jīng)營":116,"收款":117,"其他":118(分別用0-118表示)。
例子:
{"label":"110","label_des":"社區(qū)超市","sentence":"樸樸快送超市創(chuàng)立于2016年,專注于打造移動(dòng)端30分鐘即時(shí)配送一站式購物平臺(tái),商品品類包含水果、蔬菜、肉禽蛋奶、海鮮水產(chǎn)、糧油調(diào)味、酒水飲料、休閑食品、日用品、外賣等。樸樸公司希望能以全新的商業(yè)模式,更高效快捷的倉儲(chǔ)配送模式,致力于成為更快、更好、更多、更省的在線零售平臺(tái),帶給消費(fèi)者更好的消費(fèi)體驗(yàn),同時(shí)推動(dòng)中國食品安全進(jìn)程,成為一家讓社會(huì)尊敬的互聯(lián)網(wǎng)公司。,樸樸一下,又好又快,1.配送時(shí)間提示更加清晰友好2.保障用戶隱私的一些優(yōu)化3.其他提高使用體驗(yàn)的調(diào)整4.修復(fù)了一些已知bug"}
每一條數(shù)據(jù)有三個(gè)屬性,從前往后分別是類別ID,類別名稱,文本內(nèi)容。
5、OCNLI: 自然語言推理
OCNLI,即原生中文自然語言推理數(shù)據(jù)集,是第一個(gè)非翻譯的、使用原生漢語的大型中文自然語言推理數(shù)據(jù)集。
數(shù)據(jù)量:訓(xùn)練集(32),驗(yàn)證集(32),公開測試集(2520),測試集(3000),無標(biāo)簽語料(20000)
例子:
{
"level":"medium",
"sentence1":"身上裹一件工廠發(fā)的棉大衣,手插在袖筒里",
"sentence2":"身上至少一件衣服",
"label":"entailment","label0":"entailment","label1":"entailment","label2":"entailment","label3":"entailment","label4":"entailment",
"genre":"lit","prem_id":"lit_635","id":0
}
6、BUSTM: 對話短文本匹配
對話短文本語義匹配數(shù)據(jù)集,源于小布助手。它是OPPO為品牌手機(jī)和IoT設(shè)備自研的語音助手,為用戶提供便捷對話式服務(wù)。
意圖識(shí)別是對話系統(tǒng)中的一個(gè)核心任務(wù),而對話短文本語義匹配是意圖識(shí)別的主流算法方案之一。要求根據(jù)短文本query-pair,預(yù)測它們是否屬于同一語義。
數(shù)據(jù)量:訓(xùn)練集(32),驗(yàn)證集(32),公開測試集(1772),測試集(2000),無標(biāo)簽語料(4251)
例子:
{"id":5,"sentence1":"女孩子到底是不是你","sentence2":"你不是女孩子嗎","label":"1"}
{"id":18,"sentence1":"小影,你說話慢了","sentence2":"那你說慢一點(diǎn)","label":"0"}
7、CHID:成語閱讀理解
以成語完形填空形式實(shí)現(xiàn),文中多處成語被mask,候選項(xiàng)中包含了近義的成語。https://arxiv.org/abs/1906.01265
數(shù)據(jù)量:訓(xùn)練集(42),驗(yàn)證集(42),公開測試集(2002),測試集(2000),無標(biāo)簽語料(7585)
例子:
{"id":1421,"candidates":["巧言令色","措手不及","風(fēng)流人物","八仙過海","平鋪直敘","草木皆兵","言行一致"],
"content":"當(dāng)廣州憾負(fù)北控,郭士強(qiáng)黯然退場那一刻,CBA季后賽懸念仿佛一下就消失了,可萬萬沒想到,就在時(shí)隔1天后,北控外援約瑟夫-楊因個(gè)人裁決案(拖欠上一家經(jīng)紀(jì)公司的費(fèi)用),
導(dǎo)致被禁賽,打了馬布里一個(gè)#idiom#,加上郭士強(qiáng)帶領(lǐng)廣州神奇逆轉(zhuǎn)天津,讓...","answer":1}
8、CSL:摘要判斷關(guān)鍵詞判別
中文科技文獻(xiàn)數(shù)據(jù)集(CSL)取自中文論文摘要及其關(guān)鍵詞,論文選自部分中文社會(huì)科學(xué)和自然科學(xué)核心期刊,任務(wù)目標(biāo)是根據(jù)摘要判斷關(guān)鍵詞是否全部為真實(shí)關(guān)鍵詞(真實(shí)為1,偽造為0)。
數(shù)據(jù)量:訓(xùn)練集(32),驗(yàn)證集(32),公開測試集(2828),測試集(3000),無標(biāo)簽語料(19841)
例子:
{"id":1,"abst":"為解決傳統(tǒng)均勻FFT波束形成算法引起的3維聲吶成像分辨率降低的問題,該文提出分區(qū)域FFT波束形成算法.遠(yuǎn)場條件下,
以保證成像分辨率為約束條件,以劃分?jǐn)?shù)量最少為目標(biāo),采用遺傳算法作為優(yōu)化手段將成像區(qū)域劃分為多個(gè)區(qū)域.在每個(gè)區(qū)域內(nèi)選取一個(gè)波束方向,
獲得每一個(gè)接收陣元收到該方向回波時(shí)的解調(diào)輸出,以此為原始數(shù)據(jù)在該區(qū)域內(nèi)進(jìn)行傳統(tǒng)均勻FFT波束形成.對FFT計(jì)算過程進(jìn)行優(yōu)化,降低新算法的計(jì)算量,
使其滿足3維成像聲吶實(shí)時(shí)性的要求.仿真與實(shí)驗(yàn)結(jié)果表明,采用分區(qū)域FFT波束形成算法的成像分辨率較傳統(tǒng)均勻FFT波束形成算法有顯著提高,且滿足實(shí)時(shí)性要求.",
"keyword":["水聲學(xué)","FFT","波束形成","3維成像聲吶"],"label":"1"}
每一條數(shù)據(jù)有四個(gè)屬性,從前往后分別是數(shù)據(jù)ID,論文摘要,關(guān)鍵詞,真假標(biāo)簽。
9、CLUEWSC: 代詞消歧
Winograd Scheme Challenge(WSC)是一類代詞消歧的任務(wù),即判斷句子中的代詞指代的是哪個(gè)名詞。題目以真假判別的方式出現(xiàn),如:
句子:這時(shí)候放在[床]上[枕頭]旁邊的[手機(jī)]響了,我感到奇怪,因?yàn)榍焚M(fèi)已被停機(jī)兩個(gè)月,現(xiàn)在[它]突然響了。需要判斷“它”指代的是“床”、“枕頭”,還是“手機(jī)”?
從中國現(xiàn)當(dāng)代作家文學(xué)作品中抽取,再經(jīng)語言專家人工挑選、標(biāo)注。
數(shù)據(jù)量:訓(xùn)練集(32),驗(yàn)證集(32),公開測試集(976),測試集(290),無標(biāo)簽語料(0)
例子:
{"target":
{"span2_index":37,
"span1_index":5,
"span1_text":"床",
"span2_text":"它"},
"idx":261,
"label":"false",
"text":"這時(shí)候放在床上枕頭旁邊的手機(jī)響了,我感到奇怪,因?yàn)榍焚M(fèi)已被停機(jī)兩個(gè)月,現(xiàn)在它突然響了。"}
"true"表示代詞確實(shí)是指代span1_text中的名詞的,"false"代表不是。
二、中文長下文詞語預(yù)測 (Chinese WPLC)數(shù)據(jù)集
Chinese Word Prediction with Long Context (Chinese WPLC) 是天津大學(xué)聯(lián)合鵬城實(shí)驗(yàn)室在小說上建立的依賴長上下文預(yù)測目標(biāo)單詞的中文數(shù)據(jù)集,創(chuàng)建目的是為了評(píng)測模型建模長文本的能力。
數(shù)據(jù)集地址:https://openi.pcl.ac.cn/PCL-Platform.Intelligence/Chinese_WPLC
下面是文獻(xiàn)3網(wǎng)站對該數(shù)據(jù)集的描述:??
該數(shù)據(jù)集在給定前文的條件下,測試機(jī)器預(yù)測目標(biāo)句子最后一個(gè)單詞的能力,選擇的上下文、目標(biāo)句子及待預(yù)測單詞滿足以下條件:當(dāng)給定完整語境時(shí)待預(yù)測單詞很容易被猜測出來,當(dāng)只給最后一個(gè)句子時(shí),難以被猜測出來。我們希望通過這個(gè)數(shù)據(jù)集檢測模型在長上下文上提取信息的能力。例如:
上下文:隨后他立即想到自己為什么如此氣憤——他之所以氣憤,是因?yàn)樗ε铝恕T谒麄€(gè)人處于巨大危險(xiǎn)的情況下,貝思拋棄了他。在海底深處只剩下他們?nèi)齻€(gè)人,他們互相需要——他們得互相依靠。
目標(biāo)句:然而貝思不可信賴,這使他感到害怕,而且
目標(biāo)詞:氣憤
在上述的例子中,目標(biāo)詞 “氣憤“ 能夠通過上下文和目標(biāo)句推測出來,而單靠目標(biāo)句,很難被猜測出來。
1、數(shù)據(jù)采集與構(gòu)建流程
Step1)數(shù)據(jù)收集
Chinese WPLC數(shù)據(jù)集來自網(wǎng)絡(luò)爬取的小說,涵蓋玄幻、言情、武俠、偵探、懸疑等類型,總量超過6萬部。將重復(fù)的小說、公開讀本(世界名著、文學(xué)名著、古典名著等)以及敏感詞比例超5%的小說過濾后,剩余小說按照2:1:1的比例隨機(jī)劃分為訓(xùn)練集、測試集和驗(yàn)證集。
Step2)段落抽取
使用pkuseg對分句后的測試集和驗(yàn)證集小說段落進(jìn)行分詞,以段落最后一句為終點(diǎn)句子,在終點(diǎn)句子之前,往前累計(jì)總詞數(shù)大于50的最少完整句子集合抽取出來作為上下文,并進(jìn)一步將終點(diǎn)句子最后一個(gè)詞作為待預(yù)測單詞,終點(diǎn)句子剩余部分構(gòu)成目標(biāo)句子。上下文、目標(biāo)句子、待預(yù)測單詞共同組成一個(gè)上下文段落。抽取上下文段落需滿足以下條件:
目標(biāo)詞不是停用詞。
目標(biāo)詞在訓(xùn)練集語料中詞頻大于5。
pkuseg、jieba[2]、thulac[3]三種分詞工具切分出來的目標(biāo)詞一致。
目標(biāo)句子包含至少10個(gè)詞。
每本小說最多抽取200個(gè)上下文段落。
僅當(dāng)條件1不滿足時(shí),可將停用詞前一個(gè)詞作為目標(biāo)詞進(jìn)行上述2-5條件檢測,其余情況,將上下文段落拋棄。最終抽取出210萬個(gè)段落。
Step3)段落過濾
為減少數(shù)據(jù)集構(gòu)建時(shí)間,需過濾掉相對簡單的段落。使用以下四種組合生成答案候選:
給定目標(biāo)句子的預(yù)訓(xùn)練NEZHA[4]。
給定目標(biāo)句子的微調(diào)NEZHA。
給定上下文和目標(biāo)句子的預(yù)訓(xùn)練NEZHA。
給定上下文和目標(biāo)句子的微調(diào)NEZHA。
當(dāng)待預(yù)測單詞出現(xiàn)在任一束搜索策略生成的Top-5個(gè)答案候選中時(shí),將該段落拋棄。
為進(jìn)一步減少人工標(biāo)注量,在構(gòu)建數(shù)據(jù)集過程將待預(yù)測單詞困惑度在使用上下文和不使用上下文比值的對數(shù)作為指標(biāo)。優(yōu)先考慮指標(biāo)大于1的段落,由此得到21萬個(gè)段落。
Step4)人工篩選
將Step3剩余段落經(jīng)過隨機(jī)抽樣后通過100+標(biāo)注人員進(jìn)行三輪標(biāo)注:
在給定完整段落(上下文+目標(biāo)句)猜測目標(biāo)詞,猜對后的上下文段落進(jìn)入下一輪。
給不同標(biāo)注人員重復(fù)第一輪。
給定目標(biāo)句讓三個(gè)不同的標(biāo)注人員最多猜9個(gè)詞,如果目標(biāo)詞都沒有被猜到,則將該段落加入Chinese WPLC數(shù)據(jù)集。
第三輪標(biāo)注中標(biāo)注人員每人每個(gè)段落最多猜測3個(gè)詞,以最大限度確保待預(yù)測單詞需通過長上下文信息才能推斷出來,而不能通過單個(gè)句子進(jìn)行推斷。雖然第三輪標(biāo)注能夠確保待預(yù)測單詞不能通過局部信息推斷,但是由于標(biāo)注人員知識(shí)存在差異,該流程不能確保第一輪標(biāo)注段落能被猜對。第二輪標(biāo)注進(jìn)一步確保上下文段落可以被猜對。為減少人工標(biāo)注時(shí)間,在標(biāo)注過程中提示標(biāo)注人員待預(yù)測詞的長度(字?jǐn)?shù))。
2、數(shù)據(jù)統(tǒng)計(jì)分析與樣例
經(jīng)過第一輪后,只有14-17%的數(shù)據(jù)能進(jìn)入下一輪,在第二輪中的數(shù)據(jù)中,有50%-60%的數(shù)據(jù)能進(jìn)入第三輪。在第三輪標(biāo)注中,只有60%的數(shù)據(jù)能夠構(gòu)成最后的Chinese WPLC數(shù)據(jù)集。
1)數(shù)據(jù)統(tǒng)計(jì)
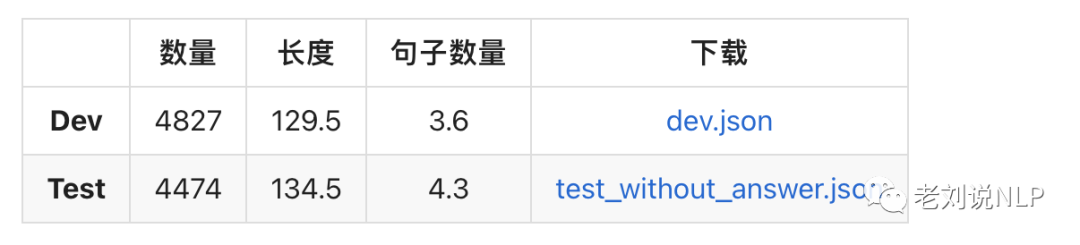
數(shù)據(jù)統(tǒng)計(jì)如表1所示:

Chinese WPLC數(shù)據(jù)集每個(gè)上下文段落平均由3-4個(gè)句子構(gòu)成,平均長度為120個(gè)字,如表2所示:
2)數(shù)據(jù)樣例
數(shù)據(jù)格式可參考下面兩個(gè)樣本數(shù)據(jù),每個(gè)樣本由2個(gè)字段組成,masked_text字段是上下文和目標(biāo)句子,correct_word是位置上正確的詞,數(shù)量代表待預(yù)測單詞字?jǐn)?shù)。
{
"masked_text":"隨后他立即想到自己為什么如此氣憤——他之所以氣憤,是因?yàn)樗ε铝恕T谒麄€(gè)人處于巨大危險(xiǎn)的情況下,貝思拋棄了他。在海底深處只剩下他們?nèi)齻€(gè)人,他們互相需要——他們得互相依靠。然而貝思不可信賴,這使他感到害怕,而且。"
{
"masked_text":"鐘將也不躲不閃,只是簡單的凝出一塊雷光盾,只是他的雷光盾卻不像楚毅峰的那樣包裹住整個(gè)身體,只有臉盆大小,但是他的雷光盾完全是一塊整體,沒有雷電閃爍,沒有電芒流轉(zhuǎn)。甚至連一點(diǎn)雷電的痕跡都看不到,就是一聲銀色的堅(jiān)實(shí)!"
總結(jié)
本文主要介紹ZeroCLUE/FewCLUE數(shù)據(jù)集、中文長下文詞語預(yù)測 (Chinese WPLC)數(shù)據(jù)集幾個(gè)下游任務(wù)數(shù)據(jù)集,感興趣的可以查看參考文獻(xiàn)進(jìn)一步處理。
審核編輯 :李倩
-
分類器
+關(guān)注
關(guān)注
0文章
153瀏覽量
13425 -
語言模型
+關(guān)注
關(guān)注
0文章
561瀏覽量
10714 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1223瀏覽量
25324
原文標(biāo)題:語言模型性能評(píng)估必備下游數(shù)據(jù)集:ZeroCLUE/FewCLUE與Chinese_WPLC數(shù)據(jù)集
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
請問NanoEdge AI數(shù)據(jù)集該如何構(gòu)建?
請問NanoEdge AI數(shù)據(jù)集該如何構(gòu)建?
建立開發(fā)集和測試集(總結(jié))
PTB數(shù)據(jù)集建立語言模型
基于不均衡醫(yī)學(xué)數(shù)據(jù)集的疾病預(yù)測模型
詳解ChatGPT數(shù)據(jù)集之謎
如何構(gòu)建高質(zhì)量的大語言模型數(shù)據(jù)集
大語言模型(LLM)預(yù)訓(xùn)練數(shù)據(jù)集調(diào)研分析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論